Bodování modelu strojového učení pomocí funkce PREDICT v Microsoft Fabric
Microsoft Fabric umožňuje uživatelům zprovoznit modely strojového učení pomocí škálovatelné funkce PREDICT. Tato funkce podporuje dávkové bodování v jakémkoli výpočetním modulu. Uživatelé můžou generovat dávkové předpovědi přímo z poznámkového bloku Microsoft Fabric nebo ze stránky položek daného modelu ML.
V tomto článku se dozvíte, jak použít funkci PREDICT napsáním kódu sami nebo pomocí prostředí s asistencí uživatelského rozhraní, které za vás zpracovává dávkové vyhodnocování.
Požadavky
Získejte předplatné Microsoft Fabric. Nebo si zaregistrujte bezplatnou zkušební verzi Microsoft Fabricu.
Přihlaste se k Microsoft Fabric.
Použijte přepínač zkušeností v levém dolním rohu domovské stránky a přepněte na Fabric.

Omezení
- Funkce PREDICT je aktuálně podporovaná pro tuto omezenou sadu příchutí modelu ML:
- CatBoost
- Keras
- LightGBM
- ONNX
- Prorok
- PyTorch
- Sklearn
- Spark
- Statsmodels
- TensorFlow
- XGBoost
- FUNKCE PREDICT vyžaduje , abyste modely ML uložili ve formátu MLflow s vyplněnými podpisy.
- PREDICT nepodporuje modely ML s více tensorovými vstupy nebo výstupy.
Volání FUNKCE PREDICT z poznámkového bloku
PREDICT podporuje modely zabalené v MLflow v registru Microsoft Fabric. Pokud už v pracovním prostoru existuje natrénovaný a zaregistrovaný model ML, můžete přeskočit ke kroku 2. Pokud ne, krok 1 obsahuje ukázkový kód, který vás provede trénováním ukázkového logistického regresního modelu. Tento model můžete použít ke generování dávkových předpovědí na konci procedury.
Natrénujte model ML a zaregistrujte ho v MLflow. Následující ukázka kódu používá rozhraní API MLflow k vytvoření experimentu strojového učení a následné spuštění MLflow pro model logistické regrese scikit-learn. Verze modelu se pak uloží a zaregistruje v registru Microsoft Fabric. Další informace o trénovacích modelech a sledování vlastních experimentů najdete v návodu k trénování modelů ML pomocí prostředku scikit-learn .
import mlflow import numpy as np from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_diabetes from mlflow.models.signature import infer_signature mlflow.set_experiment("diabetes-demo") with mlflow.start_run() as run: lr = LogisticRegression() data = load_diabetes(as_frame=True) lr.fit(data.data, data.target) signature = infer_signature(data.data, data.target) mlflow.sklearn.log_model( lr, "diabetes-model", signature=signature, registered_model_name="diabetes-model" )Načtení testovacích dat jako datového rámce Sparku K vygenerování dávkových predikcí pomocí modelu ML natrénovaného v předchozím kroku potřebujete testovací data ve formě datového rámce Sparku. V následujícím kódu nahraďte
testhodnotu proměnné vlastními daty.# You can substitute "test" below with your own data test = spark.createDataFrame(data.frame.drop(['target'], axis=1))Vytvořte
MLFlowTransformerobjekt pro načtení modelu ML pro odvozování. Chcete-li vytvořit objekt proMLFlowTransformergenerování dávkových předpovědí, musíte provést tyto akce:- zadejte sloupce datového
testrámce, které potřebujete jako vstupy modelu (v tomto případě všechny) - zvolte název nového výstupního sloupce (v tomto případě
predictions) - zadejte správný název modelu a verzi modelu pro generování těchto předpovědí.
Pokud používáte vlastní model ML, nahraďte hodnoty vstupními sloupci, názvem výstupního sloupce, názvem modelu a verzí modelu.
from synapse.ml.predict import MLFlowTransformer # You can substitute values below for your own input columns, # output column name, model name, and model version model = MLFlowTransformer( inputCols=test.columns, outputCol='predictions', modelName='diabetes-model', modelVersion=1 )- zadejte sloupce datového
Generování předpovědí pomocí funkce PREDICT K vyvolání funkce PREDICT použijte rozhraní Transformer API, Spark SQL API nebo uživatelem definovanou funkci PySpark (UDF). Následující části ukazují, jak generovat dávkové předpovědi s testovacími daty a modelem ML definovaným v předchozích krocích pomocí různých metod vyvolání funkce PREDICT.
