Konfigurace služby Azure Database for PostgreSQL v aktivitě kopírování
Tento článek popisuje, jak pomocí aktivity kopírování v datovém kanálu kopírovat data z a do služby Azure Database for PostgreSQL.
Podporovaná konfigurace
Pro konfiguraci každé karty v aktivitě kopírování přejděte na následující oddíly.
Obecné
Informace o konfiguraci karty nastavení
Zdroj
Přejděte na kartu Zdroj a nakonfigurujte zdroj aktivity kopírování. Podrobnou konfiguraci najdete v následujícím obsahu.
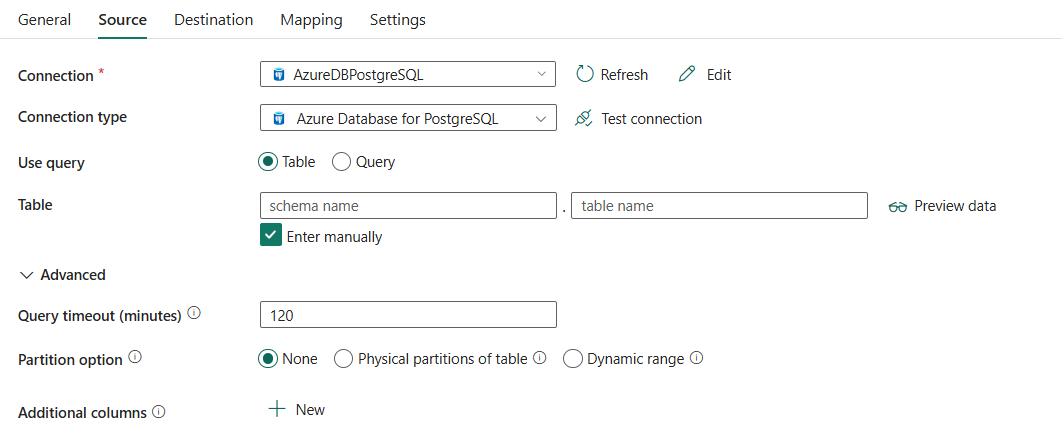
Následující tři vlastnosti jsou povinné:
- Připojení: Ze seznamu připojení vyberte připojení k databázi Azure pro PostgreSQL. Pokud neexistuje žádné připojení, vytvořte nové připojení Azure Database for PostgreSQL.
- Typ připojení: Vyberte Azure Database for PostgreSQL .
-
Použítdotazu: Vyberte tabulku ke čtení dat ze zadané tabulky nebo vyberte dotaz ke čtení dat pomocí dotazů.
Pokud vyberete tabulku:
tabulka: Vyberte tabulku z rozevíracího seznamu nebo vyberte Zadejte ručně a zadejte ji ručně pro čtení dat.

Pokud vyberete dotazu:
dotaz: Zadejte vlastní dotaz SQL pro čtení dat. Například:
SELECT * FROM mytableneboSELECT * FROM "MyTable".Poznámka
V PostgreSQL se název entity považuje za nerozeznávající velká a malá písmena, pokud není uzavřen v uvozovkách.

V části Pokročilémůžete zadat následující pole:
vypršení časového limitu dotazu (minuty): Zadejte dobu čekání před ukončením pokusu o spuštění příkazu a vygenerováním chyby, výchozí hodnota je 120 minut. Pokud je pro tuto vlastnost nastaven parametr, jsou povolené hodnoty časový rozsah, například 02:00:00 (120 minut). Další informace naleznete v tématu CommandTimeout.
možnost oddílu: Určuje možnosti dělení dat používané k načtení dat ze služby Azure Database for PostgreSQL. Pokud je povolena možnost dělení (tj. není None), nastavení stupně paralelismu pro souběžné načítání dat ze služby Azure Database for PostgreSQL je řízeno nastavením Stupeň paralelismu kopírování na kartě Nastavení aktivity kopírování.
Pokud vyberete Žádné, rozhodnete se oddíl nepoužívat.
Pokud vyberete Fyzické oddíly tabulky:
Názvy oddílů: Zadejte seznam fyzických oddílů, které je nutné zkopírovat.
