Text/CSV
Shrnutí
| Položka | Popis |
|---|---|
| Stav vydání | Všeobecná dostupnost |
| Produkty | Excel Power BI (sémantické modely) Power BI (toky dat) Prostředky infrastruktury (Tok dat Gen2) Power Apps (toky dat) Dynamics 365 Customer Insights Analysis Services |
| Referenční dokumentace k funkcím | File.Contents Lines.FromBinary Csv.Document |
Poznámka:
Některé funkce můžou být přítomné v jednom produktu, ale ne jiné kvůli plánům nasazení a možnostem specifickým pro hostitele.
Podporované funkce
- Import
Připojení do místního textového souboru nebo souboru CSV z Power Query Desktopu
Načtení místního textového souboru nebo souboru CSV:
Vyberte možnost Text/CSV v části Získat data. Tato akce spustí místní prohlížeč souborů, kde můžete vybrat textový soubor.
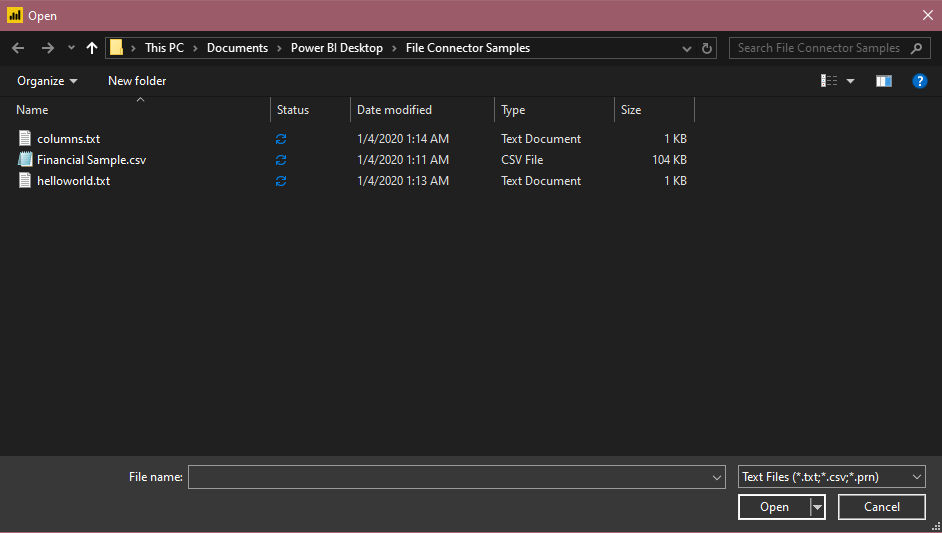
Výběrem Open (Otevřít) soubor otevřete.
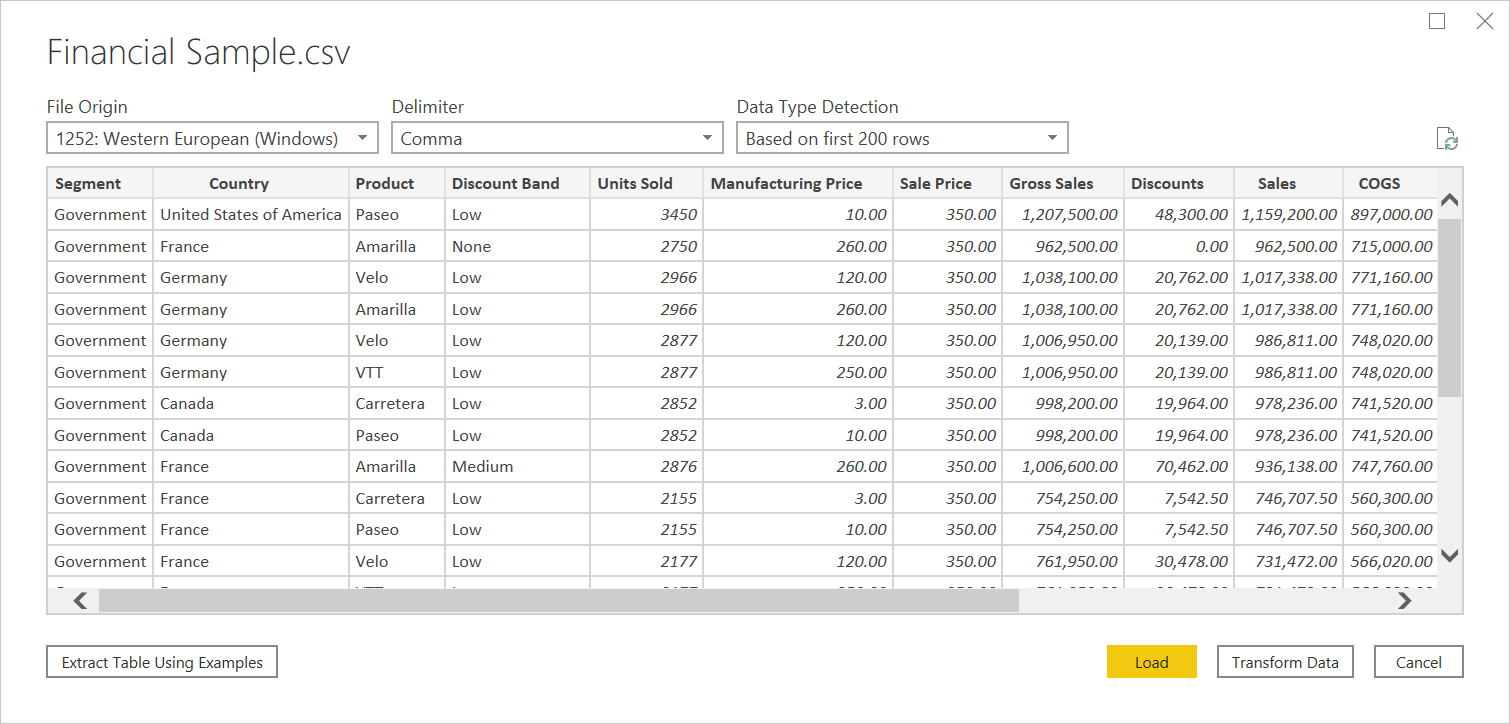
V navigátoru můžete buď transformovat data v Editor Power Query výběrem možnosti Transformovat data, nebo načíst data výběrem možnosti Načíst.
Připojení k textovému souboru nebo souboru CSV z Power Query Online
Načtení místního textového souboru nebo souboru CSV:
Na stránce Zdroje dat vyberte Text/CSV.
V nastavení Připojení zadejte cestu k souboru s místním textem nebo požadovaným souborem CSV.
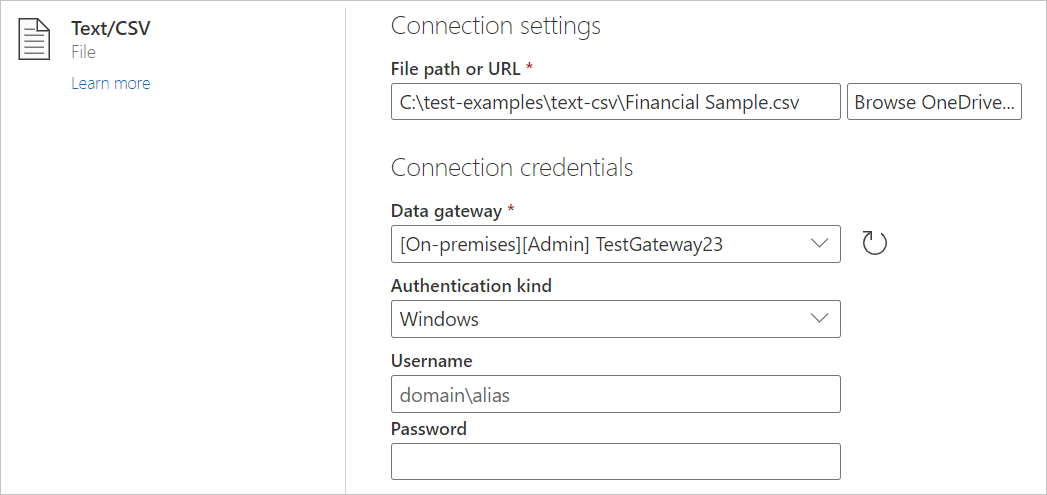
Vyberte místní bránu dat z brány dat.
Zadejte uživatelské jméno a heslo.
Vyberte Další.