PREDICT s využitím rozhraní Transformer API
Tento kód vyvolá funkci PREDICT pomocí rozhraní Transformer API. Pokud používáte vlastní model ML, nahraďte hodnoty pro model a testovací data.
# You can substitute "model" and "test" below with values
# for your own model and test data
model.transform(test).show()
PREDICT s využitím rozhraní Spark SQL API
Tento kód vyvolá funkci PREDICT pomocí rozhraní SPARK SQL API. Pokud používáte vlastní model ML, nahraďte hodnoty a model_namemodel_versionfeatures zadejte název modelu, verzi modelu a sloupce funkcí.
Poznámka:
Použití rozhraní Spark SQL API pro generování predikcí stále vyžaduje vytvoření objektu MLFlowTransformer (jak je znázorněno v kroku 3).
from pyspark.ml.feature import SQLTransformer
# You can substitute "model_name," "model_version," and "features"
# with values for your own model name, model version, and feature columns
model_name = 'diabetes-model'
model_version = 1
features = test.columns
sqlt = SQLTransformer().setStatement(
f"SELECT PREDICT('{model_name}/{model_version}', {','.join(features)}) as predictions FROM __THIS__")
# You can substitute "test" below with your own test data
sqlt.transform(test).show()
PREDICT s uživatelem definovanou funkcí
Tento kód vyvolá funkci PREDICT pomocí funkce PySpark UDF. Pokud používáte vlastní model ML, nahraďte hodnoty modelu a funkcí.
from pyspark.sql.functions import col, pandas_udf, udf, lit
# You can substitute "model" and "features" below with your own values
my_udf = model.to_udf()
features = test.columns
test.withColumn("PREDICT", my_udf(*[col(f) for f in features])).show()
Generování kódu PREDICT ze stránky položek modelu ML
Na stránce položek libovolného modelu ML můžete zvolit jednu z těchto možností, která spustí generování dávkové předpovědi pro konkrétní verzi modelu pomocí funkce PREDICT:
- Zkopírování šablony kódu do poznámkového bloku a přizpůsobení parametrů sami
- Generování kódu PREDICT pomocí uživatelského rozhraní s asistencí
Použití prostředí s asistencí uživatelského rozhraní
Prostředí uživatelského rozhraní s asistencí vás provede těmito kroky:
- Výběr zdrojových dat pro bodování
- Správně namapovat data na vstupy modelu ML
- Určení cíle pro výstupy modelu
- Vytvoření poznámkového bloku, který používá funkci PREDICT ke generování a ukládání výsledků předpovědi
Pokud chcete používat prostředí s asistencí,
Přejděte na stránku položky pro danou verzi modelu ML.
V rozevíracím seznamu Použít tuto verzi vyberte Použít tento model v průvodci.

V kroku Vybrat vstupní tabulku se otevře okno Použít predikce modelu ML.
Vyberte vstupní tabulku z jezera v aktuálním pracovním prostoru.
