Vzorkování čar s vysokou hustotou v Power BI
Algoritmus vzorkování v Power BI zlepšuje vizuály, které vzorkují data s vysokou hustotou. Můžete například vytvořit spojnicový graf z výsledků prodeje maloobchodních obchodů, přičemž každý obchod má každý rok více než 10 000 účtenek za prodej. Spojnicový graf těchto informací o prodeji by vzorkoval data z dat pro každé úložiště a vytvořil spojnicový graf s více řadami, který představuje podkladová data. Nezapomeňte vybrat smysluplnou reprezentaci těchto dat, abyste mohli ilustrovat, jak se prodeje v průběhu času liší. Tento postup je běžný při vizualizaci dat s vysokou hustotou. Podrobnosti o vzorkování dat s vysokou hustotou jsou popsány v tomto článku.
Poznámka:
Algoritmus vzorkování s vysokou hustotou popsaný v tomto článku je k dispozici v Power BI Desktopu i v služba Power BI.
Jak funguje vzorkování čar s vysokou hustotou
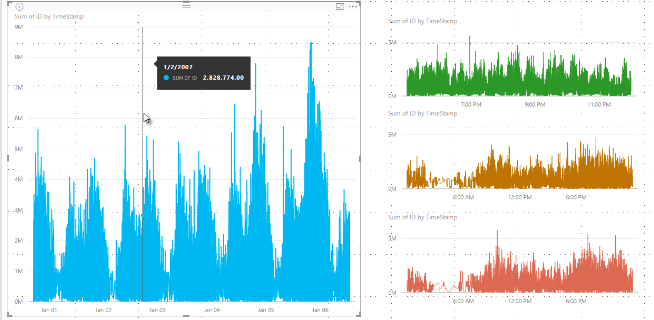
Power BI dříve vybral kolekci ukázkových datových bodů v celé oblasti podkladových dat deterministickým způsobem. Například s daty s vysokou hustotou ve vizuálu zahrnujícím jeden kalendářní rok může být ve vizuálu zobrazeno 350 ukázkových datových bodů, z nichž každý byl vybrán, aby se zajistilo, že se ve vizuálu zobrazí celý rozsah dat. Abyste pochopili, jak k tomu dojde, představte si, že vykresluje cenu akcií za jednoleté období a vyberete 365 datových bodů, abyste vytvořili vizuál spojnicového grafu. To je jeden datový bod pro každý den.
V této situaci existuje mnoho hodnot pro cenu akcií v každém dni. Samozřejmě, že existuje denní maximum a minimum, ale k nim může dojít kdykoli během dne, kdy je burzovní trh otevřený. V případě vzorkování čar s vysokou hustotou byste získali reprezentativní snímek podkladových dat v 10:30 a 12:00 každý den, například cenu v 10:30 a 12:00. Snímek ale nemusí zachytávat skutečnou vysokou a nízkou cenu akcií pro tento reprezentativní datový bod v daném dni. V takové situaci a dalších je vzorkování reprezentativní pro podkladová data, ale vždy nezachytává důležité body, což by v tomto případě bylo denním maximem cen akcií a nízkými hodnotami.
Podle definice se data s vysokou hustotou vzorkují tak, aby vytvářela vizualizace přiměřeně rychle, které reagují na interaktivitu. Příliš mnoho datových bodů ve vizuálu ho může zmát a může od viditelnosti trendů snížit. Způsob vzorkování dat je to, co řídí vytvoření algoritmu vzorkování tak, aby poskytovalo nejlepší prostředí pro vizualizaci. V Power BI Desktopu poskytuje algoritmus nejlepší kombinaci odezvy, reprezentace a zachování důležitých bodů v každém časovém řezu.
Jak funguje nový algoritmus vzorkování čar
Algoritmus vzorkování čar s vysokou hustotou je k dispozici pro vizuály spojnicového a plošného grafu s souvislou osou X.
