Integrace OneLake s Azure Databricks
Tento scénář ukazuje, jak se připojit k OneLake přes Azure Databricks. Po dokončení tohoto kurzu budete moct číst a zapisovat do Microsoft Fabric Lakehouse z pracovního prostoru Azure Databricks.
Požadavky
Než se připojíte, musíte mít:
- Pracovní prostor Fabric a jezero.
- Pracovní prostor Azure Databricks úrovně Premium. Pouze pracovní prostory Azure Databricks úrovně Premium podporují předávání přihlašovacích údajů Microsoft Entra, které potřebujete pro tento scénář.
Nastavení pracovního prostoru Databricks
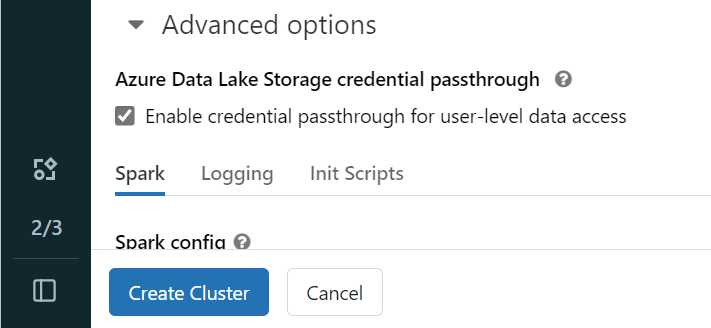
Otevřete pracovní prostor Azure Databricks a vyberte Vytvořit>cluster.
Pokud se chcete ověřit ve službě OneLake pomocí identity Microsoft Entra, musíte ve svém clusteru povolit předávání přihlašovacích údajů Azure Data Lake Storage (ADLS) v rozšířených možnostech.
Poznámka:
Databricks můžete k OneLake připojit také pomocí instančního objektu. Další informace o ověřování Azure Databricks pomocí instančního objektu najdete v tématu Správa instančních objektů.
Vytvořte cluster s upřednostňovanými parametry. Další informace o vytvoření clusteru Databricks najdete v tématu Konfigurace clusterů – Azure Databricks.
Otevřete poznámkový blok a připojte ho k nově vytvořenému clusteru.
Vytvoření poznámkového bloku
Přejděte do objektu Fabric Lakehouse a zkopírujte cestu systému souborů Azure Blob (ABFS) do svého jezera. Najdete ho v podokně Vlastnosti .
Poznámka:
Azure Databricks podporuje při čtení a zápisu do ADLS Gen2 a OneLake pouze ovladač systému souborů Azure Blob Filesystem (ABFS):
abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/Uložte cestu k jezeru v poznámkovém bloku Databricks. Toto jezero je místo, kde později zapíšete zpracovávaná data:
oneLakePath = 'abfss://myWorkspace@onelake.dfs.fabric.microsoft.com/myLakehouse.lakehouse/Files/'Načtěte data z veřejné datové sady Databricks do datového rámce. Můžete si také přečíst soubor z jiného umístění v prostředcích infrastruktury nebo zvolit soubor z jiného účtu ADLS Gen2, který už vlastníte.
yellowTaxiDF = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/databricks-datasets/nyctaxi/tripdata/yellow/yellow_tripdata_2019-12.csv.gz")Filtrování, transformace nebo příprava dat V tomto scénáři můžete datovou sadu zkrátit a zrychlit načítání, spojovat se s jinými datovými sadami nebo filtrovat podle konkrétních výsledků.
filteredTaxiDF = yellowTaxiDF.where(yellowTaxiDF.fare_amount<4).where(yellowTaxiDF.passenger_count==4) display(filteredTaxiDF)Napište filtrovaný datový rámec do fabric lakehouse pomocí cesty OneLake.
filteredTaxiDF.write.format("csv").option("header", "true").mode("overwrite").csv(oneLakePath)Otestujte, že data byla úspěšně zapsána čtením nově načteného souboru.
lakehouseRead = spark.read.format('csv').option("header", "true").load(oneLakePath) display(lakehouseRead.limit(10))
Blahopřejeme. Teď můžete číst a zapisovat data v Prostředcích infrastruktury pomocí Azure Databricks.