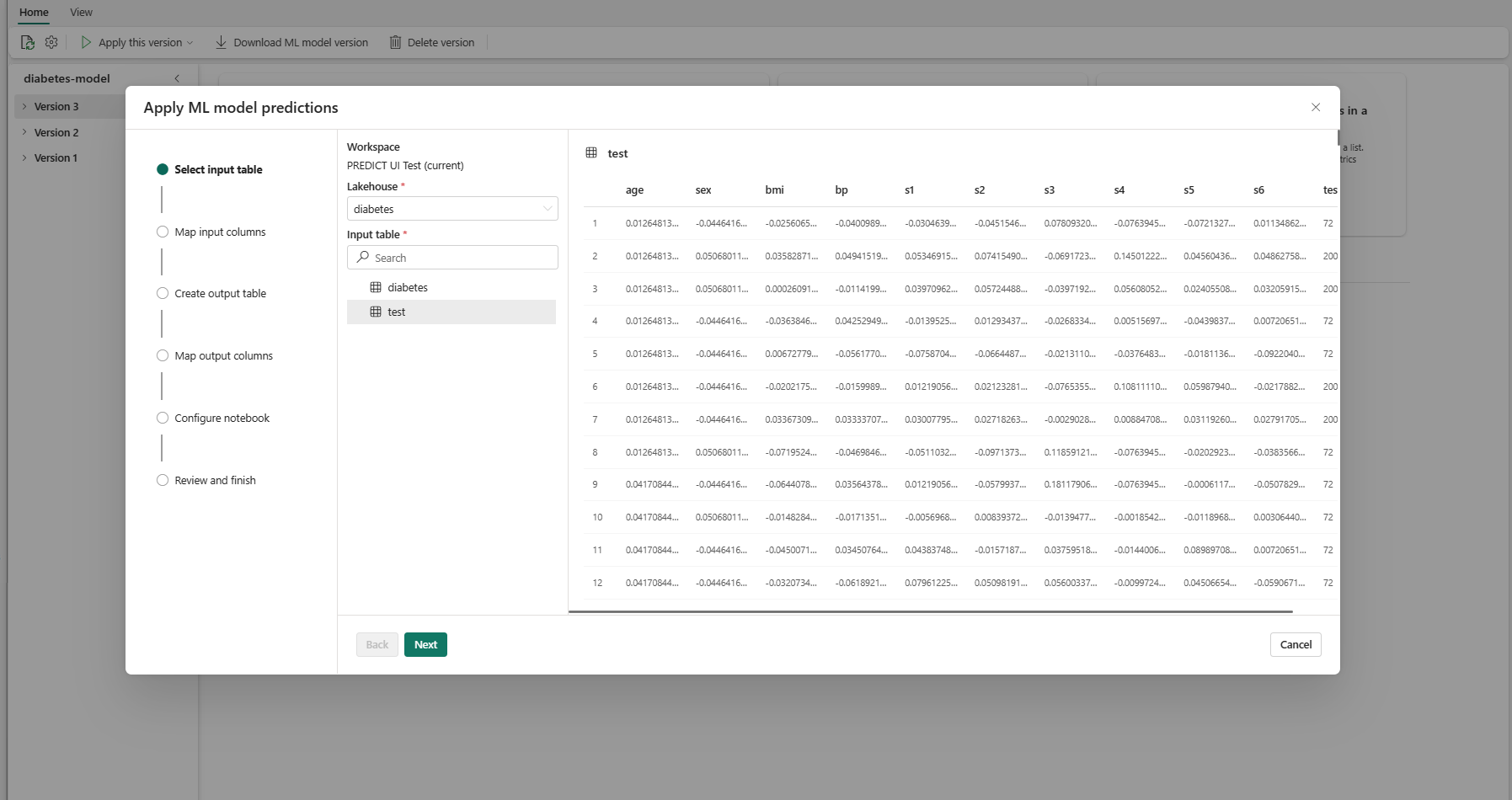
Výběrem možnosti Další přejdete do kroku Mapovat vstupní sloupce.
Namapujte názvy sloupců ze zdrojové tabulky na vstupní pole modelu ML, která se načítají z podpisu modelu. Pro všechna požadovaná pole modelu musíte zadat vstupní sloupec. Kromě toho musí datové typy zdrojového sloupce odpovídat očekávaným datovým typům modelu.
Tip
Průvodce toto mapování předem naplní, pokud názvy sloupců vstupní tabulky odpovídají názvům sloupců přihlášených v podpisu modelu ML.
