Co je Apache Flink® ve službě Azure HDInsight v AKS? (Preview)
Důležitý
Azure HDInsight v AKS byl vyřazen 31. ledna 2025. Další informace s tímto oznámením.
Abyste se vyhnuli náhlému ukončení úloh, musíte migrovat úlohy do Microsoft Fabric nebo ekvivalentního produktu Azure.
Důležitý
Tato funkce je aktuálně ve verzi Preview. Doplňkové podmínky použití pro verze Preview Microsoft Azure obsahují další právní podmínky, které se vztahují na funkce Azure, jež jsou v beta verzi, ve verzi Preview nebo dosud nebyly vydány pro obecné použití. Informace o této konkrétní verzi Preview najdete v tématu Azure HDInsight ve službě AKS ve verzi Preview. Pokud máte dotazy nebo návrhy funkcí, odešlete prosím žádost na AskHDInsight s podrobnostmi a sledujte nás pro další aktualizace v komunitě Azure HDInsight.
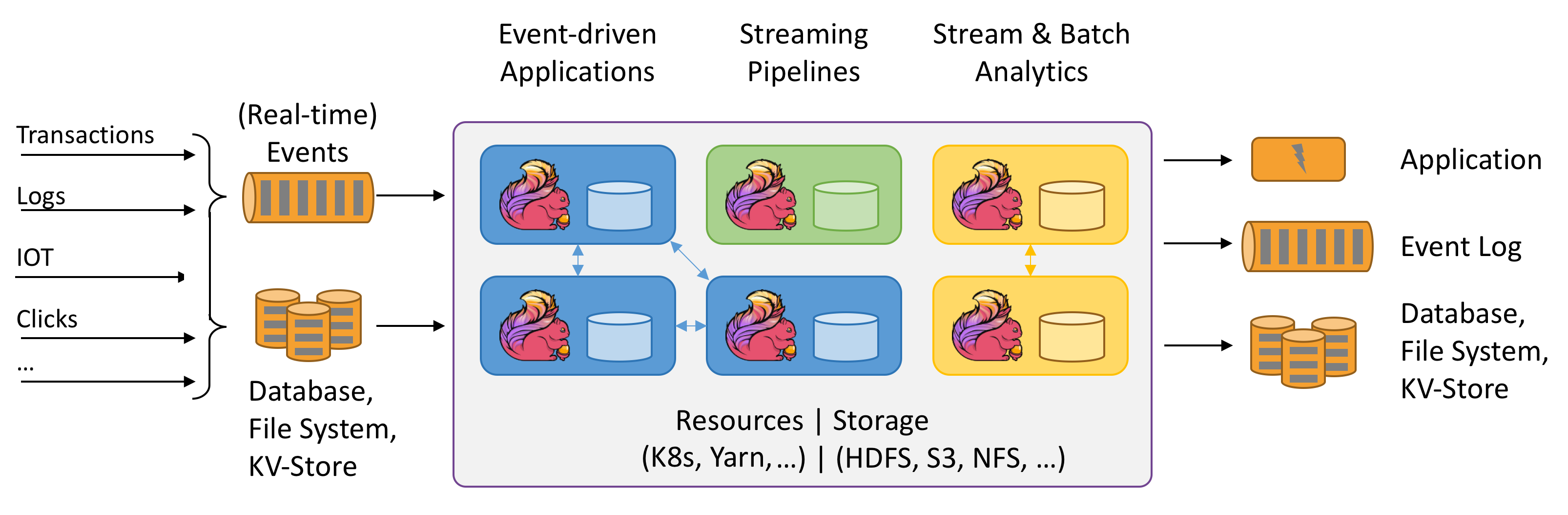
Apache Flink je architektura a distribuovaný modul zpracování pro stavové výpočty nad nevázanými a ohraničenými datovými proudy. Flink byl navržen tak, aby běžel ve všech běžných prostředích clusteru, prováděl výpočty a stavové streamované aplikace s rychlostí v paměti a v jakémkoli měřítku. Aplikace se paralelizují do tisíců úloh, které se distribuují a souběžně spouští v clusteru. Aplikace proto může používat neomezené množství vCPU, hlavní paměti, disku a vstupně-výstupních operací sítě. Flink navíc snadno udržuje rozsáhlý stav aplikace v paměti. Jeho asynchronní a přírůstkový kontrolní algoritmus zajišťuje minimální vliv na latence zpracování a současně zaručuje přesně jednou konzistenci stavu.
Apache Flink je široce škálovatelný analytický modul pro zpracování datových proudů.