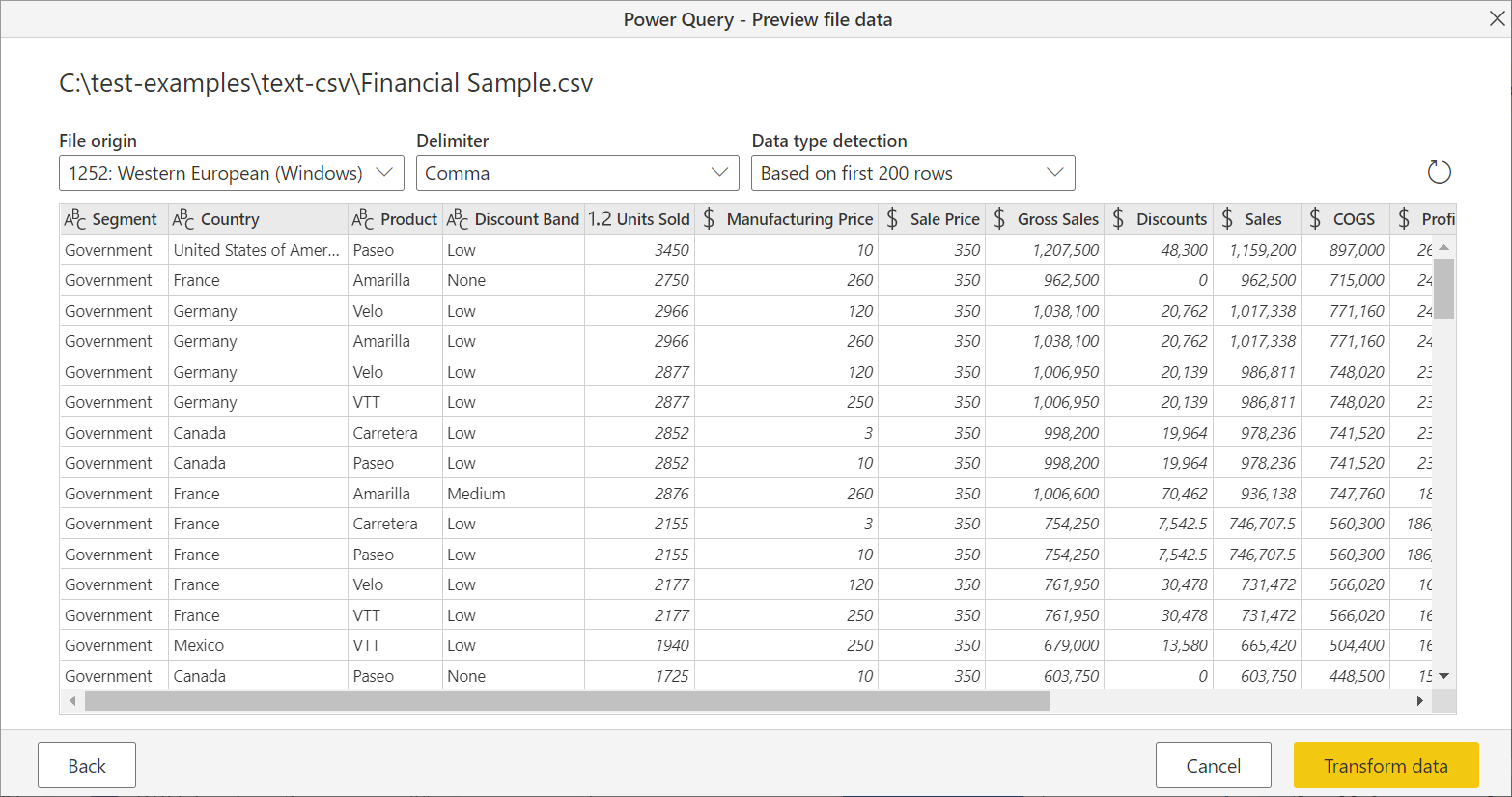
V navigátoru vyberte Transformovat data a začněte transformovat data v Editor Power Query.
Načtení z webu
Pokud chcete načíst text nebo soubor CSV z webu, vyberte webový konektor, zadejte webovou adresu souboru a postupujte podle výzev k zadání přihlašovacích údajů.
Oddělovače textu/CSV
Power Query bude zacházet se sdílenými svazky clusteru jako se strukturovanými soubory jako oddělovačem – zvláštní případ textového souboru. Pokud zvolíte textový soubor, Power Query se automaticky pokusí zjistit, jestli obsahuje hodnoty oddělené oddělovačem a jaký je tento oddělovač. Pokud může odvodit oddělovač, bude s ním automaticky zacházet jako se strukturovaným zdrojem dat.
Nestrukturovaný text
Pokud textový soubor nemá strukturu, dostanete jeden sloupec s novým řádkem zakódovaným ve zdrojovém textu. Jako příklad pro nestrukturovaný text můžete zvážit soubor poznámkového bloku s následujícím obsahem:
Hello world.
This is sample data.
Když ho načtete, zobrazí se navigační obrazovka, která načte každý z těchto řádků do vlastního řádku.
