Akce OCR
Power Automate umožňuje uživatelům číst, extrahovat a spravovat data v souborech prostřednictvím optického rozpoznávání znaků (OCR).
Chcete-li vytvořit modul OCR a extrahovat text z obrázků a dokumentů, použijte akci Extrahovat text pomocí OCR. Následující příklad extrahuje text z celého zadaného obrázku.
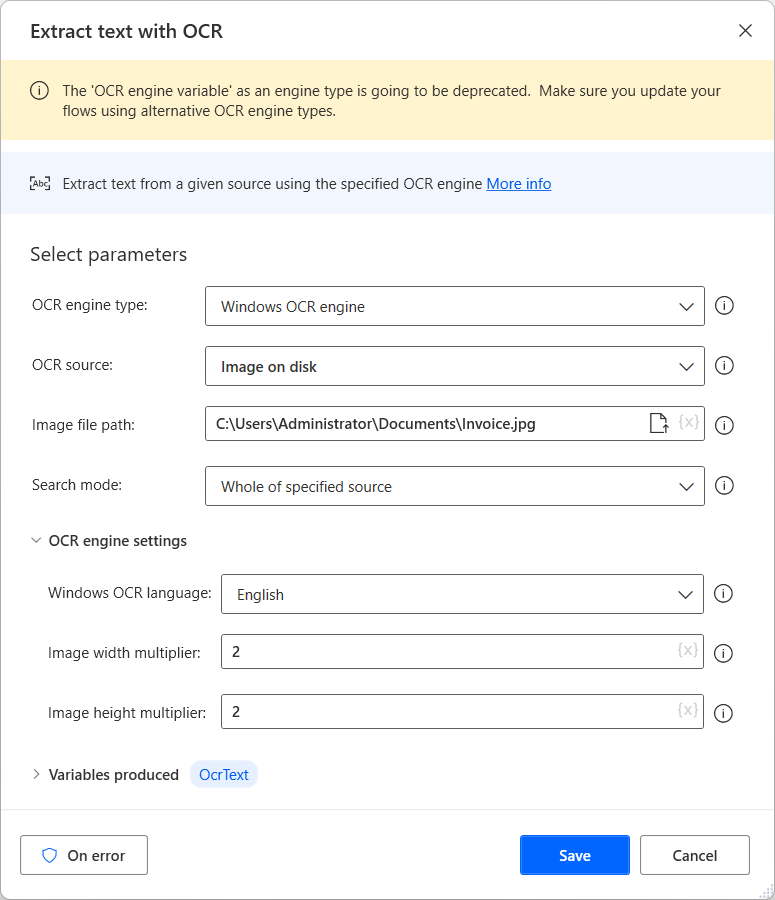
Všechny akce OCR mohou vytvořit novou proměnnou modulu OCR nebo použít existující. Proměnné modulu OCR můžete použít v jakékoli akci nabízející funkce OCR.
Power Automate podporuje modul Windows OCR i modul Tesseract. Chcete-li nakonfigurovat vybraný modul OCR, přejděte na nastavení modulu OCR příslušné akce. Mezi dostupné možnosti patří jazyk a multiplikátory šířky a výšky obrazu.
Poznámka:
- Všechny dostupné moduly OCR jsou předinstalované v Power Automate a pracují lokálně bez připojení ke cloudu. K extrahování textů v určitých jazycích však možná budete muset stáhnout jazykové balíčky nebo datové soubory.
- Multiplikátory obrázků zvětšují velikost obrázku, aby bylo efektivnější vyhledávání a extrakce textu. Nastavení hodnot větších než 3 může vést k chybným výsledkům.
Použití modulu Windows OCR
Výchozí modul OCR v Power Automate je modul Windows OCR. Chcete-li extrahovat texty pomocí modulu Windows OCR, musíte nainstalovat příslušný jazykový balíček pro jazyk, který chcete extrahovat.
