Konfigurace služby Azure Synapse Analytics v aktivitě kopírování
Tento článek popisuje, jak pomocí aktivity kopírování v datovém kanálu kopírovat data z a do Azure Synapse Analytics.
Podporovaná konfigurace
Konfigurace každé karty v aktivitě kopírování najdete v následujících částech.
OBECNÉ
Informace o konfiguraci karty Obecné nastavení najdete v doprovodných materiálech k obecným nastavením.
Zdroj
Následující vlastnosti jsou podporované pro Azure Synapse Analytics na kartě Zdroj aktivity kopírování.

Jsou vyžadovány následující vlastnosti:
Typ úložiště dat: Vyberte externí.
Připojení ion: Ze seznamu připojení vyberte připojení Azure Synapse Analytics. Pokud připojení neexistuje, vytvořte nové připojení Azure Synapse Analytics výběrem možnosti Nový.
typ Připojení: Vyberte Azure Synapse Analytics.
Použití dotazu: Ke čtení zdrojových dat můžete zvolit tabulku, dotaz nebo uloženou proceduru . Následující seznam popisuje konfiguraci jednotlivých nastavení:
Tabulka: Pokud vyberete toto tlačítko, načtěte data z tabulky, kterou jste zadali v tabulce . Vyberte tabulku z rozevíracího seznamu nebo vyberte Upravit a zadejte schéma a název tabulky ručně.

Dotaz: Zadejte vlastní dotaz SQL pro čtení dat. Příklad:
select * from MyTable. Nebo vyberte ikonu tužky, která se má upravit v editoru kódu.
Uložená procedura: Použijte uloženou proceduru, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře.

- Název uložené procedury: Vyberte uloženou proceduru nebo při výběru možnosti Upravit zadejte název uložené procedury ručně.
- Parametry uložené procedury: Vyberte Importovat parametry pro import parametru v zadané uložené proceduře nebo přidejte parametry pro uloženou proceduru výběrem + Nový. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury.

V části Upřesnit můžete zadat následující pole:
Časový limit dotazu (minuty):Zadejte časový limit pro spuštění příkazu dotazu, výchozí hodnota je 120 minut. Pokud je pro tuto vlastnost nastaven parametr, jsou povolené hodnoty časový rozsah, například 02:00:00 (120 minut).
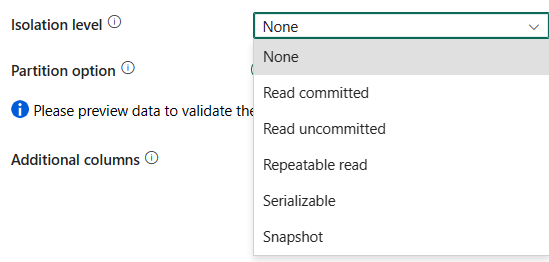
Úroveň izolace: Určuje chování zamykání transakce pro zdroj SQL. Povolené hodnoty jsou: None, Read committed, Read uncommitted, Repeatable read, Serializable nebo Snapshot. Pokud není zadána, použije se úroveň izolace Žádná . Další podrobnosti najdete v výčtu IsolationLevel.
Možnost oddílu: Zadejte možnosti dělení dat, které se používají k načtení dat z Azure Synapse Analytics. Povolené hodnoty jsou: Žádné (výchozí), fyzické oddíly tabulky a dynamický rozsah. Pokud je povolená možnost oddílu (tj. žádná), je stupeň paralelismu souběžného načítání dat z Azure Synapse Analytics řízen nastavením paralelního kopírování aktivity kopírování.
Žádné: Toto nastavení zvolte, pokud nechcete oddíl používat.
Fyzické oddíly tabulky: Toto nastavení zvolte, pokud chcete použít fyzický oddíl. Sloupec a mechanismus oddílu se automaticky určují na základě definice fyzické tabulky.