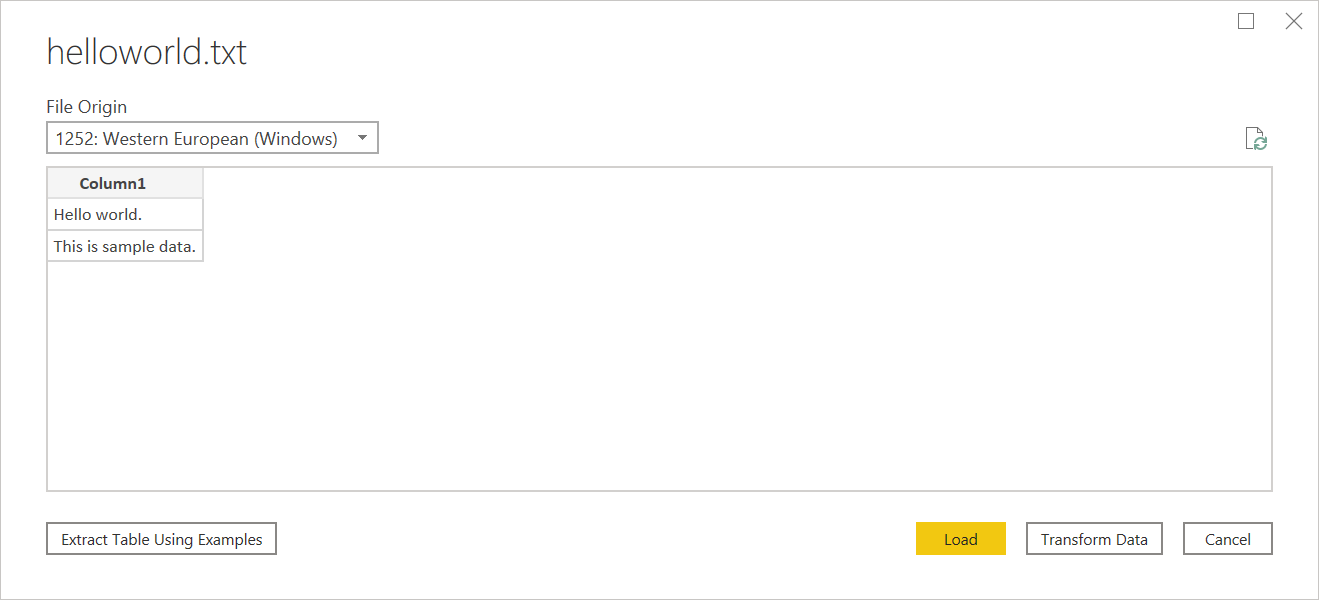
V tomto dialogovém okně můžete nakonfigurovat jenom jednu věc, což je výběr rozevíracího seznamu Původ souboru. V tomto rozevíracím seznamu můžete vybrat , která znaková sada byla použita k vygenerování souboru. Znaková sada se v současné době neodvozuje a UTF-8 se odvozuje pouze v případě, že začíná znakem kusovníku UTF-8.
CSV
Tady najdete ukázkový soubor CSV.
Kromě původu souboru podporuje CSV také určení oddělovače a způsobu zpracování detekce datových typů.
Mezi dostupné oddělovače patří dvojtečka, čárka, znaménko rovná se, středník, mezera, tabulátor, vlastní oddělovač (který může být libovolný řetězec) a pevná šířka (rozdělení textu podle určitého standardního počtu znaků).
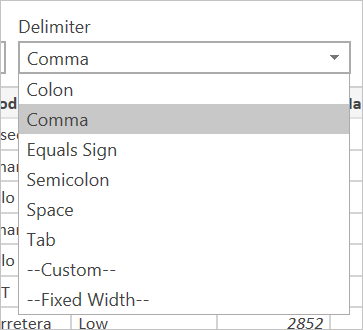
Poslední rozevírací seznam umožňuje vybrat, jak chcete zpracovávat detekci datových typů. Můžete to udělat na základě prvních 200 řádků, na celé sadě dat, nebo můžete zvolit, že nechcete automatické zjišťování datových typů a místo toho nechat všechny sloupce výchozí na Text. Upozornění: Pokud to uděláte u celé sady dat, může to způsobit pomalejší počáteční načtení dat v editoru.

Vzhledem k tomu, že odvození může být nesprávné, je vhodné před načtením pečlivě zkontrolovat nastavení.
Structured Text
Když Power Query dokáže rozpoznat strukturu textového souboru, bude se s textovým souborem považovat za soubor hodnot oddělený oddělovačem a poskytne vám stejné možnosti, které jsou k dispozici při otevření souboru CSV – což je v podstatě soubor s příponou označující typ oddělovače.