Pokud nebyl nainstalován příslušný jazykový balíček, Power Automate zobrazí chybu s výzvou k instalaci. Další informace o stahování a instalaci jazykových balíčků naleznete v části Jazykové balíčky pro Windows.
Po instalaci příslušného jazykového balíčku rozšiřte Nastavení modulu OCR akce OCR a vyberte požadovaný jazyk. Modul Windows OCR podporuje 25 jazyků: čínštinu (zjednodušenou a tradiční), češtinu, dánštinu, nizozemštinu, angličtinu, finštinu, francouzštinu, němčinu, řečtinu, maďarštinu, italštinu, japonštinu, korejštinu, norštinu, polštinu, portugalštinu, rumunštinu, ruštinu, srbštinu (cyrilice a latinka), slovenštinu, španělštinu, švédštinu a turečtinu.
Použití modulu Tesseract OCR
Poznámka:
Chcete-li použít modul OCR Tesseract, ujistěte se, že CPU počítače podporuje sadu instrukcí AVX2.
Kromě modulu Windows OCR Power Automate podporuje modul Tesseract. Tento engine dokáže extrahovat text v pěti jazycích bez další konfigurace: angličtině, němčině, španělštině, francouzštině a italštině.
Chcete-li extrahovat text v jazyce mimo uvedený seznam, povolte možnost Používat jiné jazyky v Nastavení modulu OCR akce OCR. Když je tato možnost aktivní, akce zobrazí dva další parametry: Zkratka jazyka a Datová cesta jazyka.
Pole Zkratka jazyka označuje stroji, který jazyk má během OCR hledat. Pole Cesta dat jazyka obsahuje jazykové datové soubory (.traineddata) používané k trénování stroje OCR. Jazykové datové soubory pro všechny dostupné jazyky naleznete v tomto úložišti GitHub.
Můžete také použít modul Tesseract lze k extrahování textu z vícejazyčných dokumentů. Další informace o extrahování textu z vícejazyčných dokumentů naleznete v části Provádění OCR na vícejazyčných dokumentech.
Pokud text na obrazovce (OCR)
Označí začátek podmíněného bloku akcí v závislosti na tom, zda se daný text zobrazí na obrazovce, s použitím OCR.
Vstupní parametry
| Argument | Volitelné | Přijímá | Výchozí hodnota | Description |
|---|---|---|---|---|
| If text | Není k dispozici | Existuje, neexistuje | Existuje | Určuje, zda zkontrolovat, jestli existuje text na daném zdroji k analýze |
| Typ modulu OCR | Ne | Modul Windows OCR, modul Tesseract, proměnná modulu OCR | Proměnná modulu OCR | Typ stroje OCR, který se má použít. Vyberte předkonfigurovaný modul OCR nebo nastavte nový. |
| OCR engine variable | Ne | OCREngineObject | Modul, který se má použít pro operaci OCR | |
| Text to find | Ne | Textová hodnota | Text, který se má vyhledat v zadaném zdroji | |
| Is regular expression | Není k dispozici | Logická hodnota | False | Určuje, zda použít regulární výraz k nalezení zadaného textu |
| Search for text on | Není k dispozici | Celá obrazovka, okno popředí | Celá obrazovka | Určuje, zda vyhledat zadaný text na celé viditelné obrazovce, nebo pouze v okně v popředí |
| Search mode | – | Celý zadaný zdroj, pouze konkrétní podoblast, podoblast vzhledem k obrázku | Celý zadaný zdroj | Určuje, zda prohledat celou obrazovku (nebo okno), nebo jen její zúženou podoblast |
| Image(s) | Ne | Seznamsnímků | Obrázky určující podoblast (relativní k levému hornímu rohu obrázku), ve které se má vyhledat zadaný text | |
| X1 | Ano | Číselná hodnota | Počáteční souřadnice X podoblasti, ve které se má vyhledat zadaný text | |
| Tolerance | Ano | Číselná hodnota | 10 | Určuje, do jaké míry se může hledaný obrázek lišit od původně vybraného obrázku |
| Y1 | Ano | Číselná hodnota | Počáteční souřadnice Y podoblasti, ve které se má vyhledat zadaný text | |