Dynamická oblast: Toto nastavení zvolte, pokud chcete použít oddíl dynamického rozsahu. Při použití dotazu s povoleným paralelně je potřeba parametr oddílu rozsahu(
?DfDynamicRangePartitionCondition). Ukázkový dotaz:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.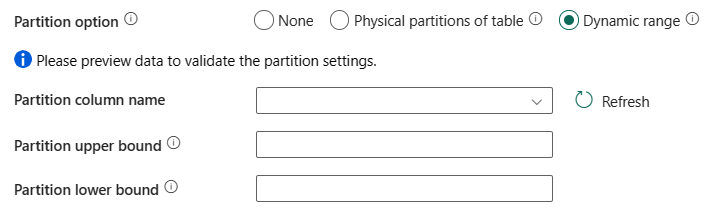
- Název sloupce oddílu: Zadejte název zdrojového sloupce v celočíselném nebo typu date/datetime (
int,smallint,bigint,date,smalldatetime,datetime,datetime2, nebodatetimeoffset), který se používá při dělení rozsahu pro paralelní kopírování. Pokud není zadaný, index nebo primární klíč tabulky se automaticky rozdetekuje a použije se jako sloupec oddílu. - Horní mez oddílu: Zadejte maximální hodnotu sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují.
- Dolní mez oddílu: Zadejte minimální hodnotu sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují.
- Název sloupce oddílu: Zadejte název zdrojového sloupce v celočíselném nebo typu date/datetime (
Další sloupce: Přidejte další datové sloupce pro ukládání relativní cesty nebo statické hodnoty zdrojových souborů. U druhého výrazu se podporuje. Další informace najdete v tématu Přidání dalších sloupců během kopírování.
Cíl
Pro Azure Synapse Analytics se na kartě Cíl aktivity kopírování podporují následující vlastnosti.
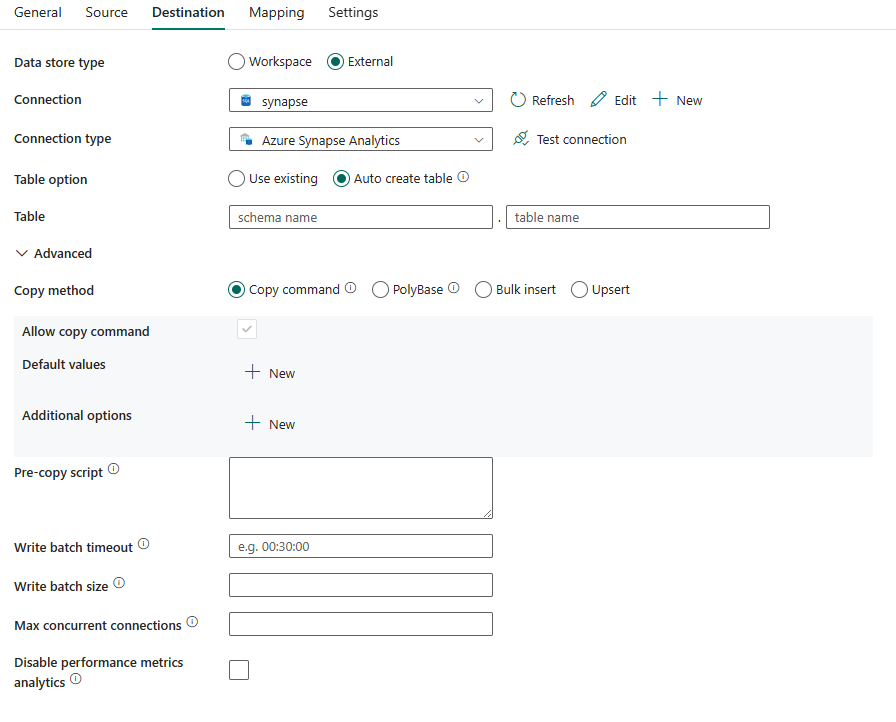
Jsou vyžadovány následující vlastnosti:
- Typ úložiště dat: Vyberte externí.
