Transformace dat pomocí Apache Sparku a dotazování pomocí SQL
V této příručce:
Nahrajte data do OneLake pomocí Průzkumníka souborů OneLake.
Pomocí poznámkového bloku Fabric můžete číst data na OneLake a zapisovat zpět jako tabulku Delta.
Analýza a transformace dat pomocí Sparku pomocí poznámkového bloku Fabric
Dotazování jedné kopie dat na OneLake pomocí SQL
Požadavky
Než začnete, musíte:
Stáhněte a nainstalujte Průzkumníka souborů OneLake.
Vytvořte pracovní prostor s položkou Lakehouse.
Stáhněte si datovou sadu WideWorldImportersDW. K připojení
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_citya stažení sady souborů CSV můžete použít Průzkumník služby Azure Storage. Nebo můžete použít vlastní data csv a podle potřeby aktualizovat podrobnosti.
Poznámka:
Vždy vytvořte, načtěte nebo vytvořte zástupce dat Delta-Parquet přímo v části Tabulky jezera. Tabulky vnořujte do podsložek v oddílu Tabulky , protože jezero ji nerozpozná jako tabulku a označí ji jako neidentifikovanou.
Nahrání, čtení, analýza a dotazování dat
V Průzkumníku souborů OneLake přejděte do svého lakehouse a pod
/Filesadresářem vytvořte podadresář s názvemdimension_city.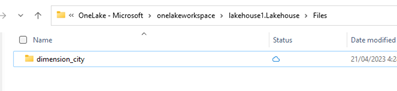
Zkopírujte ukázkové soubory CSV do adresáře
/Files/dimension_cityOneLake pomocí Průzkumníka souborů OneLake.
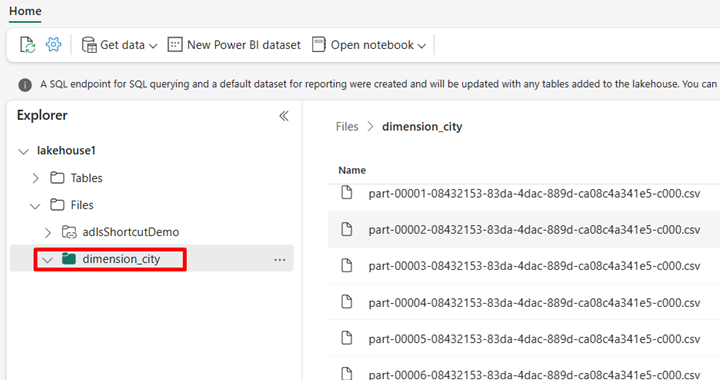
V služba Power BI přejděte do svého jezera a prohlédněte si soubory.
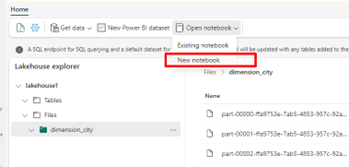
Vyberte Otevřít poznámkový blok a potom Nový poznámkový blok a vytvořte poznámkový blok .
Pomocí poznámkového bloku Fabric převeďte soubory CSV do formátu Delta. Následující fragment kódu čte data z adresáře
/Files/dimension_cityvytvořeného uživatelem a převede je na tabulkudim_cityDelta .import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/<replace with your folder path>"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<replace with workspace name>@onelake.dfs.fabric.microsoft.com/<replace with item name>.Lakehouse/Files/<folder name>/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/<name of delta table>")Pokud chcete zobrazit novou tabulku, aktualizujte zobrazení
/Tablesadresáře.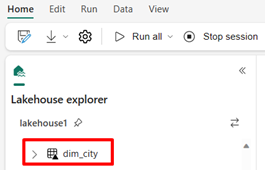
Dotazujte se na tabulku pomocí SparkSQL ve stejném poznámkovém bloku Fabric.
%%sql SELECT * from <replace with item name>.dim_city LIMIT 10;Upravte tabulku Delta přidáním nového sloupce s názvem newColumn s datovým typem integer. Nastavte hodnotu 9 pro všechny záznamy pro tento nově přidaný sloupec.
%%sql ALTER TABLE <replace with item name>.dim_city ADD COLUMN newColumn int; UPDATE <replace with item name>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <replace with item name>.dim_city LIMIT 10;K libovolné tabulce Delta na OneLake můžete přistupovat také prostřednictvím koncového bodu analýzy SQL. Koncový bod analýzy SQL odkazuje na stejnou fyzickou kopii tabulky Delta na OneLake a nabízí prostředí T-SQL. Vyberte koncový bod analýzy SQL pro lakehouse1 a pak vyberte Nový dotaz SQL pro dotazování tabulky pomocí T-SQL.
SELECT TOP (100) * FROM [<replace with item name>].[dbo].[dim_city];
