Migrace ze služby Batch AI na službu Azure Machine Learning
Služba Azure Batch AI bude vyřazena v březnu. Funkce trénování a bodování ve velkém měřítku služby Batch AI jsou teď dostupné ve službě Azure Machine Learning, která byla obecně dostupná 4. prosince 2018.
Spolu s mnoha dalšími funkcemi strojového učení zahrnuje služba Azure Machine Learning cloudový spravovaný cílový výpočetní objekt pro trénování, nasazování a bodování modelů strojového učení. Tento cílový výpočetní objekt se nazývá Výpočetní prostředky služby Azure Machine Learning. Začněte s migrací a používáním ještě dnes. Se službou Azure Machine Learning Service můžete pracovat prostřednictvím jejích sad PYTHON SDK, rozhraní příkazového řádku a Azure Portal.
Upgrade z Batch AI ve verzi Preview na obecně dostupnou službu Azure Machine Learning vám poskytne lepší prostředí prostřednictvím konceptů, které se snadněji používají, jako jsou odhady a úložiště dat. Zaručuje také smlouvy SLA služeb Azure na úrovni ga a zákaznickou podporu.
Služba Azure Machine Learning přináší také nové funkce, jako je automatizované strojové učení, ladění hyperparametrů a kanály ML, které jsou užitečné u většiny rozsáhlých úloh AI. Možnost nasadit trénovaný model bez přepnutí na samostatnou službu pomáhá dokončit smyčku datových věd od přípravy dat (pomocí sady Sdk pro přípravu dat) až po operacionalizaci a monitorování modelů.
Zahájení migrace
Abyste se vyhnuli přerušení aplikací a mohli využívat nejnovější funkce, proveďte do 31. března 2019 následující kroky:
Vytvořte pracovní prostor služby Azure Machine Learning a začněte:
Nainstalujte sadu Sdk služby Azure Machine Learning a sadu SDK pro přípravu dat.
Nastavte výpočetní prostředky služby Azure Machine Learning pro trénování modelů.
Aktualizujte skripty tak, aby používaly výpočetní prostředky služby Azure Machine Learning. Následující části ukazují, jak se běžný kód, který používáte pro Batch AI, mapuje na kód pro Azure Machine Learning.
Vytvoření pracovních prostorů
Koncept inicializace pracovního prostoru pomocí souboru configuration.json v Azure Batch AI se mapuje podobně jako použití konfiguračního souboru ve službě Azure Machine Learning.
V případě Batch AI jste to udělali takto:
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
Azure Machine Learning Service, zkuste:
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
Kromě toho můžete pracovní prostor vytvořit také přímo zadáním parametrů konfigurace, jako je například
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
Další informace o třídě pracovního prostoru Azure Machine Learning najdete v referenční dokumentaci k sadě SDK.
Vytváření výpočetních clusterů
Azure Machine Learning podporuje několik cílových výpočetních prostředků, z nichž některé spravuje služba a jiné je možné připojit k vašemu pracovnímu prostoru (např. Cluster HDInsight nebo vzdálený virtuální počítač. Přečtěte si další informace o různých cílových výpočetních objektech. Koncept vytvoření Azure Batch výpočetního clusteru AI se mapuje na vytvoření clusteru AmlCompute ve službě Azure Machine Learning. Vytvoření Amlcompute přijímá výpočetní konfiguraci podobnou tomu, jak předáváte parametry v Azure Batch AI. Upozorňujeme, že automatické škálování je ve výchozím nastavení v clusteru AmlCompute zapnuté, zatímco ve výchozím nastavení je ve Azure Batch AI vypnuté.
V případě Batch AI jste to udělali takto:
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
V případě služby Azure Machine Learning zkuste:
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Další informace o třídě AMLCompute najdete v referenční dokumentaci k sadě SDK. Všimněte si, že ve výše uvedené konfiguraci jsou povinné pouze vm_size a max_nodes a ostatní vlastnosti, jako jsou virtuální sítě, jsou určené jenom pro pokročilé nastavení clusteru.