- Připojení ion: Ze seznamu připojení vyberte připojení Azure Synapse Analytics. Pokud připojení neexistuje, vytvořte nové připojení Azure Synapse Analytics výběrem možnosti Nový.
- typ Připojení: Vyberte Azure Synapse Analytics.
- Možnost Tabulka: Můžete zvolit Použít existující tabulku, automaticky vytvořit tabulku. Následující seznam popisuje konfiguraci jednotlivých nastavení:
- Použít existující: V rozevíracím seznamu vyberte tabulku v databázi. Nebo zaškrtněte políčko Upravit a zadejte název schématu a tabulky ručně.
- Automaticky vytvořit tabulku: Automaticky vytvoří tabulku (pokud neexistuje) ve zdrojovém schématu.
V části Upřesnit můžete zadat následující pole:
Metoda kopírování Zvolte metodu, kterou chcete použít ke kopírování dat. Můžete zvolit příkaz Kopírovat, PolyBase, Hromadné vložení nebo Upsert. Následující seznam popisuje konfiguraci jednotlivých nastavení:
Příkaz pro kopírování: Příkaz COPY slouží k načtení dat z úložiště Azure do Azure Synapse Analytics nebo fondu SQL.
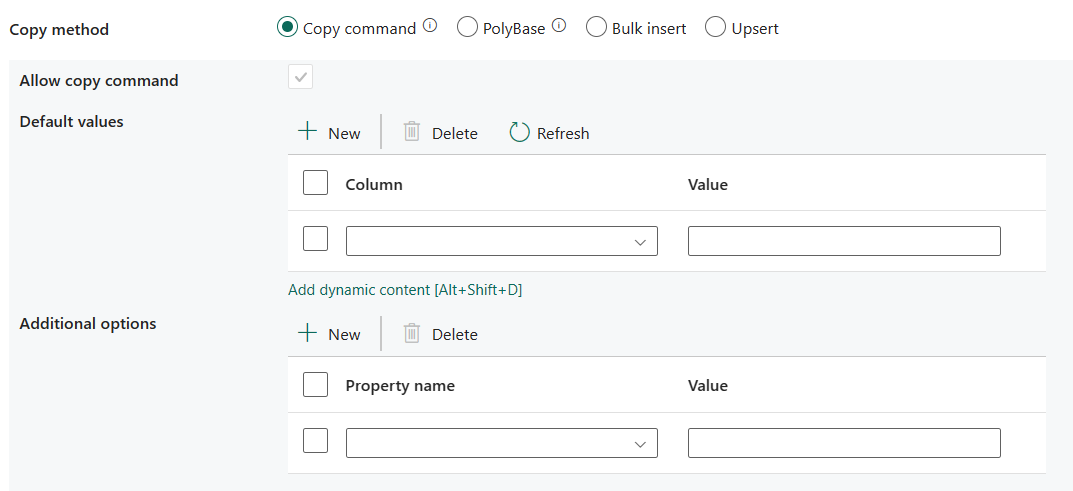
- Povolit kopírování: Je povinné vybrat, když zvolíte příkaz Kopírovat.
- Výchozí hodnoty: Zadejte výchozí hodnoty pro každý cílový sloupec ve službě Azure Synapse Analytics. Výchozí hodnoty ve vlastnosti přepíší omezení DEFAULT nastavené v datovém skladu a sloupec identity nemůže mít výchozí hodnotu.
- Další možnosti: Další možnosti, které se předají do příkazu COPY služby Azure Synapse Analytics přímo v klauzuli With v příkazu COPY. Podle potřeby uvozujte hodnotu tak, aby odpovídala požadavkům příkazu COPY.
PolyBase: PolyBase je mechanismus vysoké propustnosti. Můžete ho použít k načtení velkých objemů dat do Azure Synapse Analytics nebo fondu SQL.