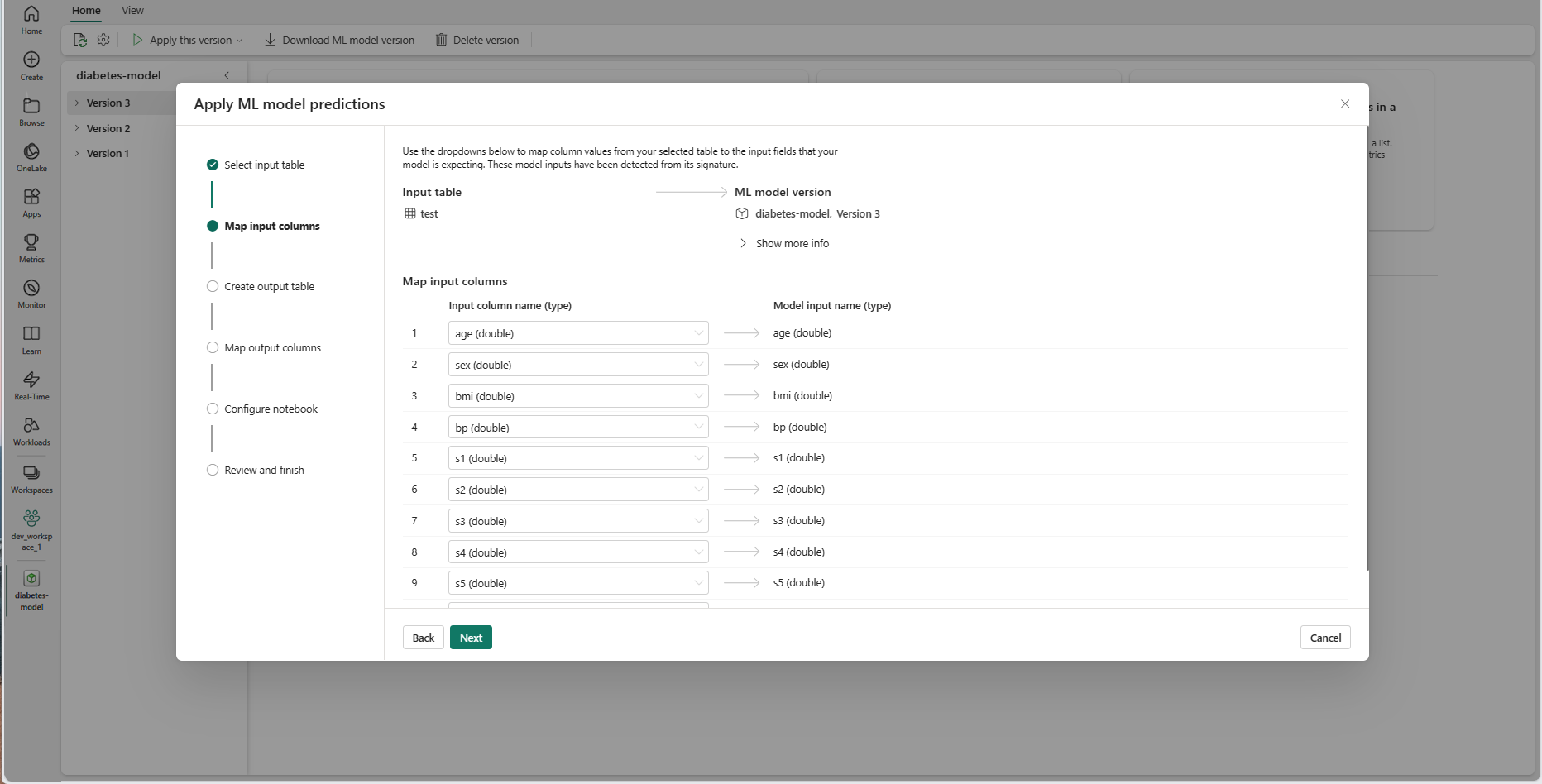
Výběrem možnosti Další přejděte do kroku Vytvořit výstupní tabulku.
Zadejte název nové tabulky ve vybraném jezeře vašeho aktuálního pracovního prostoru. Tato výstupní tabulka ukládá vstupní hodnoty modelu ML a k této tabulce připojí hodnoty predikce. Ve výchozím nastavení se výstupní tabulka vytvoří ve stejném jezeře jako vstupní tabulka. Cílové jezero můžete změnit.
