Použití kaskádových parametrů ve stránkovaných sestavách
Tento článek je určen jako autor sestavy, která navrhuje stránkované sestavy Power BI. Poskytuje scénáře návrhu kaskádových parametrů. Kaskádové parametry jsou parametry sestavy se závislostmi. Když uživatel sestavy vybere hodnotu parametru (nebo hodnoty), použije se k nastavení dostupných hodnot pro jiný parametr.
Poznámka:
Úvod k kaskádovým parametrům a jejich konfiguraci se v tomto článku nezabývá. Pokud nejste plně obeznámeni s kaskádovými parametry, doporučujeme, abyste si nejdříve přečetli možnost Přidat kaskádové parametry do sestavy v Power BI Tvůrce sestav.
Scénáře návrhu
Existují dva scénáře návrhu pro použití kaskádových parametrů. Dají se efektivně využít k:
- Filtrování velkých sad položek
- Prezentace relevantních položek
Ukázková databáze
Příklady uvedené v tomto článku jsou založené na službě Azure SQL Database. Databáze zaznamenává operace prodeje a obsahuje různé tabulky, které ukládají prodejce, produkty a prodejní objednávky.
Tabulka s názvem Reseller ukládá jeden záznam pro každého prodejce a obsahuje mnoho tisíc záznamů. Tabulka Reseller obsahuje tyto sloupce:
- ResellerCode (celé číslo)
- ResellerName
- Country-Region (Země-oblast)
- State-Province (Kraj)
- Město
- PostalCode
Tabulka s názvem Sales je také. Ukládá záznamy prodejních objednávek a má relaci cizího klíče k tabulce Reseller ve sloupci ResellerCode .
Příklad požadavku
Existuje požadavek na vývoj sestavy profilu prodejce. Sestava musí být navržená tak, aby zobrazovala informace pro jednoho prodejce. Není vhodné, aby uživatel sestavy zadal kód prodejce, protože si ho jen zřídka pamatuje.
Filtrování velkých sad položek
Podívejme se na tři příklady, které vám pomůžou omezit velké sady dostupných položek, jako jsou prodejci. Mezi ně patří:
- Filtrování podle souvisejících sloupců
- Filtrování podle sloupce seskupení
- Filtrovat podle vzoru hledání
Filtrování podle souvisejících sloupců
V tomto příkladu uživatel sestavy pracuje s pěti parametry sestavy. Musí vybrat zemi,kraj, město a psč. Konečný parametr pak zobrazí seznam prodejců, kteří se nacházejí v tomto zeměpisném umístění.
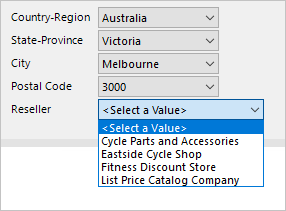
Tady je postup, jak můžete vyvíjet kaskádové parametry:
Vytvořte pět parametrů sestavy seřazených ve správném pořadí.
Pomocí následujícího příkazu dotazu vytvořte datovou sadu CountryRegion, která načítá jedinečné hodnoty zemí a oblastí:
SELECT DISTINCT [Country-Region] FROM [Reseller] ORDER BY [Country-Region]Pomocí následujícího příkazu dotazu vytvořte datovou sadu StateProvince, která načte jedinečné hodnoty krajů pro vybranou zemi a oblast:
SELECT DISTINCT [State-Province] FROM [Reseller] WHERE [Country-Region] = @CountryRegion ORDER BY [State-Province]Pomocí následujícího příkazu dotazu vytvořte datovou sadu City, která načítá jedinečné hodnoty města pro vybranou oblast a kraj státu:
SELECT DISTINCT [City] FROM [Reseller] WHERE [Country-Region] = @CountryRegion AND [State-Province] = @StateProvince ORDER BY [City]Pokračujte tímto vzorem a vytvořte datovou sadu PSČ .
