Přírůstková aktualizace v Toku dat Gen2 (Preview)
V tomto článku zavádíme přírůstkovou aktualizaci dat v Toku dat Gen2 pro službu Data Factory Microsoft Fabric. Pokud používáte toky dat pro příjem a transformaci dat, existují scénáře, kdy potřebujete aktualizovat pouze nová nebo aktualizovaná data – zejména s tím, jak se vaše data stále rozšiřují. Funkce přírůstkové aktualizace tuto potřebu řeší tím, že umožňuje zkrátit dobu aktualizace, zvýšit spolehlivost tím, že se vyhnete dlouhotrvajícím operacím a minimalizujete využití prostředků.
Požadavky
Pokud chcete v Toku dat Gen2 použít přírůstkovou aktualizaci, musíte splnit následující požadavky:
- Musíte mít kapacitu Fabric.
- Váš zdroj dat podporuje posouvání (doporučeno) a musí obsahovat sloupec Date/DateTime, který se dá použít k filtrování dat.
- Měli byste mít cíl dat, který podporuje přírůstkovou aktualizaci. Další informace najdete v tématu Podpora cíle.
- Než začnete, ujistěte se, že jste zkontrolovali omezení přírůstkové aktualizace. Další informace najdete v tématu Omezení.
Cílová podpora
Přírůstková aktualizace podporuje následující cíle dat:
- Fabric Warehouse
- Azure SQL Database
- Azure Synapse Analytics
Další cíle, jako je Lakehouse, je možné použít v kombinaci s přírůstkovou aktualizací pomocí druhého dotazu, který odkazuje na fázovaná data k aktualizaci cíle dat. Díky tomu můžete stále používat přírůstkovou aktualizaci, abyste snížili množství dat, která je potřeba zpracovat a načíst ze zdrojového systému. Musíte ale provést úplnou aktualizaci z fázovaných dat do cíle dat.
Jak používat přírůstkovou aktualizaci
Vytvořte nový tok dat Gen2 nebo otevřete existující tok dat Gen2.
V editoru toku dat vytvořte nový dotaz, který načte data, která chcete aktualizovat přírůstkově.
Zkontrolujte náhled dat a ujistěte se, že dotaz vrací data obsahující sloupec DateTime, Date nebo DateTimeZone, který můžete použít k filtrování dat.
Ujistěte se, že se dotaz plně přeloží, což znamená, že dotaz je plně vložený do zdrojového systému. Pokud se dotaz úplně nepřeloží, musíte dotaz upravit tak, aby se plně přeložil. Pokud chcete zajistit, aby se dotaz plně sbalil, zkontrolujte kroky dotazu v editoru dotazů.
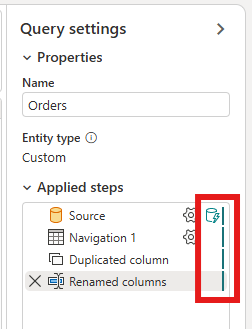
Klikněte pravým tlačítkem myši na dotaz a vyberte Přírůstková aktualizace.
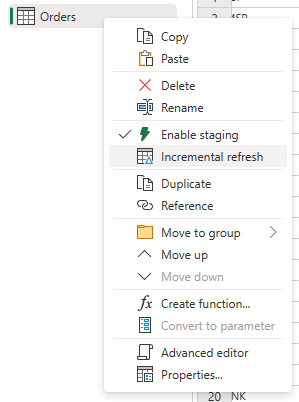
Zadejte požadovaná nastavení pro přírůstkovou aktualizaci.
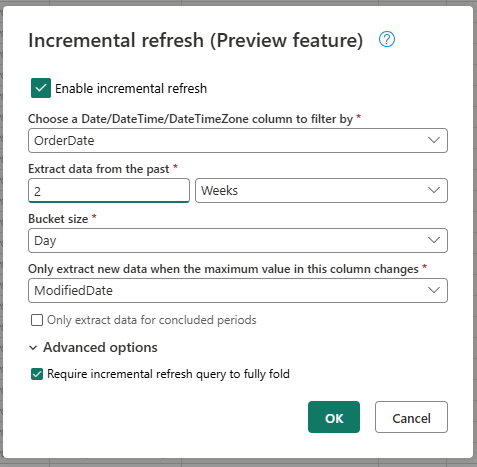
- Zvolte sloupec DateTime, podle které chcete filtrovat.