| X1 | Ano | Číselná hodnota | Počáteční souřadnice X podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| X2 | Ano | Číselná hodnota | Koncová souřadnice X podoblasti, ve které se má vyhledat zadaný text | |
| Y1 | Ano | Číselná hodnota | Počáteční souřadnice Y podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| Y2 | Ano | Číselná hodnota | Koncová souřadnice Y podoblasti, ve které se má vyhledat zadaný text | |
| X2 | Ano | Číselná hodnota | Koncová souřadnice X podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| Y2 | Ano | Číselná hodnota | Koncová souřadnice Y podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| Jazyk modulu Windows OCR | Neuvedeno | Čínština (zjednodušená), čínština (tradiční), čeština, dánštinu, nizozemština, angličtina, finština, francouzština, němčina, řečtina, maďarština, italština, japonština, korejština, norština, polština, portugalština, rumunština, ruština, srbština (cyrilice), srbština (latinka), slovenština, španělština, švédština, turečtina | Angličtina | Jazyk textu, který modul Windows OCR rozpozná |
| Použít jiný jazyk | Neuvedeno | Logická hodnota | False | Určuje, jestli se má použít jazyk, který není uveden v poli Jazyk modulu Tesseract |
| Jazyk Tesseract | Neuvedeno | Angličtina, němčina, španělština, francouzština, italština | Angličtina | Jazyk textu, který modul Tesseract detekuje |
| Zkratka jazyka | Ne | Textová hodnota | Zkratka Tesseract jazyka, který se má použít. Pokud jsou například data „eng.traineddata“, nastavte parametr na „eng“ | |
| Cesta k datům jazyka | Ne | Textová hodnota | Cesta ke složce, která obsahuje data Tesseract v zadaném jazyce | |
| Násobitel šířky obrázku | Ne | Číselná hodnota | 1 | Násobitel šířky obrázku |
| Násobitel výšky obrázku | Ne | Číselná hodnota | 1 | Násobitel výšky obrázku |
| Algoritmus určení shody obrázku | – | Základní, Rozšířený | Základní | Obrazový algoritmus, který se má použít při hledání obrázků |
Poznámka:
- Modul regulárních výrazů Power Automate je .NET. Více informací o regulárních výrazech naleznete v článku Jazyk regulárních výrazů – rychlý průvodce.
- Možnost Proměnná modulu OCR je plánována na ukončení podpory.
Vytvořené proměnné
| Argument | Type | Description |
|---|---|---|
| LocationOfTextFoundX | Číselná hodnota | Souřadnice X bodu, kde se text nachází na obrazovce. Pokud se hledání provádí v popředí, vrácená souřadnice je relativní k levému hornímu rohu okna |
| LocationOfTextFoundY | Číselná hodnota | Souřadnice X bodu, kde se text nachází na obrazovce. Pokud se hledání provádí v popředí, vrácená souřadnice je relativní k levému hornímu rohu okna |
Výjimky
| Výjimka | Description |
|---|---|
| Nelze zkontrolovat, zda existuje text v neinteraktivním režimu | Označuje, že není možné zkontrolovat text na obrazovce v neinteraktivním režimu |
| Neplatné souřadnice podoblasti | Označuje, že souřadnice zadané podoblasti jsou neplatné |
| Nepodařilo se analyzovat text pomocí OCR | Označuje, že došlo k chybě při pokusu analyzovat text pomocí OCR |
| Nepodařilo se vytvořit modul OCR | Označuje, že došlo k chybě při pokusu o vytvoření modulu OCR |
| Složka cesty k datům neexistuje | Označuje, že zadaná složka pro data jazyka neexistuje |
| Vybraná jazyková sada Windows není v počítači nainstalovaná | Ukazuje, že vybraná jazyková sada Windows není v počítači nainstalovaná |
| Modul OCR není aktivní | Označuje, že modul OCR není aktivní |
Čekat na text na obrazovce (OCR)
Čekat, až se na obrazovce, v okně v popředí nebo v vzhledem k obrázku zobrazí na obrazovce nebo v okně v popředí konkrétní text pomocí OCR, nebo z nich zmizí.