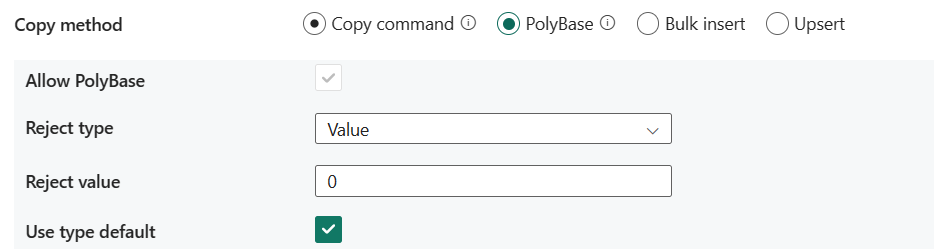
- Povolit PolyBase: Je povinné vybrat při výběru PolyBase.
- Typ odmítnutí: Určete, zda je možnost rejectValue literál nebo procento. Povolené hodnoty jsou Hodnota (výchozí) a Procento.
- Hodnota zamítnutí: Zadejte počet nebo procento řádků, které lze odmítnout před selháním dotazu. Další informace o možnostech zamítnutí PolyBase najdete v části Argumenty create EXTERNAL TABLE (Transact-SQL). Povolené hodnoty jsou 0 (výchozí), 1, 2 atd.
- Odmítnout ukázkovou hodnotu: Určuje počet řádků, které se mají načíst, než PolyBase přepočítá procento odmítnutých řádků. Povolené hodnoty jsou 1, 2 atd. Pokud jako typ zamítnutí zvolíte Procento , je tato vlastnost povinná.
- Použít výchozí typ: Určete, jak zpracovat chybějící hodnoty v textových souborech s oddělovači, když PolyBase načte data z textového souboru. Další informace o této vlastnosti najdete v části Argumenty ve formátu CREATE EXTERNAL FILE FORMAT (Transact-SQL). Povolené hodnoty jsou vybrané (výchozí) nebo nevybrané.
Hromadné vložení: Pomocí hromadného vložení můžete vložit data do cíle hromadně.

- Zámek tabulky hromadného vložení: Tento postup slouží ke zlepšení výkonu kopírování během hromadné operace vložení tabulky bez indexu z více klientů. Další informace najdete v příkazu BULK INSERT (Transact-SQL).
Upsert: Určete skupinu nastavení pro chování zápisu, pokud chcete přenést data do cíle.
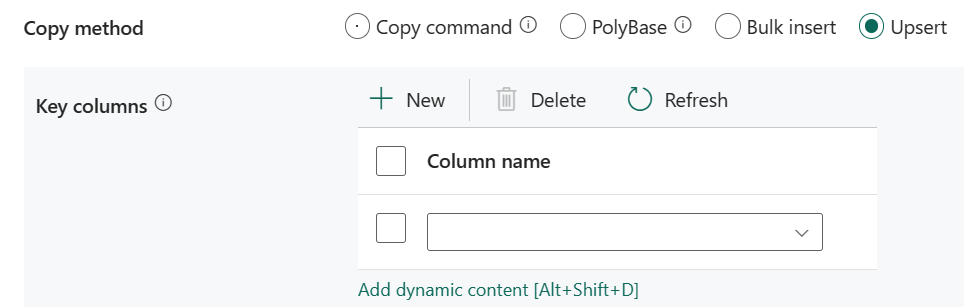
Klíčové sloupce: Zvolte, který sloupec se použije k určení, jestli řádek ze zdroje odpovídá řádku z cíle.
Zámek tabulky hromadného vložení: Tento postup slouží ke zlepšení výkonu kopírování během hromadné operace vložení tabulky bez indexu z více klientů. Další informace najdete v příkazu BULK INSERT (Transact-SQL).
Skript předběžného kopírování: Zadejte skript pro aktivitu kopírování, který se má spustit před zápisem dat do cílové tabulky v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat.
