Konfigurace Amazon RDS pro SQL Server v aktivitě kopírování
Tento článek popisuje, jak pomocí aktivity kopírování v datovém kanálu kopírovat data z Amazon RDS pro SQL Server.
Podporovaná konfigurace
Konfigurace každé karty v aktivitě kopírování najdete v následujících částech.
OBECNÉ
Informace o konfiguraci karty Obecné nastavení najdete v doprovodných materiálech k obecným nastavením.
Zdroj
Následující vlastnosti jsou podporovány pro Amazon RDS pro SQL Server na kartě Zdroj aktivity kopírování.
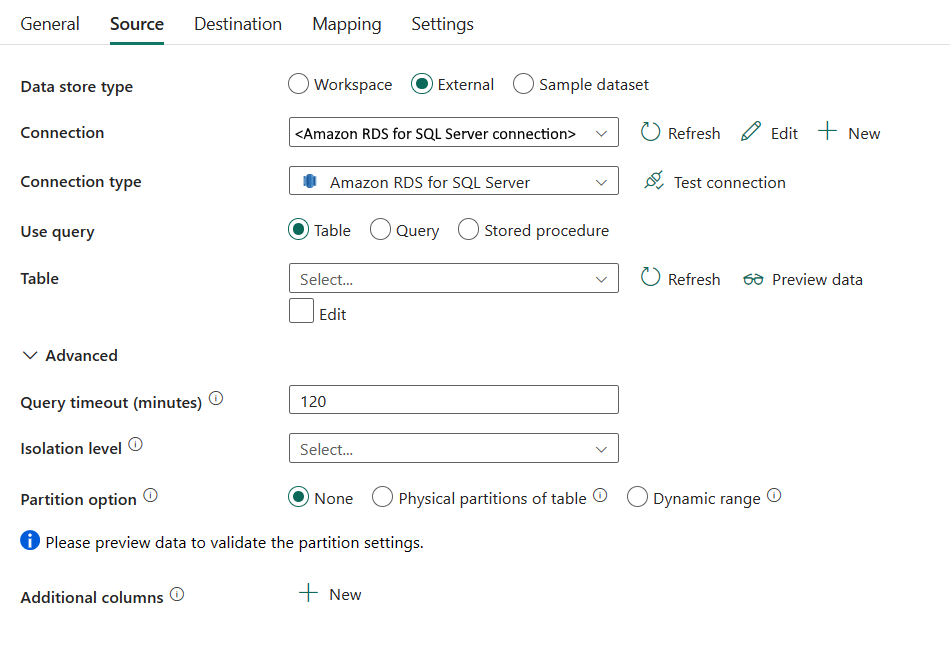
Jsou vyžadovány následující vlastnosti:
Typ úložiště dat: Vyberte externí.
Připojení: Ze seznamu připojení vyberte Amazon RDS pro připojení k SQL Serveru. Pokud připojení neexistuje, vytvořte novou Amazon RDS pro připojení k SQL Serveru výběrem možnosti Nový.
Typ připojení: Vyberte Amazon RDS pro SQL Server.
Použití dotazu: Zadejte způsob čtení dat. Můžete zvolit tabulku, dotaz nebo uloženou proceduru. Následující seznam popisuje konfiguraci jednotlivých nastavení:
Tabulka: Čtení dat ze zadané tabulky Vyberte zdrojovou tabulku z rozevíracího seznamu nebo ji vyberte Upravit a zadejte ji ručně.
Dotaz: Zadejte vlastní dotaz SQL pro čtení dat. Příklad:
select * from MyTable. Nebo vyberte ikonu tužky, která se má upravit v editoru kódu.
