Rozhraní TABLE API a SQL v clusterech Apache Flink® ve službě HDInsight v AKS
Důležitý
Azure HDInsight v AKS byl vyřazen 31. ledna 2025. Další informace najdete v tomto oznámení .
Abyste se vyhnuli náhlému ukončení úloh, musíte migrovat úlohy do Microsoft Fabric nebo ekvivalentního produktu Azure.
Důležitý
Tato funkce je aktuálně ve verzi Preview. doplňkové podmínky použití pro verze preview Microsoft Azure obsahují další právní podmínky, které se vztahují na funkce Azure, které jsou v beta verzi, ve verzi preview nebo jinak dosud nebyly vydány k obecné dostupnosti. Informace o této konkrétní verzi preview najdete v tématu Azure HDInsight ve službě AKS ve verzi previewu. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás pro další aktualizace v komunitě Azure HDInsight .
Apache Flink nabízí dvě relační rozhraní API – Table API a SQL – pro jednotné zpracování streamů a dávek. Rozhraní Table API je rozhraní API pro dotazy integrované v jazyce, které umožňuje intuitivně skládat dotazy z relačních operátorů, jako je výběr, filtrování a spojení. Podpora jazyka SQL Flink je založená na Apache Calcite, který implementuje standard SQL.
Rozhraní Table API a rozhraní SQL se bezproblémově integrují s Flinkovým rozhraním DataStream API. Můžete snadno přepínat mezi všemi rozhraními API a knihovnami, které na nich vycházejí.
Apache Flink SQL
Stejně jako ostatní moduly SQL fungují dotazy Flink nad tabulkami. Liší se od tradiční databáze, protože Flink nespravuje neaktivní uložená data místně; místo toho dotazy pracují nepřetržitě s externími tabulkami.
Kanály zpracování dat Flink začínají zdrojovými tabulkami a končí výstupními tabulkami. Zdrojové tabulky vytvářejí řádky, nad kterými se provádí operace během provádění dotazu. Jsou to tabulky odkazované v klauzuli FROM dotazu. Konektory mohou být typu HDInsight Kafka, HDInsight HBase, Azure Event Hubs, databázové systémy, souborové systémy nebo jakýkoli jiný systém, jehož konektor je v classpath.
Použití klienta Flink SQL ve službě HDInsight v clusterech AKS
V tomto článku se dozvíte, jak používat rozhraní příkazového řádku ze služby Secure Shell na webu Azure Portal. Tady je několik rychlých ukázek, jak začít.
Spuštění klienta SQL
./bin/sql-client.shPředání inicializačního souboru SQL ke spuštění společně s sql-clientem
./sql-client.sh -i /path/to/init_file.sqlNastavení konfigurace v sql-clientu
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL podporuje následující příkazy CREATE.
- CREATE TABLE
- VYTVOŘIT DATABÁZI
- VYTVOŘIT KATALOG
Následuje příklad syntaxe definování zdrojové tabulky pomocí konektoru jdbc pro připojení k MSSQL s ID, název jako sloupce v příkazu CREATE TABLE
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
Vytvořit databázi (CREATE DATABASE):
CREATE DATABASE students;
VYTVOŘIT KATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
V horní části těchto tabulek můžete spouštět průběžné dotazy.
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Zapište do Sink Table z Source Table:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Přidání závislostí
Příkazy JAR se používají k přidání uživatelských JARů do cesty ke třídám, odebrání uživatelských JARů z cesty ke třídám, nebo zobrazení přidaných JARů v cestě ke třídám během běhu programu.
Flink SQL podporuje následující příkazy JAR:
- PŘIDAT JAR
- ZOBRAZIT DÓZY
- ODEBRAT JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Metastore Hive v clusterech systému Apache Flink® při použití HDInsight na AKS.
Katalogy poskytují metadata, jako jsou databáze, tabulky, oddíly, zobrazení a funkce a informace potřebné pro přístup k datům uloženým v databázi nebo jiných externích systémech.
