Vizualizace poznámkového bloku v Microsoft Fabric
Microsoft Fabric je integrovaná analytická služba, která zrychluje čas pro přehledy napříč datovými sklady a systémy pro analýzu velkých objemů dat. Vizualizace dat v poznámkových blocích je klíčovou komponentou, která umožňuje získat přehled o datech. Pomáhá lidem usnadnit pochopení velkých a malých dat. Usnadňuje také zjišťování vzorů, trendů a odlehlých hodnot ve skupinách dat.
Pokud používáte Apache Spark v prostředcích infrastruktury, existují různé integrované možnosti, které vám pomůžou vizualizovat data, včetně možností grafu poznámkového bloku Fabric, a přístup k oblíbeným opensourcovým knihovnám.
Při použití poznámkového bloku Fabric můžete zobrazení tabulkových výsledků převést na přizpůsobený graf pomocí možností grafu. Tady můžete vizualizovat data, aniž byste museli psát jakýkoli kód.
Integrovaný příkaz vizualizace – funkce display()
Vestavěná funkce vizualizace Fabric vám umožňuje převést datové rámce Apache Spark, datové rámce Pandas a výsledky dotazů SQL na bohaté vizualizace dat.
Pomocí funkce zobrazení na datových rámcích vytvořených v PySpark a Scala ve funkcích Spark DataFrames nebo Odolných distribuovaných datových sad (RDD) můžete vytvořit bohaté zobrazení tabulky datového rámce a zobrazení grafu.
Můžete zadat počet řádků vykreslovaného datového rámce. Výchozí hodnota je 1000. Widget zobrazení výstupu poznámkového bloku podporuje zobrazení a profilování maximálně 1 0000 řádků datového rámce.

Pomocí funkce filtru na globálním panelu nástrojů můžete efektivně filtrovat data, která mapujete pomocí vlastního pravidla, podmínka se použije na zadaný sloupec a výsledek filtru se odráží v zobrazení tabulky i v zobrazení grafu.

Výstup příkazu SQL přijímá ve výchozím nastavení stejný widget výstupu s display().
Zobrazení tabulky s bohatým datovým rámcem
Podpora bezplatného výběru v zobrazení tabulky
Zobrazení tabulky se ve výchozím nastavení vykreslí při použití příkazu display(). Bohatý náhled datového rámce v poznámkovém bloku nabízí funkci bezplatného výběru navrženou tak, aby vylepšila možnosti analýzy dat prostřednictvím flexibilních a intuitivních možností výběru. Tato funkce umožňuje uživatelům pracovat s datovými rámci efektivněji a snadno získat podrobnější přehledy.