Pokud k načtení zdrojových dat použijete dotaz, připojte
?AdfTabularPartitionNamev klauzuli WHERE. Příklad najdete v části Paralelní kopírování v části Azure Database for PostgreSQL.
Pokud vyberete Dynamický rozsah:
Název sloupce oddílu: Zadejte název zdrojového sloupce v celočíselném nebo datovém/datumovém typu (
int,smallint,bigint,date,timestamp without time zone,timestamp with time zonenebotime without time zone), který bude použit pro rozsahové dělení při paralelním kopírování. Pokud není zadáno, primární klíč tabulky se automaticky rozpozná a použije jako partition sloupec.Pokud k načtení zdrojových dat použijete dotaz, přidejte
?AdfRangePartitionColumnNamev klauzuli WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL.horní mez oddílu: Zadejte maximální hodnotu sloupce oddílu, aby bylo možné data zkopírovat ven.
Pokud chcete k načtení zdrojových dat použít dotaz, připojte
?AdfRangePartitionUpbounddo klauzule WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL. .Dolní mez oddílu: Zadejte minimální hodnotu sloupce oddílu pro kopírování dat ven.
Pokud k načtení zdrojových dat použijete dotaz, zapojte
?AdfRangePartitionLowboundv klauzuli WHERE. Příklad najdete v části Paralelní kopírování ze služby Azure Database for PostgreSQL.
Další sloupce: Přidejte další datové sloupce pro ukládání relativní cesty nebo statické hodnoty zdrojových souborů. Výraz je podporován pro to druhé.
Cíl
Přejděte na kartu Cíl a nakonfigurujte cíl aktivity kopírování. Podrobnou konfiguraci najdete v následujícím obsahu.
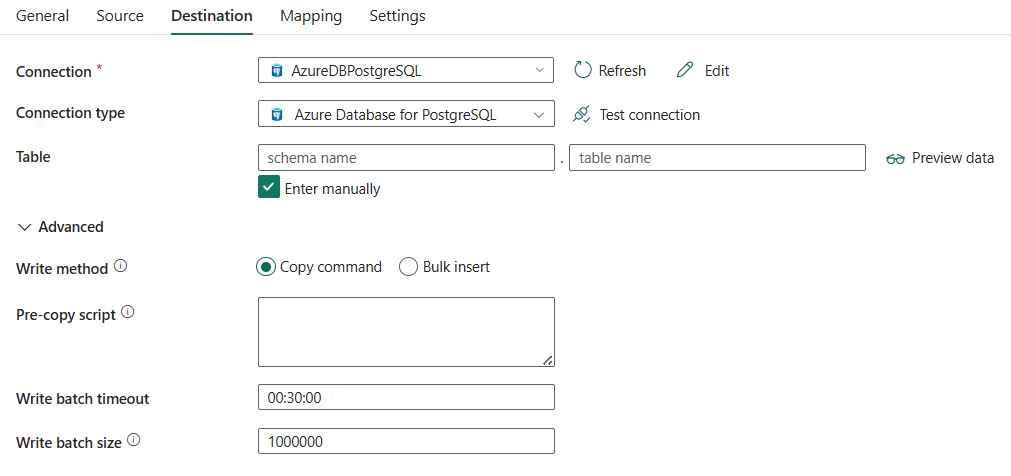
Následující tři vlastnosti jsou požadované:
- Připojení: Ze seznamu připojení vyberte připojení Azure Database for PostgreSQL. Pokud neexistuje žádné připojení, vytvořte nové připojení Azure Database for PostgreSQL.
- Typ připojení: Vyberte Azure Database for PostgreSQL .
- tabulka: Vyberte tabulku z rozevíracího seznamu nebo vyberte Zadejte ručně a zadejte ji pro zápis dat.
V části Pokročilémůžete zadat následující pole:
metoda zápisu: Vyberte metodu použitou k zápisu dat do služby Azure Database for PostgreSQL. Vyberte příkaz Kopírovat (výchozí, protože je výkonnější) a Hromadné vložení.
skript předběžného kopírování: Zadejte dotaz SQL pro aktivitu kopírování, který se má provést před zápisem dat do služby Azure Database for PostgreSQL v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat.