- Extrahujte data z minulosti.
- Velikost kbelíku
- Extrahujte nová data pouze v případě, že se změní maximální hodnota v tomto sloupci.
V případě potřeby nakonfigurujte upřesňující nastavení.
- Vyžaduje, aby se dotaz přírůstkové aktualizace plně sbalil.
Vyberte OK a uložte nastavení.
Pokud chcete, můžete teď nastavit cíl dat pro dotaz. Ujistěte se, že toto nastavení provedete před první přírůstkovou aktualizací, protože jinak cíl dat obsahuje pouze přírůstkově změněná data od poslední aktualizace.
Publikujte tok dat Gen2.
Po nakonfigurování přírůstkové aktualizace tok dat automaticky aktualizuje data přírůstkově na základě nastavení, která jste zadali. Tok dat načte pouze data, která se od poslední aktualizace změnila. Tok dat tedy běží rychleji a spotřebovává méně prostředků.
Jak přírůstková aktualizace funguje na pozadí
Přírůstková aktualizace funguje rozdělením dat do kbelíků na základě sloupce DateTime. Každý kbelík obsahuje data, která se od poslední aktualizace změnila. Tok dat ví, co se změnilo kontrolou maximální hodnoty ve sloupci, který jste zadali. Pokud se pro tento kbelík změnila maximální hodnota, tok dat načte celý kontejner a nahradí data v cíli. Pokud se maximální hodnota nezměnila, tok dat nenačte žádná data. Následující části obsahují základní přehled o tom, jak přírůstková aktualizace funguje krok za krokem.
První krok: Vyhodnocení změn
Při spuštění toku dat se nejprve vyhodnotí změny ve zdroji dat. Toto vyhodnocení provede porovnáním maximální hodnoty ve sloupci DateTime s maximální hodnotou v předchozí aktualizaci. Pokud se maximální hodnota změnila nebo pokud se jedná o první aktualizaci, označí tok dat kontejner jako změněný a vypíše ho ke zpracování. Pokud se maximální hodnota nezměnila, tok dat kontejner přeskočí a nezpracuje ho.
Druhý krok: Načtení dat
Teď je tok dat připravený k načtení dat. Načte data pro každý změněný kontejner. Tok dat provede toto načtení paralelně za účelem zlepšení výkonu. Tok dat načte data ze zdrojového systému a načte je do pracovní oblasti. Tok dat načte jenom data, která jsou v rozsahu kbelíku. Jinými slovy tok dat načte jenom data, která se od poslední aktualizace změnila.
Poslední krok: Nahrazení dat v cíli dat
Tok dat nahradí data v cíli novými daty. Tok dat používá metodu replace k nahrazení dat v cíli. To znamená, že tok dat nejprve odstraní data v cíli pro daný kbelík a pak vloží nová data. Tok dat nemá vliv na data, která jsou mimo rozsah kbelíku. Pokud tedy máte data v cíli, která jsou starší než první kbelík, přírůstková aktualizace tato data nijak neovlivní.
Vysvětlení nastavení přírůstkové aktualizace
Pokud chcete nakonfigurovat přírůstkovou aktualizaci, musíte zadat následující nastavení.
Obecné nastavení
Obecná nastavení jsou povinná a určují základní konfiguraci přírůstkové aktualizace.
Zvolte sloupec DateTime, podle které chcete filtrovat.
Toto nastavení je povinné a určuje sloupec, který toky dat používají k filtrování dat. Tento sloupec by měl být sloupec DateTime, Date nebo DateTimeZone. Tok dat používá tento sloupec k filtrování dat a načte pouze data, která se od poslední aktualizace změnila.
Extrakce dat z minulosti
Toto nastavení je povinné a určuje, jak daleko zpět v čase má tok dat extrahovat data. Toto nastavení slouží k načtení počátečního načtení dat. Tok dat načte všechna data ze zdrojového systému, který je v zadaném časovém rozsahu. Možné hodnoty jsou:
- x dní
- x týdnů
- x měsíců
- x čtvrtletí
- x let
Pokud zadáte například 1 měsíc, tok dat načte všechna nová data ze zdrojového systému, který spadá do posledního měsíce.