Výběr sloupce
- Jeden sloupec: Kliknutím na záhlaví sloupce vyberte celý sloupec.
- více sloupců: Po výběru jednoho sloupce stiskněte a podržte klávesu Shift a potom kliknutím na jiné záhlaví sloupce vyberte více sloupců.
výběr řádku
- jeden řádek: Kliknutím na záhlaví řádku vyberte celý řádek.
- více řádků: Po výběru jednoho řádku stiskněte a podržte klávesu Shift a potom kliknutím na další záhlaví řádku vyberte více řádků.
náhled obsahu buňky: Zobrazte si náhled obsahu jednotlivých buněk, abyste získali rychlý a podrobný pohled na data, aniž byste museli psát další kód.
souhrn sloupce: Získejte souhrn jednotlivých sloupců, včetně rozdělení dat a klíčových statistik, abyste rychle porozuměli charakteristikám dat.
výběr volné oblasti: Výběrem libovolného souvislého segmentu tabulky získáte přehled o celkových vybraných buňkách a číselných hodnotách ve vybrané oblasti.
Kopírování vybraného obsahu: Ve všech případech výběru můžete vybraný obsah rychle zkopírovat pomocí klávesové zkratky Ctrl + C. Vybraná data se zkopírují ve formátu CSV, což usnadňuje zpracování v jiných aplikacích.
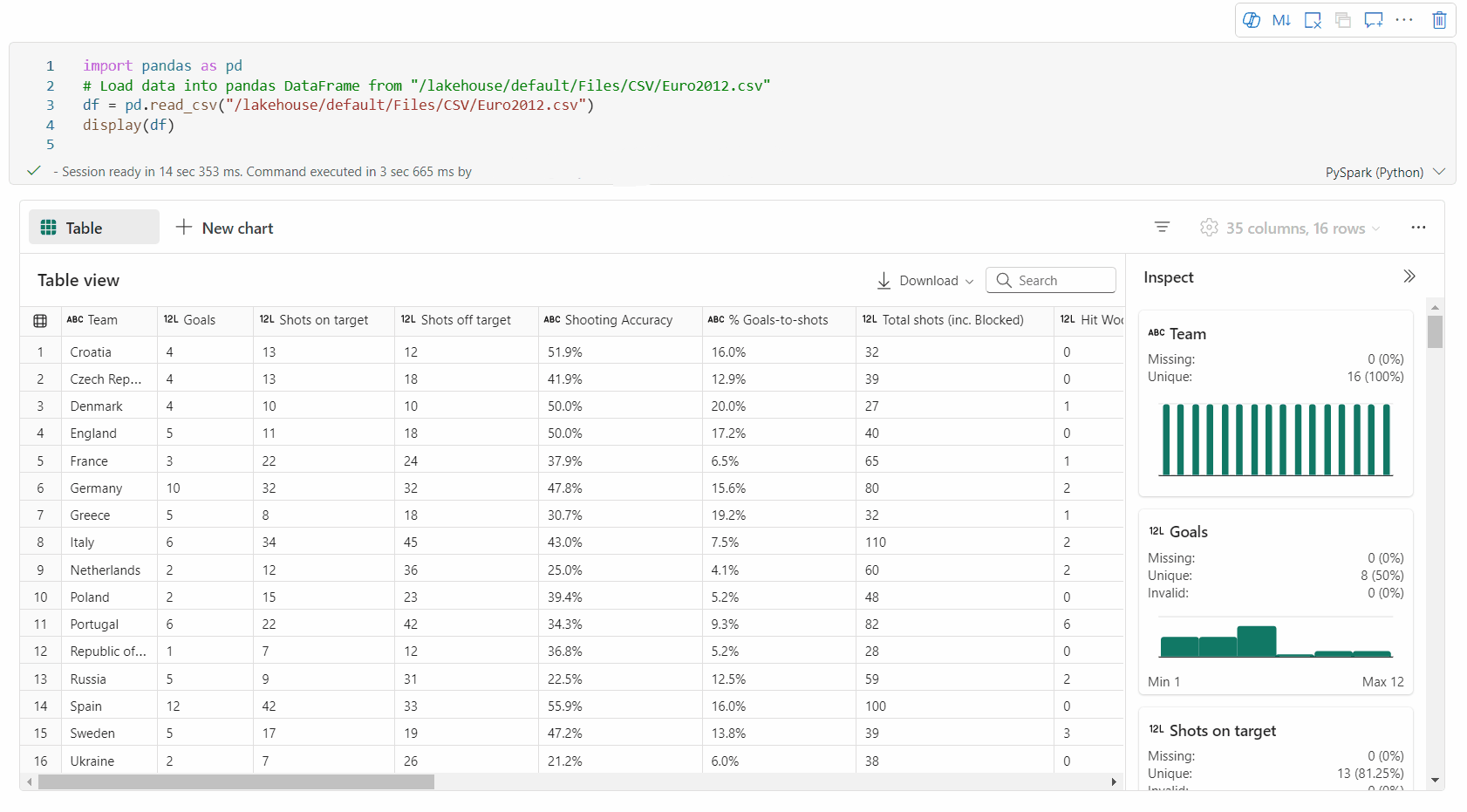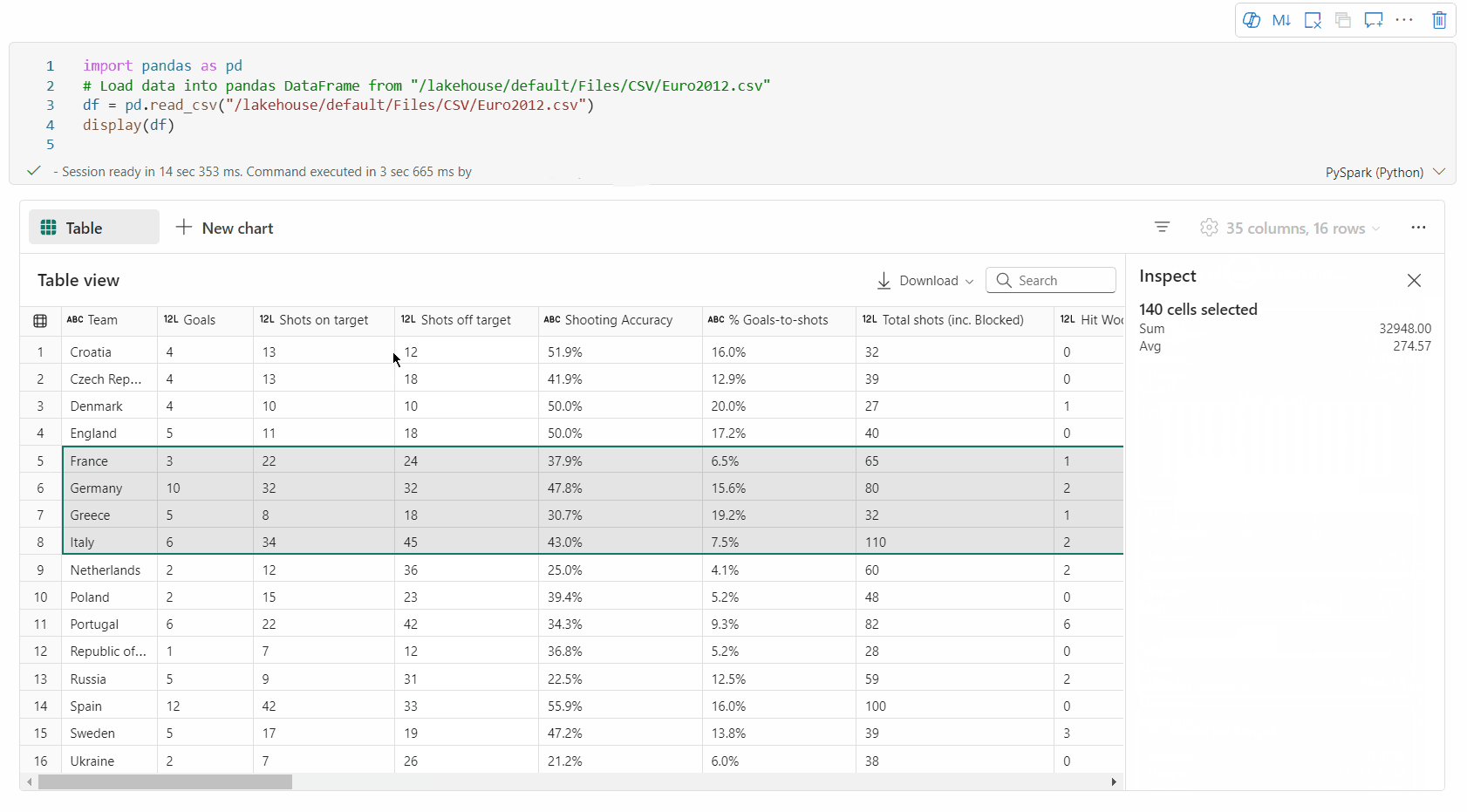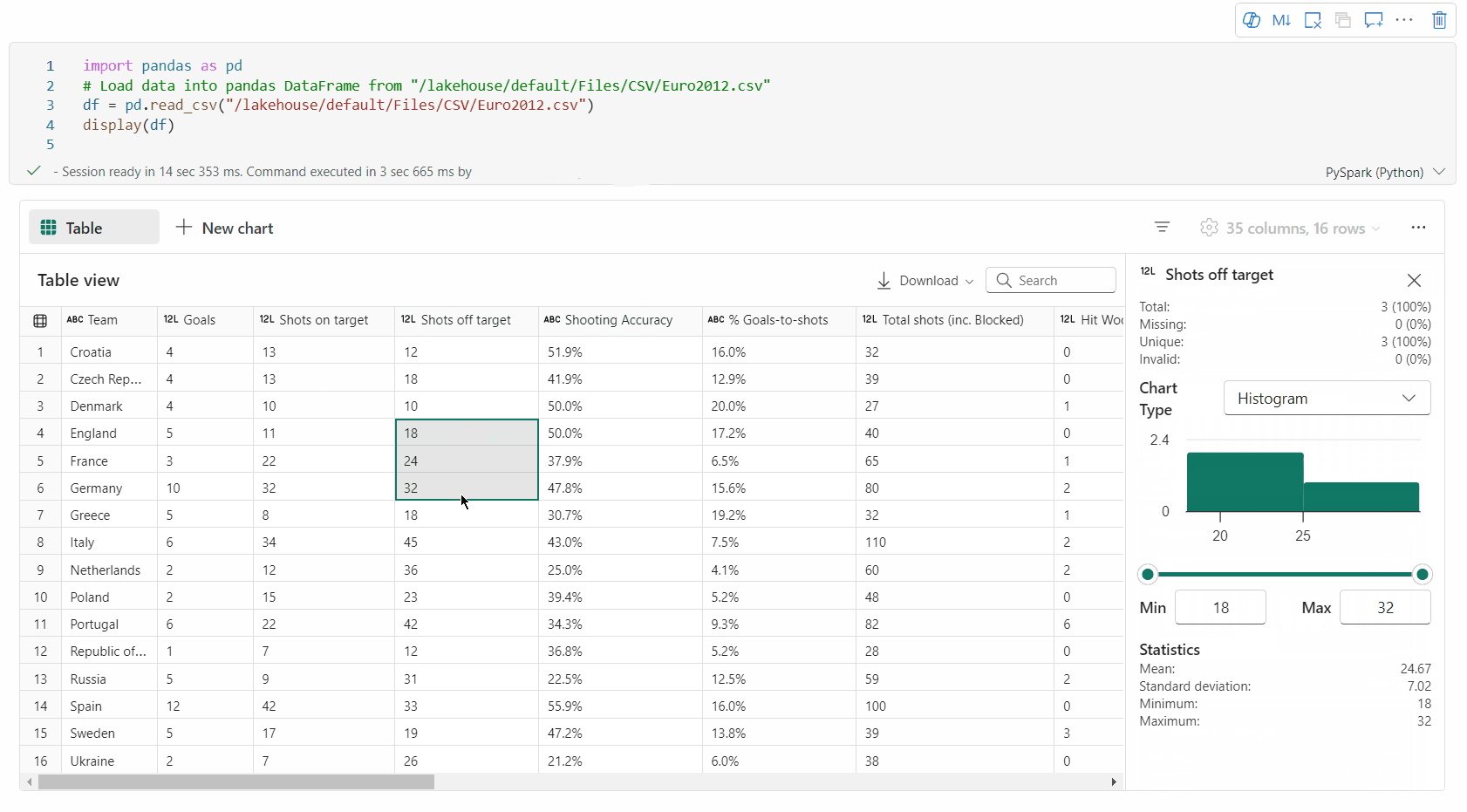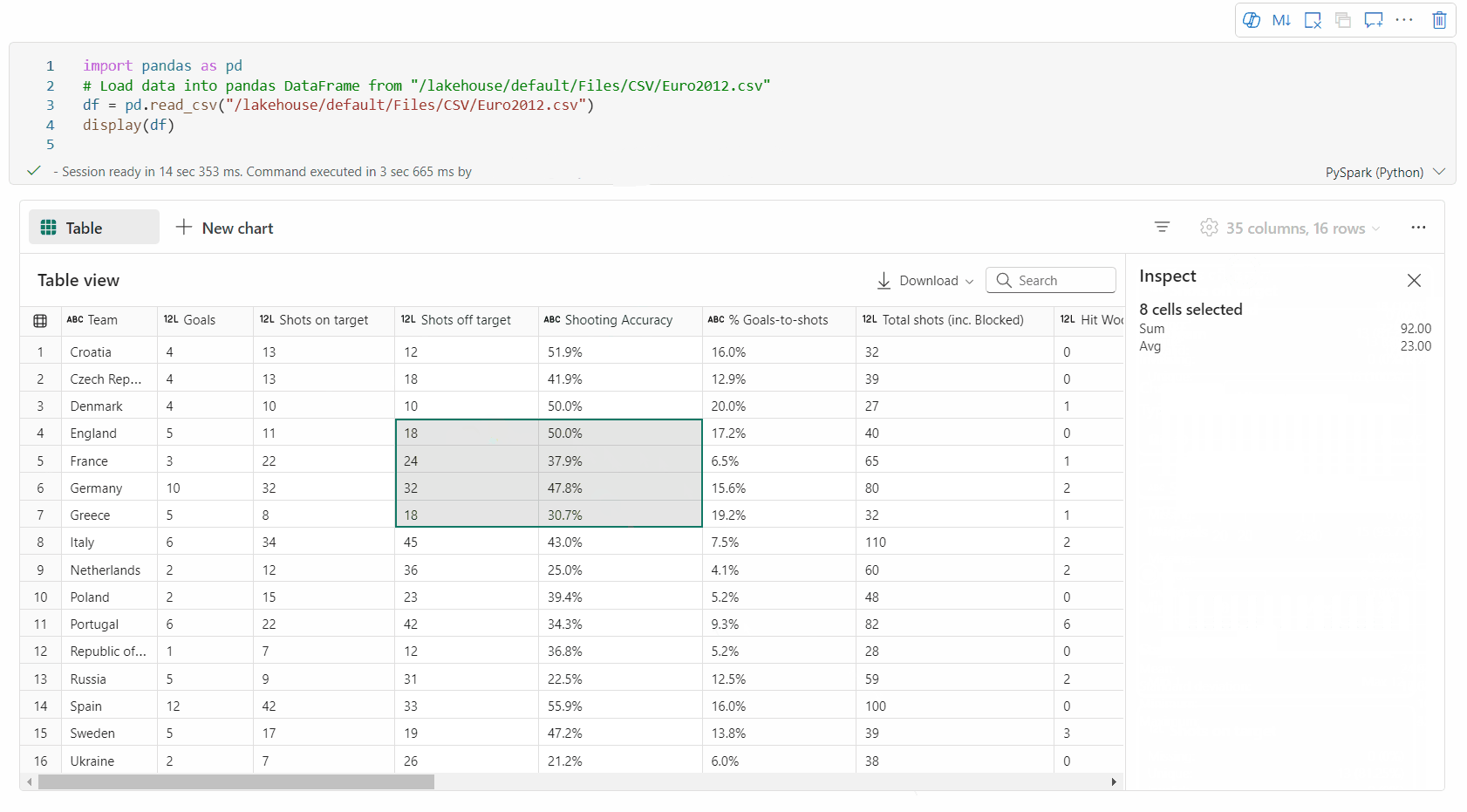
Podpora profilace dat prostřednictvím podokna Kontrola
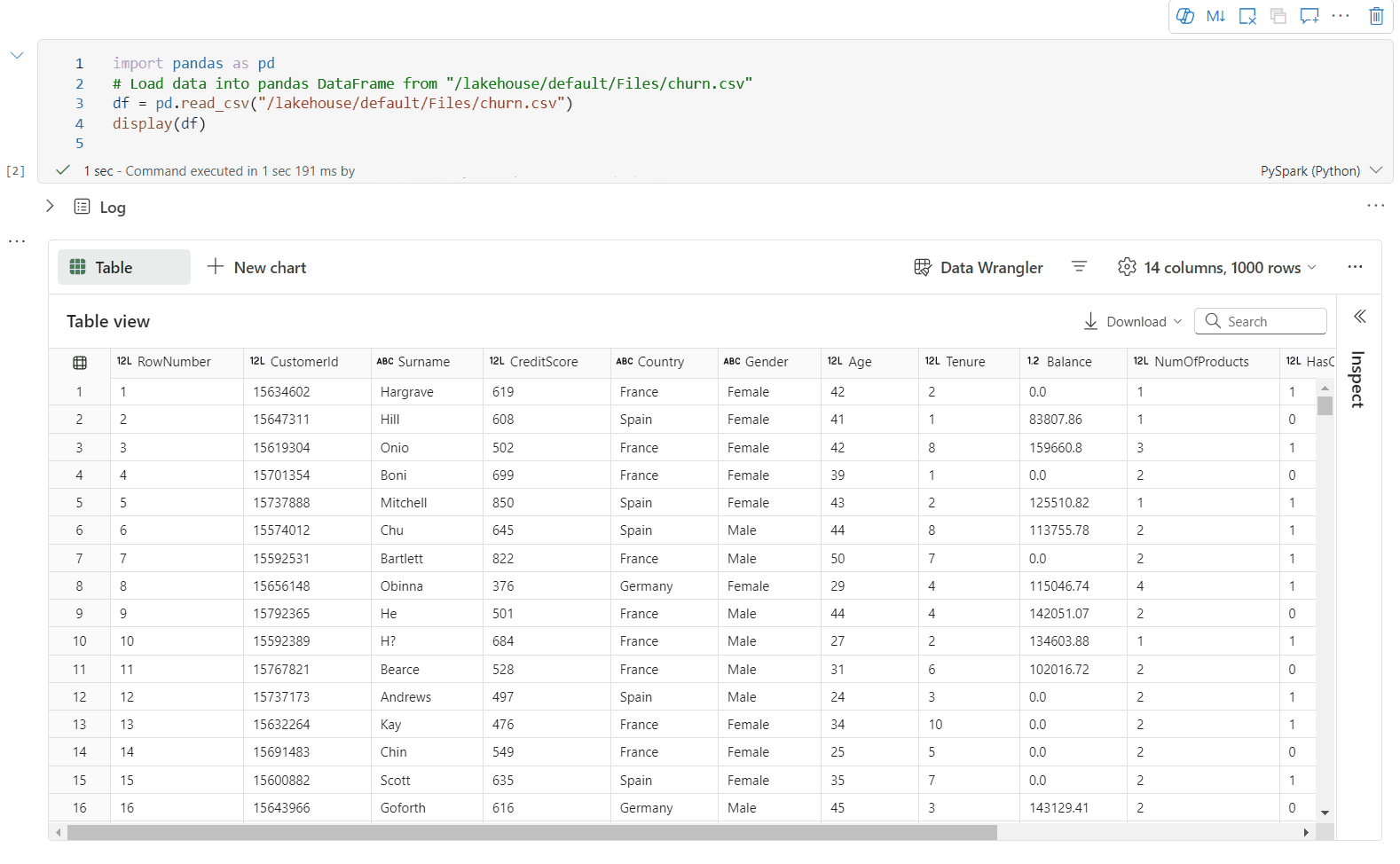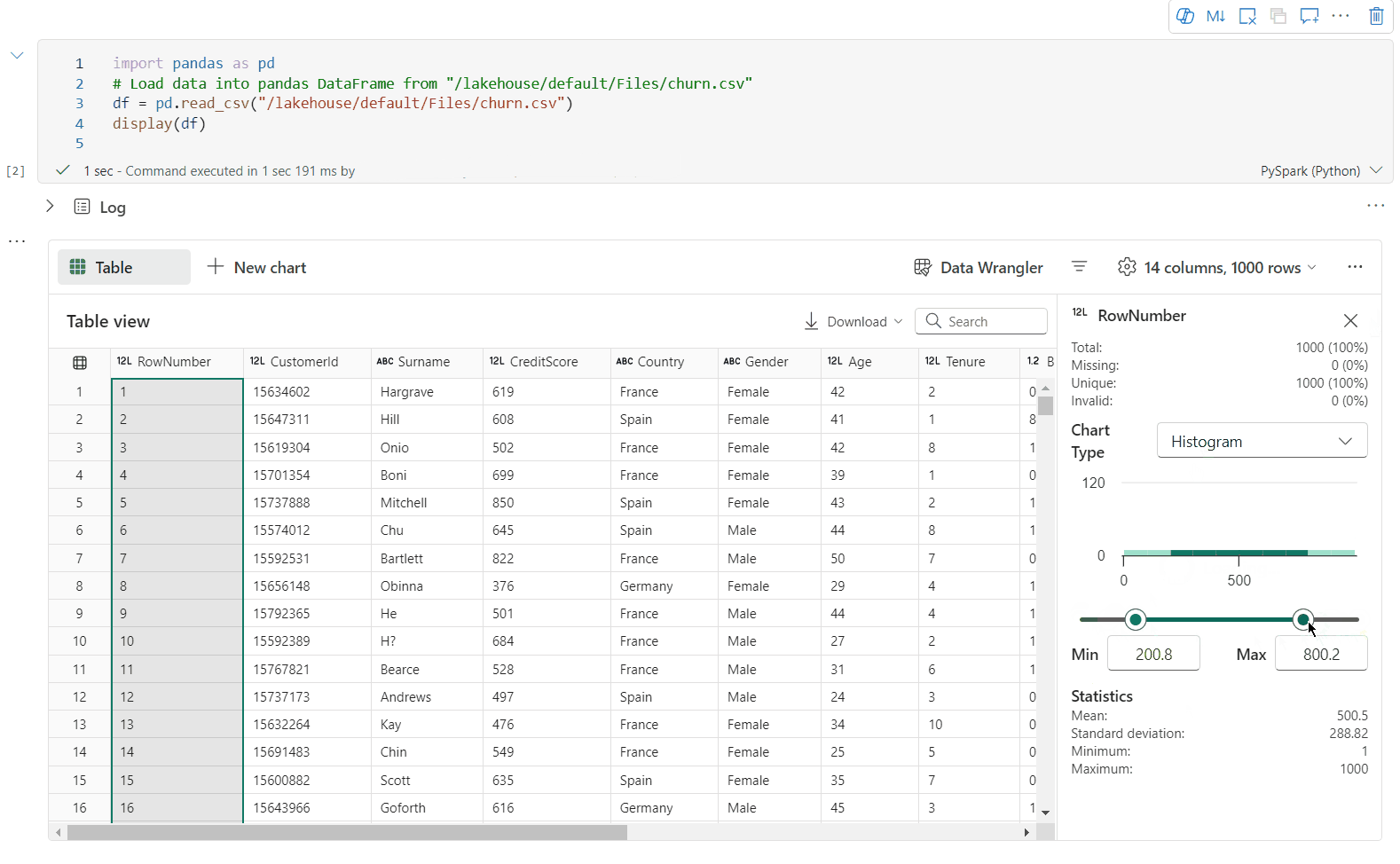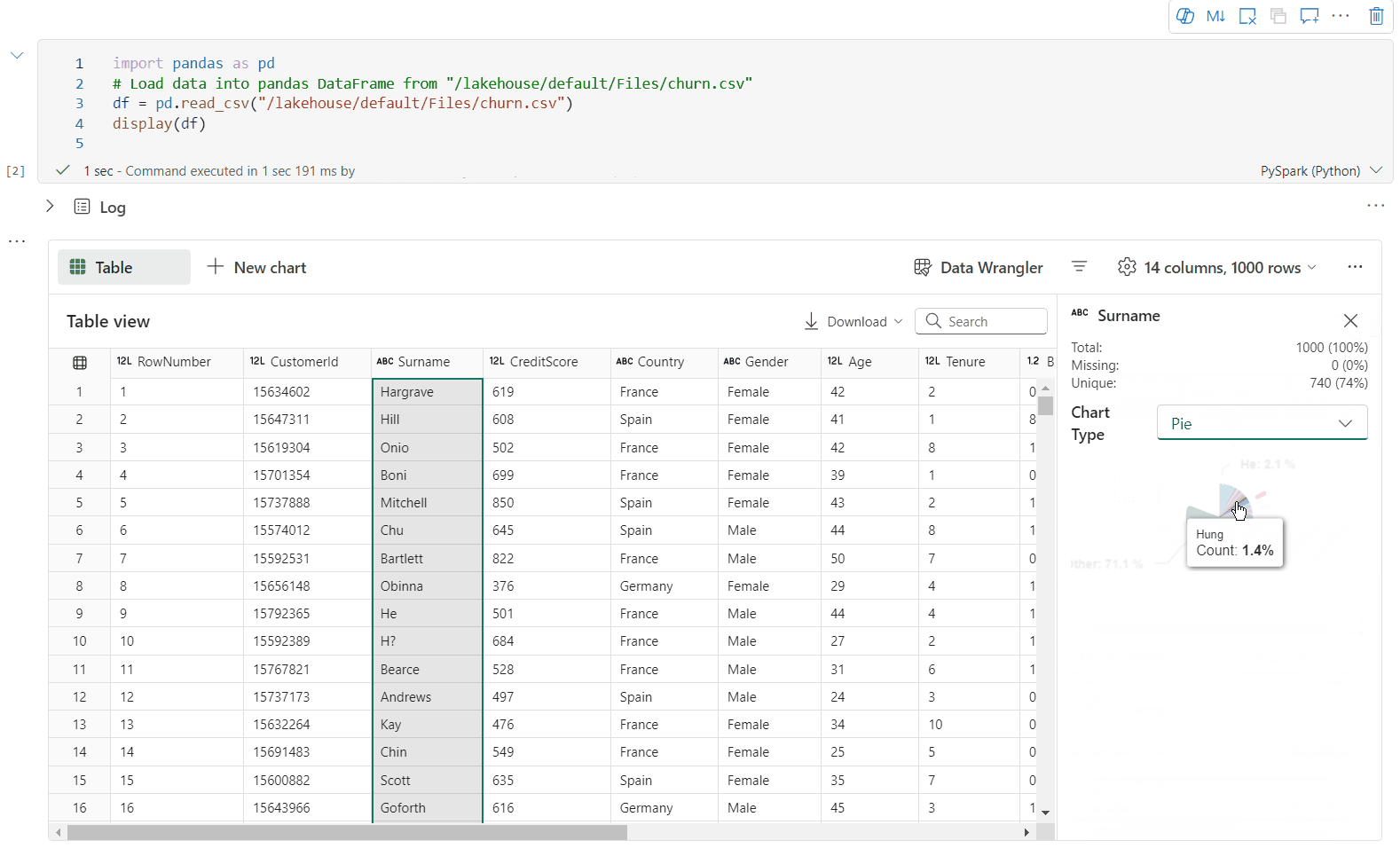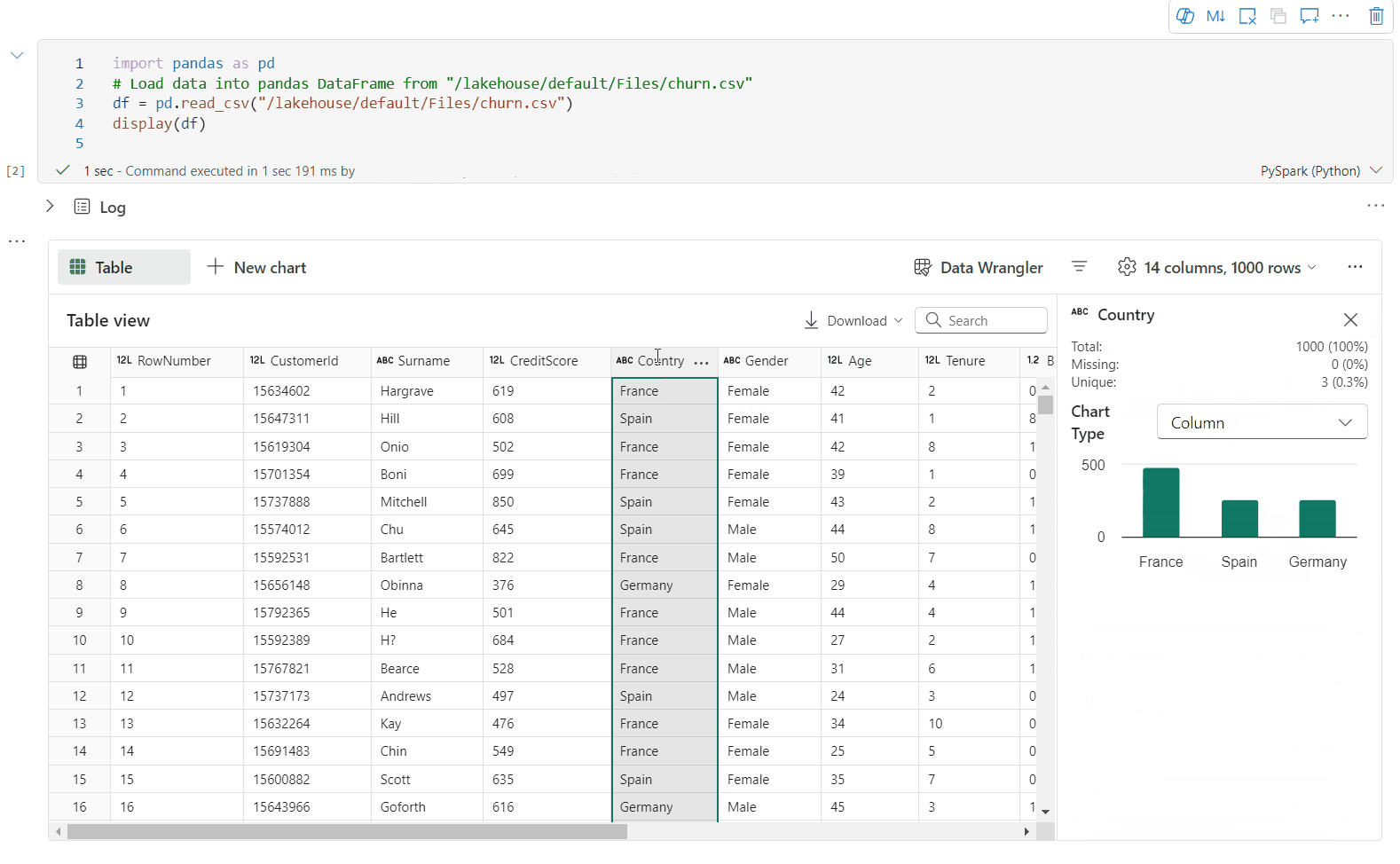
Datový rámec můžete profilovat kliknutím na tlačítko Zkontrolovat . Poskytuje souhrnnou distribuci dat a zobrazuje statistiky jednotlivých sloupců.
Každá karta v bočním podokně Kontrola se mapuje na sloupec datového rámce. Další podrobnosti můžete zobrazit kliknutím na kartu nebo výběrem sloupce v tabulce.
Podrobnosti o buňce můžete zobrazit kliknutím na buňku tabulky. Tato funkce je užitečná, pokud datový rámec obsahuje dlouhý typ řetězce obsahu.
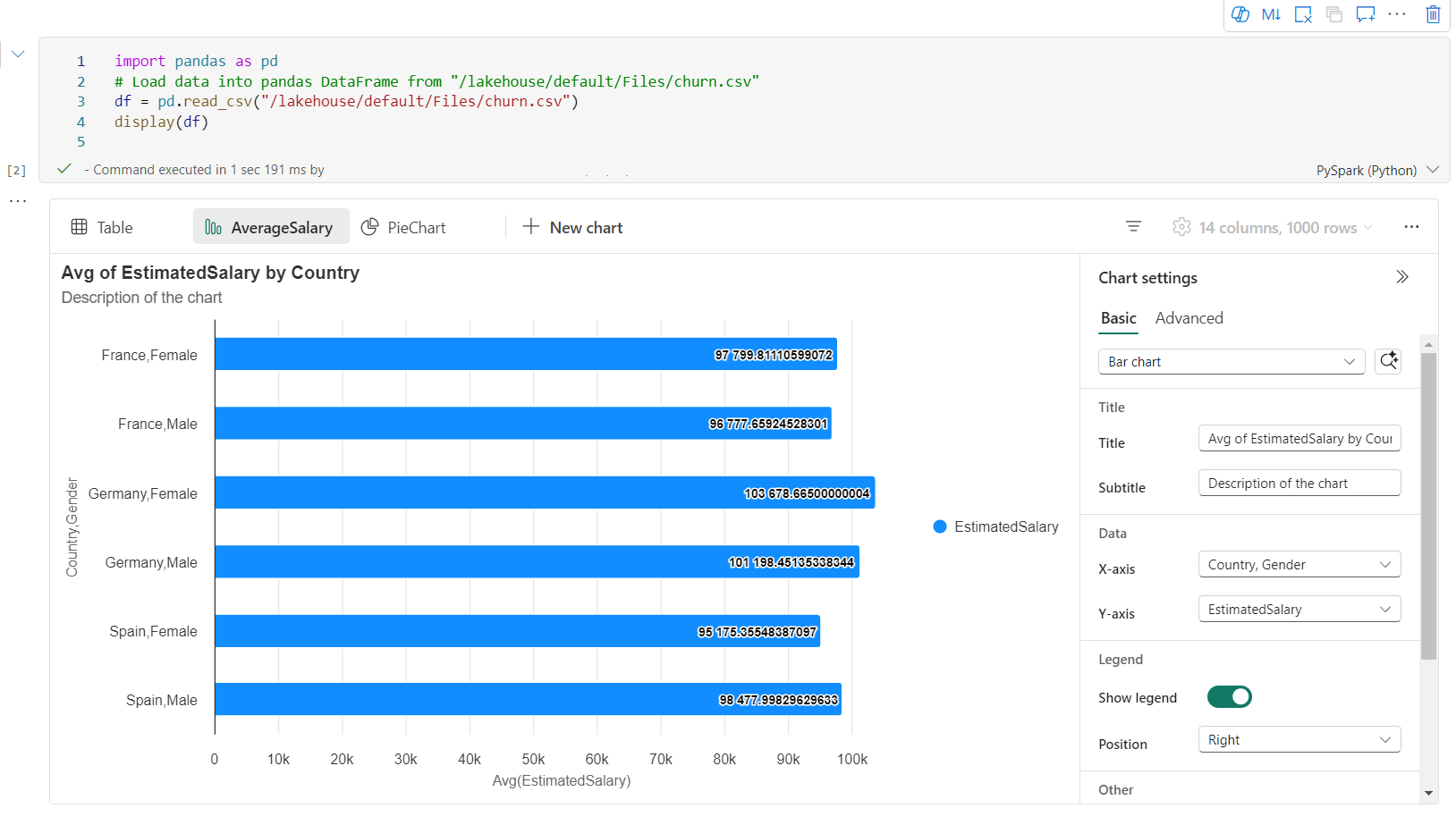
Nové zobrazení grafu s bohatým datovým rámcem
Poznámka:
V současné době je tato funkce ve verzi Preview.