Časový limit dávkového zápisu: Zadejte dobu čekání na dokončení operace dávkového vložení, než vyprší časový limit. Povolená hodnota je časový úsek. Výchozí hodnota je 00:30:00 (30 minut).
Velikost dávky zápisu: Zadejte počet řádků načtených do databáze Azure pro PostgreSQL pro každou dávku. Povolená hodnota je celé číslo, které představuje počet řádků. Výchozí hodnota je 1 000 000.
Mapování
Informace o konfiguraci mapování karty naleznete v tématu Konfigurace mapování na kartě mapování.
Nastavení
Pokud chcete konfiguraci karty v záložce Nastavení, přejděte na Konfigurace dalších nastavení na záložceNastavení.
Paralelní kopírování ze služby Azure Database for PostgreSQL
Konektor Azure Database for PostgreSQL v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj kopírovací aktivity.
Když povolíte dělené kopírování, aktivita kopírování spustí paralelní dotazy na zdroj Azure Database for PostgreSQL, aby načetla data podle oddílů. Paralelní stupeň je řízen Stupněm paralelismu kopírování na kartě nastavení aktivity kopírování. Pokud například nastavíte Stupeň paralelismu kopírování na čtyři, služba paralelně generuje a spouští čtyři dotazy na základě zadané možnosti oddílení a nastavení, a každý dotaz načte část dat z vaší služby Azure Database for PostgreSQL.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat ze služby Azure Database for PostgreSQL. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly |
Možnost rozdělení: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. |
| Úplné načtení z velké tabulky bez fyzických oddílů, ale s celočíselným sloupcem pro dělení dat. |
možnosti rozdělení: Dynamický rozsah. Sloupec rozdělení: Zadejte sloupec použitý pro rozdělení dat. Pokud není zadaný žádný jiný, použije se sloupec primárního klíče. |
| Načtěte velké množství dat pomocí vlastního dotazu s fyzickými oddíly. |
možnost oddílu: Fyzické oddíly tabulky. dotazu Název(e)/názvy oddílu(ů): Zadejte název(e) nebo názvy oddílů, ze kterých chcete kopírovat data. Pokud není zadaný, služba automaticky rozpozná fyzické oddíly v tabulce, kterou jste zadali v datové sadě PostgreSQL. Během provádění služba nahradí ?AdfTabularPartitionName skutečným názvem oddílu a odešle ji do služby Azure Database for PostgreSQL. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických partitionů, s použitím celočíselného sloupce pro dělení dat. |
možnosti oddílu: Dynamický rozsah. dotazu: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Sloupec pro oddílení: Zadejte sloupec použitý k členění dat. Sloupec můžete rozdělit na celé číslo nebo datový typ date/datetime. Horní hranice oddílu a dolní hranice: Zda chcete filtrovat podle sloupce oddílu a načíst data pouze z rozmezí dolní a horní hranice. Během provádění služba nahrazuje ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbounda ?AdfRangePartitionLowbound skutečným názvem sloupce a rozsahy hodnot pro každý oddíl a odesílá je do Služby Azure Database for PostgreSQL. Pokud je například partitionní sloupec "ID" nastavený s dolní mezí jako 1 a horní mez jako 80, s paralelním kopírováním nastaveným na 4, služba načte data ve 4 oddílech. Jejich ID jsou mezi [1,20], [21, 40], [41, 60] a [61, 80], v uvedeném pořadí. |
Osvědčené postupy pro načtení dat s možností rozdělení:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje vestavěný oddíl, použijte možnost „Fyzické oddíly tabulky“ pro dosažení lepšího výkonu.
Souhrn tabulky
Následující tabulka obsahuje další informace o aktivitě kopírování ve službě Azure Database for PostgreSQL.
