Formát textu s oddělovači ve službě Data Factory v Microsoft Fabric
Tento článek popisuje, jak nakonfigurovat formát textu s oddělovači v datovém kanálu služby Data Factory v Microsoft Fabric.
Podporované funkce
Formát textu s oddělovači je podporovaný pro následující aktivity a konektory jako zdroj a cíl.
| Kategorie | Konektor nebo aktivita |
|---|---|
| Podporovaný konektor | Amazon S3 |
| Kompatibilní s Amazon S3 | |
| Azure Blob Storage | |
| Azure Data Lake Storage Gen1 | |
| Azure Data Lake Storage Gen2 | |
| Azure Files | |
| Systém souborů | |
| FTP | |
| Cloudové úložiště Googlu | |
| HTTP | |
| Soubory Lakehouse | |
| Oracle Cloud Storage | |
| SFTP | |
| Podporovaná aktivita | aktivita Copy (zdroj/cíl) |
| Aktivita Lookup | |
| Aktivita GetMetadata | |
| Aktivita odstranění |
Formát textu s oddělovači v aktivitě kopírování
Pokud chcete nakonfigurovat textový formát s oddělovači, zvolte připojení ve zdroji nebo cíli aktivity kopírování datového kanálu a pak v rozevíracím seznamu formát souboru vyberte Oddělovač text. Vyberte Nastavení pro další konfiguraci tohoto formátu.
Formát textu s oddělovači jako zdroj
Po výběru Nastavení v části Formát souboru se v dialogovém okně Nastavení formátu souboru zobrazí následující vlastnosti.
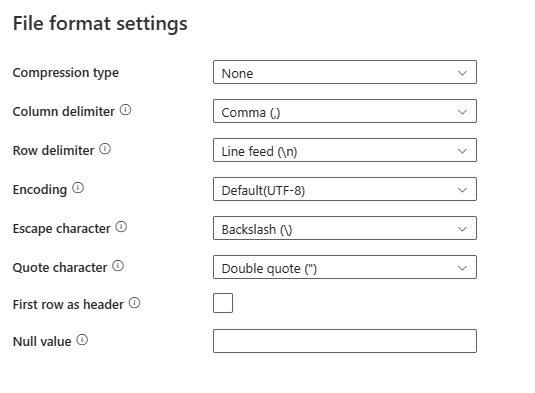
Typ komprese: Kodek komprese použitý ke čtení textových souborů s oddělovači. V rozevíracím seznamu si můžete vybrat z možností None, bzip2, gzip, deflate, ZipDeflate, TarGzip nebo tar type.
Pokud jako typ komprese vyberete ZipDeflate , zobrazí se název souboru ZIP jako složka v části Upřesnit nastavení na kartě Zdroj .
- Zachovat název souboru ZIP jako složku: Určuje, jestli se má při kopírování zachovat název zdrojového souboru ZIP jako struktura složek.
- Pokud je toto políčko zaškrtnuté (výchozí), služba zapíše rozbalené soubory do
<specified file path>/<folder named as source zip file>/. - Pokud toto políčko není zaškrtnuté, služba zapíše rozbalené soubory přímo do
<specified file path>. Ujistěte se, že v různých zdrojových souborech ZIP nemáte duplicitní názvy souborů, abyste se vyhnuli závodnímu nebo neočekávanému chování.
- Pokud je toto políčko zaškrtnuté (výchozí), služba zapíše rozbalené soubory do
Pokud jako typ komprese vyberete TarGzip/tar , zachová se název souboru komprese jako složka v části Upřesnit nastavení na kartě Zdroj .
- Zachovat název souboru komprese jako složku: Označuje, zda se má zachovat zdrojový komprimovaný název souboru jako struktura složek během kopírování.
- Pokud je toto políčko zaškrtnuté (výchozí), služba zapíše dekomprimované soubory do
<specified file path>/<folder named as source compressed file>/. - Pokud toto políčko není zaškrtnuté, služba zapíše dekomprimované soubory přímo do
<specified file path>. Ujistěte se, že v různých zdrojových souborech ZIP nemáte duplicitní názvy souborů, abyste se vyhnuli závodnímu nebo neočekávanému chování.
- Pokud je toto políčko zaškrtnuté (výchozí), služba zapíše dekomprimované soubory do
- Zachovat název souboru ZIP jako složku: Určuje, jestli se má při kopírování zachovat název zdrojového souboru ZIP jako struktura složek.
Úroveň komprese: Při výběru typu komprese zadejte poměr komprese. Můžete si vybrat z optimálního nebo nejrychlejšího.