Pomocí následujícího příkazu dotazu vytvořte datovou sadu Reseller, která načte všechny prodejce pro vybrané geografické hodnoty:
SELECT [ResellerCode], [ResellerName] FROM [Reseller] WHERE [Country-Region] = @CountryRegion AND [State-Province] = @StateProvince AND [City] = @City AND [PostalCode] = @PostalCode ORDER BY [ResellerName]Pro každou datovou sadu kromě první namapujte parametry dotazu na odpovídající parametry sestavy.
Poznámka:
Všechny parametry dotazu (předpona symbolu @), které jsou uvedené v těchto příkladech, můžou být vloženy do příkazů SELECT nebo předány uloženým procedurám.
Obecně platí, že uložené procedury představují lepší přístup k návrhu. Je to proto, že jejich plány dotazů se ukládají do mezipaměti pro rychlejší spouštění a umožňují v případě potřeby vyvíjet sofistikovanější logiku. V současné době ale nejsou podporované pro relační zdroje dat brány, což znamená SQL Server, Oracle a Teradata.
Nakonec byste měli vždy zajistit, aby existovaly vhodné indexy pro podporu efektivního načítání dat. Jinak by parametry sestavy mohly být pomalé a databáze by se mohla přetížit. Další informace o indexování SYSTÉMU SQL Server naleznete v tématu Architektura a návrh sql Serveru Průvodce návrhem.
Filtrování podle sloupce seskupení
V tomto příkladu uživatel sestavy komunikuje s parametrem sestavy a vybere první písmeno prodejce. Druhý parametr pak zobrazí seznam prodejců, když název začíná vybraným písmenem.
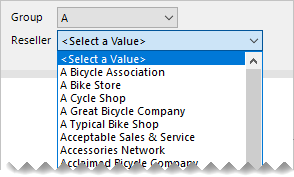
Tady je postup, jak můžete vyvíjet kaskádové parametry:
Vytvořte parametry sestavy ReportGroup a Reseller seřazené ve správném pořadí.
Pomocí následujícího příkazu dotazu vytvořte datovou sadu ReportGroup, která načte první písmena používaná všemi prodejci:
SELECT DISTINCT LEFT([ResellerName], 1) AS [ReportGroup] FROM [Reseller] ORDER BY [ReportGroup]Vytvořte datovou sadu Reseller pro načtení všech prodejců, kteří začínají vybraným písmenem, pomocí následujícího příkazu dotazu:
SELECT [ResellerCode], [ResellerName] FROM [Reseller] WHERE LEFT([ResellerName], 1) = @ReportGroup ORDER BY [ResellerName]Namapujte parametr dotazu datové sady Reseller na odpovídající parametr sestavy.
Přidání sloupce seskupování do tabulky Reseller je efektivnější. Při zachování a indexování zajistí nejlepší výsledek. Další informace naleznete v tématu Určení počítaných sloupců v tabulce.
ALTER TABLE [Reseller]
ADD [ReportGroup] AS LEFT([ResellerName], 1) PERSISTED
Tato technika může přinést ještě větší potenciál. Zvažte následující skript, který přidá nový sloupec seskupení pro filtrování prodejců podle předem definovaných pásem písmen. Vytvoří také index, který efektivně načte data požadovaná parametry sestavy.
ALTER TABLE [Reseller]
ADD [ReportGroup2] AS CASE
WHEN [ResellerName] LIKE '[A-C]%' THEN 'A-C'
WHEN [ResellerName] LIKE '[D-H]%' THEN 'D-H'
WHEN [ResellerName] LIKE '[I-M]%' THEN 'I-M'
WHEN [ResellerName] LIKE '[N-S]%' THEN 'N-S'
WHEN [ResellerName] LIKE '[T-Z]%' THEN 'T-Z'
ELSE '[Other]'
END PERSISTED
GO
CREATE NONCLUSTERED INDEX [Reseller_ReportGroup2]
ON [Reseller] ([ReportGroup2]) INCLUDE ([ResellerCode], [ResellerName])
GO
Filtrovat podle vzoru hledání
V tomto příkladu uživatel sestavy komunikuje s parametrem sestavy, aby zadal vzor hledání. Druhý parametr pak zobrazí seznam prodejců, pokud název obsahuje vzor.