Časový limit dávky zápisu: Zadejte dobu čekání na dokončení operace dávkového vložení, než vyprší časový limit. Povolená hodnota je časový rozsah. Výchozí hodnota je 00:30:00 (30 minut).
Velikost dávky zápisu: Zadejte počet řádků, které se mají vložit do tabulky SQL na dávku. Povolená hodnota je celé číslo (počet řádků). Ve výchozím nastavení služba dynamicky určuje odpovídající velikost dávky na základě velikosti řádku.
Maximální počet souběžných připojení: Zadejte horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení.
Zakázat analýzu metrik výkonu: Toto nastavení slouží ke shromažďování metrik, jako jsou DTU, DWU, RU atd., pro optimalizaci výkonu kopírování a doporučení. Pokud máte obavy o toto chování, zaškrtněte toto políčko. Ve výchozím nastavení není vybraná.
Přímé kopírování pomocí příkazu COPY
Příkaz COPY pro Azure Synapse Analytics přímo podporuje Azure Blob Storage a Azure Data Lake Storage Gen2 jako zdrojová úložiště dat. Pokud zdrojová data splňují kritéria popsaná v této části, pomocí příkazu COPY zkopírujte přímo ze zdrojového úložiště dat do Azure Synapse Analytics.
Zdrojová data a formát obsahují následující typy a metody ověřování:
Podporovaný typ zdrojového úložiště dat Podporovaný formát Podporovaný typ ověřování zdroje Azure Blob Storage Text s oddělovači
ParquetAnonymní ověření
Ověřování pomocí klíče účtu
Ověřování pomocí sdíleného přístupového podpisuAzure Data Lake Storage Gen2 Text s oddělovači
ParquetOvěřování pomocí klíče účtu
Ověřování pomocí sdíleného přístupového podpisuMůžete nastavit následující nastavení formátu:
- Pro Parquet: Typ komprese může být None, snappy nebo gzip.
- Text s oddělovači:
- Oddělovač řádků: Při kopírování textu s oddělovači do Azure Synapse Analytics prostřednictvím přímého příkazu COPY zadejte explicitně oddělovač řádků (\r; \n; nebo \r\n). Pouze v případě, že oddělovač řádků zdrojového souboru je \r\n, funguje výchozí hodnota (\r, \n nebo \r\n). Jinak povolte přípravu pro váš scénář.
- Hodnota Null je ponechána jako výchozí nebo je nastavena na prázdný řetězec ("").
- Kódování je ponecháno jako výchozí nebo nastaveno na UTF-8 nebo UTF-16.
- Vynechání počtu řádků je ponecháno jako výchozí nebo je nastaveno na 0.
- Typ komprese může být None nebo gzip.
Pokud je zdrojem složka, musíte zaškrtnout políčko Rekurzivně .
Počáteční čas (UTC) a Koncový čas (UTC) ve filtru podle poslední změny, předpony, povolení zjišťování oddílů a dalších sloupců nejsou zadané.
Informace o příjmu dat do Azure Synapse Analytics pomocí příkazu COPY najdete v tomto článku.
Pokud zdrojové úložiště dat a formát není původně podporováno příkazem COPY, použijte místo toho fázovanou kopii pomocí funkce PŘÍKAZU COPY. Automaticky převede data do formátu kompatibilního s příkazem COPY a potom zavolá příkaz COPY, který načte data do Azure Synapse Analytics.
mapování.
Pokud pro konfiguraci karty Mapování nepoužijete Azure Synapse Analytics s automatickým vytvořením tabulky jako cíle, přejděte na Mapování.