Oddělovač sloupců: Znaky použité k oddělení sloupců v souboru. Výchozí hodnota je čárka (
,).Oddělovač řádků: Zadejte znak použitý k oddělení řádků v souboru. Je povolený jenom jeden znak. Výchozí hodnota je odřádkování
\n.Kódování: Typ kódování použitý k čtení a zápisu testovacích souborů. Výchozí hodnota je UTF-8.
Řídicí znak: Jeden znak pro řídicí uvozovky uvnitř uvozovek. Výchozí hodnota je zpětné lomítko
\. Pokud je řídicí znak definován jako prázdný řetězec, musí být znak uvozovky nastaven také jako prázdný řetězec. V takovém případě se ujistěte, že všechny hodnoty sloupců neobsahují oddělovače.Znak uvozovky: Jeden znak pro uvozovky hodnoty sloupce, pokud obsahuje oddělovač sloupců. Výchozí hodnota je dvojité uvozovky
". Pokud je znak uvozovky definován jako prázdný řetězec, znamená to, že neexistuje znak uvozovky a hodnota sloupce není uvozována, a řídicí znak se používá k řídicímu znaku oddělovače sloupců a samotný.První řádek jako záhlaví: Určuje, jestli má být první řádek považován za řádek záhlaví s názvy sloupců. Povolené hodnoty jsou vybrané a nevybrané (výchozí). Pokud není vybraný první řádek jako záhlaví, všimněte si, že náhled dat uživatelského rozhraní a výstup vyhledávací aktivity automaticky generují názvy sloupců jako Prop_{n} (počínaje 0), aktivita kopírování vyžaduje explicitní mapování ze zdroje na cíl a vyhledá sloupce podle řad (počínaje 1).
Hodnota Null: Určuje řetězcovou reprezentaci hodnoty null. Výchozí hodnota je prázdný řetězec.
V části Upřesnit nastavení na kartě Zdroj jsou vystaveny další vlastnosti související s textovým formátem s oddělovači.
Formát textu s oddělovači jako cíl
Po výběru Nastavení v části Formát souboru se v dialogovém okně Nastavení formátu souboru zobrazí následující vlastnosti.
Typ komprese: Kodek komprese použitý k zápisu textových souborů s oddělovači. V rozevíracím seznamu si můžete vybrat z možností None, bzip2, gzip, deflate, ZipDeflate, TarGzip nebo tar type.
Úroveň komprese: Při výběru typu komprese zadejte poměr komprese. Můžete si vybrat z optimálního nebo nejrychlejšího.
Oddělovač sloupců: Znaky použité k oddělení sloupců v souboru. Výchozí hodnota je čárka (
,).Oddělovač řádků: Znak použitý k oddělení řádků v souboru. Je povolený jenom jeden znak. Výchozí hodnota je odřádkování
\n.Kódování: Typ kódování použitý k zápisu testovacích souborů. Výchozí hodnota je UTF-8.
Řídicí znak: Jeden znak pro řídicí uvozovky uvnitř uvozovek. Výchozí hodnota je zpětné lomítko
\. Pokud je řídicí znak definován jako prázdný řetězec, musí být znak uvozovky nastaven také jako prázdný řetězec. V takovém případě se ujistěte, že všechny hodnoty sloupců neobsahují oddělovače.Znak uvozovky: Jeden znak pro uvozovky hodnoty sloupce, pokud obsahuje oddělovač sloupců. Výchozí hodnota je dvojité uvozovky
". Pokud je znak uvozovky definován jako prázdný řetězec, znamená to, že neexistuje znak uvozovky a hodnota sloupce není uvozována, a řídicí znak se používá k řídicímu znaku oddělovače sloupců a samotný.První řádek jako záhlaví: Určuje, jestli má být první řádek považován za řádek záhlaví s názvy sloupců. Povolené hodnoty jsou vybrané a nevybrané (výchozí). Pokud není vybraný první řádek jako záhlaví, všimněte si, že náhled dat uživatelského rozhraní a výstup vyhledávací aktivity automaticky generují názvy sloupců jako Prop_{n} (počínaje 0), aktivita kopírování vyžaduje explicitní mapování ze zdroje na cíl a vyhledá sloupce podle řad (počínaje 1).
Hodnota Null: Určuje řetězcovou reprezentaci hodnoty null. Výchozí hodnota je prázdný řetězec.
V části Upřesnit nastavení na kartě Cíl se zobrazí další vlastnost související s textovým formátem s oddělovači.