V případě vizuálu s vysokou hustotou Power BI inteligentně rozdělí data do bloků s vysokým rozlišením a pak vybere důležité body, které představují jednotlivé bloky dat. Tento proces vytváření řezů dat s vysokým rozlišením je vyladěn, aby se zajistilo, že výsledný graf je vizuálně nerozlišitelný od vykreslování všech podkladových datových bodů, ale je rychlejší a interaktivnější.
Minimální a maximální hodnoty pro vizuály čar s vysokou hustotou
Pro každou vizualizaci platí následující omezení:
3 500 je maximální počet datových bodů zobrazených ve většině vizuálů bez ohledu na počet podkladových datových bodů nebo řad, viz výjimky v následujícím seznamu. Pokud máte například 10 řad s 350 datovými body, vizuál dosáhl maximálního celkového limitu datových bodů. Pokud máte jednu řadu, může mít až 3 500 datových bodů, pokud algoritmus považuje za nejlepší vzorkování podkladových dat.
Pro libovolný vizuál je maximálně 60 řad . Pokud máte více než 60 řad, rozdělte data a vytvořte několik vizuálů s 60 nebo méně řadami. Doporučujeme použít průřez k zobrazení jenom segmentů dat, ale jenom pro určité řady. Pokud například v legendě zobrazujete všechny podkategorie, můžete použít průřez k filtrování podle celkové kategorie na stejné stránce sestavy.
Maximální počet datových limitů je vyšší pro následující typy vizuálů, což jsou výjimky z limitu 3 500 datových bodů:
- Maximálně 150 000 datových bodů pro vizuály R
- 30 000 datových bodů pro vizuály Azure Map
- 10 000 datových bodů pro některé konfigurace bodového grafu (bodové grafy jsou ve výchozím nastavení 3500).
- 3 500 pro všechny ostatní vizuály pomocí vzorkování s vysokou hustotou Některé další vizuály můžou vizualizovat více dat, ale nebudou používat vzorkování.
Tyto parametry zajišťují, aby se vizuály v Power BI Desktopu vykreslují rychle, reagovaly na interakci s uživateli a nezpůsobily zbytečné výpočetní režijní náklady na počítač, který vizuál vykresluje.
Vyhodnocení reprezentativních datových bodů pro vizuály čar s vysokou hustotou
Pokud počet podkladových datových bodů překročí maximální počet datových bodů, které lze ve vizuálu znázornět, zahájí se proces s názvem binning . Binning rozdělí podkladová data do skupin označovaných jako intervaly a pak tyto intervaly iterativním způsobem zpřesní.
Algoritmus vytvoří co nejvíce intervalů, aby vytvořil největší členitost vizuálu. V rámci každé přihrádky algoritmus najde minimální a maximální hodnotu dat, aby se zajistilo, že se ve vizuálu zachytí a zobrazí důležité a významné hodnoty, jako jsou odlehlé hodnoty. Na základě výsledků binningu a následného vyhodnocení dat v Power BI se určí minimální rozlišení osy x vizuálu, aby se zajistilo maximální členitost vizuálu.
Jak jsme zmínili dříve, minimální členitost každé řady je 350 bodů a maximum je pro většinu vizuálů 3 500. Výjimky jsou uvedeny v předchozích odstavcích.
Každý interval je reprezentován dvěma datovými body, které se stanou reprezentativními datovými body přihrádky ve vizuálu. Datové body jsou vysokou a nízkou hodnotou pro danou přihrádku. Když vyberete vysokou a nízkou hodnotu, proces binningu zajistí, že se ve vizuálu zachytí a vykreslí jakákoli důležitá vysoká nebo významná nízká hodnota.
Pokud to zní jako spousta analýz, abyste zajistili, že se občasná odlehlé hodnoty zachytí a správně zobrazí ve vizuálu, jste správní. To je přesný důvod algoritmu a procesu binningu.
Popisy a vzorkování čar s vysokou hustotou
Je důležité si uvědomit, že tento proces binningu, jehož výsledkem je minimální a maximální hodnota v daném intervalu zachycená a zobrazená, může mít vliv na to, jak popisy zobrazují data při najetí myší na datové body. Abychom vysvětlili, jak a proč k tomu dochází, podívejme se na náš příklad cen akcií.