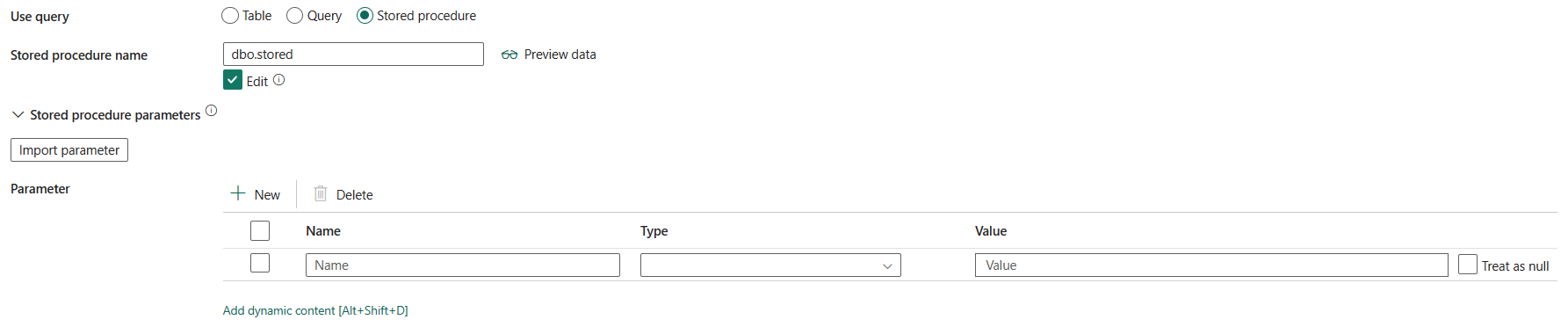
Uložená procedura: Použijte uloženou proceduru, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře.
Název uložené procedury: Vyberte uloženou proceduru nebo zadejte název uložené procedury ručně při výběru možnosti Upravit pro čtení dat ze zdrojové tabulky.
Parametry uložené procedury: Zadejte hodnoty pro parametry uložené procedury. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury. Pokud chcete získat parametry uložené procedury, můžete vybrat Parametry importu.
V části Upřesnit můžete zadat následující pole:
Časový limit dotazu (minuty):Zadejte časový limit pro spuštění příkazu dotazu, výchozí hodnota je 120 minut. Pokud je pro tuto vlastnost nastaven parametr, jsou povolené hodnoty časový rozsah, například 02:00:00 (120 minut).
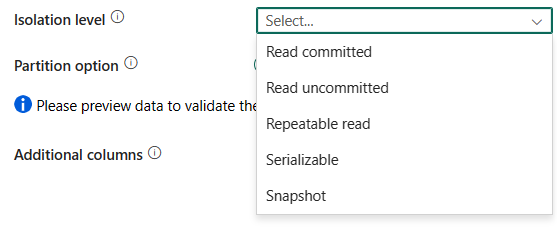
Úroveň izolace: Určuje chování zamykání transakce pro zdroj SQL. Povolené hodnoty jsou: Číst potvrzeno, Číst nepotvrzené, Opakovatelné čtení, Serializovatelné, Snímek. Pokud není zadáno, použije se výchozí úroveň izolace databáze. Další podrobnosti najdete v výčtu IsolationLevel.
Možnost oddílu: Zadejte možnosti dělení dat používané k načtení dat z Amazon RDS pro SQL Server. Povolené hodnoty jsou: Žádné (výchozí), fyzické oddíly tabulky a dynamický rozsah. Pokud je povolená možnost oddílu (tj. žádná), stupeň paralelismu souběžného načítání dat z Amazon RDS pro SQL Server je řízen stupněm paralelismu kopírování na kartě nastavení aktivity kopírování.
Žádné: Toto nastavení zvolte, pokud nechcete oddíl používat.
Fyzické oddíly tabulky: Při použití fyzického oddílu se sloupec a mechanismus oddílu automaticky určují na základě definice fyzické tabulky.
Dynamický rozsah: Při použití dotazu s povoleným paralelním povolením je potřeba parametr oddílu rozsahu(
?DfDynamicRangePartitionCondition). Ukázkový dotaz:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.Název sloupce oddílu: Zadejte název zdrojového sloupce v celočíselném nebo typu date/datetime (
int,smallint,bigint,date,smalldatetime,datetime,datetime2, nebodatetimeoffset), který se používá při dělení rozsahu pro paralelní kopírování. Pokud není zadaný, index nebo primární klíč tabulky se automaticky rozpozná a použije jako sloupec oddílu.Pokud k načtení zdrojových dat použijete dotaz, připojte se
?DfDynamicRangePartitionConditiondo klauzule WHERE. Příklad najdete v části Paralelní kopírování z databáze SQL.Horní mez oddílu: Zadejte maximální hodnotu sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Příklad najdete v části Paralelní kopírování z databáze SQL.
Dolní mez oddílu: Zadejte minimální hodnotu sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Příklad najdete v části Paralelní kopírování z databáze SQL.
