Aspekty mapování polí pro standardní toky dat
Při načítání dat do tabulek Dataverse namapujete sloupce zdrojového dotazu v prostředí pro úpravy toku dat na cílové sloupce tabulky Dataverse. Kromě mapování dat je potřeba vzít v úvahu i další aspekty a osvědčené postupy. V tomto článku se podíváme na různá nastavení toku dat, která řídí chování aktualizace toku dat a v důsledku toho data v cílové tabulce.
Řízení, jestli toky dat vytvářejí nebo upsertují záznamy každé aktualizace
Pokaždé, když aktualizujete tok dat, načte záznamy ze zdroje a načte je do Dataverse. Pokud tok dat spustíte více než jednou – v závislosti na konfiguraci toku dat – můžete:
- Vytvořte nové záznamy pro každou aktualizaci toku dat, i když tyto záznamy již v cílové tabulce existují.
- Vytvořte nové záznamy, pokud ještě v tabulce neexistují, nebo aktualizujte existující záznamy, pokud už v tabulce existují. Toto chování se nazývá upsert.
Použití klíčového sloupce označuje tok dat k přenesení záznamů do cílové tabulky, aniž by výběr klíče indikuje toku dat pro vytvoření nových záznamů v cílové tabulce.
Klíčový sloupec je sloupec, který je jedinečný a deterministický pro řádek dat v tabulce. Například pokud je ID objednávky klíčovým sloupcem, neměli byste mít dva řádky se stejným ID objednávky. Také jedno ID objednávky ( řekněme, že objednávka s ID 345) by měla představovat pouze jeden řádek v tabulce. Pokud chcete zvolit klíčový sloupec pro tabulku v Dataverse z toku dat, musíte v prostředí mapových tabulek nastavit klíčové pole.
Volba pole primárního názvu a klíče při vytváření nové tabulky
Následující obrázek ukazuje, jak můžete při vytváření nové tabulky v toku dat zvolit klíčový sloupec, který se má ze zdroje naplnit.
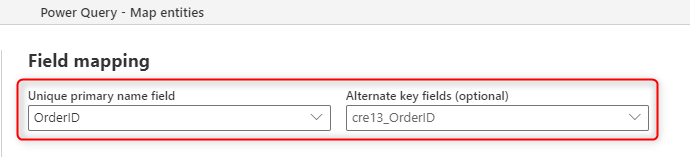
Pole primárního názvu, které vidíte v mapování polí, je určené pro pole popisku; toto pole nemusí být jedinečné. Pole použité v tabulce pro kontrolu duplicit je pole, které jste nastavili v poli Alternativní klíč .
Primární klíč v tabulce zajistí, že i když máte duplicitní data v poli, které je namapované na primární klíč, duplicitní položky se do tabulky nenačtou. Toto chování udržuje vysokou kvalitu dat v tabulce. Vysoce kvalitní data jsou nezbytná při vytváření řešení pro vytváření sestav na základě tabulky.
Pole primárního názvu
Pole primárního názvu je zobrazované pole použité v Dataverse. Toto pole se používá ve výchozím zobrazení k zobrazení obsahu tabulky v jiných aplikacích. Toto pole není polem primárního klíče a nemělo by se považovat za toto. Toto pole může mít duplicitní hodnoty, protože se jedná o zobrazované pole. Osvědčeným postupem je ale použít zřetězené pole k mapování na pole primárního názvu, takže je tento název plně vysvětlující.
Pole alternativního klíče je to, co se používá jako primární klíč.
Výběr pole klíče při načítání do existující tabulky
Při mapování dotazu toku dat na existující tabulku Dataverse můžete zvolit, jestli a jaký klíč se má použít při načítání dat do cílové tabulky.
Následující obrázek ukazuje, jak můžete zvolit klíčový sloupec, který se má použít při přenesení záznamů do existující tabulky Dataverse:

Nastavení sloupce Jedinečné ID tabulky a jeho použití jako pole klíče pro přenesení záznamů do existujících tabulek Dataverse
Všechny řádky tabulky Microsoft Dataverse mají jedinečné identifikátory definované jako identifikátory GUID. Tyto identifikátory GUID jsou primárním klíčem pro každou tabulku. Ve výchozím nastavení nejde primární klíč tabulky nastavit podle toků dat a při vytvoření záznamu se automaticky vygeneruje službou Dataverse. Existují pokročilé případy použití, kdy je žádoucí využít primární klíč tabulky, například integraci dat s externími zdroji a zachování stejných hodnot primárního klíče v externí tabulce i tabulce Dataverse.
Poznámka:
- Tato funkce je dostupná pouze při načítání dat do existujících tabulek.
- Pole jedinečného identifikátoru přijímá pouze řetězec obsahující hodnoty GUID, jakýkoli jiný datový typ nebo hodnota způsobí selhání vytváření záznamů.
Pokud chcete využít výhod pole jedinečného identifikátoru tabulky, vyberte Načíst do existující tabulky na stránce Mapové tabulky při vytváření toku dat. V příkladu zobrazeném na následujícím obrázku načte data do tabulky CustomerTransactions a použije sloupec TransactionID ze zdroje dat jako jedinečný identifikátor tabulky.
Všimněte si, že v rozevíracím seznamu Vybrat klíč je možné vybrat jedinečný identifikátor , který se vždy jmenuje tablename + ID tabulky. Vzhledem k tomu, že název tabulky je CustomerTransactions, pole jedinečného identifikátoru má název CustomerTransactionId.