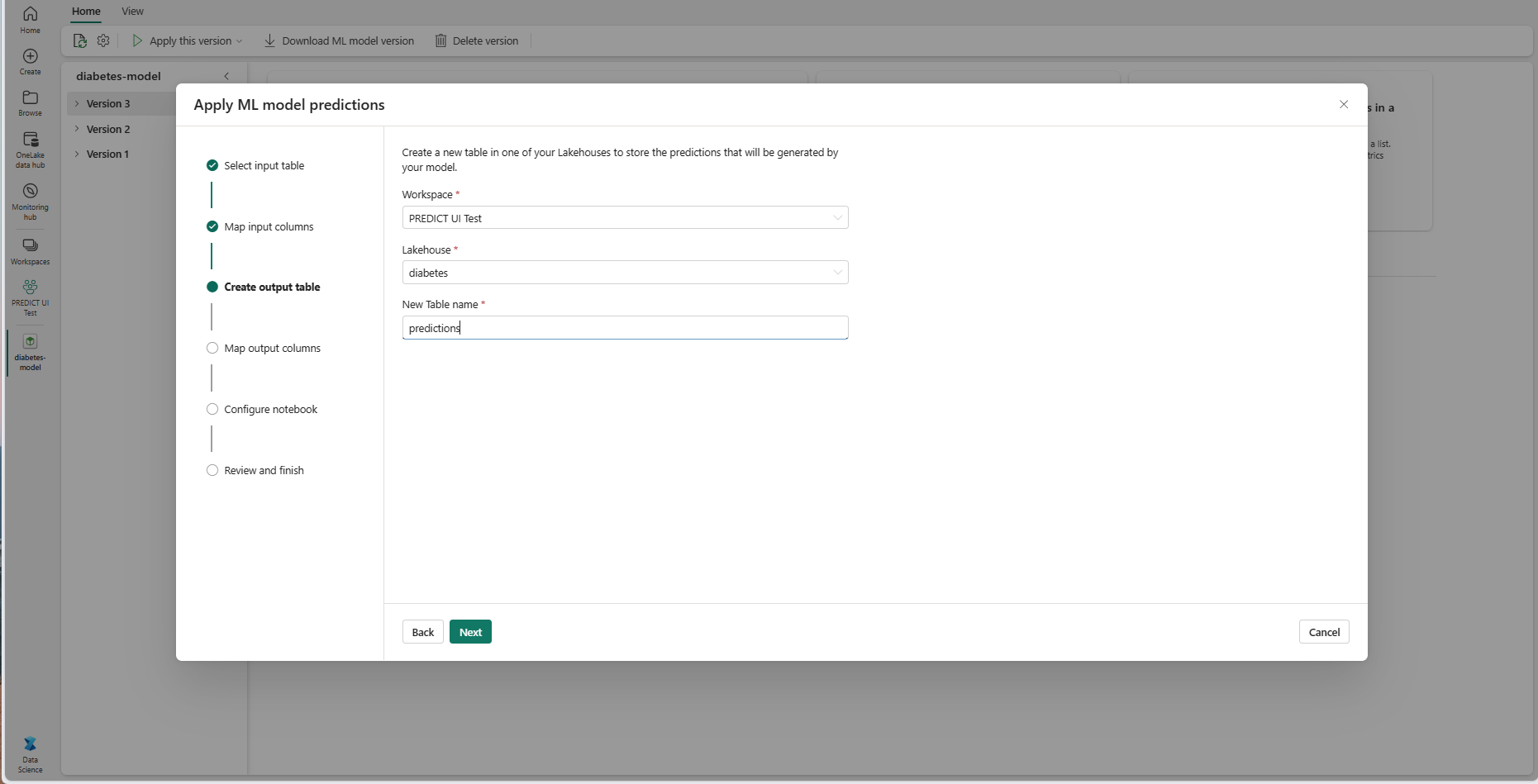
Výběrem možnosti Další přejdete do kroku Mapovat výstupní sloupce.
Pomocí zadaných textových polí pojmenujte sloupce výstupní tabulky, ve kterých jsou uloženy předpovědi modelu ML.