Velikost kbelíku
Toto nastavení je povinné a určuje velikost kontejnerů, které tok dat používá k filtrování dat. Tok dat rozdělí data do kbelíků na základě sloupce DateTime. Každý kbelík obsahuje data, která se od poslední aktualizace změnila. Velikost kbelíku určuje, kolik dat se zpracovává v každé iteraci. Menší velikost kbelíku znamená, že tok dat zpracovává v každé iteraci méně dat, ale také to znamená, že ke zpracování všech dat se vyžaduje více iterací. Větší velikost kbelíku znamená, že tok dat zpracovává v každé iteraci více dat, ale také to znamená, že ke zpracování všech dat je potřeba méně iterací.
Extrahování nových dat pouze v případě, že se změní maximální hodnota v tomto sloupci
Toto nastavení je povinné a určuje sloupec, který tok dat používá k určení, jestli se data změnila. Tok dat porovnává maximální hodnotu v tomto sloupci s maximální hodnotou v předchozí aktualizaci. Pokud se změní maximální hodnota, tok dat načte data, která se od poslední aktualizace změnila. Pokud se maximální hodnota nezmění, tok dat nenačte žádná data.
Extrahovat pouze data pro uzavřená období
Toto nastavení je volitelné a určuje, jestli by tok dat měl extrahovat pouze data za uzavřená období. Pokud je toto nastavení povolené, tok dat extrahuje pouze data po obdobích, která se ukončila. Tok dat tedy extrahuje jenom data za období, která jsou úplná a neobsahují žádná budoucí data. Pokud je toto nastavení zakázané, tok dat extrahuje data pro všechna období včetně období, která nejsou dokončená a neobsahují budoucí data.
Pokud máte například sloupec DateTime, který obsahuje datum transakce a chcete aktualizovat pouze dokončené měsíce, můžete toto nastavení povolit v kombinacích s velikostí kbelíku month. Tok dat proto extrahuje jenom data po celé měsíce a neextrahuje data po neúplné měsíce.
Rozšířené nastavení
Některá nastavení se považují za pokročilá a ve většině scénářů se nevyžadují.
Vyžadovat plně složený dotaz přírůstkové aktualizace
Toto nastavení je volitelné a určuje, jestli se dotaz použitý pro přírůstkovou aktualizaci musí plně sbalit. Pokud je toto nastavení povolené, musí se dotaz použitý pro přírůstkovou aktualizaci plně sbalit. Jinými slovy, dotaz musí být plně vložen do zdrojového systému. Pokud je toto nastavení zakázané, dotaz použitý pro přírůstkovou aktualizaci nemusí být plně složený. V tomto případě může být dotaz částečně posunut do zdrojového systému. Důrazně doporučujeme povolit toto nastavení, aby se zlepšil výkon, aby se zabránilo načítání nepotřebných a nefiltrovaných dat.
Omezení
Podporují se pouze cíle dat založené na SQL.
V současné době se pro přírůstkovou aktualizaci podporují jenom cíle dat založené na SQL. Pro přírůstkovou aktualizaci tedy můžete jako cíl dat použít pouze Fabric Warehouse, Azure SQL Database nebo Azure Synapse Analytics. Důvodem tohoto omezení je, že tyto cíle dat podporují operace založené na SQL, které jsou vyžadovány pro přírůstkovou aktualizaci. Operace Delete a Insert slouží k nahrazení dat v cíli dat, která není možné provádět paralelně s jinými cíli dat.
Cíl dat musí být nastavený na pevné schéma.
Cíl dat musí být nastavený na pevné schéma, což znamená, že schéma tabulky v cíli dat musí být pevné a nemůže se změnit. Pokud je schéma tabulky v cíli dat nastavené na dynamické schéma, musíte ho před konfigurací přírůstkové aktualizace změnit na pevné schéma.
Jediná podporovaná metoda aktualizace v cíli dat je replace
Jedinou podporovanou metodou aktualizace v cíli dat je replace, což znamená, že tok dat nahradí data pro každý kbelík v cíli dat novými daty. Na data mimo rozsah kbelíku to ale nemá vliv. Pokud tedy máte data v cíli dat, která jsou starší než první kbelík, přírůstková aktualizace tato data nijak neovlivní.
