Provádění analýzy dat pomocí poznámkových bloků Microsoft Fabric
Platí pro:✅SQL Database v Microsoft Fabric
Analýzu dat můžete provádět pomocí mnoha nástrojů, jako je sestava Power BI, kterou jste vytvořili v posledním kroku tohoto kurzu. Dalším oblíbeným nástrojem pro analýzu je Jupyter Notebooks. Poznámkové bloky jsou položka založená na Pythonu, která obsahuje buňky, které obsahují kód nebo prostý text (jako Markdown, jazyk formátování rtfů pro prostý text). Kód, který se spouští, je založený na jádru nebo prostředí jupyter Notebooku. Microsoft Fabric obsahuje poznámkové bloky a více prostředí pro buňky kódu.
V našem ukázkovém kurzu vaše organizace požádala o nastavení poznámkového bloku pro data v datech SQL. Použijeme koncový bod analýzy SQL vaší databáze SQL, který obsahuje automaticky replikovaná data z vaší databáze SQL.
Požadavky
- Dokončete všechny předchozí kroky v tomto kurzu.
Analýza dat s využitím poznámkových bloků T-SQL
Na domovské stránce portálu Microsoft Fabric přejděte do pracovního prostoru, který jste pro tento kurz vytvořili.
Na panelu nástrojů vyberte tlačítko Nová položka a pak vyberte Všechny položky a posuňte se, dokud neuvidíte položku poznámkového bloku. Výběrem této položky vytvořte nový poznámkový blok.
Na panelu ikon změňte prostředí z PySpark (Python) na T-SQL.
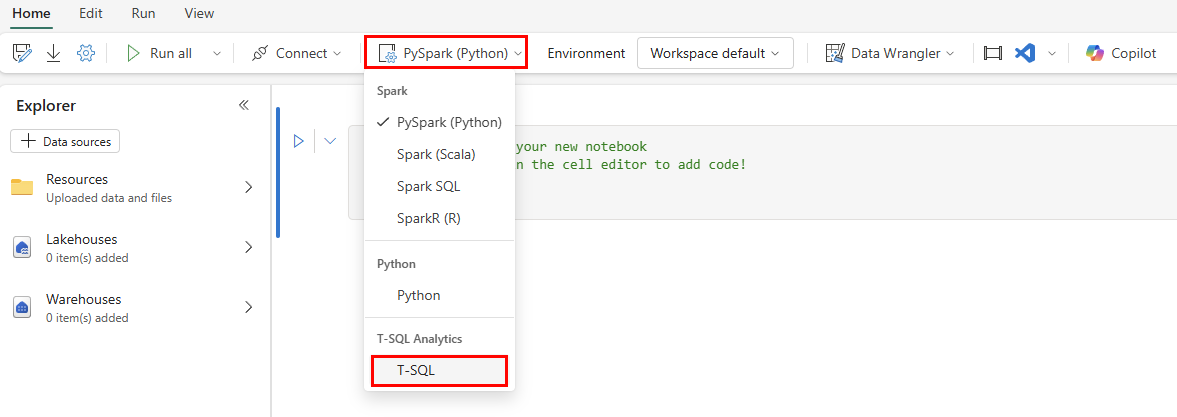
V každé buňce kódu je rozevírací seznam pro jazyk kódu. V první buňce v poznámkovém bloku změňte jazyk kódu z PySpark (Python) na T-SQL.

V Průzkumníku poznámkových bloků vyberte položku Sklady.
Vyberte tlačítko + Sklady.
Vyberte objekt koncového bodu analýzy SQL s názvem
supply_chain_analytics_databasese stejným názvem objektu, který jste vytvořili dříve v tomto kurzu. Vyberte Potvrdit.Rozbalte databázi a rozbalte schémata.
SupplyChainRozbalte schéma. Rozbalte zobrazení a vyhledejte zobrazení SQL s názvemvProductsBySupplier.Vyberte tři tečky vedle tohoto zobrazení. a vyberte možnost , která říká
SELECT TOP 100.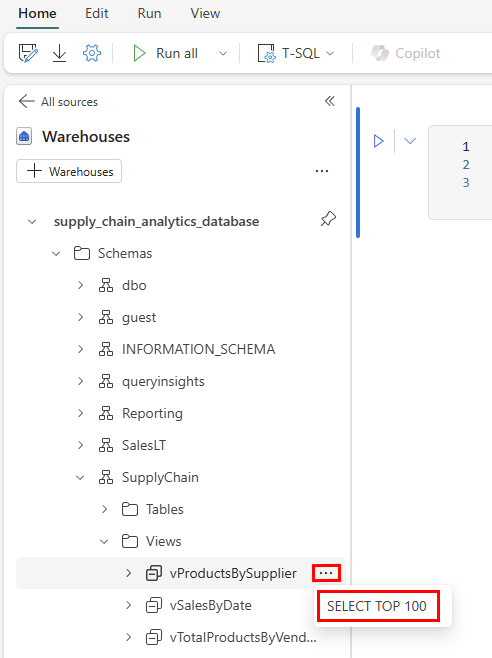
Tím se vytvoří buňka s kódem T-SQL, který obsahuje předem vyplněné příkazy. Výběrem tlačítka Spustit buňku pro buňku spusťte dotaz a vrátíte výsledky.