Vstupní parametry
| Argument | Volitelné | Přijímá | Výchozí hodnota | Description |
|---|---|---|---|---|
| Wait for text to | Není k dispozici | Zobrazit, Skrýt | Zobrazit | Určuje, zda čekat na zobrazení nebo zmizení textu |
| Typ modulu OCR | Ne | Modul Windows OCR, modul Tesseract, proměnná modulu OCR | Proměnná modulu OCR | Typ stroje OCR, který se má použít. Vyberte předkonfigurovaný modul OCR nebo nastavte nový. |
| OCR engine variable | Ne | OCREngineObject | Modul, který se má použít pro operaci OCR | |
| Text to find | Ne | Textová hodnota | Text, který se má vyhledat v zadaném zdroji | |
| Is regular expression | Není k dispozici | Logická hodnota | False | Určuje, zda použít regulární výraz k nalezení zadaného textu |
| Search for text on | Není k dispozici | Celá obrazovka, okno popředí | Celá obrazovka | Určuje, zda vyhledat zadaný text na celé viditelné obrazovce, nebo pouze v okně v popředí |
| Search mode | – | Celý zadaný zdroj, pouze konkrétní podoblast, podoblast vzhledem k obrázku | Celý zadaný zdroj | Určuje, zda prohledat celou obrazovku (nebo okno), nebo jen její zúženou podoblast |
| Image(s) | Ne | Seznamsnímků | Obrázky určující podoblast (relativní k levému hornímu rohu obrázku), ve které se má vyhledat zadaný text | |
| X1 | Ano | Číselná hodnota | Počáteční souřadnice X podoblasti, ve které se má vyhledat zadaný text | |
| Tolerance | Ano | Číselná hodnota | 10 | Určuje, do jaké míry se může hledaný obrázek lišit od původně vybraného obrázku |
| Y1 | Ano | Číselná hodnota | Počáteční souřadnice Y podoblasti, ve které se má vyhledat zadaný text | |
| X1 | Ano | Číselná hodnota | Počáteční souřadnice X podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| X2 | Ano | Číselná hodnota | Koncová souřadnice X podoblasti, ve které se má vyhledat zadaný text | |
| Y1 | Ano | Číselná hodnota | Počáteční souřadnice Y podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| Y2 | Ano | Číselná hodnota | Koncová souřadnice Y podoblasti, ve které se má vyhledat zadaný text | |
| X2 | Ano | Číselná hodnota | Koncová souřadnice X podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| Y2 | Ano | Číselná hodnota | Koncová souřadnice Y podoblasti relativní k určenému obrázku, ve kterém se má vyhledat zadaný text | |
| Jazyk modulu Windows OCR | Neuvedeno | Čínština (zjednodušená), čínština (tradiční), čeština, dánštinu, nizozemština, angličtina, finština, francouzština, němčina, řečtina, maďarština, italština, japonština, korejština, norština, polština, portugalština, rumunština, ruština, srbština (cyrilice), srbština (latinka), slovenština, španělština, švédština, turečtina | Angličtina | Jazyk textu, který modul Windows OCR rozpozná |
| Použít jiný jazyk | Neuvedeno | Logická hodnota | False | Určuje, jestli se má použít jazyk, který není uveden v poli Jazyk modulu Tesseract |
| Jazyk Tesseract | Neuvedeno | Angličtina, němčina, španělština, francouzština, italština | Angličtina | Jazyk textu, který modul Tesseract detekuje |
| Zkratka jazyka | Ne | Textová hodnota | Zkratka Tesseract jazyka, který se má použít. Pokud jsou například data „eng.traineddata“, nastavte parametr na „eng“ | |
| Cesta k datům jazyka | Ne | Textová hodnota | Cesta ke složce, která obsahuje data Tesseract v zadaném jazyce | |
| Násobitel šířky obrázku | Ne | Číselná hodnota | 1 | Násobitel šířky obrázku |
| Násobitel výšky obrázku | Ne | Číselná hodnota | 1 | Násobitel výšky obrázku |
| Algoritmus určení shody obrázku | – | Základní, Rozšířený | Základní | Obrazový algoritmus, který se má použít při hledání obrázků |
| Selhání s chybou časového limitu | – | Logická hodnota | False | Určete, zda chcete, aby akce počkala neomezeně dlouho, nebo aby selhala po nastaveném časovém období |
Poznámka:
- Modul regulárních výrazů Power Automate je .NET. Více informací o regulárních výrazech naleznete v článku Jazyk regulárních výrazů – rychlý průvodce.
- Možnost Proměnná modulu OCR je plánována na ukončení podpory.
Vytvořené proměnné
| Argument | Type | Description |
|---|---|---|
| LocationOfTextFoundX | Číselná hodnota | Souřadnice X bodu, kde se text nachází na obrazovce. Pokud se hledání provádí v popředí, vrácená souřadnice je relativní k levému hornímu rohu okna |
| LocationOfTextFoundY | Číselná hodnota | Souřadnice X bodu, kde se text nachází na obrazovce. Pokud se hledání provádí v popředí, vrácená souřadnice je relativní k levému hornímu rohu okna |
Výjimky
| Výjimka | Description |
|---|---|
| Nelze zkontrolovat, zda existuje text v neinteraktivním režimu | Označuje, že není možné zkontrolovat text na obrazovce v neinteraktivním režimu |
| Neplatné souřadnice podoblasti | Označuje, že souřadnice zadané podoblasti jsou neplatné |
| Nepodařilo se analyzovat text pomocí OCR | Označuje, že došlo k chybě při pokusu analyzovat text pomocí OCR |
| Nepodařilo se vytvořit modul OCR | Označuje, že došlo k chybě při pokusu o vytvoření modulu OCR |
| Složka cesty k datům neexistuje | Označuje, že zadaná složka pro data jazyka neexistuje |
| Vybraná jazyková sada Windows není v počítači nainstalovaná | Ukazuje, že vybraná jazyková sada Windows není v počítači nainstalovaná |
| Modul OCR není aktivní | Označuje, že modul OCR není aktivní |
| Chyba: Vypršel časový limit | Označuje, že akce selhala po nastavené době |
Extrahovat text pomocí OCR
Extrahovat text z daného zdroje pomocí zadaného modulu OCR.