Další sloupce: Přidejte další datové sloupce pro ukládání relativní cesty nebo statické hodnoty zdrojových souborů. U druhého výrazu se podporuje.
Mějte na paměti následující body:
- Pokud je pro zdroj zadán dotaz , aktivita kopírování spustí tento dotaz na Amazon RDS pro zdroj SQL Serveru, aby získala data. Uloženou proceduru můžete zadat také zadáním parametrů Uložené procedury a Uložené procedury, pokud uložená procedura přebírá parametry.
- Při použití uložené procedury ve zdroji k načtení dat si všimněte, že uložená procedura je navržena jako vrácení jiného schématu, pokud je předána jiná hodnota parametru, může dojít k selhání nebo může dojít k neočekávanému výsledku při importu schématu z uživatelského rozhraní nebo při kopírování dat do databáze SQL s automatickým vytvořením tabulky.
mapování.
V části Konfigurace karty Mapování přejděte na Konfigurace mapování na kartě Mapování.
Nastavení
V části Konfigurace karty Nastavení přejděte na Konfigurovat další nastavení na kartě Nastavení.
Paralelní kopírování z databáze SQL
Konektor Amazon RDS pro SQL Server v aktivitě kopírování poskytuje integrované dělení dat pro paralelní kopírování dat. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.
Když povolíte dělené kopírování, aktivita kopírování spouští paralelní dotazy na zdroj Amazon RDS pro zdroj SQL Serveru pro načtení dat podle oddílů. Paralelní stupeň je řízen stupněm paralelismu kopírování na kartě nastavení aktivity kopírování. Pokud například nastavíte stupeň paralelismu kopírování na čtyři, služba souběžně vygeneruje a spouští čtyři dotazy na základě zadané možnosti a nastavení oddílu a každý dotaz načte část dat z vaší Amazon RDS pro SQL Server.
Doporučujeme povolit paralelní kopírování s dělením dat, zejména pokud načítáte velké množství dat z Amazon RDS pro SQL Server. Následující konfigurace jsou navržené pro různé scénáře. Při kopírování dat do souborového úložiště dat se doporučuje zapisovat do složky jako více souborů (zadat pouze název složky), v takovém případě je výkon lepší než zápis do jednoho souboru.
| Scénář | Navrhovaná nastavení |
|---|---|
| Úplné načtení z velké tabulky s fyzickými oddíly | Možnost oddílu: Fyzické oddíly tabulky. Během provádění služba automaticky rozpozná fyzické oddíly a kopíruje data podle oddílů. Pokud chcete zkontrolovat, jestli tabulka obsahuje fyzický oddíl nebo ne, můžete odkazovat na tento dotaz. |
| Úplné načtení z velké tabulky bez fyzických oddílů, zatímco s celočíselnou nebo datetime sloupcem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Sloupec oddílu (volitelné): Zadejte sloupec použitý k dělení dat. Pokud není zadaný, použije se sloupec primárního klíče. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky v tabulce budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky zjistí hodnoty a může trvat dlouhou dobu v závislosti na hodnotách MIN a MAX. Doporučuje se zadat horní mez a dolní mez. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez jako 80, přičemž paralelní kopírování je 4, služba načte data o 4 oddílech – ID v rozsahu <=20, [21, 50], [51, 80] a >=81. |
| Načtěte velké množství dat pomocí vlastního dotazu bez fyzických oddílů, zatímco s celočíselnou nebo datem a datem a časem pro dělení dat. | Možnosti oddílu: Oddíl dynamického rozsahu Dotaz: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Sloupec oddílu: Zadejte sloupec použitý k rozdělení dat. Horní mez oddílu a dolní mez oddílu (volitelné): Určete, jestli chcete určit krok oddílu. To není pro filtrování řádků v tabulce, všechny řádky ve výsledku dotazu budou rozděleny a zkopírovány. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. Pokud má například sloupec oddílu ID hodnoty od 1 do 100 a dolní mez nastavíte jako 20 a horní mez 80, přičemž paralelní kopírování je 4, služba načte data podle 4 oddílů v rozsahu <=20, [21, 50], [51, 80] a >=81. Tady jsou další ukázkové dotazy pro různé scénáře: • Zadejte dotaz na celou tabulku: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Dotaz z tabulky s výběrem sloupce a dalšími filtry klauzule where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s poddotazy: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Dotaz s oddílem v poddotazu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Osvědčené postupy pro načtení dat s možností oddílu:
- Zvolte výrazný sloupec jako sloupec oddílu (například primární klíč nebo jedinečný klíč), abyste se vyhnuli nerovnoměrné distribuci dat.