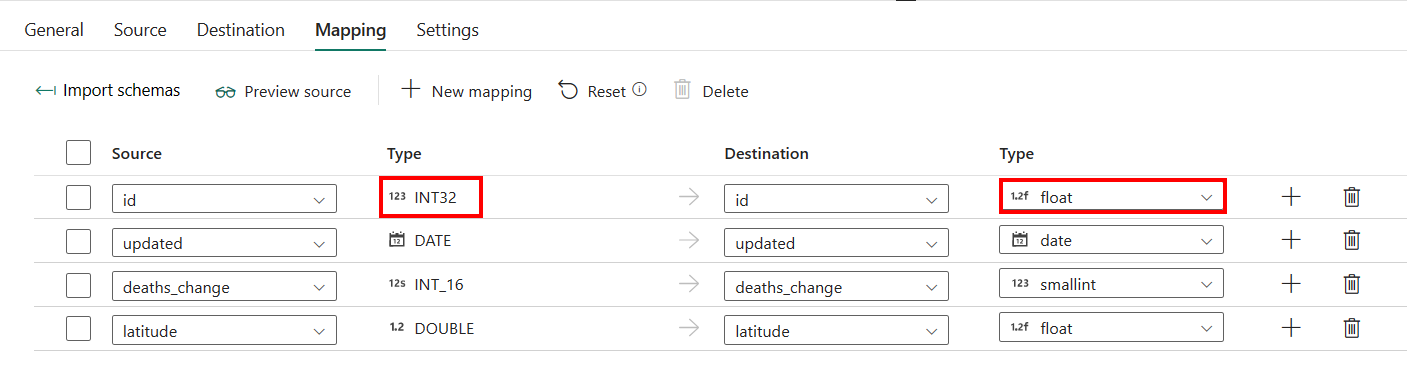
Pokud použijete Azure Synapse Analytics s automatickým vytvořením tabulky jako cíle s výjimkou konfigurace v mapování, můžete typ cílových sloupců upravit. Po výběru schémat importu můžete zadat typ sloupce v cíli.
Například typ sloupce ID ve zdroji je int a můžete ho změnit na typ float při mapování na cílový sloupec.
Nastavení
V případě konfigurace karty Nastavení přejděte na Konfigurovat další nastavení na kartě Nastavení.
Paralelní kopírování z Azure Synapse Analytics
Konektor Azure Synapse Analytics v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.
Když povolíte dělené kopírování, aktivita kopírování spouští paralelní dotazy na zdroj Azure Synapse Analytics, aby načetla data podle oddílů. Paralelní stupeň je řízen stupněm paralelismu kopírování na kartě nastavení aktivity kopírování. Pokud například nastavíte stupeň paralelismu kopírování na čtyři, služba souběžně generuje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z vaší služby Azure Synapse Analytics.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z Azure Synapse Analytics. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly | Možnost oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. Pokud chcete zkontrolovat, jestli tabulka obsahuje fyzický oddíl nebo ne, můžete odkazovat na tento dotaz. |
| Úplné načtení z velké tabulky bez fyzických oddílů, zatímco s celočíselnou nebo datetime sloupcem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Sloupec oddílu (volitelné): Zadejte sloupec použitý k dělení dat. Pokud není zadaný, použije se sloupec indexu nebo primárního klíče. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky v tabulce budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnoty. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez jako 80, přičemž paralelní kopírování je 4, služba načte data o 4 oddílech – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, zatímco s celočíselnou nebo datem a datem a časem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky ve výsledku dotazu budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez 80, přičemž paralelní kopírování je 4, služba načte data podle 4 oddílů v rozsahu <=20, [21, 50], [51, 80] a >=81. Tady jsou další ukázkové dotazy pro různé scénáře: • Zadejte dotaz na celou tabulku: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Dotaz z tabulky s výběrem sloupce a dalšími filtry klauzule where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s poddotazy: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s oddílem v poddotazu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Osvědčené postupy pro načtení dat s možností oddílu:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje předdefinovaný oddíl, pomocí možnosti oddílu Fyzické oddíly tabulky získáte lepší výkon.
- Azure Synapse Analytics může najednou spouštět maximálně 32 dotazů. Nastavení stupně paralelismu kopírování může způsobit problém s omezováním Synapse.
Ukázkový dotaz pro kontrolu fyzického oddílu
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Pokud tabulka obsahuje fyzický oddíl, zobrazí se hodnota HasPartition jako ano.