Maximální počet kbelíků je 50 pro jeden dotaz a 150 pro celý tok dat.
Maximální počet kbelíků na dotaz, který tok dat podporuje, je 50. Pokud máte více než 50 kbelíků, je potřeba zvětšit velikost kbelíku nebo zmenšit rozsah kbelíku a snížit tak počet kbelíků. Maximální počet kbelíků pro celý tok dat je 150. Pokud máte v toku dat více než 150 kbelíků, musíte snížit počet dotazů přírůstkové aktualizace nebo zvětšit velikost kontejneru, abyste snížili počet kontejnerů.
Rozdíly mezi přírůstkovou aktualizací v Toku dat Gen1 a Tokem dat Gen2
Mezi tokem Dataflow Gen1 a Dataflow Gen2 existují určité rozdíly v tom, jak přírůstková aktualizace funguje. Následující seznam vysvětluje hlavní rozdíly mezi přírůstkovou aktualizací v Toku dat Gen1 a Dataflow Gen2.
- Přírůstková aktualizace je teď ve službě Dataflow Gen2 prvotřídní funkcí. V Toku dat Gen1 jste museli po publikování toku dat nakonfigurovat přírůstkovou aktualizaci. Přírůstková aktualizace v Toku dat Gen2 je teď prvotřídní funkcí, kterou můžete nakonfigurovat přímo v editoru toku dat. Tato funkce usnadňuje konfiguraci přírůstkové aktualizace a snižuje riziko chyb.
- V Toku dat Gen1 jste museli při konfiguraci přírůstkové aktualizace zadat historický rozsah dat. V Toku dat Gen2 nemusíte zadávat historický rozsah dat. Tok dat neodebere žádná data z cíle, který je mimo rozsah kbelíku. Pokud tedy máte data v cíli, která jsou starší než první kbelík, přírůstková aktualizace tato data nijak neovlivní.
- V Toku dat Gen1 jste museli při konfiguraci přírůstkové aktualizace zadat parametry přírůstkové aktualizace. V Toku dat Gen2 nemusíte zadávat parametry přírůstkové aktualizace. Tok dat automaticky přidá filtry a parametry jako poslední krok v dotazu. Proto nemusíte parametry přírůstkové aktualizace zadávat ručně.
Často kladené dotazy
Zobrazilo se mi upozornění, že jsem ke zjišťování změn a filtrování použil stejný sloupec. Co to znamená?
Pokud se zobrazí upozornění, že jste ke zjišťování změn a filtrování použili stejný sloupec, znamená to, že sloupec, který jste zadali pro zjišťování změn, se používá také k filtrování dat. Toto použití nedoporučujeme, protože může vést k neočekávaným výsledkům. Místo toho doporučujeme k detekci změn a filtrování dat použít jiný sloupec. Pokud se data mezi kontejnery posunou, nemusí tok dat správně rozpoznat změny a může v cíli vytvořit duplicitní data. Toto upozornění můžete vyřešit pomocí jiného sloupce pro detekci změn a filtrování dat. Nebo můžete upozornění ignorovat, pokud jste si jistí, že se data mezi aktualizacemi zadaného sloupce nemění.
Chci použít přírůstkovou aktualizaci s cílem dat, který není podporovaný. Co mám dělat?
Pokud chcete použít přírůstkovou aktualizaci s cílem dat, který není podporovaný, můžete v dotazu povolit přírůstkovou aktualizaci a použít druhý dotaz, který odkazuje na fázovaná data k aktualizaci cíle dat. Pomocí přírůstkové aktualizace tak můžete snížit množství dat, která je potřeba zpracovat a načíst ze zdrojového systému, ale musíte provést úplnou aktualizaci z připravených dat do cíle dat. Ujistěte se, že jste správně nastavili velikost okna a kbelíku, protože nezaručujeme, že se data v přípravném prostředí zachovají mimo rozsah kbelíku.
Návody vědět, jestli má dotaz povolenou přírůstkovou aktualizaci?