Řekněme, že vytváříte vizuál založený na cenách akcií a porovnáváte dvě různé akcie, z nichž obě používají vzorkování s vysokou hustotou. Podkladová data pro každou řadu mají mnoho datových bodů. Například možná zachytíte cenu akcií každou sekundu dne. Algoritmus vzorkování čar s vysokou hustotou provádí binning pro každou řadu nezávisle na druhé.
Teď řekněme, že první akcie vyskočí v ceně na 12:02 a pak se rychle vrátí zpět o 10 sekund později. To je důležitý datový bod. Když dojde k binningu pro danou zásobu, je nejvyšší hodnota v 12:02 reprezentativním datovým bodem pro danou přihrádku.
U druhé akcie však 12:02 nebyla vysoká ani nízká v intervalu, který tento čas zahrnoval. Možná došlo k vysokému a nízkému intervalu, který zahrnuje 12:02, o tři minuty později. Když se v takovém případě vytvoří spojnicový graf a najedete myší na 12:02, zobrazí se v popisu první akcie hodnota. Důvodem je to, že se skočilo na 12:02 a tato hodnota byla vybrána jako datový bod s vysokým datovým bodem v daném intervalu. V popisu se ale nezobrazí žádná hodnota v 12:02 pro druhou akcii. Je to proto, že druhá burza neměla pro koš vysoké nebo nízké hodnoty, které obsahovaly 12:02. Proto nejsou k dispozici žádná data pro druhou akcii v 12:02, a proto se nezobrazují žádná data popisu.
K této situaci často dochází pomocí popisů. Vysoké a nízké hodnoty pro konkrétní interval se pravděpodobně nebudou přesně shodovat s rovnoměrně škálovanými body hodnot osy x a popis nezobrazí hodnotu.
Zapnutí vzorkování čar s vysokou hustotou
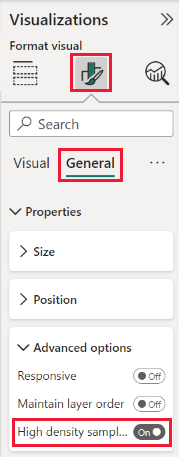
Ve výchozím nastavení je algoritmus zapnutý. Pokud chcete toto nastavení změnit, přejděte do podokna Formátování, na kartě Obecné a v dolní části se zobrazí posuvník vzorkování s vysokou hustotou. Výběrem posuvníku zapněte nebo vypněte.
Úvahy a omezení
Algoritmus vzorkování čar s vysokou hustotou je důležitým vylepšením Power BI, ale při práci s hodnotami a daty s vysokou hustotou je potřeba vědět několik aspektů.
Kvůli zvýšené členitosti a procesu binningu můžou popisy zobrazovat hodnotu pouze v případě, že jsou reprezentativní data zarovnaná s kurzorem. Další informace najdete v části Popisy a vzorkování čar s vysokou hustotou v tomto článku.
Pokud je velikost celkového zdroje dat příliš velká, algoritmus eliminuje řadu (prvky legendy), aby vyhovoval maximálnímu omezení importu dat.
- V této situaci algoritmus objednává řadu legend abecedně, počínaje seznamem prvků legendy v abecedním pořadí, dokud nedosáhne maximálního počtu importu dat, a neimportuje další řady.
Pokud má podkladová datová sada více než 60 řad, algoritmus řadí řadu abecedně a eliminuje řadu nad 60. abecedně seřazenou řadu.
Pokud hodnoty v datech nejsou typu číselné nebo datum a čas, Power BI tento algoritmus nepoužije a vrátí se k předchozímu algoritmu vzorkování bez vysoké hustoty.
Algoritmus nepodporuje možnosti Zobrazit položky bez nastavení dat .
Algoritmus se nepodporuje při použití živého připojení k modelu hostovaného v Služba Analysis Services serveru SQL verzi 2016 nebo starší. Podporuje se v modelech hostovaných v Power BI nebo Azure Analysis Services.