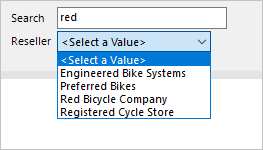
Tady je postup, jak můžete vyvíjet kaskádové parametry:
Vytvořte parametry sestavy Vyhledávání a prodejce seřazené ve správném pořadí.
Vytvořte datovou sadu Reseller pro načtení všech prodejců, kteří obsahují hledaný text, pomocí následujícího příkazu dotazu:
SELECT [ResellerCode], [ResellerName] FROM [Reseller] WHERE [ResellerName] LIKE '%' + @Search + '%' ORDER BY [ResellerName]Namapujte parametr dotazu datové sady Reseller na odpovídající parametr sestavy.
Tip
Tento návrh můžete vylepšit, abyste uživatelům sestavy poskytli větší kontrolu. Umožňuje jim definovat vlastní hodnotu porovnávání vzorů. Například vyhledávací hodnota "red%" vyfiltruje prodejce s názvy, které začínají znaky "červená".
Další informace najdete v tématu LIKE (Transact-SQL).
Tady je postup, jak uživatelům sestavy umožnit definovat vlastní vzor.
WHERE
[ResellerName] LIKE @Search
Mnoho odborníků, kteří nejsou databázemi, ale neví o procentech zástupných znaků (%). Místo toho znají hvězdičku (*). Úpravou klauzule WHERE je můžete nechat používat tento znak.
WHERE
[ResellerName] LIKE SUBSTITUTE(@Search, '%', '*')
Prezentace relevantních položek
V tomto scénáři můžete pomocí dat faktů omezit dostupné hodnoty. Uživatelům sestavy se zobrazí položky, ve kterých byla zaznamenána aktivita.
V tomto příkladu uživatel sestavy pracuje se třemi parametry sestavy. První dva nastaví rozsah kalendářních dat prodejních objednávek. Třetí parametr pak vypíše prodejce, ve kterých byly objednávky vytvořeny během tohoto časového období.
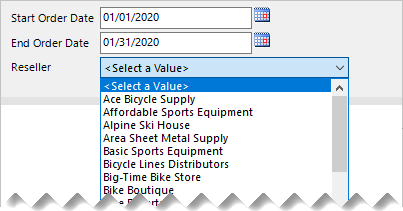
Tady je postup, jak můžete vyvíjet kaskádové parametry:
Vytvořte parametry sestavy OrderDateStart, OrderDateEnd a Reseller seřazené ve správném pořadí.
Vytvořte datovou sadu Reseller pro načtení všech prodejců, kteří v období data vytvořili objednávky, pomocí následujícího příkazu dotazu:
SELECT DISTINCT [r].[ResellerCode], [r].[ResellerName] FROM [Reseller] AS [r] INNER JOIN [Sales] AS [s] ON [s].[ResellerCode] = [r].[ResellerCode] WHERE [s].[OrderDate] >= @OrderDateStart AND [s].[OrderDate] < DATEADD(DAY, 1, @OrderDateEnd) ORDER BY [r].[ResellerName]
Doporučení
Sestavy doporučujeme navrhovat s kaskádovými parametry, kdykoli je to možné. Je to proto, že:
- Poskytování intuitivních a užitečných prostředí pro uživatele sestavy
- Jsou efektivní, protože načítají menší sady dostupných hodnot.
Nezapomeňte optimalizovat zdroje dat podle:
- Kdykoli je to možné, pomocí uložených procedur
- Přidání vhodných indexů pro efektivní načítání dat
- Materializace hodnot sloupců (a dokonce řádků), aby se zabránilo drahým vyhodnocením doby dotazu
Související obsah
Další informace týkající se tohoto článku najdete v následujících zdrojích informací: