Příprava veřejných datových sad v datových sadách SDOH – transformace (Preview)
[Tento článek představuje předběžnou dokumentaci a může se změnit.]
Veřejné datové sady SDOH obsahují agregovaná data o sociálních determinantech zdraví (SDOH) publikovaná vládními agenturami a dalšími oficiálními zdroji, jako jsou univerzity. Tyto datové sady konsolidují různé parametry SDOH na geografických úrovních, jako je stát, okres nebo PSČ. Datové sady SDOH – Transformace (Preview) umožňují ingestovat, ukládat a analyzovat datové sady ve formátu CSV (Hodnoty oddělené čárkou) nebo XLSX (Excel Open XML Spreadsheet) a normalizovat je do vlastního datového modelu.
Verze Preview poskytuje následujících osm ukázkových datových sad SDOH z různých domén SDOH, které vám pomůžou spouštět datové kanály a zkoumat transformace dat prostřednictvím bronzových, stříbrných a zlatých vrstev transakčního jezera:
Atlas potravinového prostředí USDA: Zahrnuje faktory, jako je blízkost obchodu/restaurace, ceny potravin, programy výživové pomoci a charakteristiky komunity. Tyto faktory ovlivňují výběr potravin, kvalitu stravy a v konečném důsledku i zdravotní výsledky.
Atlas venkova USDA: Nabízí statistiky o socioekonomických faktorech, jako jsou lidé, pracovní místa, klasifikace okresů, příjmy a veteráni.
Data SDOH AHRQ: Poskytuje podrobnosti v pěti klíčových doménách SDOH:
- Sociální kontext, jako je věk, rasa/etnická příslušnost, status veterána.
- Ekonomický kontext, jako je příjem, míra nezaměstnanosti.
- Vzdělávání
- Fyzická infrastruktura, jako je bydlení, kriminalita, doprava.
- Kontext zdravotní péče, jako je zdravotní pojištění.
Index dostupnosti lokality: Odhaduje náklady domácností na bydlení a dopravu na úrovni čtvrti.
Index environmentální spravedlnosti: Agreguje data z více zdrojů, aby seřadil kumulativní dopady environmentální nespravedlnosti na zdraví pro každé sčítání lidu.
ACS Education Attainment: Poskytuje poznatky o vzdělání pro geografické oblasti, odvozené z rozsáhlého probíhajícího demografického průzkumu.
Australská SEIFA: Kombinuje údaje z australského sčítání lidu, jako je příjem, vzdělání, zaměstnanost a bydlení, a shrnuje socioekonomické charakteristiky oblasti.
Britské indexy deprivace: Široce používaný socioekonomický ukazatel ve Spojeném království k hodnocení chudoby v malých oblastech, pokrývající různé dimenze.
Kde:
- USDA: Ministerstvo zemědělství Spojených států amerických
- AHRQ: Agentura pro výzkum a kvalitu zdravotní péče
- ACS: Průzkum americké komunity
- SEIFA: Socioekonomické indexy pro oblasti
Důležité
Tyto datové sady nejsou jen ukázky, ale kompletní, skutečné datové sady publikované příslušnými organizacemi. Poskytují přesnou reprezentaci profilů SDOH jejich geografických oblastí. Při jejich úpravách buďte opatrní, protože se jedná o oficiální publikace federálních agentur.
Struktura složky
Cílová zóna pro datové sady SDOH – transformace (Preview) se skládá ze tří složek: Ingestování, Zpracování a Selhání. Další informace o těchto složkách naleznete v tématu Sjednocená struktura složek.
Příprava datových sad SDOH před příjmem dat
Před příjmem veřejných datových sad SDOH se ujistěte, že jsou připravené na úspěšný příjem dat. Následující sekce popisují dva scénáře.
- Použití vlastní datové sady
- Použití ukázkové datové sady
Použití vlastní datové sady
Veřejné datové sady SDOH se v jednotlivých vydavatelských organizacích výrazně liší formátem, objemem a strukturou. Chybí jim zavedený standard pro sběr a výměnu zachycených informací. Proto je před jejich reprezentací v datovém modelu nezbytné jejich sjednocení do společného tvaru.
Pokud chcete ingestovat a transformovat veřejnou datovou sadu SDOH podle vašeho výběru, přidejte do ní následující tři klíčové informace:
Rozložení: Vzhledem k absenci standardní sady kódů pro snímání dat SDOH je pochopení významu každého pole náročné. Pokud chcete tento problém vyřešit, vytvořte datový slovník pro datovou sadu přidáním nového listu s názvem Rozložení (pokud je vaše datová sada ve formátu XLSX) nebo vytvořte nový soubor CSV (pokud je vaše datová sada ve formátu CSV) se sloupci zobrazenými v následujícím příkladu:
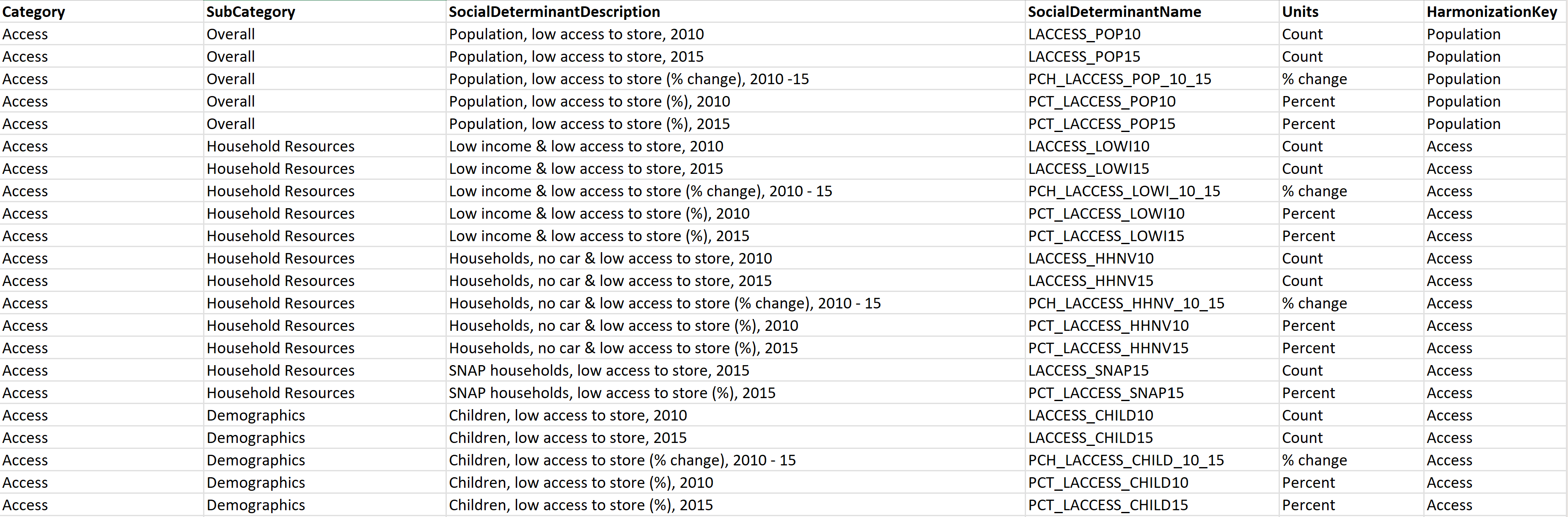
DataSetMetadata: Vzhledem k tomu, že datové sady SDOH pocházejí od různých vydavatelů, je zásadní zaznamenat klíčové podrobnosti o datové sadě. Přidejte nový list s názvem DataSetMetadata (pokud je vaše datová sada ve formátu XLSX) nebo vytvořte nový soubor CSV (pokud je vaše datová sada ve formátu CSV) se sloupci zobrazenými v následujícím příkladu:

LocationConfiguration: Různé geografické oblasti definují a uspořádávají údaje o poloze různými způsoby. Pokud chcete kanálům SDOH pomoct pochopit geografickou strukturu datové sady, přidejte nový list s názvem LocationConfiguration (pokud je vaše datová sada ve formátu XLSX) nebo vytvořte nový soubor CSV (pokud je vaše datová sada ve formátu CSV) se sloupci zobrazenými v následujícím příkladu:




Také:
- Můžete se podívat na strukturu ukázkových datových sad SDOH a vyplnit požadované informace, jako je kategorie sociálního determinantu, metadata a harmonizační klíč.
- Pokud nechcete ingestovat určitá pole z původní datové sady, odeberte je z datového listu nebo ponechte jejich podrobnosti v listu rozložení prázdné. V obou případech nejsou zahrnuty do stříbrného datového modelu.
- Datové sady se stejným názvem, datem publikování a vydavatelem jsou považovány za duplicitní.
Použití ukázkové datové sady
Ukázkové datové sady SDOH, které jsou součástí datových řešení pro zdravotnictví, jsou předem vyplněné se všemi nezbytnými informacemi a jsou k dispozici ve vašem OneLake. Můžete je extrahovat lokálně.
Nahrání datových sad do pracovního prostoru prostředků infrastruktury
Až budou datové sady připravené, zvolte jednu z následujících dvou možností a nahrajte je. Možnost 2 můžete použít jenom v případě, že používáte ukázkovou datovou sadu, která je součástí datových sad SDOH – transformace (Preview).
- Možnost 1: Ruční nahrání datových sad.
- Možnost 2: K nahrání datových sad použijte skript.
Ruční nahrání datových sad
V prostředí Řešení pro zdravotní data vyberte transakční jezero healthcare#_msft_bronze.
Otevřete složku Ingest. Další informace naleznete v tématu Popisy složky.
Vyberte tři tečky (...) vedle názvu složky a vyberte Nahrát složku.
Nahrajte datové sady z místního systému. Pomocí Průzkumníka souborů OneLake vyhledejte datové sady v následující cestě:
<workspace name>\healthcare#.HealthDataManager\DMHSampleData\8SdohPublicDataset.Aktualizujte složku Ingest. Nyní byste měli vidět soubory datových sad v podsložce SDOH.
Použití skriptu k nahrání datových sad
Důležité
Tuto možnost použijte jenom v případě, že používáte poskytnutou ukázkovou datovou sadu.
Přejděte do pracovního prostoru prostředků infrastruktury Řešení pro zdravotní data.
Vyberte + Nová položka.
V podokně Nová položka vyhledejte a vyberte Poznámkový blok.
Zkopírujte a vložte následující fragment kódu do poznámkového bloku.
workspace_name = '<workspace_name>' # workspace name one_lake_endpoint = "<OneLake_endpoint>" # OneLake endpoint solution_name = "<solution_name>" # solution name bronze_lakehouse_name = "<bronze_lakehouse_name>" # bronze lakehouse name def copy_source_files_and_folders(source_path, destination_path): source_contents = mssparkutils.fs.ls(source_path) # list the source directory contents # list the destination directory contents try: if mssparkutils.fs.exists(destination_path): destination_contents = mssparkutils.fs.ls(destination_path) destination_files = {item.path.split('/')[-1]: item.path for item in destination_contents} else: print(f"Destination path {destination_path} does not exist.") destination_files = {} except Exception as e: print(f" Error: {str(e)}") destination_files = {} # copy each item inside the source directory to the destination directory for item in source_contents: item_path = item.path item_name = item_path.split('/')[-1] destination_item_path = f"{destination_path}/{item_name}" # recursively copy the contents of the directory if item.isDir: copy_source_files_and_folders(item_path, destination_item_path) else: if item_name in destination_files: print(f"File already exists, skipping: {destination_item_path}") else: print(f"Creating new file: {destination_item_path}") mssparkutils.fs.cp(item_path, destination_item_path, recurse=True) # define the source and destination paths with placeholder values data_manager_solution_path = f"abfss://{workspace_name}@{one_lake_endpoint}/{solution_name}" data_manager_sample_data_path = f"{data_manager_solution_path}/DMHSampleData" sdoh_csv_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/csv" sdoh_xlsx_data_path = f"{data_manager_sample_data_path}/8SdohPublicDataset/xlsx" destination_path_csv = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/CSV" destination_path_xlsx = f"abfss://{workspace_name}@{one_lake_endpoint}/{bronze_lakehouse_name}.Lakehouse/Files/Ingest/SDOH/XLSX" # copy the files along with their parent folders copy_source_files_and_folders(sdoh_csv_data_path, destination_path_csv) copy_source_files_and_folders(sdoh_xlsx_data_path, destination_path_xlsx)Spusťte poznámkový blok. Ukázkové datové sady SDOH se teď přesunou do určeného umístění ve složce Ingest.
Datové sady SDOH jsou teď připravené k příjmu dat.