Vylepšené zobrazení grafu je k dispozici v příkazu display(). Poskytuje intuitivnější a výkonnější prostředí pro vizualizaci dat pomocí příkazu display().
Teď můžete přidat až 5 grafů do jednoho widgetu výstupu zobrazení() kliknutím na Nový graf, který umožňuje vytvářet více grafů na základě různých sloupců a snadno porovnávat grafy.
Při vytváření nových grafů můžete získat seznam doporučení pro grafy na základě cílového datového rámce. Můžete upravit doporučený graf nebo vytvořit vlastní graf úplně od začátku.
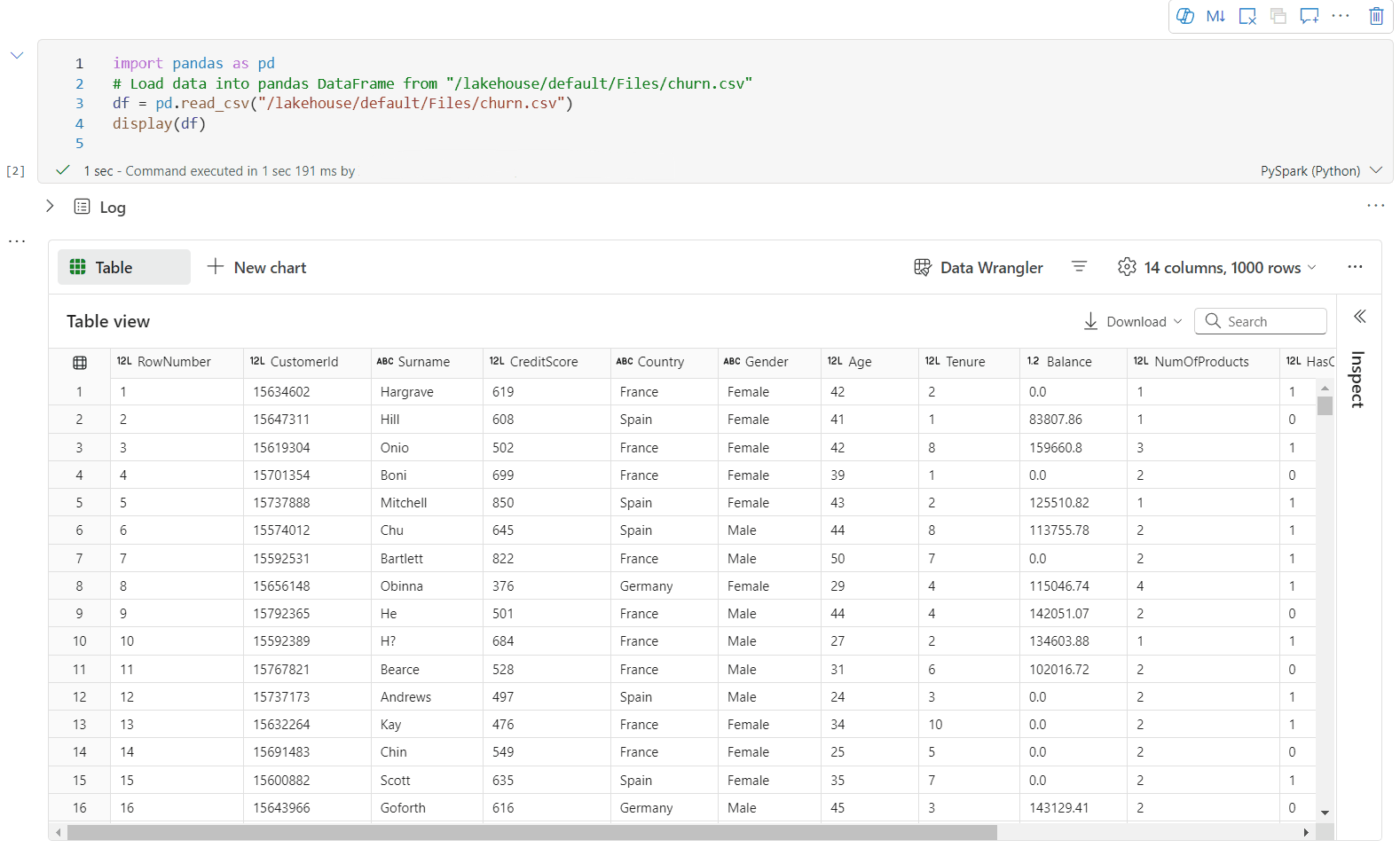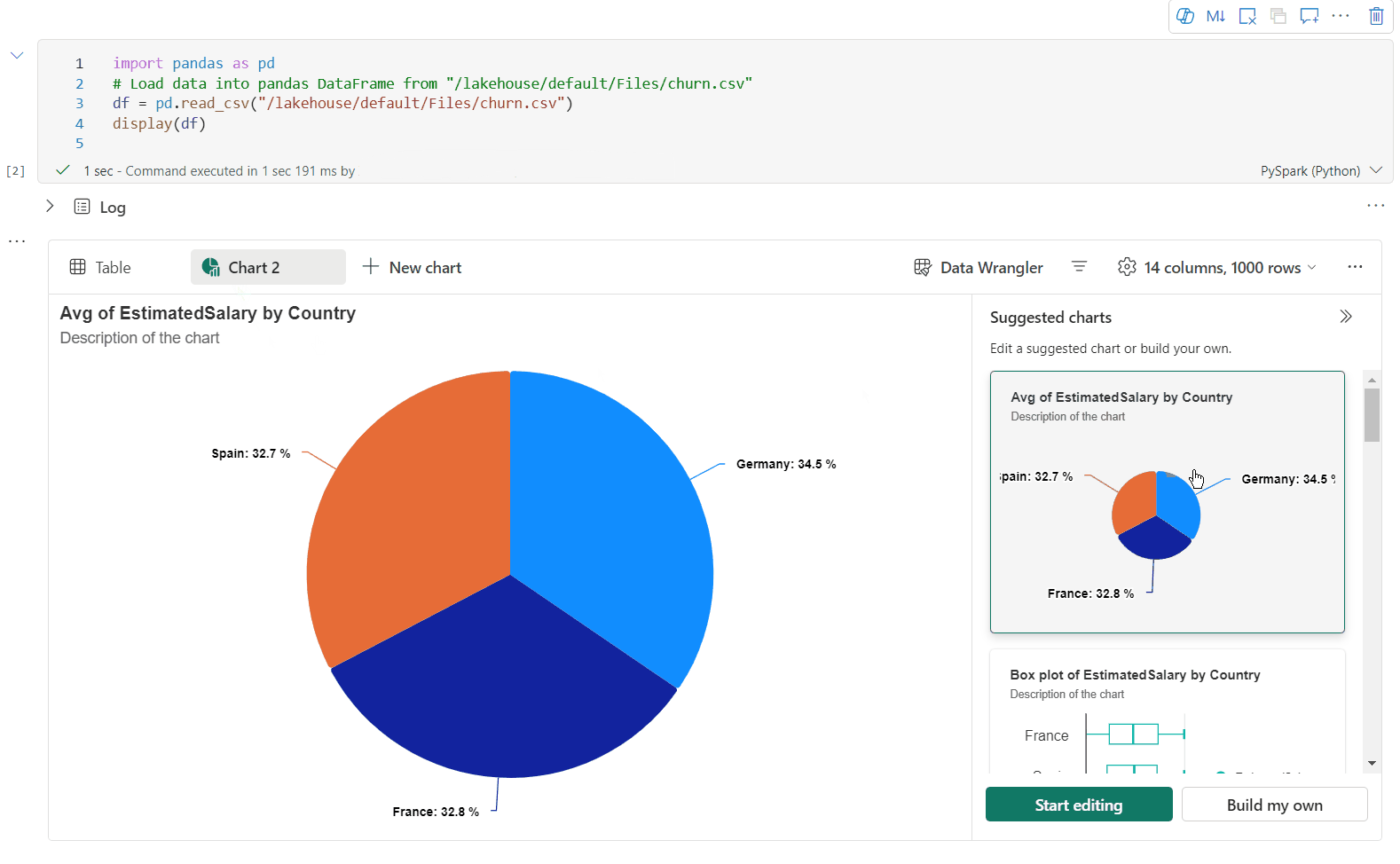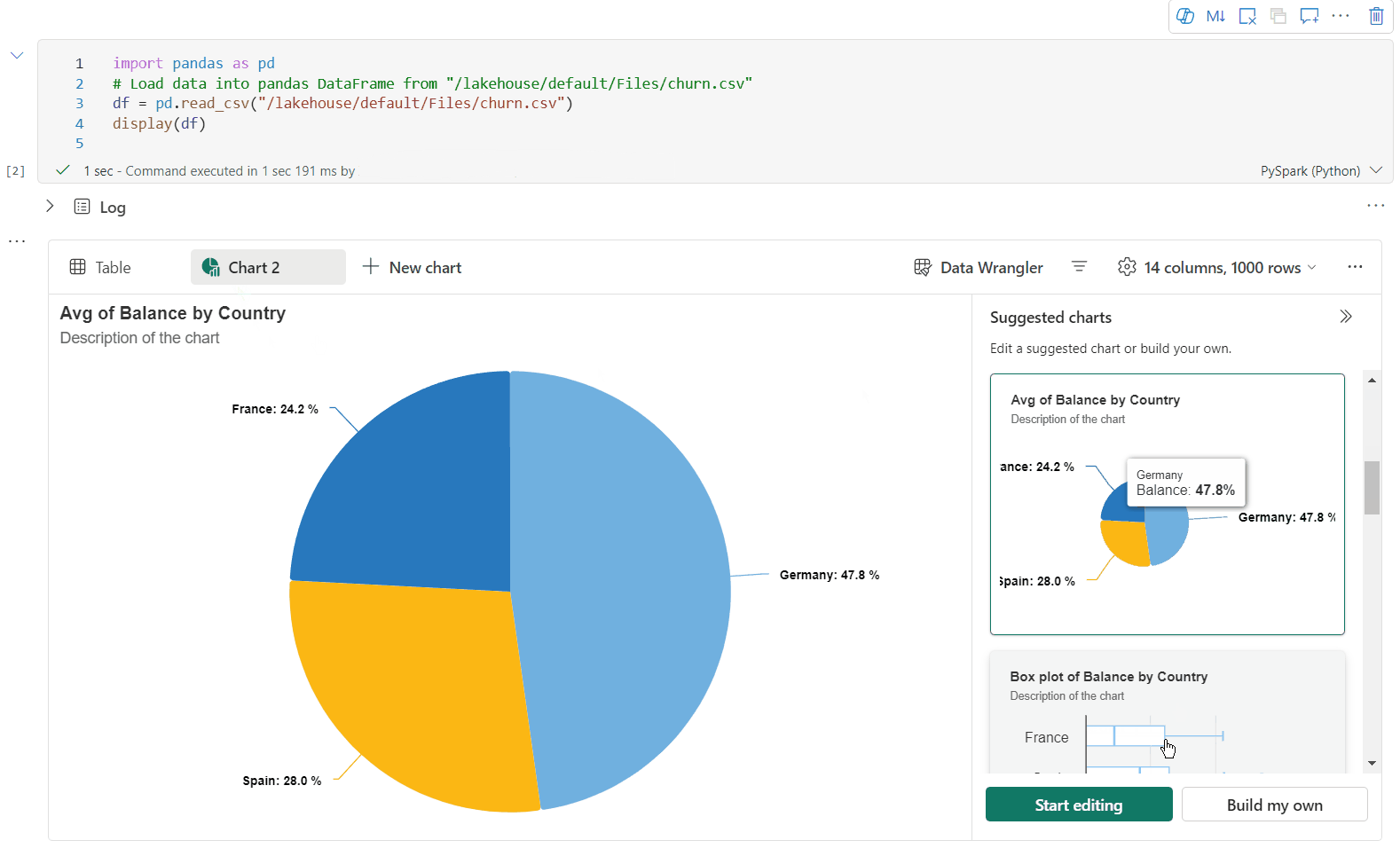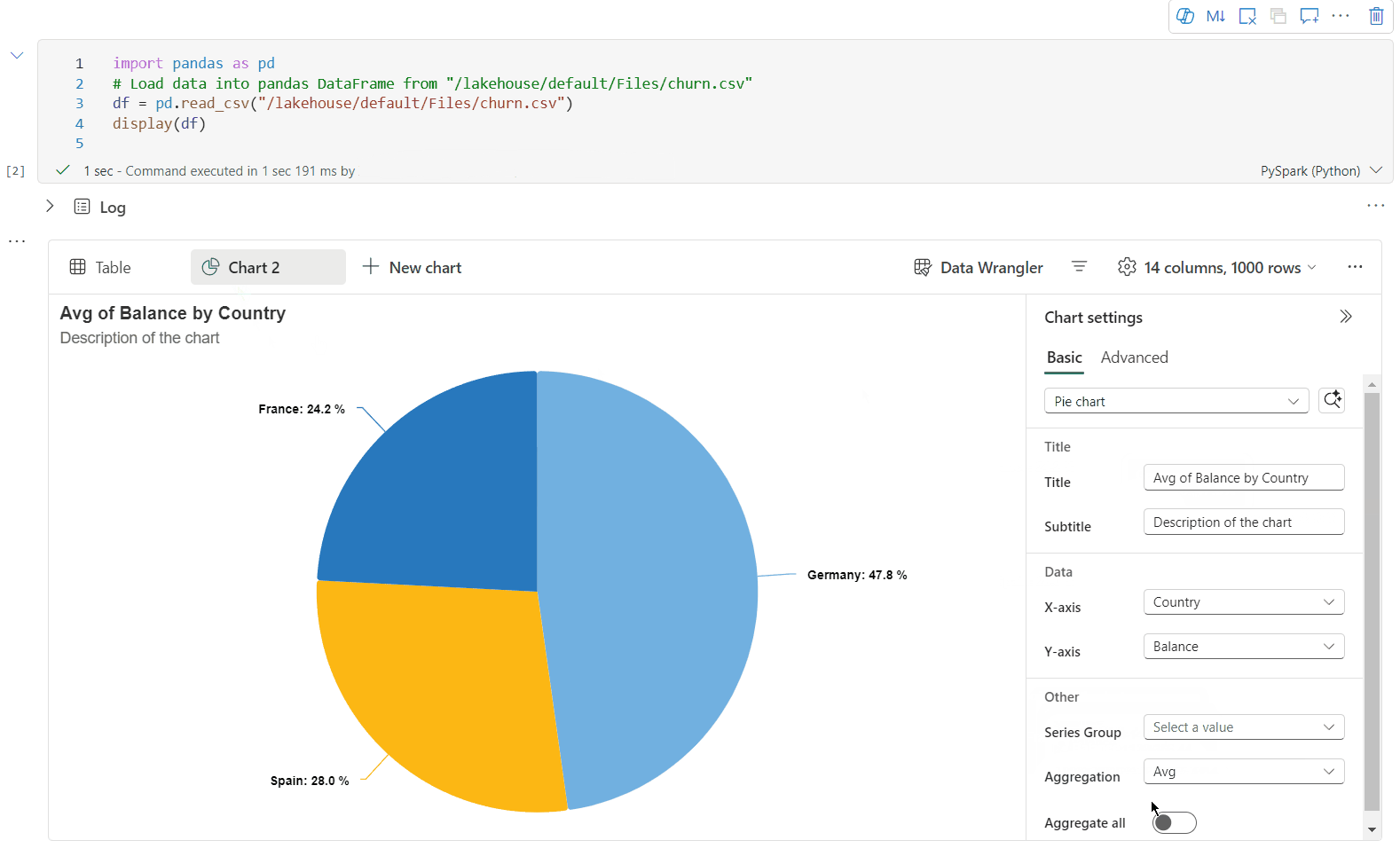
Teď můžete vizualizaci přizpůsobit zadáním následujícího nastavení. Možnosti nastavení se můžou změnit podle vybraného typu grafu:
Kategorie Základní nastavení Popis Typ grafu Funkce zobrazení podporuje širokou škálu typů grafů, včetně pruhových grafů, bodových grafů, spojnicových grafů, kontingenční tabulky a dalších. Nadpis Nadpis Název grafu. Nadpis Subtitle Podnadpis grafu s dalšími popisy Data Osa x Zadejte klíč grafu. Data Osa y Zadejte hodnoty grafu. Legenda: Zobrazit