Po výběru se oddíl mapování sloupců aktualizuje tak, aby zahrnoval jedinečný identifikátor jako cílový sloupec. Potom můžete namapovat zdrojový sloupec představující jedinečný identifikátor každého záznamu.

Co jsou vhodnými kandidáty pro klíčové pole
Pole klíče je jedinečná hodnota představující jedinečný řádek v tabulce. Toto pole je důležité mít, protože pomáhá vyhnout se duplicitním záznamům v tabulce. Toto pole může pocházet ze tří zdrojů:
Primární klíč ve zdrojovém systému (například OrderID v předchozím příkladu). zřetězené pole vytvořené prostřednictvím transformací Power Query v toku dat.
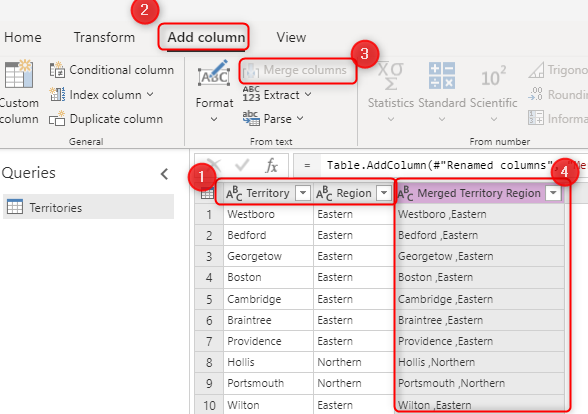
Kombinace polí, která se mají vybrat v možnosti Alternativní klíč Kombinace polí používaných jako pole s klíčem se označuje také jako složený klíč.
Odebrání řádků, které již neexistují
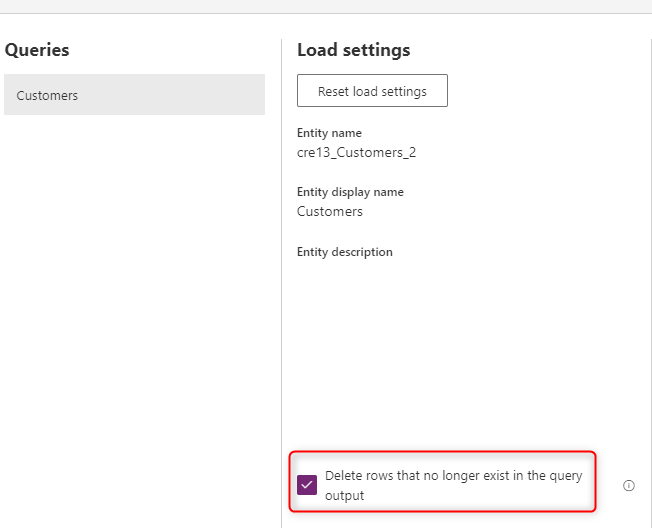
Pokud chcete mít data v tabulce vždy synchronizovaná s daty ze zdrojového systému, zvolte možnost Odstranit řádky, které už ve výstupu dotazu neexistují. Tato možnost ale zpomalí tok dat, protože je potřeba provést porovnání řádků na základě primárního klíče (alternativního klíče v mapování pole toku dat) pro tuto akci.
Tato možnost znamená, že pokud v tabulce existuje řádek dat, který v výstupu dotazu další aktualizace toku dat neexistuje, odebere se tento řádek z tabulky.
Poznámka:
Standardní toky dat V2 spoléhají na createdon pole a modifiedon odeberou řádky, které ve výstupu toků dat neexistují, z cílové tabulky. Pokud tyto sloupce v cílové tabulce neexistují, záznamy se neodstraní.
Známá omezení
- Mapování na polymorfní vyhledávací pole se v současné době nepodporuje.
- Mapování na vyhledávací pole s více úrovněmi, vyhledávání, které odkazuje na vyhledávací pole jiné tabulky, se v současné době nepodporuje.
- Mapování na pole Stav a Důvod stavu se v současné době nepodporuje.
- Mapování dat na víceřádkový text, který obsahuje znaky zalomení řádku, není podporováno a konce řádků se odeberou. Místo toho můžete pomocí značky
<br>zalomení řádku načíst a zachovat víceřádkový text. - Mapování na pole Volba nakonfigurované s povolenou možností vícenásobného výběru je podporováno pouze za určitých podmínek. Tok dat načte data pouze do polí Volba s povolenou možností vícenásobného výběru a použije se čárkami oddělený seznam hodnot (celá čísla). Pokud jsou například popisky "Choice1, Choice2, Choice3" s odpovídajícími celočíselnou hodnotou "1, 2, 3", pak by hodnoty sloupce měly být "1,3", aby se vybraly první a poslední volby.
- Standardní toky dat V2 spoléhají na
createdonpole amodifiedonodeberou řádky, které ve výstupu toků dat neexistují, z cílové tabulky. Pokud tyto sloupce v cílové tabulce neexistují, záznamy se neodstraní. - Mapování na pole, jejichž vlastnost IsValidForCreate je nastavená na
false, není podporována (například pole Účet entity Kontakt).