Monitorování stavu clusteru
Ve službě Azure Machine Learning Je to jednodušší, jak uvidíte níže.
V případě Batch AI jste to udělali takto:
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
V případě služby Azure Machine Learning zkuste:
gpu_cluster.get_status().serialize()
Získání odkazu na účet úložiště
Koncept úložiště dat, jako je objekt blob, se ve službě Azure Machine Learning zjednodušuje pomocí objektu DataStore. Ve výchozím nastavení vytvoří pracovní prostor služby Azure Machine Learning účet úložiště, ale při vytváření pracovního prostoru můžete připojit i vlastní úložiště.
V případě Batch AI jste to udělali takto:
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
V případě služby Azure Machine Learning zkuste:
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Další informace o registraci dalších účtů úložiště nebo získání odkazu na jiné registrované úložiště dat najdete v dokumentaci ke službě Azure Machine Learning.
Stažení a nahrání dat
U obou služeb můžete data snadno nahrát do účtu úložiště pomocí výše uvedeného odkazu na úložiště dat. Pro Azure Batch AI nasadíme také trénovací skript jako součást sdílené složky, i když uvidíte, jak ho můžete zadat jako součást konfigurace úlohy v případě služby Azure Machine Learning Service.
V případě Batch AI jste to udělali takto:
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
V případě služby Azure Machine Learning zkuste:
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
Vytváření experimentů
Jak je uvedeno výše, služba Azure Machine Learning má koncept experimentu podobný Azure Batch AI. Každý experiment pak může mít jednotlivá spuštění, podobně jako máme úlohy v Azure Batch AI. Služba Azure Machine Learning také umožňuje mít hierarchii pod každým nadřazeným spuštěním pro jednotlivá podřízená spuštění.
V případě Batch AI jste to udělali takto:
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
V případě služby Azure Machine Learning zkuste:
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
Odesílání úloh
Jakmile vytvoříte experiment, máte několik různých způsobů odeslání spuštění. V tomto příkladu se pokoušíme vytvořit model hlubokého učení pomocí TensorFlowu a použijeme k tomu nástroj pro posouzení služby Azure Machine Learning. Estimátor je jednoduše funkce obálky v základní konfiguraci spuštění, která usnadňuje odesílání spuštění. V současné době se podporuje pouze pro Pytorch a TensorFlow. Prostřednictvím koncepce úložišť dat také uvidíte, jak snadné je zadat cesty připojení.
V případě Batch AI jste to udělali takto:
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
Odeslání samotné úlohy v Azure Batch AI probíhá prostřednictvím funkce create.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
Úplné informace o tomto fragmentu trénovacího kódu (včetně souboru mnist_replica.py, který jsme nahráli do výše uvedené sdílené složky) najdete v úložišti Azure Batch ukázkového poznámkového bloku AI na GitHubu.
V případě služby Azure Machine Learning zkuste:
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
Úplné informace o tomto fragmentu trénovacího kódu (včetně souboru tf_mnist_replica.py) najdete v úložišti ukázkového poznámkového bloku služby Azure Machine Learning Service na GitHubu. Samotné úložiště dat je možné buď připojit k jednotlivým uzlům, nebo se trénovací data dají stáhnout do samotného uzlu. Další podrobnosti o odkazování na úložiště dat v estimátoru najdete v dokumentaci ke službě Azure Machine Learning.
Odeslání spuštění ve službě Azure Machine Learning se provádí prostřednictvím funkce submit.
run = experiment.submit(estimator)
print(run)
Parametry pro spuštění můžete zadat i jiným způsobem, a to pomocí konfigurace spuštění – zvlášť užitečné pro definování vlastního trénovacího prostředí. Další podrobnosti najdete v tomto ukázkovém poznámkovém bloku AmlCompute.
Monitorování spuštění
Po odeslání spuštění můžete buď počkat na jeho dokončení, nebo ho monitorovat ve službě Azure Machine Learning pomocí přehledných widgetů Jupyter, které můžete vyvolat přímo ze svého kódu. Můžete si také vyžádat kontext jakéhokoli předchozího spuštění tak, že projdete různé experimenty v pracovním prostoru a jednotlivé se spustí v rámci každého experimentu.