Souhrn tabulky
Následující tabulky obsahují další informace o aktivitě kopírování ve službě Azure Synapse Analytics.
Zdroj
| Název | Popis | Hodnota | Požaduje se | Vlastnost skriptu JSON |
|---|---|---|---|---|
| Typ úložiště dat | Váš typ úložiště dat. | Externí | Ano | / |
| Připojení | Vaše připojení ke zdrojovému úložišti dat. | < vaše připojení > | Ano | připojení |
| Typ připojení: | Typ zdrojového připojení. | Azure Synapse Analytics | Ano | / |
| Použití dotazu | Způsob čtení dat. | •Tabulka •Dotazu • Uložená procedura |
Ano | • typeProperties (pod typeProperties ->source)-Schématu -Tabulka • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters -Jméno -Hodnotu |
| Časový limit dotazu | Časový limit spuštění příkazu dotazu je ve výchozím nastavení 120 minut. | timespan | No | queryTimeout |
| Úroveň izolace | Chování uzamčení transakce pro zdroj SQL. | •Žádný • Čtení potvrzeno • Nepotvrzené čtení • Opakovatelné čtení •Serializovatelný •Snímek |
No | Isolationlevel: •Readcommitted •Readuncommitted •Repeatableread •Serializovatelný •Snímek |
| Možnost oddílu | Možnosti dělení dat používané k načtení dat ze služby Azure SQL Database. | •Žádný • Fyzické oddíly tabulky • Dynamický rozsah – Název sloupce oddílu - Horní mez oddílu – Dolní mez oddílu |
No | partitionOption: • PhysicalPartitionsOfTable • DynamicRange oddíl Nastavení: – partitionColumnName – partitionUpperBound – partitionLowerBound |
| Další sloupce | Přidejte další datové sloupce pro ukládání relativní cesty ke zdrojovým souborům nebo statické hodnotě. U druhého výrazu se podporuje. | • Jméno •Hodnotu |
No | additionalColumns: •Jméno •Hodnotu |
Cíl
| Název | Popis | Hodnota | Požaduje se | Vlastnost skriptu JSON |
|---|---|---|---|---|
| Typ úložiště dat | Váš typ úložiště dat. | Externí | Ano | / |
| Připojení | Vaše připojení k cílovému úložišti dat. | < vaše připojení > | Ano | připojení |
| Typ připojení: | Typ cílového připojení. | Azure Synapse Analytics | Ano | / |
| Možnost Tabulka | Možnost cílové tabulky dat | • Použít existující • Automaticky vytvořit tabulku |
Ano | • typeProperties (pod typeProperties ->sink)-Schématu -Tabulka • tableOption: - autoCreate typeProperties (v části typeProperties ->sink)-Schématu -Tabulka |
| Metoda kopírování | Metoda použitá ke kopírování dat. | • Kopírovat příkaz • PolyBase • Hromadné vkládání • Upsert |
No | / |
| Při výběru příkazu Kopírovat | Příkaz COPY slouží k načtení dat z úložiště Azure do Azure Synapse Analytics nebo fondu SQL. | / | Ne. Použít při použití funkce COPY. |
allowCopyCommand: true copyCommand Nastavení |
| Výchozí hodnoty | Zadejte výchozí hodnoty pro každý cílový sloupec ve službě Azure Synapse Analytics. Výchozí hodnoty ve vlastnosti přepíší omezení DEFAULT nastavené v datovém skladu a sloupec identity nemůže mít výchozí hodnotu. | < výchozí hodnoty > | No | defaultValues: -Columnname -Defaultvalue |
| Další možnosti | Další možnosti, které se předají do příkazu COPY služby Azure Synapse Analytics přímo v klauzuli With v příkazu COPY. Podle potřeby uvozujte hodnotu tak, aby odpovídala požadavkům příkazu COPY. | < další možnosti > | No | additionalOptions: - <název> vlastnosti: <hodnota> |