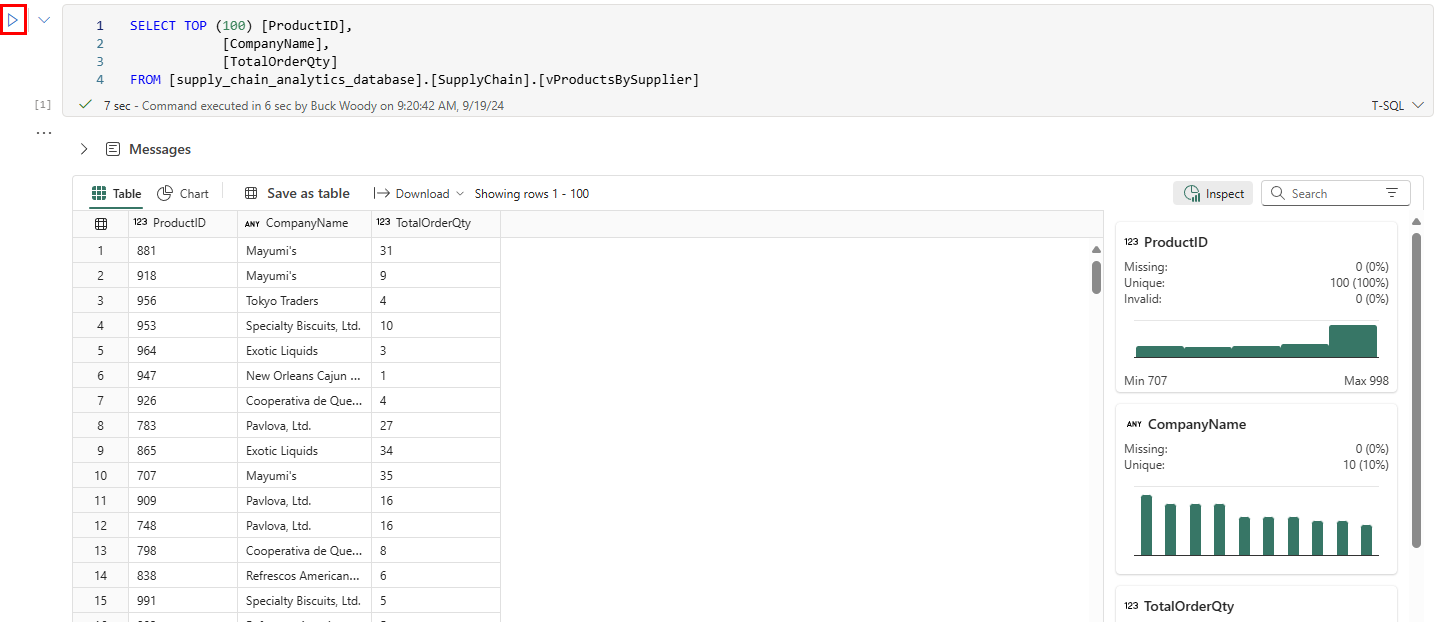
Ve výsledcích uvidíte nejen požadovaná data, ale tlačítka, která umožňují zobrazit grafy, uložit data jako jinou tabulku, stáhnout a další. Na straně výsledků uvidíte nové podokno s rychlou kontrolou datových prvků, kde se zobrazují minimální a maximální hodnoty, chybějící data a jedinečné počty vrácených dat.
Při najetí myší mezi buňky kódu se zobrazí nabídka pro přidání další buňky. Vyberte tlačítko + Markdown.

Tím se umístí textové pole, do kterého můžete přidat informace. Stylování textu je k dispozici na panelu ikon nebo můžete vybrat
</>tlačítko pro práci s Markdownem přímo. Výsledek formátování se zobrazí jako náhled formátovaného textu.
Na pásu karet vyberte ikonu Uložit jako . Zadejte text
products_by_suppliers_notebook. Ujistěte se, že jste umístění nastavili na pracovní prostor kurzu. Výběrem tlačítka Uložit poznámkový blok uložte.