Mezi klíčové funkce, které Flink nabízí, patří:
- Operace s ohraničenými a nevázanými datovými proudy
- Výkon paměti
- Schopnost streamování i dávkových výpočtů
- Nízká latence, operace s vysokou propustností
- Přesné jednorázové zpracování
- Vysoká dostupnost
- Odolnost proti stavu a chybám
- Plně kompatibilní s ekosystémem Hadoop
- Sjednocená rozhraní SQL API pro stream i batch
Proč Apache Flink?
Apache Flink je skvělou volbou pro vývoj a spouštění mnoha různých typů aplikací z důvodu rozsáhlé sady funkcí. Funkce Flinku zahrnují podporu pro zpracování datových proudů a dávek, sofistikovanou správu stavu, sémantiku zpracování času událostí a záruky konzistence "přesně jednou" pro stav. Flink nemá jediný bod selhání. Flink se ukázalo, že škáluje na tisíce jader a terabajtů stavu aplikace, zajišťuje vysokou propustnost a nízkou latenci a využívá některé z nejnáročnějších aplikací pro zpracování datových proudů na světě.
- detekce podvodů: Flink se dá použít k detekci podvodných transakcí nebo aktivit v reálném čase pomocí složitých pravidel a modelů strojového učení na streamovaných datech.
- detekce anomálií: Flink se dá použít k identifikaci odlehlých hodnot nebo neobvyklých vzorů v streamovaných datech, jako jsou čtení snímačů, síťový provoz nebo chování uživatelů.
- upozorňování na základě pravidel: Flink se dá použít k aktivaci výstrah nebo oznámení na základě předdefinovaných podmínek nebo prahových hodnot u streamovaných dat, jako je teplota, tlak nebo ceny zásob.
- monitorování obchodních procesů: Flink je možné použít ke sledování a analýze stavu a výkonu obchodních procesů nebo pracovních postupů v reálném čase, jako je například plnění objednávek, doručení nebo zákaznický servis.
- webové aplikace (sociální sítě): Flink se dá použít k napájení webových aplikací, které vyžadují zpracování dat generovaných uživatelem v reálném čase, jako jsou zprávy, lajky, komentáře nebo doporučení.
Přečtěte si více o běžných případech použití popsaných v Apache Flink Use cases.
Clustery Apache Flink ve službě HDInsight v AKS jsou plně spravovaná služba. Tady jsou uvedené výhody vytvoření clusteru Flink ve službě HDInsight v AKS.
| Funkce | Popis |
|---|---|
| Usnadnění vytváření | Pomocí webu Azure Portal, Azure PowerShellu nebo sady SDK můžete vytvořit nový cluster Flink v HDInsight v řádu minut. Viz Začínáme s clusterem Apache Flink na HDInsight v AKS. |
| Snadné použití | Mezi clustery Flink ve službě HDInsight v AKS patří správa konfigurace založená na portálu a škálování. Kromě toho s rozhraním API pro správu úloh používáte rozhraní REST API nebo Azure Portal ke správě úloh. |
| Rozhraní REST API | Clustery Flink ve službě HDInsight v AKS zahrnují rozhraní API pro správu úloh , metodu odeslání úlohy Flink založené na rozhraní REST API pro vzdálené odesílání a monitorování úloh na webu Azure Portal. |
| Typ nasazení | Flink může spouštět aplikace v režimu relace nebo v režimu aplikace. HdInsight na AKS v současné době podporuje pouze session clustery. V clusteru relací můžete spustit více úloh Flink. Režim aplikace je v plánu pro HDInsight v clusterech AKS. |
| Podpora metastoru | Clustery Flink ve službě HDInsight na AKS mohou podporovat katalogy s Hive Metastore v různých formátech otevřených souborů s pomocí vzdálených kontrolních bodů v Azure Data Lake Storage Gen2. |
