Osvědčené postupy pro navrhování a vývoj složitých toků dat
Pokud se tok dat, který vyvíjíte, zvětší a složitější, tady je několik věcí, které můžete udělat, abyste vylepšili původní návrh.
Rozdělte ho do několika toků dat.
Nedělejte všechno v jednom toku dat. Nejen že jeden složitý tok dat ztěžuje proces transformace dat, ale také znesnadňuje pochopení a opětovné použití toku dat. Rozdělení toku dat do několika toků dat je možné provést oddělením tabulek v různých tocích dat nebo dokonce jedné tabulky do několika toků dat. Koncept počítané tabulky nebo propojené tabulky můžete použít k vytvoření části transformace v jednom toku dat a jeho opakované použití v jiných tocích dat.
Oddělte toky dat transformace od toků dat přípravy/extrakce
Některé toky dat jsou užitečné nejen pro extrakci dat (tj. přípravných toků dat) a jiné jen pro transformaci dat je užitečné nejen při vytváření vícevrstvé architektury, ale také je užitečné snížit složitost toků dat. Některé kroky pouze extrahují data ze zdroje dat, například získání dat, navigace a změny datového typu. Rozdělením přípravných toků dat a transformačních toků dat usnadníte vývoj toků dat.
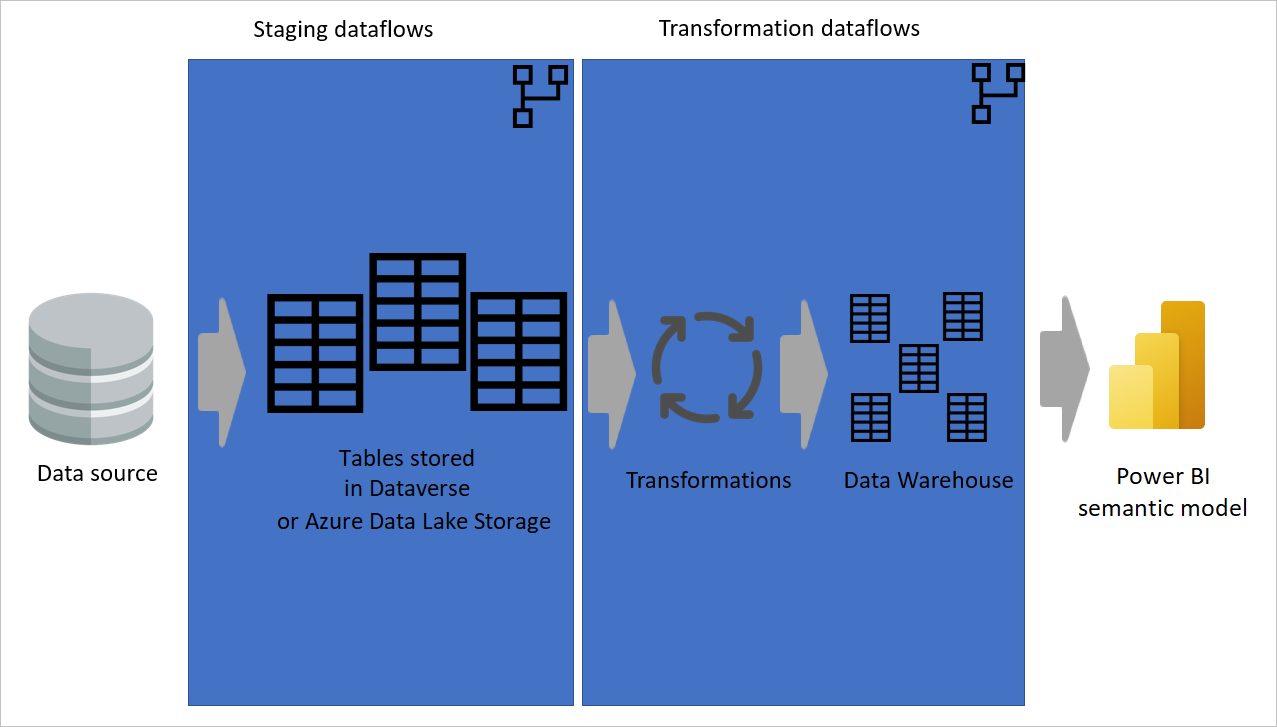
Obrázek znázorňující extrahování dat ze zdroje dat do pracovních toků dat, kde jsou tabulky uložené buď ve službě Dataverse, nebo ve službě Azure Data Lake Storage Potom se data přesunou do transformačních toků dat, ve kterých se data transformují a převedou na strukturu datového skladu. Data se pak přesunou do sémantického modelu.