Ve službě HDInsight na AKS pro Flink podporujeme dvě možnosti katalogu:
GenericInMemoryCatalog
GenericInMemoryCatalog je katalog implementovaný v paměti. Všechny objekty jsou k dispozici pouze po celou dobu životnosti relace SQL.
Hive Katalog
HiveCatalog slouží dvěma účelům; jako trvalé úložiště pro čistě metadata Flink a jako rozhraní pro čtení a zápis existujících metadat Hive.
Poznámka
HDInsight v clusterech AKS obsahuje integrovanou možnost metastoru Hive pro Apache Flink. Při vytváření clusteru můžete zvolit Hive Metastore
Vytvoření a registrace databází Flink do katalogů
V tomto článku se dozvíte, jak používat rozhraní příkazového řádku a jak začít používat Flink SQL Client z Secure Shell na webu Azure Portal.
Zahájení relace
sql-client.sh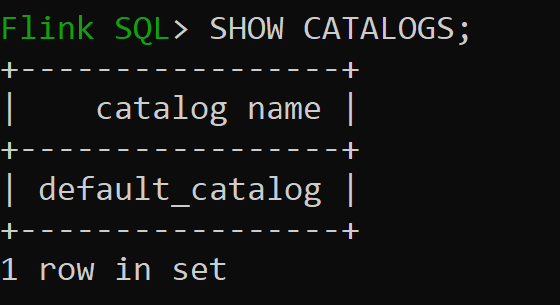
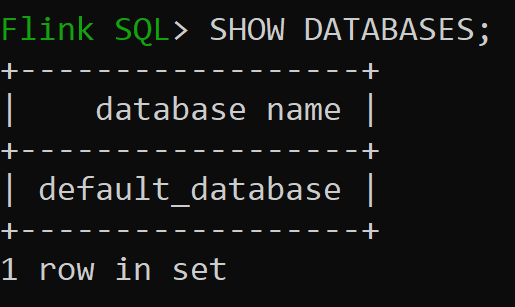
Default_catalog je výchozí katalog v paměti.
Teď zkontrolujeme výchozí databázi katalogu v paměti
Pojďme vytvořit katalog Hive verze 3.1.2 a použít ho
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Poznámka
HDInsight v AKS podporuje Hive 3.1.2 a Hadoop 3.3.2.
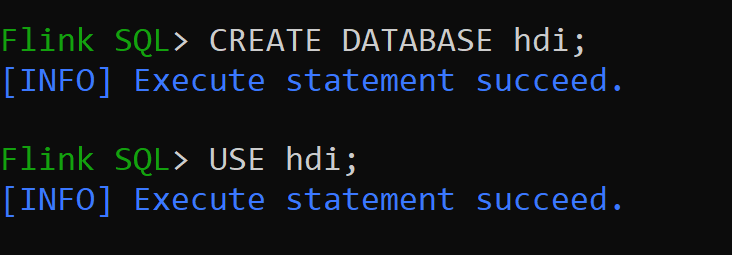
hive-conf-dirje nastaveno na umístění/opt/hive-confPojďme vytvořit databázi v katalogu Hive a nastavit ji jako výchozí pro relaci (pokud se nezmění).
Vytvoření a registrace tabulek Hive do katalogu Hive
Postupujte podle pokynů na Vytvoření a registrace databází Flink v katalogu
Vytvořme Flink tabulku typu konektoru Hive bez dělení.
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Vložení dat do hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Čtení dat z hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsPoznámka
Adresář skladu Hive se nachází v určeném kontejneru účtu úložiště zvoleného při vytváření clusteru Apache Flink. Najdete ho v adresáři hive/warehouse/
Vytvořme tabulku Flink typu konektoru hive s particí.
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Důležitý
Apache Flink má známé omezení. Poslední sloupce "n" se vyberou pro oddíly bez ohledu na sloupec oddílu definovaný uživatelem. FLINK-32596 Při vytváření tabulky Hive pomocí dialektu Flink bude klíč oddílu chybný.
Odkaz
- Apache Flink Table API & SQL
- Názvy projektů Apache, Apache Flink, Flink a souvisejících open source projektů jsou ochranné známky nadace Apache Software Foundation (ASF).