Uvozovek veškerý text: Uzavře všechny hodnoty do uvozovek.
Přípona souboru: Přípona souboru použitá k pojmenování výstupních souborů,
.csvnapříklad , ..txtMaximální počet řádků na soubor: Při zápisu dat do složky se můžete rozhodnout zapisovat do více souborů a zadat maximální počet řádků na soubor.
Předpona názvu souboru: Platí při konfiguraci maximálního počtu řádků na soubor . Při zápisu dat do více souborů zadejte předponu názvu souboru, výsledkem je tento vzor:
<fileNamePrefix>_00000.<fileExtension>. Pokud není zadána, automaticky se vygeneruje předpona názvu souboru. Tato vlastnost se nevztahuje, pokud zdroj je úložiště na základě souborů nebo možnost oddílu s povolenou možností úložiště dat.
Souhrn tabulky
Text s oddělovači jako zdroj
Následující vlastnosti jsou podporovány v části Zdroj aktivity kopírování při použití textového formátu s oddělovači.
| Jméno | Popis | Hodnota | Požadovaný | Vlastnost skriptu JSON |
|---|---|---|---|---|
| Formát souboru | Formát souboru, který chcete použít. | Text s oddělovači | Ano | typ (v části datasetSettings):Text s oddělovači |
| Typ komprese | Komprimační kodek používaný ke čtení textových souborů s oddělovači. | Můžete vybrat: Nic bzip2 gzip vyfouknout ZipDeflate TarGzip dehet |
No | typ (v části compression): bzip2 gzip vyfouknout ZipDeflate TarGzip dehet |
| Zachovat název souboru ZIP jako složku | Určuje, zda chcete zachovat název zdrojového souboru ZIP jako strukturu složek během kopírování. Platí pro výběr komprese ZipDeflate . | Výběr nebo zrušení výběru | Ne | preserveZipFileNameAsFolder (pod compressionProperties->type as ZipDeflateReadSettings) |
| Zachování názvu komprimačního souboru jako složky | Určuje, zda se má během kopírování zachovat zdrojový komprimovaný název souboru jako struktura složek. Platí pro výběr komprese TarGzip/tar . | Výběr nebo zrušení výběru | No | preserveCompressionFileNameAsFolder (pod compressionProperties->type jako TarGZipReadSettings nebo TarReadSettings) |
| Úroveň komprese | Poměr komprese. Povolené hodnoty jsou optimální nebo nejrychlejší. | Optimální nebo nejrychlejší | Ne | úroveň (v části compression): Nejrychlejší Optimální |
| Oddělovač sloupců | Znaky použité k oddělení sloupců v souboru. | < oddělovač vybraného sloupce > čárka , (ve výchozím nastavení) |
No | columnDelimiter |
| Oddělovač řádků | Znak, který slouží k oddělení řádků v souboru. | < oddělovač vybraných řádků > \r,\n (ve výchozím nastavení) nebo r\n |
Ne | rowDelimiter |
| Kódování | Typ kódování použitý k čtení a zápisu testovacích souborů. | "UTF-8" (ve výchozím nastavení),"UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM8869", "IBM88"70", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1252"1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Ne | encodingName |
| Řídicí znak | Jeden znak pro řídicí uvozovky uvnitř uvozovky. Pokud je řídicí znak definován jako prázdný řetězec, musí být znak uvozovky nastaven také jako prázdný řetězec. V takovém případě se ujistěte, že všechny hodnoty sloupců neobsahují oddělovače. | < vybraný řídicí znak > zpětné lomítko \ (ve výchozím nastavení) |
No | escapeChar |
| Znak uvozovek | Jeden znak pro uvozovky hodnoty sloupce, pokud obsahuje oddělovač sloupců. Pokud je znak uvozovky definován jako prázdný řetězec, znamená to, že neexistuje znak uvozovky a hodnota sloupce není uvozována, a řídicí znak se používá k řídicímu znaku oddělovače sloupců a samotný. | < vybraný znak uvozovky > dvojité uvozovky " (ve výchozím nastavení) |
No | quoteChar |
| První řádek jako záhlaví | Určuje, jestli se má první řádek v daném listu nebo oblasti považovat za řádek záhlaví s názvy sloupců. | Vybraná nebo nevybraná | No | firstRowAsHeader: true nebo false (výchozí) |
| Hodnota Null | Určuje řetězcovou reprezentaci hodnoty null. Výchozí hodnota je prázdný řetězec. | < řetězcová reprezentace hodnoty null > prázdný řetězec (ve výchozím nastavení) |
No | nullValue |
Text s oddělovači jako cíl
Následující vlastnosti jsou podporovány v části Cíl aktivity kopírování při použití textového formátu s oddělovači.