Informace o zdroji
| Jméno | Popis | Hodnota | Povinný | Vlastnost skriptu JSON |
|---|---|---|---|---|
| připojení | Vaše připojení ke zdrojovému úložišti dat. | < vaše připojení k Azure Database for PostgreSQL > | Ano | připojení |
| Typ připojení | Typ zdrojového připojení. | Azure databáze pro PostgreSQL | Ano | / |
| Použít dotaz | Způsob čtení dat. Použití |
• Tabulka • dotaz |
Ano | • vlastnosti_typu (pod typeProperties ->source)- schéma - stůl • dotaz |
| vypršení časového limitu dotazu (minuty) | Doba čekání před ukončením pokusu o spuštění příkazu a vygenerováním chyby je výchozí 120 minut. Pokud je pro tuto vlastnost nastaven parametr, jsou povolené hodnoty časový rozsah, například 02:00:00 (120 minut). Další informace naleznete v dokumentaci CommandTimeout. | časový rozsah | Ne | časový limit dotazu |
| názvy oddílů | Seznam fyzických oddílů, které je potřeba zkopírovat. Pokud použijete dotaz k načtení zdrojových dat, připojte ?AdfTabularPartitionName v klauzuli WHERE. |
< vaše názvy oddílů > | Ne | partitionNames |
| název sloupce oddílu | Název zdrojového sloupce v celočíselném nebo datum/časovém typu (int, smallint, bigint, date, timestamp without time zone, timestamp with time zone nebo time without time zone), který bude použit pro rozsahové dělení při paralelním kopírování. Pokud není specifikováno, primární klíč tabulky se automaticky rozpozná a použije jako sloupec pro rozdělení. |
< vaše názvy sloupců oddílů > | Ne | názevSloupceOddílu |
| horní mez oddílu | Maximální hodnota oddílového sloupce pro zkopírování dat ven. Pokud používáte dotaz pro načtení zdrojových dat, připojte ?AdfRangePartitionUpbound do klauzule WHERE. |
< horní mez oddílu > | Ne | partitionUpperBound |
| dolní mez oddílu | Minimální hodnota sloupce oddílu pro zkopírování dat. Pokud k načtení zdrojových dat použijete dotaz, zahodíte ?AdfRangePartitionLowbound v klauzuli WHERE. |
< vaše dolní mez oddílu > | Ne | partitionLowerBound |
| Další sloupce | Přidejte další datové sloupce pro ukládání relativní cesty ke zdrojovým souborům nebo statické hodnotě. U druhého výrazu se podporuje. | •Jméno •Hodnota |
Ne | dalšíSloupce •Jméno •hodnota |
Informace o cíli
| Jméno | Popis | Hodnota | Požadovaný | Vlastnost skriptu JSON |
|---|---|---|---|---|
| připojení | Vaše připojení k cílovému úložišti dat. | < připojení ke službě Azure Database for PostgreSQL > | Ano | připojení |
| Typ připojení | Typ cílového připojení. | Azure Database for PostgreSQL | Ano | / |
| Tabulka | Tabulka dat cílového umístění pro zápis dat. | < název cílové tabulky > | Ano | vlastnostiTypu (pod typeProperties ->sink):- schéma - stůl |
| metoda Write | Metoda použitá k zápisu dat do služby Azure Database for PostgreSQL. | • příkaz kopírování (výchozí) • hromadné vkládání |
Ne | metoda zápisu: • CopyCommand • Hromadné vložení |
| skript předběžného kopírování | Dotaz SQL na aktivitu kopírování, který se má provést před zápisem dat do služby Azure Database for PostgreSQL v každém spuštění. Tuto vlastnost můžete použít k vyčištění předem načtených dat. | < předkopírovaný skript > | Ne | preCopyScript |
| Časový limit dávkového zápisu | Čekací doba pro dokončení operace dávkového vložení před vypršením časového limitu. | časový rozsah (Výchozí hodnota je 00:30:00 - 30 minut) |
Ne | writeBatchTimeout |
| velikost dávky zápisu | Počet řádků načtených do služby Azure Database for PostgreSQL na dávku | celé číslo (výchozí hodnota je 1 000 000) |
Ne | writeBatchSize |
Související obsah
- přehled konektoru Azure Database for PostgreSQL