| Podpora pro Azure Storage | Clustery Flink ve službě HDInsight můžou jako jímku souborů používat Azure Data Lake Storage Gen2. Další informace o Data Lake Storage Gen2 najdete v tématu Azure Data Lake Storage Gen2. |
| Integrace se službami Azure | Cluster Flink ve službě HDInsight ve službě AKS se dodává s integrací do Kafka spolu s azure Event Hubs a azure HDInsight. Streamované aplikace můžete vytvářet pomocí služby Event Hubs nebo HDInsight. |
| Přizpůsobivost | HDInsight v AKS umožňuje škálovat uzly clusteru Flink na základě plánu pomocí funkce automatického škálování. Viz automatické škálování služby Azure HDInsight v clusterech AKS. |
| Stavové úložiště | HDInsight v AKS používá RocksDB jako výchozí StateBackend. RocksDB je vestavěné perzistentní ukládání klíč-hodnota pro rychlé úložiště. |
| Kontrolní body | Ve službě HDInsight je ve výchozím nastavení v clusterech AKS povolené vytváření kontrolních bodů. Výchozí nastavení ve službě HDInsight v AKS udržuje posledních pět kontrolních bodů v trvalém úložišti. V případě selhání úlohy je možné úlohu restartovat z nejnovějšího kontrolního bodu. |
| Přírůstkové kontrolní body | RocksDB podporuje přírůstkové kontrolní body. Doporučujeme používat přírůstkové kontrolní body pro rozsáhlý stav; tuto funkci je nutné povolit ručně. Nastavení výchozí hodnoty ve vašem flink-conf.yaml: state.backend.incremental: true povolí přírůstkové kontrolní body, pokud aplikace toto nastavení v kódu nepřepíše. Tento příkaz je ve výchozím nastavení pravdivý. Tuto hodnotu můžete také nakonfigurovat přímo v kódu (přepíše výchozí nastavení konfigurace) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); . Ve výchozím nastavení zachováváme posledních pět kontrolních bodů v nakonfigurovaném adresáři kontrolních bodů. Tuto hodnotu lze změnit změnou konfigurace v části správy konfigurace state.checkpoints.num-retained: 5 |
Mezi clustery Apache Flink ve službě HDInsight v AKS patří následující komponenty, které jsou ve výchozím nastavení dostupné v clusterech.
- DataStreamAPI
- TableAPI & SQL.
Podívejte se na roadmapu o tom, co připravujeme.
Správa úloh Apache Flink
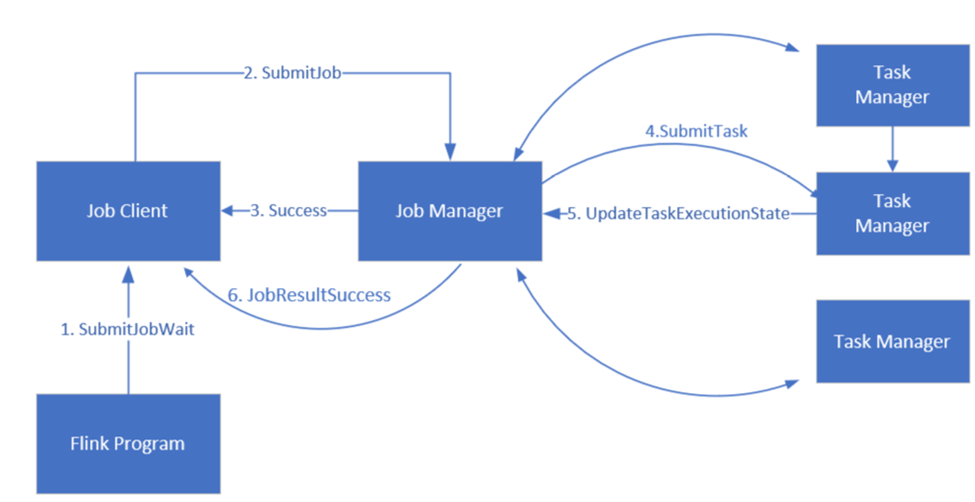
Flink plánuje úlohy pomocí tří distribuovaných komponent, správce úloh, správce úloh a klienta úloh, které jsou nastavené v Leader-Follower vzoru.
úlohy Flink: Úloha nebo program Flink se skládá z více úkolů. Úkoly jsou základní jednotkou provádění v Flinku. Každá úloha Flink má více instancí v závislosti na úrovni paralelismu a každá instance se provádí v TaskManageru.
správce úloh: Správce úloh funguje jako plánovač a plánuje úkoly na manažerech úkolů.
správce úloh: Správci úloh mají jeden nebo více slotů pro paralelní spouštění úkolů.
Klient úlohy: Klient komunikuje se správcem úloh za účelem odesílání úloh do Flink.
webového uživatelského rozhraní Flink: Flink nabízí webové uživatelské rozhraní pro kontrolu, monitorování a ladění spuštěných aplikací.
Odkaz
- Webová stránka Apache Flink
- Názvy projektů Apache, Apache Kafka, Kafka, Apache Flink, Flink a přidružených open source projektů jsou ochranné známkyApache Software Foundation (ASF).