| Jméno | Popis | Hodnota | Požadovaný | Vlastnost skriptu JSON |
|---|---|---|---|---|
| Formát souboru | Formát souboru, který chcete použít. | Text s oddělovači | Ano | typ (v části datasetSettings):Text s oddělovači |
| Typ komprese | Komprimační kodek použitý k zápisu textových souborů s oddělovači. | Můžete vybrat: Nic bzip2 gzip vyfouknout ZipDeflate TarGzip dehet |
No | typ (v části compression): bzip2 gzip vyfouknout ZipDeflate TarGzip dehet |
| Zachovat název souboru ZIP jako složku | Určuje, zda chcete zachovat název zdrojového souboru ZIP jako strukturu složek během kopírování. | Výběr nebo zrušení výběru | Ne | preserveZipFileNameAsFolder (pod compressionProperties->type as ZipDeflateReadSettings) |
| Zachování názvu komprimačního souboru jako složky | Určuje, zda se má během kopírování zachovat zdrojový komprimovaný název souboru jako struktura složek. | Výběr nebo zrušení výběru | No | preserveCompressionFileNameAsFolder (pod compressionProperties->type jako TarGZipReadSettings nebo TarReadSettings) |
| Úroveň komprese | Poměr komprese. Povolené hodnoty jsou optimální nebo nejrychlejší. | Optimální nebo nejrychlejší | Ne | úroveň (v části compression): Nejrychlejší Optimální |
| Oddělovač sloupců | Znaky použité k oddělení sloupců v souboru. | < oddělovač vybraného sloupce > čárka , (ve výchozím nastavení) |
No | columnDelimiter |
| Oddělovač řádků | Znak, který slouží k oddělení řádků v souboru. | < oddělovač vybraných řádků > \r,\n (ve výchozím nastavení) nebo r\n |
Ne | rowDelimiter |
| Kódování | Typ kódování použitý k čtení a zápisu testovacích souborů. | "UTF-8" (ve výchozím nastavení),"UTF-8 bez BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM8869", "IBM88"70", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1252"1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258" | Ne | encodingName |
| Řídicí znak | Jeden znak pro řídicí uvozovky uvnitř uvozovky. Pokud je řídicí znak definován jako prázdný řetězec, musí být znak uvozovky nastaven také jako prázdný řetězec. V takovém případě se ujistěte, že všechny hodnoty sloupců neobsahují oddělovače. | < vybraný řídicí znak > zpětné lomítko \ (ve výchozím nastavení) |
No | escapeChar |
| Znak uvozovek | Jeden znak pro uvozovky hodnoty sloupce, pokud obsahuje oddělovač sloupců. Pokud je znak uvozovky definován jako prázdný řetězec, znamená to, že neexistuje znak uvozovky a hodnota sloupce není uvozována, a řídicí znak se používá k řídicímu znaku oddělovače sloupců a samotný. | < vybraný znak uvozovky > dvojité uvozovky " (ve výchozím nastavení) |
No | quoteChar |
| První řádek jako záhlaví | Určuje, jestli se má první řádek v daném listu nebo oblasti považovat za řádek záhlaví s názvy sloupců. | Vybraná nebo nevybraná | No | firstRowAsHeader: true nebo false (výchozí) |
| Citace veškerého textu | Uzavře všechny hodnoty do uvozovek. | Vybraná (výchozí) nebo nevybraná | No | quoteAllText: true (výchozí) nebo false |
| Přípona souboru | Přípona souboru použitá k pojmenování výstupních souborů. | < vaše přípona souboru > .txt (ve výchozím nastavení) |
No | fileExtension |
| Maximální počet řádků na soubor | Při zápisu dat do složky se můžete rozhodnout zapisovat do více souborů a zadat maximální počet řádků na soubor. | < maximální počet řádků na soubor > | No | maxRowsPerFile |
| Předpona názvu souboru | Platí pro konfiguraci maximálního počtu řádků na soubor . Při zápisu dat do více souborů zadejte předponu názvu souboru, výsledkem je tento vzor: <fileNamePrefix>_00000.<fileExtension>. Pokud není zadána, automaticky se vygeneruje předpona názvu souboru. Tato vlastnost se nevztahuje, pokud zdroj je úložiště na základě souborů nebo možnost oddílu s povolenou možností úložiště dat. |
< předpona názvu souboru > | No | fileNamePrefix |