Pokud například uložíte následující příklad jako textový soubor, přečte se jako oddělovač tabulátoru místo nestrukturovaného textu.
Column 1 Column 2 Column 3
This is a string. 1 ABC123
This is also a string. 2 DEF456
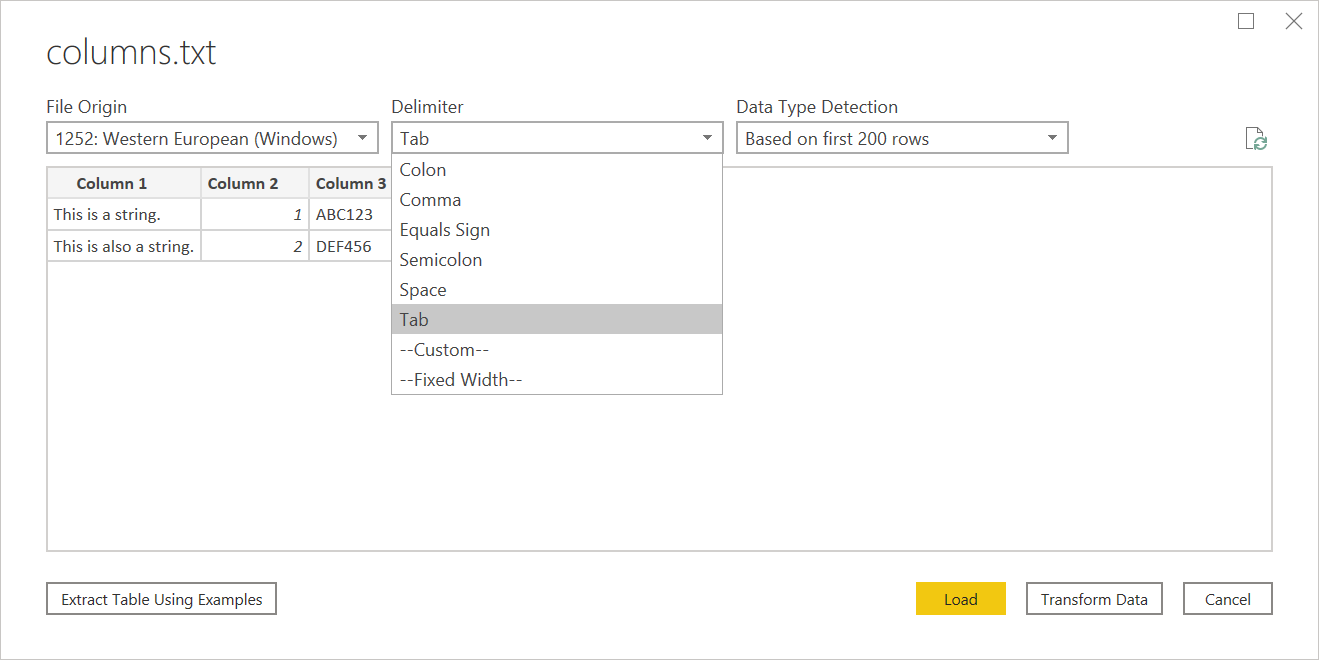
To lze použít pro jakýkoli druh jiného souboru založeného na oddělovači.
Úprava zdroje
Při úpravách zdrojového kroku se zobrazí trochu jiné dialogové okno než při počátečním načítání. V závislosti na tom, co s souborem aktuálně pracujete (tj. jako s textem nebo souborem CSV), zobrazí se obrazovka s celou řadou rozevíracích seznamu.
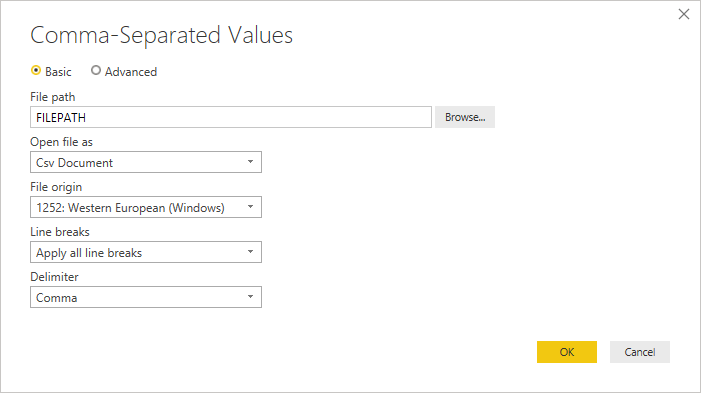
Rozevírací seznam Konce řádků vám umožní vybrat, jestli chcete použít konce řádků, které jsou uvnitř uvozovek nebo ne.