Pokud je u dotazu povolená přírůstková aktualizace, můžete zkontrolovat ikonu vedle dotazu v editoru toku dat. Pokud ikona obsahuje modrý trojúhelník, je povolená přírůstková aktualizace. Pokud ikona neobsahuje modrý trojúhelník, přírůstková aktualizace není povolená.
Když používám přírůstkovou aktualizaci, zdroj získá příliš mnoho požadavků. Co mám dělat?
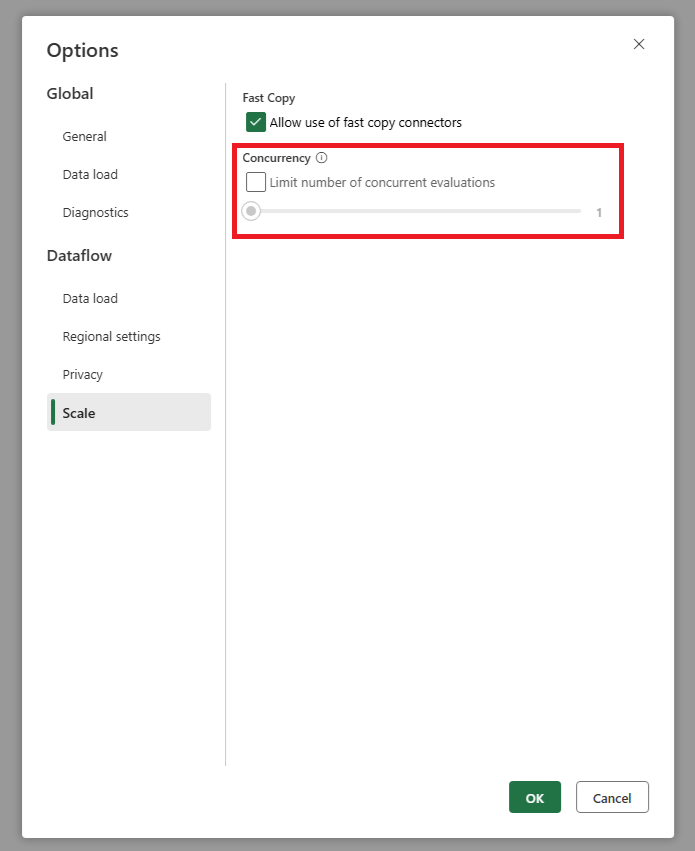
Přidali jsme nastavení, které vám umožní nastavit maximální počet paralelních vyhodnocení dotazů. Toto nastavení najdete v globálním nastavení toku dat. Nastavením této hodnoty na nižší číslo můžete snížit počet požadavků odeslaných do zdrojového systému. Toto nastavení může pomoct snížit počet souběžných požadavků a zlepšit výkon zdrojového systému. Pokud chcete nastavit maximální počet paralelních spuštění dotazů, přejděte do globálního nastavení toku dat, přejděte na kartu Škálování a nastavte maximální počet paralelních vyhodnocení dotazů. Doporučujeme nepovolovat tento limit, pokud nemáte problémy se zdrojovým systémem.
Chci použít přírůstkovou aktualizaci, ale po povolení vidím, že aktualizace toku dat trvá déle. Co mám dělat?
Přírůstková aktualizace, jak je popsáno v tomto článku, je navržená tak, aby snížila množství dat, která je potřeba zpracovat a načíst ze zdrojového systému. Pokud ale aktualizace toku dat po povolení přírůstkové aktualizace trvá déle, může to být proto, že zvýšená režie při kontrole, jestli se data změnila a zpracování košů, je vyšší než čas ušetřený zpracováním menšího množství dat. V takovém případě doporučujeme zkontrolovat nastavení přírůstkové aktualizace a upravit je tak, aby lépe vyhovovaly vašemu scénáři. Můžete například zvětšit velikost kontejneru, abyste snížili počet kbelíků a režijní náklady na jejich zpracování. Nebo můžete snížit počet kbelíků zvětšením velikosti kontejneru. Pokud po úpravě nastavení stále dochází k nízkému výkonu, můžete přírůstkovou aktualizaci zakázat a místo toho použít úplnou aktualizaci, protože to může být ve vašem scénáři efektivnější.