| Při výběru PolyBase | PolyBase je mechanismus vysoké propustnosti. Můžete ho použít k načtení velkých objemů dat do Azure Synapse Analytics nebo fondu SQL. | / | Ne. Použít při použití PolyBase. |
allowPolyBase: true polyBase Nastavení |
| Odmítnout typ | Typ hodnoty zamítnutí. | •Hodnotu •Procento |
No | rejectType: -Hodnotu -Procento |
| Odmítnout hodnotu | Početneboch | 0 (výchozí), 1, 2 atd. | No | rejectValue |
| Odmítnout ukázkovou hodnotu | Určuje počet řádků, které se mají načíst, než PolyBase přepočítá procento odmítnutých řádků. | 1, 2 atd. | Ano, pokud jako typ zamítnutí zadáte procento . | rejectSampleValue |
| Použít výchozí typ | Určete, jak zpracovat chybějící hodnoty v textových souborech s oddělovači, když PolyBase načte data z textového souboru. Další informace o této vlastnosti najdete v části Argumenty ve formátu CREATE EXTERNAL FILE FORMAT (Transact-SQL). | vybraná (výchozí) nebo nevybraná. | No | useTypeDefault: true (výchozí) nebo false |
| Při výběru hromadného vložení | Vložte data do cíle hromadně. | / | No | writeBehavior: Vložení |
| Zámek hromadného vložení tabulky | Tento postup slouží ke zlepšení výkonu kopírování během hromadné operace vkládání v tabulce bez indexu z více klientů. Další informace najdete v příkazu BULK INSERT (Transact-SQL). | vybraná nebo nevybraná (výchozí) | No | sqlWriterUseTableLock: true nebo false (výchozí) |
| Při výběru možnosti Upsert | Určete skupinu nastavení pro chování zápisu, pokud chcete přenést data do cíle. | / | No | writeBehavior: Upsert |
| Klíčové sloupce | Určuje, který sloupec se používá k určení, jestli řádek ze zdroje odpovídá řádku z cíle. | < název sloupce> | No | upsert Nastavení: - klíče: < název sloupce > - interimSchemaName |
| Zámek hromadného vložení tabulky | Tento postup slouží ke zlepšení výkonu kopírování během hromadné operace vkládání v tabulce bez indexu z více klientů. Další informace najdete v příkazu BULK INSERT (Transact-SQL). | vybraná nebo nevybraná (výchozí) | No | sqlWriterUseTableLock: true nebo false (výchozí) |
| Skript předběžného kopírování | Skript pro aktivitu kopírování, který se má spustit před zápisem dat do cílové tabulky v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat. | < skript předběžného kopírování > (řetězec) |
No | preCopyScript |
| Časový limit zápisu dávky | Doba čekání, než se operace dávkového vložení dokončí, než vyprší časový limit. Povolená hodnota je časový rozsah. Výchozí hodnota je 00:30:00 (30 minut). | timespan | No | writeBatchTimeout |
| Velikost dávky zápisu | Počet řádků, které se mají vložit do tabulky SQL na dávku Ve výchozím nastavení služba dynamicky určuje odpovídající velikost dávky na základě velikosti řádku. | < počet řádků > (celé číslo) |
No | writeBatchSize |
| Maximální počet souběžných připojení | Horní limit souběžných připojení vytvořených k úložišti dat během spuštění aktivity. Zadejte hodnotu pouze v případech, kdy chcete omezit souběžná připojení. | < horní limit souběžných připojení > (celé číslo) |
No | maxConcurrent Připojení ions |
| Zakázání analýz metrik výkonu | Toto nastavení slouží ke shromažďování metrik, jako jsou DTU, DWU, RU atd., pro optimalizaci výkonu kopírování a doporučení. Pokud máte obavy o toto chování, zaškrtněte toto políčko. | výběr nebo zrušení výběru (výchozí) | No | disableMetricsCollection: true nebo false (výchozí) |