V případě Batch AI jste to udělali takto:
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
V případě služby Azure Machine Learning zkuste:
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
Tady je snímek toho, jak by se widget načetl do poznámkového bloku, aby se mohl podívat na protokoly v reálném čase: 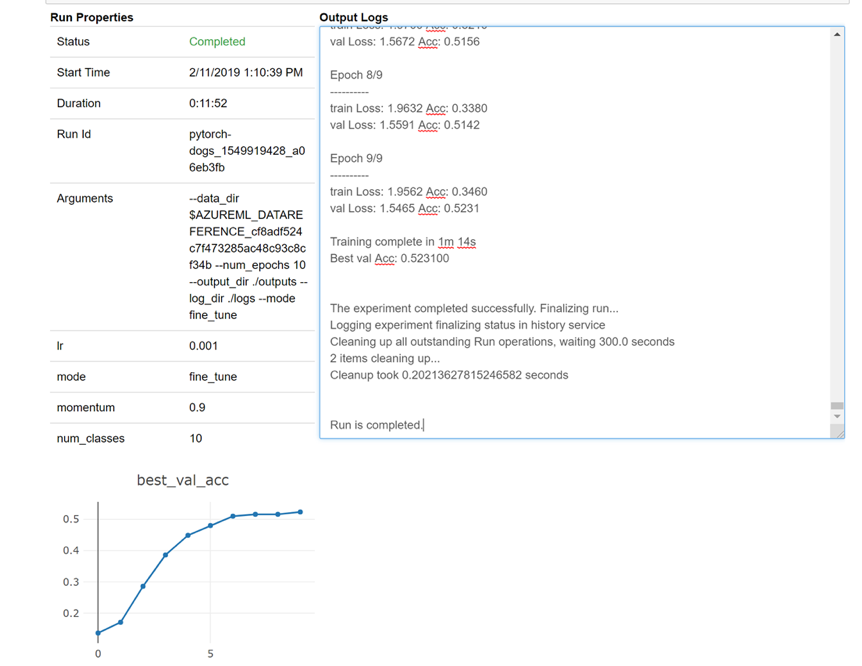
Úprava clusterů
Odstranění clusteru je jednoduché. Kromě toho služba Azure Machine Learning service také umožňuje aktualizovat cluster z poznámkového bloku pro případ, že ho chcete škálovat na větší počet uzlů nebo prodloužit dobu nečinnosti před vertikálním snížením kapacity clusteru. Neumožňujeme vám změnit velikost virtuálního počítače samotného clusteru, protože to vyžaduje nové nasazení v back-endu.
V případě Batch AI jste to udělali takto:
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
V případě služby Azure Machine Learning zkuste:
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
Získání podpory
Služba Batch AI se má 31. března vyřadit z provozu a už blokuje registraci nových předplatných ve službě, pokud není na seznamu povolených vyvoláním výjimky prostřednictvím podpory. Pokud máte při migraci na službu Azure Machine Learning Service zpětnou vazbu, obraťte se na nás na Azure Batch AI Training Preview.
Služba Azure Machine Learning je obecně dostupná služba. To znamená, že se dodává s potvrzenou smlouvou SLA a různými plány podpory, ze kterých si můžete vybrat.
Ceny za používání infrastruktury Azure prostřednictvím služby Azure Batch AI nebo prostřednictvím služby Azure Machine Learning by se neměly lišit, protože v obou případech účtujeme pouze cenu za základní výpočetní prostředky. Další informace najdete v cenové kalkulačce.
Zobrazte regionální dostupnost mezi těmito dvěma službami na Azure Portal.
Další kroky
Přečtěte si přehled služby Azure Machine Learning.
Konfigurace cílového výpočetního objektu pro trénování modelu pomocí služby Azure Machine Learning
Projděte si plán azure a seznamte se s dalšími aktualizacemi služeb Azure.