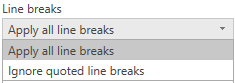
Pokud například upravíte výše uvedenou ukázku strukturovanou, můžete přidat konec řádku.
Column 1 Column 2 Column 3
This is a string. 1 "ABC
123"
This is also a string. 2 "DEF456"
Pokud je konce řádků nastavené na Ignorovat konce řádků, načte se, jako by nedošlo k přerušení řádku (s nadbytečným mezerou).

Pokud je zalomení řádků nastavené na Použít všechny konce řádků, načte se další řádek s obsahem za koncem řádku jediným obsahem v daném řádku (přesný výstup může záviset na struktuře obsahu souboru).
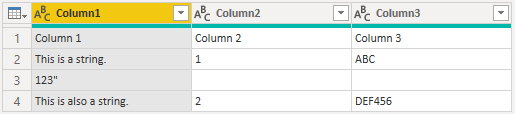
Rozevírací seznam Otevřít soubor jako vám umožní upravit, co chcete soubor načíst– důležité pro řešení potíží. U strukturovaných souborů, které nejsou technicky sdílené svazky clusteru (například soubor hodnot oddělený tabulátorem uložený jako textový soubor), byste stále měli mít soubor Otevřít nastavený na CSV. Toto nastavení také určuje, které rozevírací seznamy jsou k dispozici ve zbývající části dialogového okna.
Text/CSV podle příkladu
Text/CSV podle příkladu v Power Query je obecně dostupná funkce v Power BI Desktopu a Power Query Online. Když použijete konektor Text/CSV, zobrazí se v levém dolním rohu navigátoru možnost Extrahovat tabulku pomocí příkladů .
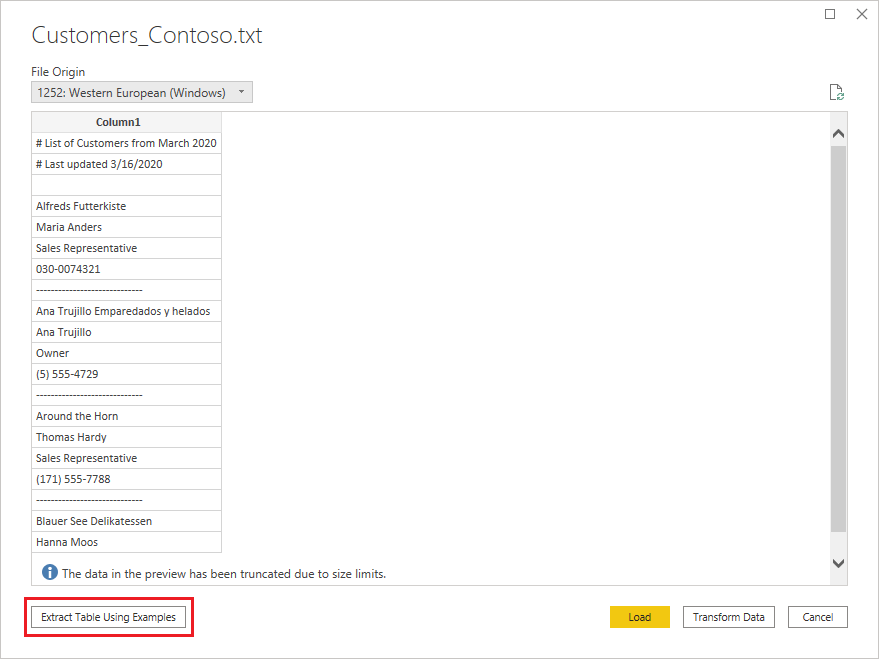
Když toto tlačítko vyberete, přejdete na stránku Extrahovat tabulku pomocí příkladů . Na této stránce zadáte ukázkové výstupní hodnoty pro data, která chcete extrahovat ze souboru Text/CSV. Po zadání první buňky sloupce se vyplní další buňky ve sloupci. Aby se data extrahovaná správně extrahovali, budete možná muset do sloupce zadat více než jednu buňku. Pokud jsou některé buňky ve sloupci nesprávné, můžete opravit první nesprávnou buňku a data se znovu extrahují. Zkontrolujte data v prvních několika buňkách a ujistěte se, že se data úspěšně extrahovali.
Poznámka:
Doporučujeme zadat příklady v pořadí sloupců. Po úspěšném vyplnění sloupce vytvořte nový sloupec a začněte do nového sloupce zadávat příklady.