Vstupní parametry
| Argument | Volitelné | Přijímá | Výchozí hodnota | Description |
|---|---|---|---|---|
| Modul OCR | Ne | Modul Windows OCR, modul Tesseract, proměnná modulu OCR | Proměnná modulu OCR | Typ stroje OCR, který se má použít. Vyberte předkonfigurovaný modul OCR nebo nastavte nový |
| Proměnná modulu OCR | Ne | OCREngineObject | Modul, který se má použít pro operaci OCR | |
| OCR source | Není k dispozici | Obrazovka, obrázek popředí, obrázek na disku | Obrazovka | Zdroj obrázku, na kterém se má provést operace OCR |
| Image file path | Ne | Soubor | Cesta obrázku, na kterém se má provést operace OCR | |
| Search mode | Není k dispozici | Celý zadaný zdroj, pouze konkrétní podoblast, podoblast vzhledem k obrázku | Celý zadaný zdroj | Vybraný režim pro operaci OCR |
| Image | Ne | Seznamsnímků | Obrázek, který se má použít pro zúžení skenování na podoblast vzhledem k zadanému obrázku | |
| Tolerance | Ano | Číselná hodnota | 10 | Určuje, do jaké míry se může obrázek lišit od původně vybraného obrázku |
| X1 | Ano | Číselná hodnota | Počáteční souřadnice X podoblasti, na kterou zúžit skenování | |
| X2 | Ano | Číselná hodnota | Koncová souřadnice X podoblasti, na kterou zúžit skenování | |
| Y1 | Ano | Číselná hodnota | Počáteční souřadnice Y podoblasti, na kterou zúžit skenování | |
| Y2 | Ano | Číselná hodnota | Koncová souřadnice Y podoblasti, na kterou zúžit skenování | |
| Jazyk modulu Windows OCR | Neuvedeno | Čínština (zjednodušená), čínština (tradiční), čeština, dánštinu, nizozemština, angličtina, finština, francouzština, němčina, řečtina, maďarština, italština, japonština, korejština, norština, polština, portugalština, rumunština, ruština, srbština (cyrilice), srbština (latinka), slovenština, španělština, švédština, turečtina | Angličtina | Jazyk textu, který modul Windows OCR rozpozná |
| Použít jiný jazyk | Neuvedeno | Logická hodnota | False | Určuje, jestli se má použít jazyk, který není uveden v poli Jazyk modulu Tesseract |
| Jazyk Tesseract | Neuvedeno | Angličtina, němčina, španělština, francouzština, italština | Angličtina | Jazyk textu, který modul Tesseract detekuje |
| Zkratka jazyka | Ne | Textová hodnota | Zkratka Tesseract jazyka, který se má použít. Pokud jsou například data „eng.traineddata“, nastavte parametr na „eng“ | |
| Cesta k datům jazyka | Ne | Textová hodnota | Cesta ke složce, která obsahuje data Tesseract v zadaném jazyce | |
| Násobitel šířky obrázku | Ne | Číselná hodnota | 1 | Násobitel šířky obrázku |
| Násobitel výšky obrázku | Ne | Číselná hodnota | 1 | Násobitel výšky obrázku |
| Počkat na zobrazení obrázku | – | Logická hodnota | True | Určuje, zda počkat, než se obrázek zobrazí na obrazovce nebo v okně v popředí |
| Časový limit | Ne | Číselná hodnota | 5 | Určuje čas čekání na dokončení operace, než akce selže |
| Algoritmus určení shody obrázku | – | Základní, Rozšířený | Základní | Obrazový algoritmus, který se má použít při hledání obrázků |
Poznámka:
Možnost Proměnná modulu OCR je plánována na ukončení podpory.
Vytvořené proměnné
| Argument | Type | Description |
|---|---|---|
| OcrText | Textová hodnota | Výsledek extrakce textu |
Výjimky
| Výjimka | Popis |
|---|---|
| Nepodařilo se extrahovat text pomocí OCR | Označuje, že došlo k chybě při pokusu o extrahování textu pomocí OCR z daného zdroje |
| Soubor obrázku nenalezen | Označuje, že soubor v dané cestě neexistuje |
| Obrázek orientačního bodu nenalezen | Označuje, že obrázek orientačního bodu neexistuje |
| Nelze získat text z obrazovky v neinteraktivním režimu | Označuje, že není možné získat text z obrazovky v neinteraktivním režimu |
| Nepodařilo se vytvořit modul OCR | Označuje, že došlo k chybě při pokusu o vytvoření modulu OCR |
| Složka cesty k datům neexistuje | Označuje, že zadaná složka pro data jazyka neexistuje |
| Vybraná jazyková sada Windows není v počítači nainstalovaná | Ukazuje, že vybraná jazyková sada Windows není v počítači nainstalovaná |
| Modul OCR není aktivní | Označuje, že modul OCR není aktivní |