- Pokud tabulka obsahuje předdefinovaný oddíl, pomocí možnosti oddílu Fyzické oddíly tabulky získáte lepší výkon.
Ukázkový dotaz pro kontrolu fyzického oddílu
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Pokud tabulka obsahuje fyzický oddíl, zobrazí se "HasPartition" jako "ano", například následující.

Souhrn tabulky
V následující tabulce najdete souhrn a další informace o aktivitě kopírování Amazon RDS pro SQL Server.
Informace o zdroji
| Název | Popis | Hodnota | Požaduje se | Vlastnost skriptu JSON |
|---|---|---|---|---|
| Typ úložiště dat | Váš typ úložiště dat. | Externí | Ano | / |
| Připojení | Vaše připojení ke zdrojovému úložišti dat. | < vaše připojení > | Ano | připojení |
| Typ připojení: | Typ připojení. Vyberte Amazon RDS pro SQL Server. | Amazon RDS pro SQL Server | Ano | / |
| Použití dotazu | Vlastní dotaz SQL pro čtení dat. | •Stůl •Dotaz • Uložená procedura |
Ano | / |
| Tabulka | Zdrojová tabulka dat | < název cílové tabulky> | No | schéma table |
| Dotaz | Vlastní dotaz SQL pro čtení dat. | < dotaz > | No | sqlReaderQuery |
| Název uložené procedury | Tato vlastnost je název uložené procedury, která čte data ze zdrojové tabulky. Poslední příkaz SQL musí být příkaz SELECT v uložené proceduře. | < název uložené procedury > | No | sqlReaderStoredProcedureName |
| Parametr uložené procedury | Tyto parametry jsou určené pro uloženou proceduru. Povolené hodnoty jsou dvojice názvů nebo hodnot. Názvy a velikost písmen parametrů musí odpovídat názvům a velikostem písmen parametrů uložené procedury. | < dvojice název nebo hodnota > | No | storedProcedureParameters |
| Časový limit dotazu | Časový limit spuštění příkazu dotazu. | timespan (výchozí hodnota je 120 minut) |
No | queryTimeout |
| Úroveň izolace | Určuje chování uzamčení transakce pro zdroj SQL. | • Čtení potvrzeno • Nepotvrzené čtení • Opakovatelné čtení •Serializovatelný •Snímek |
No | isolationLevel: • ReadCommitted • ReadUncomcommitted • Opakovatelnýread •Serializovatelný •Snímek |
| Možnost oddílu | Možnosti dělení dat používané k načtení dat z Amazon RDS pro SQL Server. | • Žádné (výchozí) • Fyzické oddíly tabulky • Dynamický rozsah |
No | partitionOption: • Žádné (výchozí) • PhysicalPartitionsOfTable • DynamicRange |
| Název sloupce oddílu | Název zdrojového sloupce v celočíselném čísle nebo typu date/datetime (int, smallint, bigint, smalldatetimedate, , datetime, datetime2nebo datetimeoffset), který se používá při dělení rozsahu pro paralelní kopírování. Pokud není zadaný, index nebo primární klíč tabulky se automaticky rozpozná a použije jako sloupec oddílu. Pokud k načtení zdrojových dat použijete dotaz, připojte se ?DfDynamicRangePartitionCondition do klauzule WHERE. |
< názvy sloupců oddílů > | No | partitionColumnName |
| Horní mez oddílu | Maximální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. | < horní mez oddílu > | No | partitionUpperBound |
| Dolní mez oddílu | Minimální hodnota sloupce oddílu pro rozdělení rozsahu oddílů. Tato hodnota se používá k rozhodování o kroku oddílu, nikoli k filtrování řádků v tabulce. Všechny řádky v tabulce nebo výsledku dotazu se rozdělí a zkopírují. Pokud není zadáno, aktivita kopírování automaticky rozpozná hodnotu. | < dolní mez oddílu > | No | partitionLowerBound |
| Další sloupce | Přidejte další datové sloupce pro ukládání relativní cesty ke zdrojovým souborům nebo statické hodnotě. U druhého výrazu se podporuje. | • Jméno •Hodnota |
No | additionalColumns: •Jméno •hodnota |