Konfigurace automatických agregací
Konfigurace automatických agregací zahrnuje povolení trénování pro podporovaný sémantický model DirectQuery a konfiguraci jedné nebo více plánovaných aktualizací. Po spuštění několika iterací operací trénování a aktualizace se můžete vrátit k nastavení sémantického modelu a doladit procento dotazů sestav, které používají mezipaměť agregací v paměti. Před dokončením těchto kroků se ujistěte, že plně rozumíte funkcím a omezením popsaným v automatických agregacích.
Povolit
Abyste mohli povolit automatické agregace, musíte mít oprávnění vlastníka sémantického modelu. Správci pracovního prostoru můžou převzít oprávnění vlastníka modelu.
V sémantickém modelu Nastavení rozbalte plánovanou aktualizaci a optimalizaci výkonu.
Přepněte automatické trénování agregací na Zapnuto. Pokud je přepínač neaktivní, ujistěte se, že jsou nakonfigurované přihlašovací údaje ke zdroji dat a jste přihlášení.

V plánu aktualizace zadejte frekvenci aktualizace a časové pásmo. Pokud jsou ovládací prvky plánu aktualizace zakázané, ověřte konfiguraci zdroje dat, včetně připojení brány (v případě potřeby) a přihlašovacích údajů ke zdroji dat.
Vyberte Přidat jiný čas a pak zadejte jednu nebo více aktualizací.
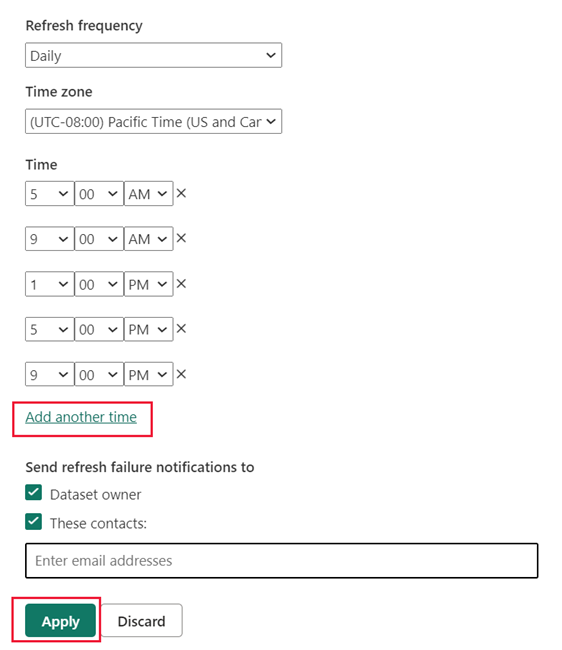
Musíte naplánovat aspoň jednu aktualizaci. První aktualizace vybrané frekvence bude zahrnovat jak operaci trénování , tak aktualizaci, která načte nové a aktualizované agregace do mezipaměti v paměti. Naplánujte další aktualizace, aby se zajistilo, že dotazy sestavy, které narazí na mezipaměť agregací, získávají výsledky, které jsou nejvíce synchronizované s back-endovým zdrojem dat. Další informace najdete v tématu Operace aktualizace.
Vyberte Použít.
Trénování a aktualizace na vyžádání
První naplánovaná operace aktualizace pro zvolenou frekvenci zahrnuje operaci trénování. Pokud se tato operace trénování nedokončí během 60minutového časového limitu, následná operace aktualizace se nenačte ani neaktualizuje agregace v mezipaměti. Další operace trénování se nespustí až do první operace aktualizace zvolené frekvence.
V takových případech můžete ručně spustit jednu nebo více operací trénování a aktualizace na vyžádání , abyste plně dokončili trénování a načítání nebo aktualizace agregací v mezipaměti. Pokud se například při kontrole historie aktualizace nedokončí první naplánovaná operace trénování a aktualizace dne (frekvence) v časovém limitu a nechcete čekat na naplánovanou aktualizaci dalšího dne, která zahrnuje spuštění trénovací operace, můžete spustit jednu nebo více operací trénování a aktualizace na vyžádání, abyste plně zpracovali protokol datových dotazů (trénování) a agregace načítání do mezipaměti (aktualizace).
Pokud chcete spustit operaci trénování a aktualizace na vyžádání, vyberte Možnost Trénovat a Aktualizovat hned. Nezapomeňte sledovat historii aktualizací, abyste zajistili úspěšné dokončení operace trénování na vyžádání. Pokud ne, spusťte další operaci trénování a aktualizace, dokud se trénování úspěšně nedokončí, a agregace se načtou nebo aktualizují v mezipaměti.