legendu Povolí nebo zakáže legendu. Legenda: Position Přizpůsobte pozici legendy. Jiný důvod Skupina Řad Pomocí této konfigurace můžete určit skupiny pro agregaci. Jiný důvod Agregace Tato metoda slouží k agregaci dat ve vizualizaci. Jiný důvod Skládaný Nakonfigurujte styl zobrazení výsledku. Poznámka:
Ve výchozím nastavení funkce display(df) přijímá pouze prvních 1 000 řádků dat k vykreslení grafů. Vyberte Možnost Agregace u všech výsledků a pak vyberte Použít pro použití generování grafu z celého datového rámce. Úloha Sparku se aktivuje při změně nastavení grafu. Dokončení výpočtu a vykreslení grafu může trvat několik minut.
Kategorie Rozšířené nastavení Popis Color Motiv Definujte barevnou sadu motivů grafu. Osa x Popisek Zadejte popisek osy X. Osa x Měřítko Zadejte funkci měřítka osy X. Osa x Rozsah Zadejte osu X rozsahu hodnot. Osa y Popisek Určete popisek pro osu Y. Osa y Měřítko Zadejte funkci měřítka osy Y. Osa y Rozsah Zadejte osu Y rozsahu hodnot. Zobrazit Zobrazit popisky Zobrazí nebo skryje popisky výsledků v grafu. Změny konfigurací se projeví okamžitě a všechny konfigurace se automaticky ukládají v obsahu poznámkového bloku.