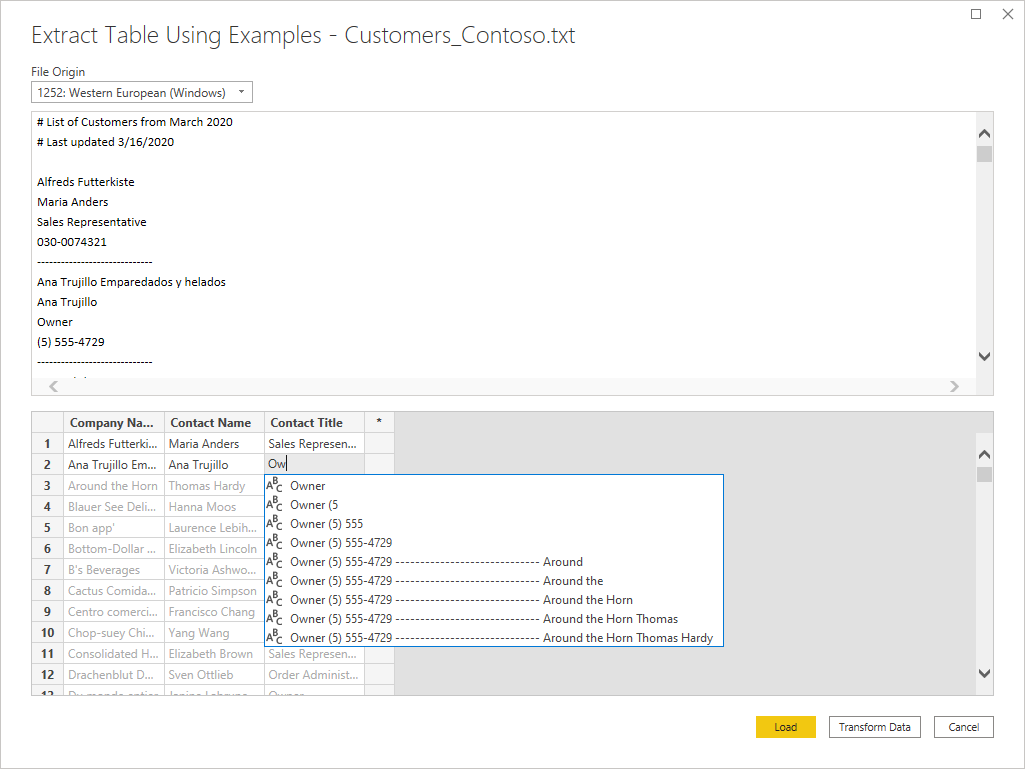
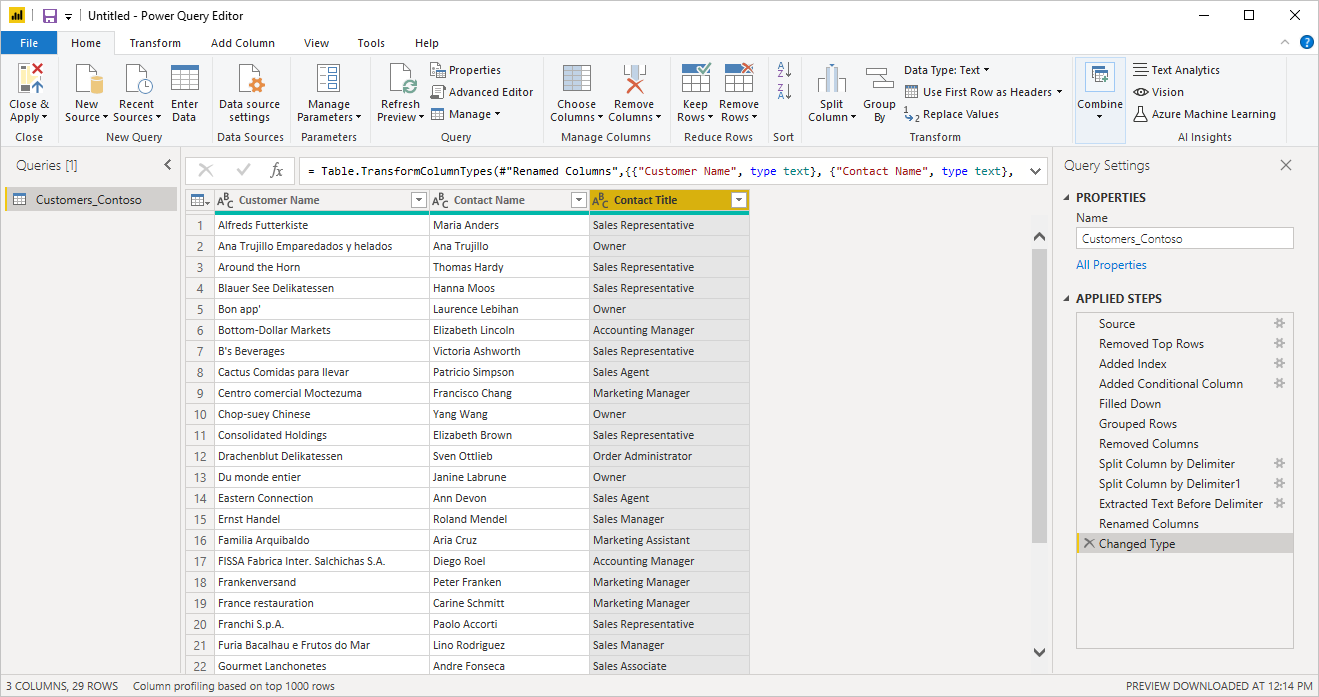
Po vytvoření této tabulky můžete buď vybrat načtení nebo transformaci dat. Všimněte si, že výsledné dotazy obsahují podrobný rozpis všech kroků odvozených pro extrakci dat. Tyto kroky jsou jen běžné kroky dotazu, které můžete podle potřeby přizpůsobit.
Řešení problému
Načítání souborů z webu
Pokud požadujete textové soubory nebo soubory CSV z webu a také podporujete hlavičky a načítáte dostatek souborů, které potřebujete mít obavy o potenciální omezování, měli byste zvážit zabalení Web.Contents hovoru Binary.Buffer(). V takovém případě uložení souboru do vyrovnávací paměti před povýšením hlaviček způsobí, že soubor bude požadován pouze jednou.
Práce s velkými soubory CSV
Pokud pracujete s velkými soubory CSV v editoru Power Query Online, může se zobrazit vnitřní chyba. Doporučujeme nejprve pracovat se souborem CSV s menší velikostí, použít kroky v editoru a po dokončení změnit cestu k většímu souboru CSV. Tato metoda umožňuje pracovat efektivněji a snižuje pravděpodobnost, že v online editoru dojde k vypršení časového limitu. Neočekáváme, že během doby aktualizace narazíte na tuto chybu, protože umožňujeme delší dobu trvání časového limitu.
Nestrukturovaný text interpretovaný jako strukturovaný
Ve výjimečných případech může být dokument s podobnými čárkami v odstavcích interpretován jako CSV. Pokud k tomuto problému dojde, upravte krok Zdroj v editoru Power Query a v rozevíracím seznamu Otevřít soubor jako vyberte text místo souboru CSV.