Spuštění trénování a aktualizace teď může být užitečné pro vyladění procenta dotazů sestavy, které budou používat agregace z mezipaměti v paměti. Spuštěním operace trénování a aktualizace na vyžádání teď můžete rychleji zjistit, jestli nové nastavení procenta umožňuje dokončení trénovací operace v rámci časového limitu.
Mějte na paměti, operace trénování a aktualizace, ať už plánované nebo na vyžádání, jsou pro zdroj dat i Power BI náročné na prostředky. Vyberte čas, kdy jsou prostředky nejméně ovlivněné.
Vyladění
Tabulky agregací generovaných uživatelem i systémem jsou součástí modelu, přispívají k velikosti modelu a podléhají stávajícím omezením velikosti modelu Power BI. Zpracování agregací také spotřebovává prostředky a ovlivňuje dobu trvání aktualizace modelu. Optimální konfigurace představuje rovnováhu mezi poskytováním předem agregovaných výsledků z mezipaměti agregací v paměti pro nejčastěji používané dotazy sestavy a zároveň přijímá pomalejší výsledky pro odlehlé a ad hoc dotazy výměnou za rychlejší trénování a aktualizaci a nižší zátěž systémových prostředků.
Úprava procenta
Ve výchozím nastavení nastavení mezipaměti agregací určující procento dotazů sestavy, které budou používat agregace z mezipaměti v paměti, je 75 %. Zvýšení procent znamená, že větší počet dotazů sestavy je seřazený výš, a proto jsou agregace zahrnuté do mezipaměti agregací v paměti. Vyšší procento sice může znamenat, že z mezipaměti v paměti odpovídá více dotazů, ale může to také znamenat delší dobu trénování a aktualizace. Úprava na nižší procento může na druhou stranu znamenat kratší dobu trénování a aktualizace a menší využití prostředků, ale výkon vizualizace sestavy by mohl snížit, protože mezipaměť agregací v paměti odpovídá méně dotazů na sestavy, protože tyto dotazy sestavy místo toho musí přecházet do zdroje dat.
Aby systém mohl určit optimální agregace, které se mají zahrnout do mezipaměti, musí nejprve znát vzory dotazů sestavy, které se používají nejčastěji. Před úpravou procenta dotazů, které budou používat mezipaměť agregací, nezapomeňte dokončit několik iterací operací trénování/aktualizace. Díky tomu má trénovací algoritmus čas analyzovat dotazy sestavy v širším časovém období a odpovídajícím způsobem se přizpůsobit. Pokud jste například naplánovali aktualizace pro denní frekvenci, můžete chtít počkat celý týden. Vzory vytváření sestav uživatelů v některých dnech v týdnu se můžou lišit od jiných.
Úprava procenta
V sémantickém modelu Nastavení rozbalte plánovanou aktualizaci a optimalizaci výkonu.
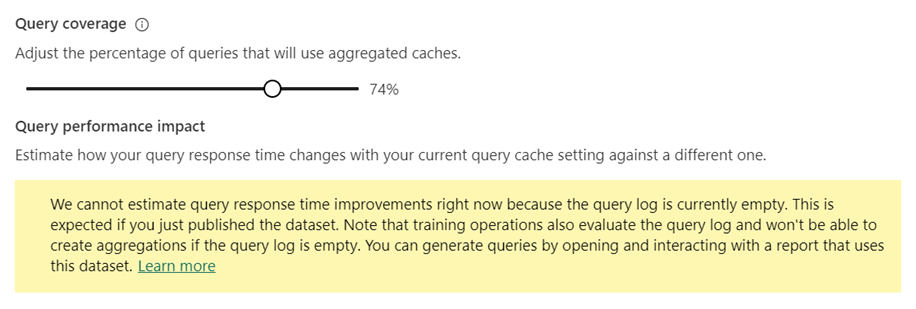
V pokrytí dotazů použijte možnost Upravit procento dotazů, které budou pomocí posuvníku agregovaných mezipamětí zvýšit nebo snížit procento na požadovanou hodnotu. Když upravíte procento, graf Query Performance Impact Lift poskytuje odhadované doby odezvy dotazů.
Vyberte Možnost Trénovat a Aktualizovat hned nebo Použít.