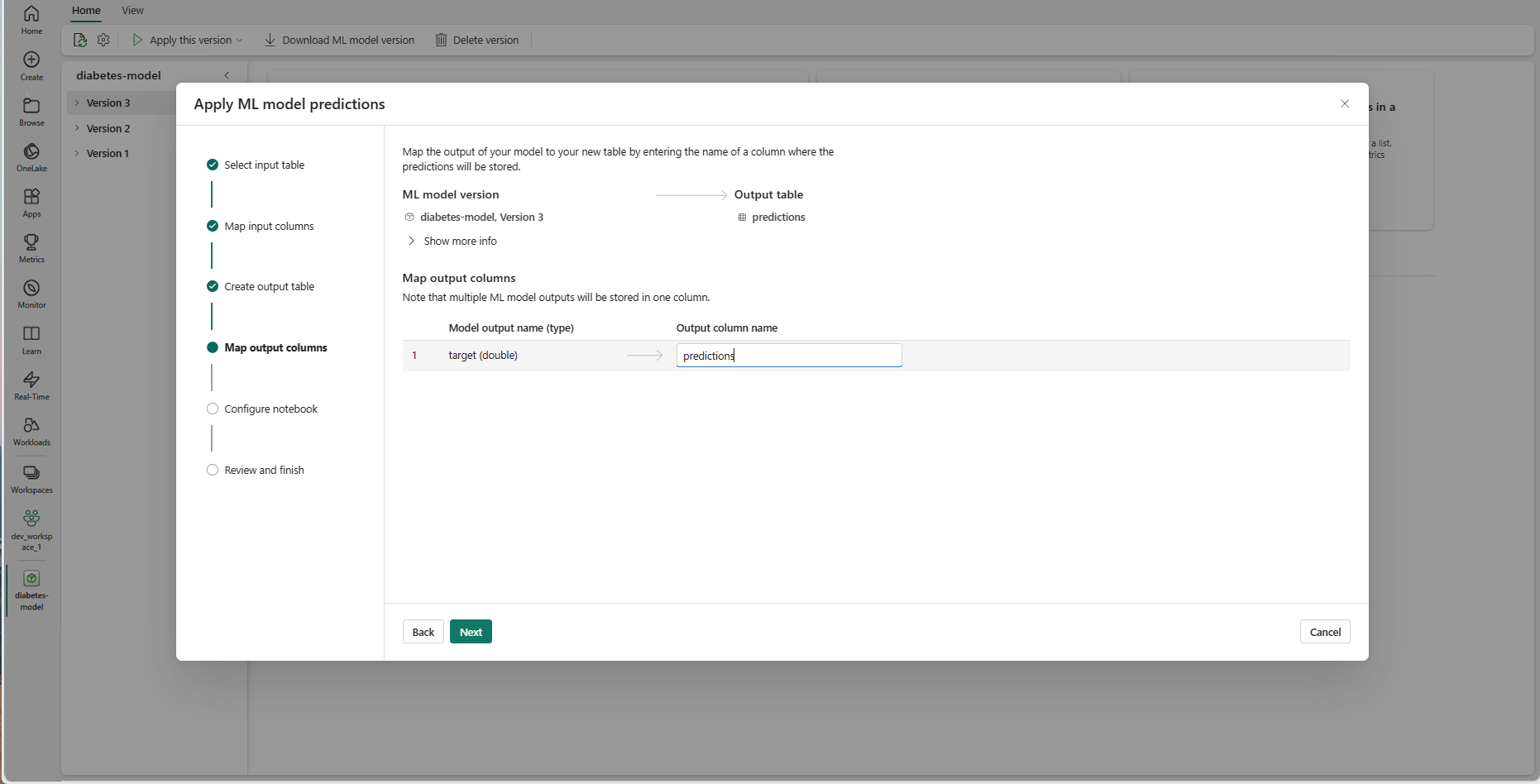
Výběrem možnosti Další přejděte ke kroku Konfigurovat poznámkový blok.
Zadejte název nového poznámkového bloku, na kterém se spustí vygenerovaný kód PREDICT. Průvodce zobrazí náhled vygenerovaného kódu v tomto kroku. Pokud chcete, můžete kód zkopírovat do schránky a vložit ho do existujícího poznámkového bloku.