Použití vlastních funkcí
Vlastní funkce jsou užitečné ve scénářích, kdy je potřeba provést určitý počet kroků pro určitý počet dotazů z různých zdrojů. Vlastní funkce je možné vyvíjet prostřednictvím grafického rozhraní v Editoru Power Query nebo pomocí skriptu M. Funkce je možné opakovaně používat v toku dat v tolika tabulkách, kolik potřebujete.
Vlastní funkce pomáhá mít pouze jednu verzi zdrojového kódu, takže nemusíte duplikovat kód. V důsledku toho je údržba logiky transformace Power Query a celého toku dat mnohem jednodušší. Další informace najdete v následujícím blogovém příspěvku: Snadné použití vlastních funkcí v Power BI Desktopu.
Poznámka
Někdy se může zobrazit oznámení, že se k aktualizaci toku dat vlastní funkcí vyžaduje kapacita Premium. Tuto zprávu můžete ignorovat a znovu otevřít editor toku dat. Tento problém se obvykle vyřeší, pokud vaše funkce neodkazuje na dotaz, který má povolenou zátěž.
Umístění dotazů do složek
Použití složek pro dotazy pomáhá seskupit související dotazy dohromady. Při vývoji toku dat věnujte trochu více času uspořádání dotazů ve složkách, které mají smysl. Tento přístup vám usnadní hledání dotazů v budoucnu a správa kódu je mnohem jednodušší.
Použijte počítané tabulky
Počítané tabulky nejen usnadňují srozumitelnější tok dat, ale také poskytují lepší výkon. Použijete-li vypočítanou tabulku, ostatní tabulky, které na ni odkazují, získávají data z jedné „již zpracované a uložené“ tabulky. Transformace je mnohem jednodušší a rychlejší.
Využití vylepšeného výpočetního modulu
U toků dat vyvinutých na portálu pro správu Power BI se ujistěte, že používáte vylepšený výpočetní modul provedením transformací spojení a filtrování nejprve ve vypočítané tabulce, než provedete jiné typy transformací.
Rozdělení mnoha kroků do několika dotazů
V jedné tabulce je těžké sledovat velký počet kroků. Místo toho byste měli rozdělit velký počet kroků do více tabulek. Můžete použít Povolit načtení pro jiné dotazy a zakázat je, pokud se jedná o zprostředkující dotazy, a načíst pouze konečnou tabulku prostřednictvím toku dat. Pokud máte v každé z nich více dotazů s menšími kroky, je jednodušší použít diagram závislostí a sledovat každý dotaz pro další šetření, a nemusíte se zabývat stovkami kroků v jednom dotazu.
Přidání vlastností pro dotazy a kroky
Dokumentace je klíčem k snadné údržbě kódu. V Power Query můžete do tabulek přidat vlastnosti a také kroky. Text, který přidáte do vlastností, se zobrazí jako popis, když na tento dotaz nebo krok najedete myší. Tato dokumentace vám pomůže udržovat model v budoucnu. Když nahlédnete na tabulku nebo krok, můžete pochopit, co se tam děje, a nemusíte si pamatovat, co jste v daném kroku udělali.
Ujistěte se, že je kapacita ve stejné oblasti.
Toky dat momentálně nepodporují více zemí nebo oblastí. Kapacita Premium musí být ve stejné oblasti jako váš tenant Power BI.
Oddělení místních zdrojů od cloudových zdrojů
Doporučujeme vytvořit samostatný tok dat pro každý typ zdroje, jako je místní, cloud, SQL Server, Spark a Dynamics 365. Oddělení toků dat podle typu zdroje usnadňuje rychlé řešení potíží a při aktualizaci toků dat se vyhne interním limitům.
Oddělení toků dat na základě plánované aktualizace vyžadované pro tabulky
Pokud máte tabulku prodejních transakcí, která se aktualizuje ve zdrojovém systému každou hodinu a máte tabulku mapování produktů, která se aktualizuje každý týden, rozdělte tyto dvě tabulky do dvou toků dat s různými plány aktualizace dat.
Vyhněte se plánování aktualizace propojených tabulek ve stejném pracovním prostoru.
Pokud jste pravidelně zablokováni z toků dat, které obsahují propojené tabulky, může to být způsobeno odpovídajícím závislým tokem dat v tomtéž pracovním prostoru, který je uzamčen během obnovení toku dat. Takové zamykání zajišťuje přesnost transakcí a zajišťuje, že se oba toky dat úspěšně aktualizují, ale může vám zablokovat úpravy.
Pokud pro propojený tok dat nastavíte samostatný plán, dají se toky dat zbytečně aktualizovat a blokovat úpravy toku dat. Existují dvě doporučení, která by se tomuto problému vyhnula:
- Nenastavujte plán aktualizace pro propojený tok dat ve stejném pracovním prostoru jako zdrojový tok dat.
- Pokud chcete nakonfigurovat plán aktualizace samostatně a chcete se vyhnout chování uzamčení, přesuňte tok dat do samostatného pracovního prostoru.