Odhad dopadu na výkon dotazů
Graf výtahu dopadu na výkon dotazů poskytuje odhadované doby spuštění dotazů sestavy jako funkci procenta dotazů, které budou používat agregace uložené v mezipaměti. Graf zpočátku zobrazí 0,0 pro všechny metriky, dokud se neprovede alespoň jedna operace trénování/aktualizace. Po počáteční operaci trénování/aktualizace vám může graf pomoct určit, jestli se upraví procento dotazů, které používají mezipaměť agregací v paměti, může potenciálně zlepšit odpověď na dotazy.
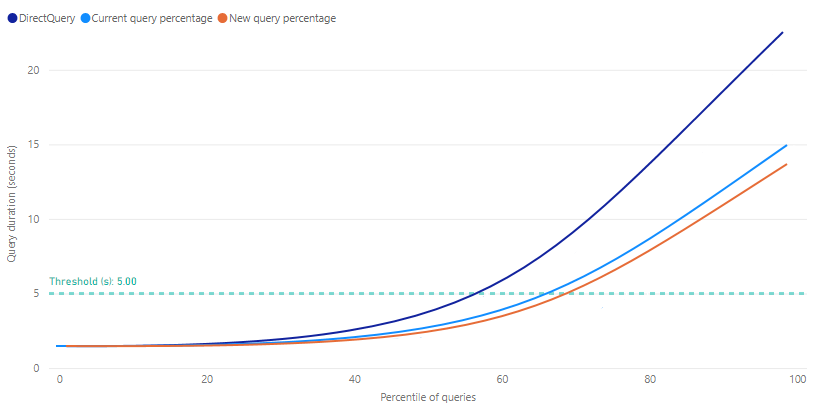
Prahová hodnota se v grafu výtahu zobrazí jako čára značky a označuje dobu odezvy cílového dotazu pro sestavy. Pak můžete vyladit procento dotazů, které budou používat mezipaměť agregací, a určit tak nové procento dotazu, které splňuje požadovanou prahovou hodnotu.
Metriky
DirectQuery – odhadovaná doba trvání dotazu sestavy odeslaného do zdroje dat a vrácená z zdroje dat pomocí DirectQuery. Dotazy, na které není možné odpovědět v mezipaměti agregací v paměti, obvykle budou v rámci tohoto odhadu.
Procento aktuálního dotazu – odhadovaná doba trvání pro dotazy sestavy zodpovězené z mezipaměti agregací v paměti na základě procentuálního nastavení poslední operace trénování/aktualizace.
Nové procento dotazu – odhadovaná doba trvání pro dotazy sestavy zodpovězené z mezipaměti agregací v paměti pro nově vybrané procento. Když se změní posuvník procent, tato metrika odráží potenciální změnu.
Zakázat
K zakázání automatických agregací musíte mít oprávnění vlastníka modelu. Správci pracovního prostoru můžou převzít oprávnění vlastníka modelu.
Pokud chcete zakázat, přepněte automatické trénování agregací na vypnuto.
Když zakážete trénování, zobrazí se výzva k odstranění automatických tabulek agregace.
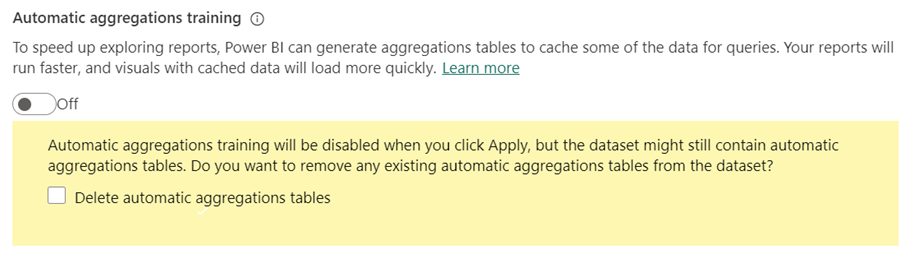
Pokud se rozhodnete neodstraňovat existující tabulky automatické agregace, zůstanou tabulky v modelu a budou se i nadále aktualizovat. Protože je ale trénování zakázané, nebudou do nich přidány žádné nové agregace. Power BI bude dál používat existující tabulky k získání agregovaných výsledků dotazu, pokud je to možné.
Pokud se rozhodnete tabulky odstranit, model se vrátí do původního stavu bez automatických agregací.
Vyberte Použít.