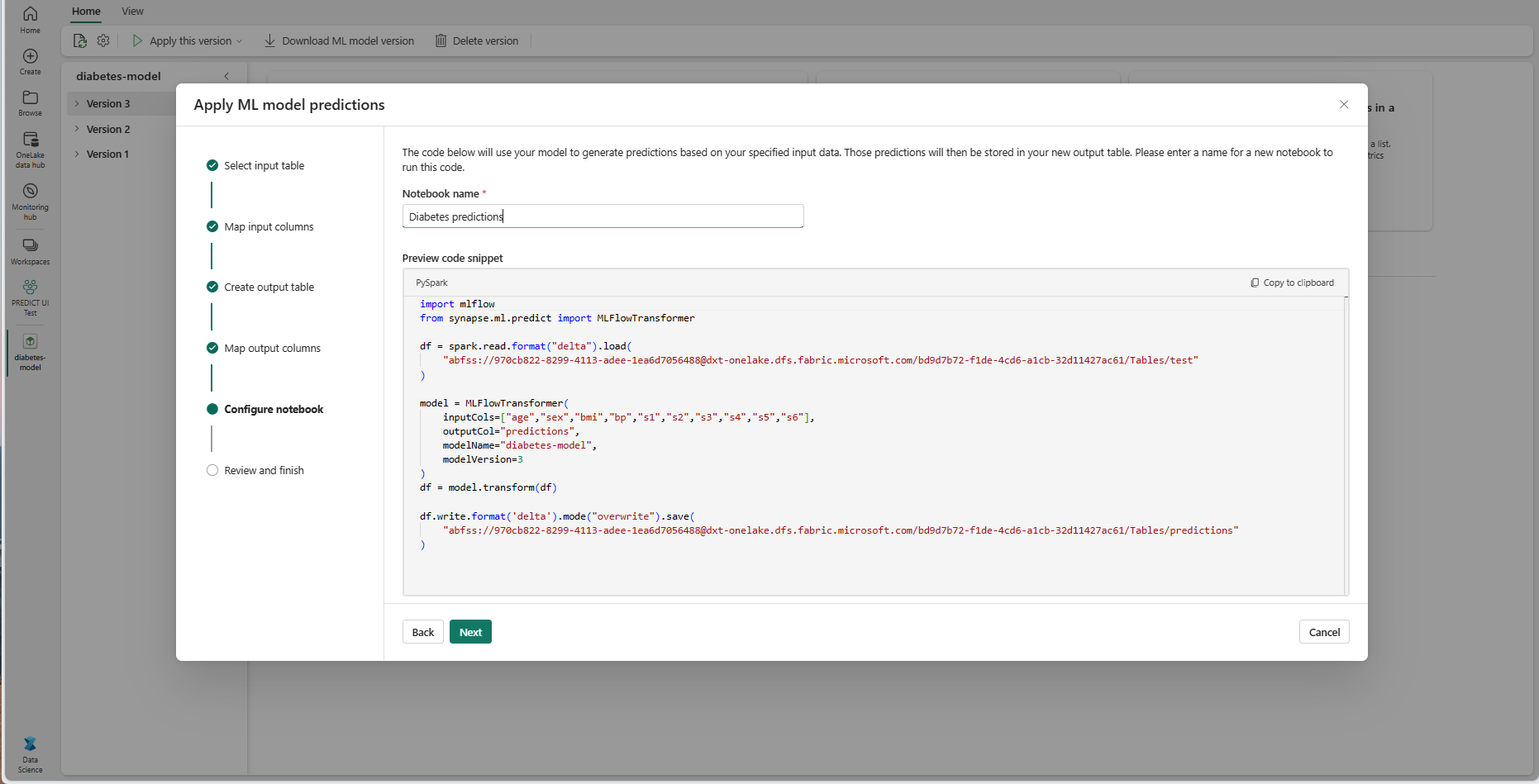
Výběrem možnosti Další přejdete na krok Revize a dokončení.
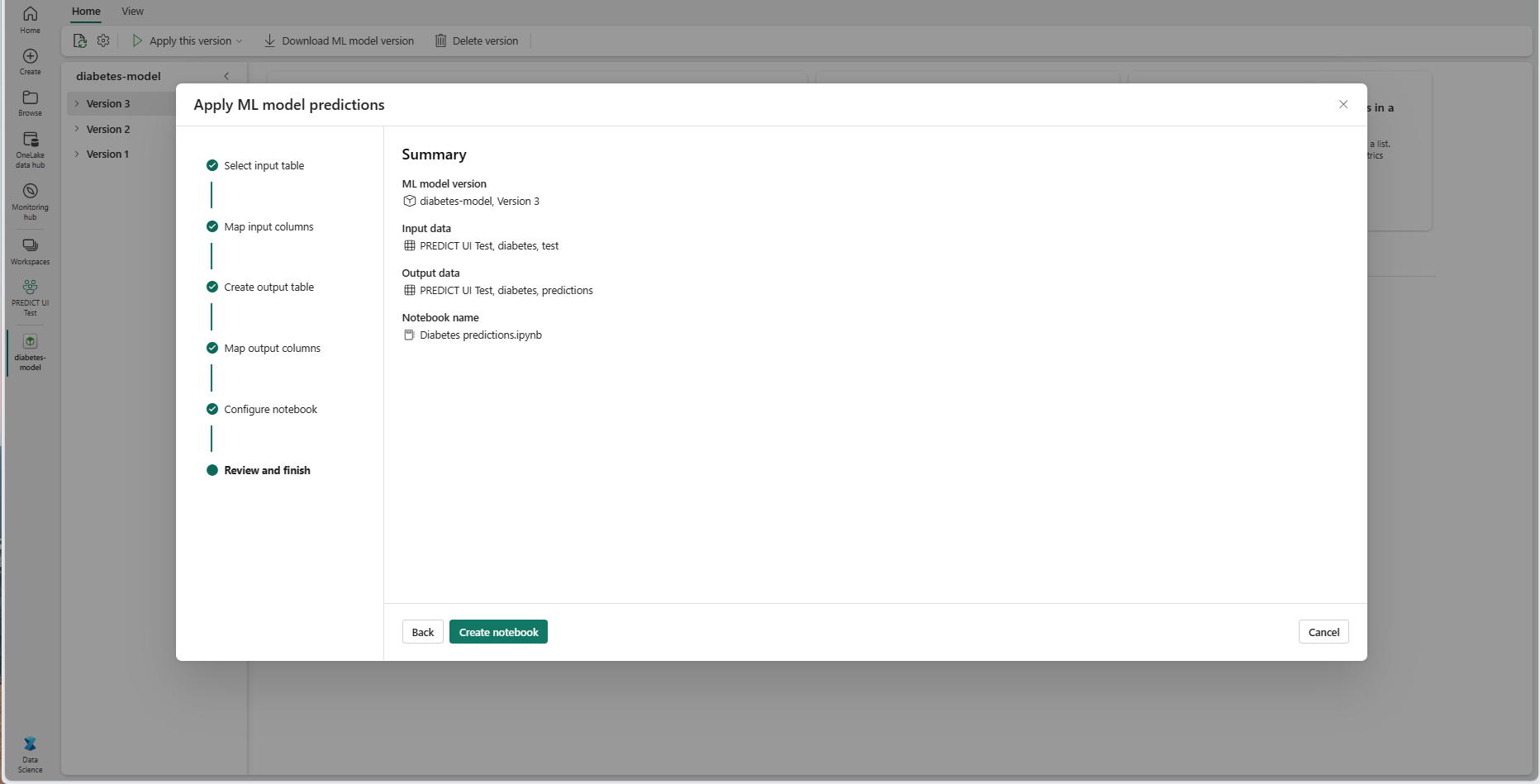
Zkontrolujte podrobnosti na stránce souhrnu a výběrem možnosti Vytvořit poznámkový blok přidejte nový poznámkový blok s jeho vygenerovaným kódem do pracovního prostoru. Dostanete se přímo do poznámkového bloku, kde můžete kód spustit pro generování a ukládání předpovědí.







Použití přizpůsobitelné šablony kódu
Použití šablony kódu pro generování dávkových předpovědí:
- Přejděte na stránku položky pro danou verzi modelu ML.
- V rozevíracím seznamu Použít tuto verzi vyberte Kopírovat kód. Výběr umožňuje kopírovat přizpůsobitelnou šablonu kódu.
Tuto šablonu kódu můžete vložit do poznámkového bloku a vygenerovat dávkové předpovědi pomocí modelu ML. Chcete-li úspěšně spustit šablonu kódu, musíte ručně nahradit následující hodnoty:
-
<INPUT_TABLE>: Cesta k souboru tabulky, která poskytuje vstupy do modelu ML -
<INPUT_COLS>: Pole názvů sloupců ze vstupní tabulky pro podávání do modelu ML -
<OUTPUT_COLS>: Název nového sloupce ve výstupní tabulce, která ukládá předpovědi -
<MODEL_NAME>: Název modelu ML, který se má použít pro generování předpovědí -
<MODEL_VERSION>: Verze modelu ML, která se má použít pro generování předpovědí -
<OUTPUT_TABLE>: Cesta k souboru pro tabulku, která ukládá predikce.

import mlflow
from synapse.ml.predict import MLFlowTransformer
df = spark.read.format("delta").load(
<INPUT_TABLE> # Your input table filepath here
)
model = MLFlowTransformer(
inputCols=<INPUT_COLS>, # Your input columns here
outputCol=<OUTPUT_COLS>, # Your new column name here
modelName=<MODEL_NAME>, # Your ML model name here
modelVersion=<MODEL_VERSION> # Your ML model version here
)
df = model.transform(df)
df.write.format('delta').mode("overwrite").save(
<OUTPUT_TABLE> # Your output table filepath here
)