Sloupce v Power BI Desktopu
Při importu souboru CSV vygeneruje Power BI Desktop sloupec=x (kde x je počet sloupců v souboru CSV během počátečního importu) jako krok v Editor Power Query. Pokud následně přidáte další sloupce a zdroj dat se nastaví na aktualizaci, všechny sloupce nad rámec počátečního počtu x sloupců se neaktualizuje.
Chyba: Připojení ion uzavřený hostitelem
Při načítání souborů Text/CSV z webového zdroje a zvýšení úrovně hlaviček může někdy dojít k následujícím chybám: "An existing connection was forcibly closed by the remote host" nebo "Received an unexpected EOF or 0 bytes from the transport stream." tyto chyby můžou být způsobené tím, že hostitel používá ochranná opatření a zavře připojení, které může být dočasně pozastaveno, například při čekání na jiné připojení ke zdroji dat pro připojení nebo operaci připojení. Chcete-li tyto chyby obejít, zkuste přidat Binary.Buffer (doporučeno) nebo Table.Buffer volání, které stáhne soubor, načte ho do paměti a okamžitě zavře připojení. To by mělo zabránit pozastavení během stahování a zabránit vynucení ukončení připojení před načtením obsahu.
Následující příklad ukazuje toto alternativní řešení. Toto ukládání do vyrovnávací paměti je potřeba provést před předáním výsledné tabulky do Table.PromoteHeaders.
- Původní:
Csv.Document(Web.Contents("https://.../MyFile.csv"))
- S
Binary.Buffer:
Csv.Document(Binary.Buffer(Web.Contents("https://.../MyFile.csv")))
- S
Table.Buffer:
Table.Buffer(Csv.Document(Web.Contents("https://.../MyFile.csv")))