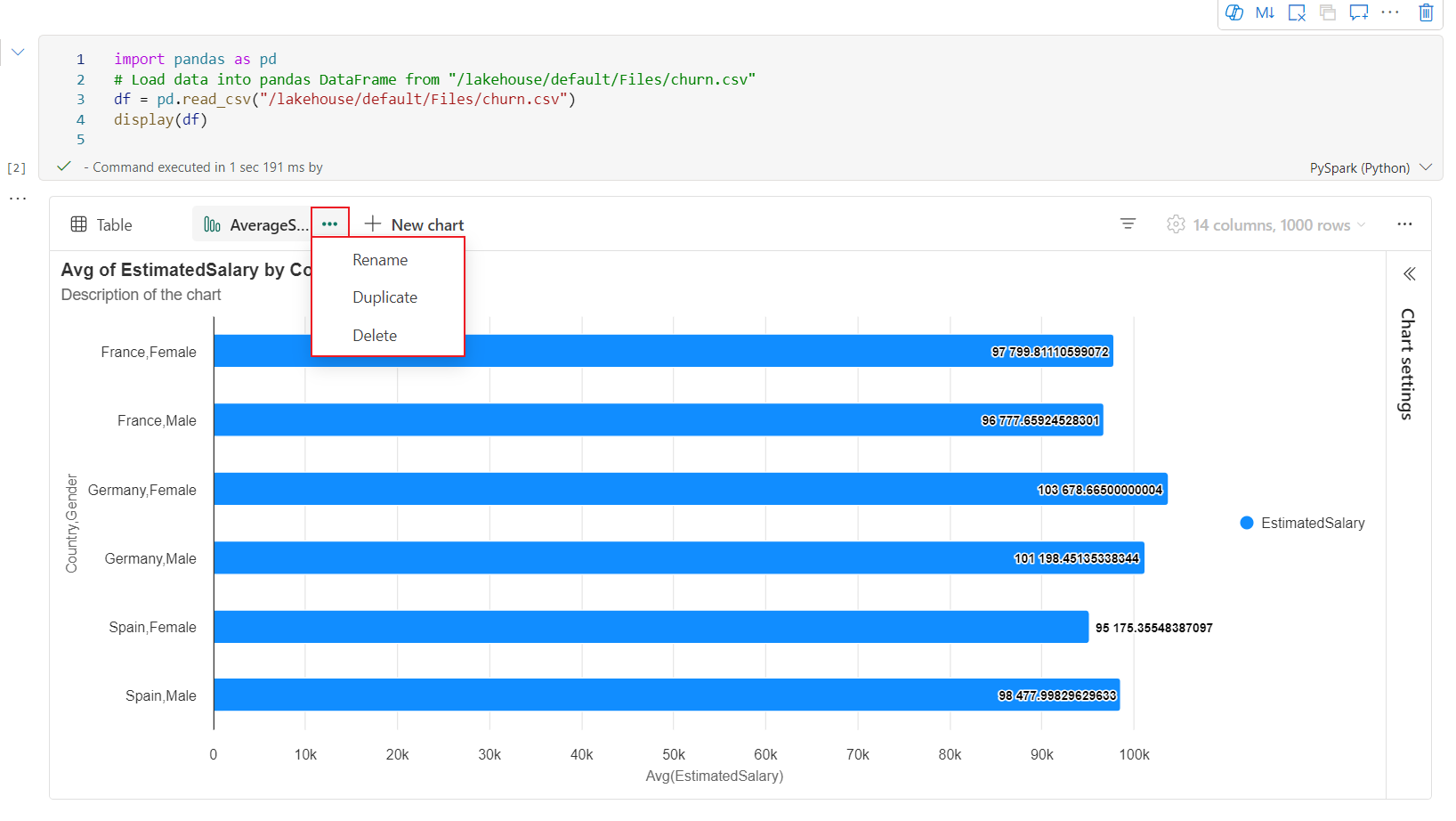
Grafy můžete snadno přejmenovat, duplikovat nebo odstranit v nabídce karty grafu.
Interaktivní panel nástrojů je k dispozici v novém prostředí grafu, když uživatel na graf najet myší. Operace podpory, jako je přiblížení, oddálení, výběr pro přiblížení, resetování, posouvání atd.




Zobrazení starší verze grafu
Poznámka:
Starší zobrazení grafu bude po dokončení náhledu nového zobrazení grafu zastaralé.
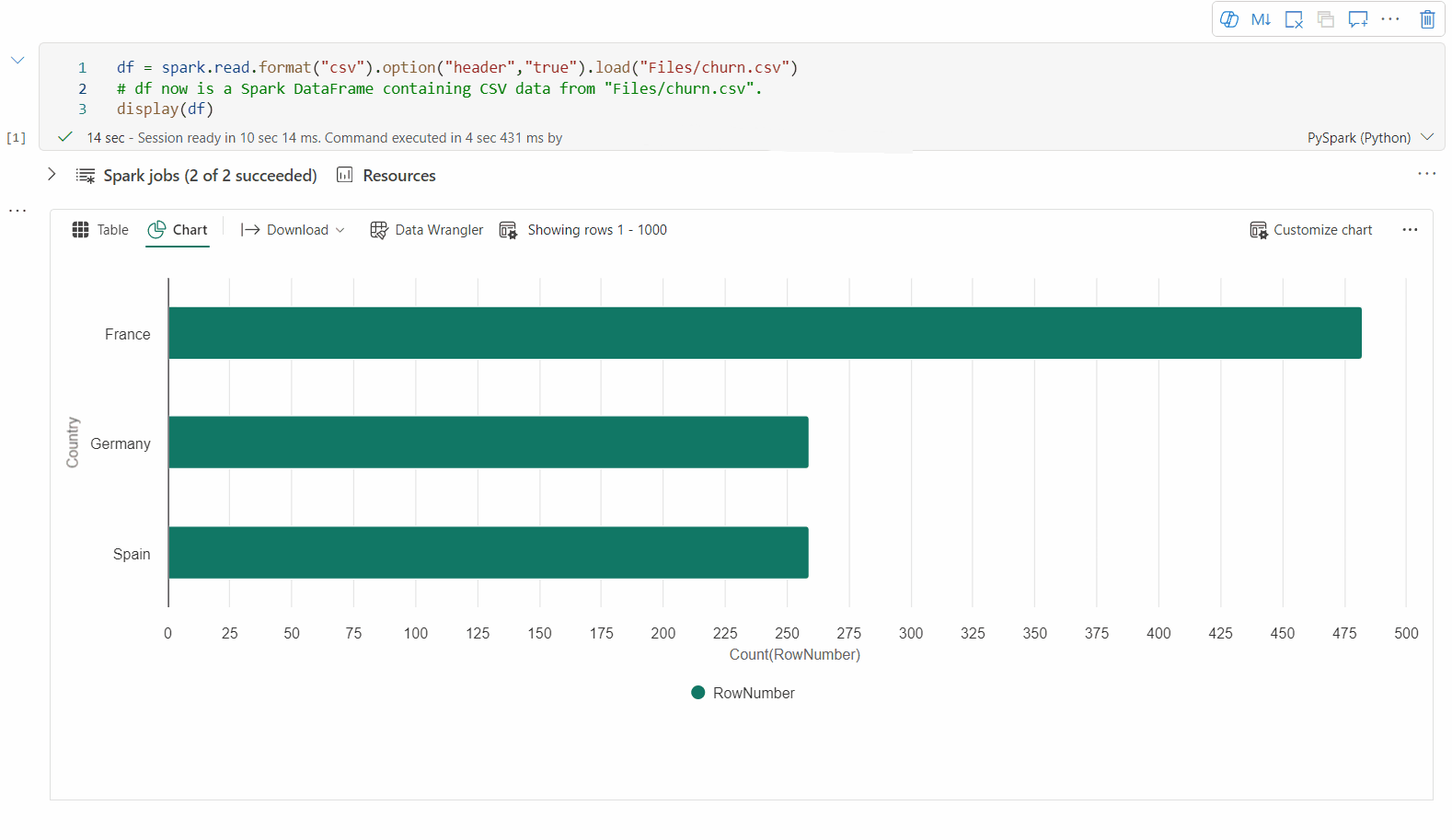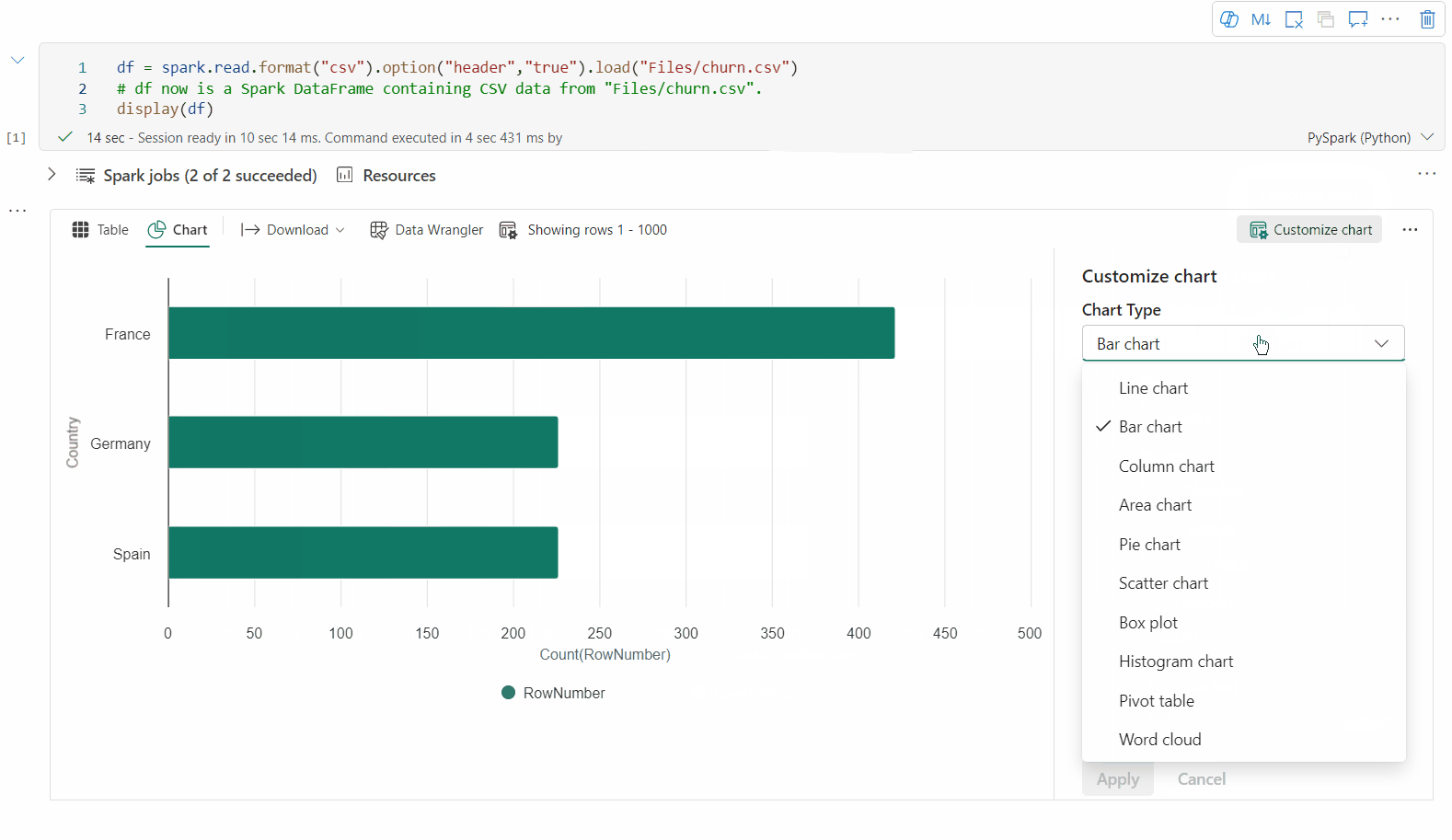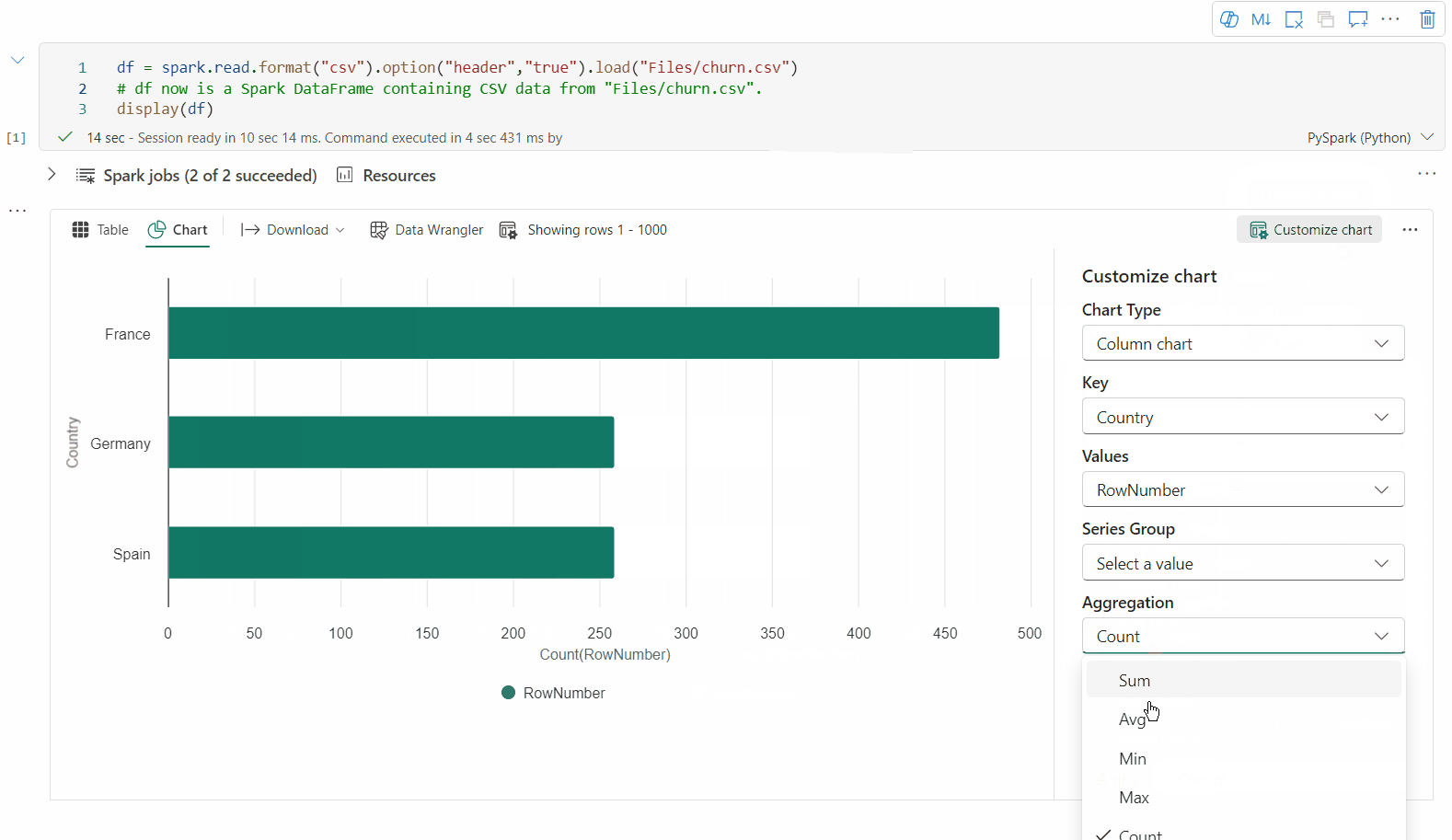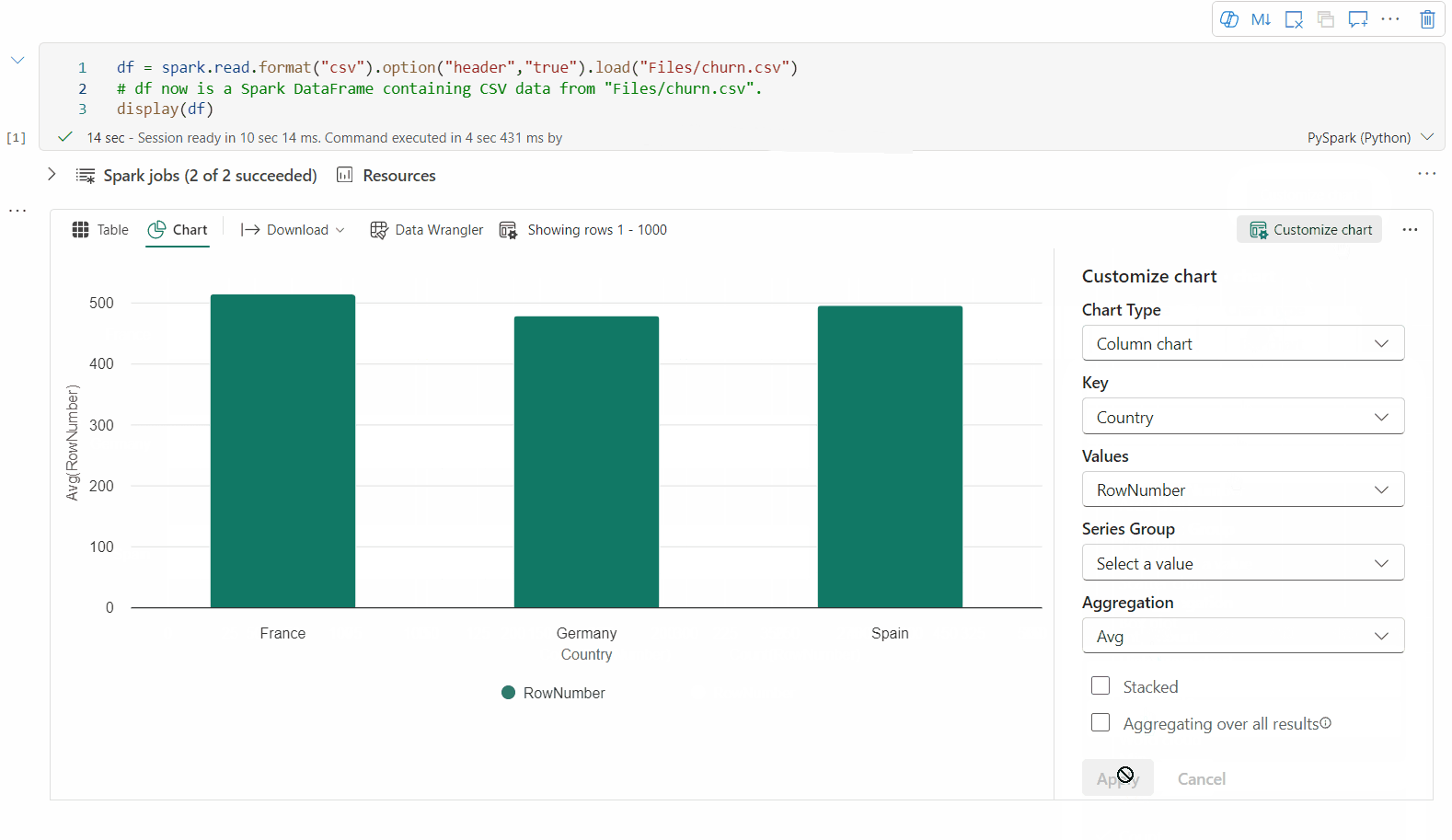
Zpět do staršího zobrazení grafu můžete přepnout přepnutím možnosti Nová vizualizace. Nové prostředí je ve výchozím nastavení povolené.
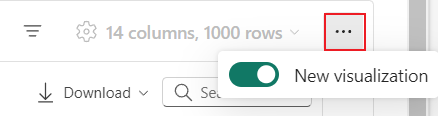
Jakmile budete mít vykreslené zobrazení tabulky, přepněte do zobrazení Graf .
Poznámkový blok Fabric automaticky doporučí grafy založené na cílovém datovém rámci, aby byl graf smysluplný pomocí přehledů dat.
Teď můžete vizualizaci přizpůsobit zadáním následujících hodnot:
Konfigurace Popis Typ grafu Funkce zobrazení podporuje širokou škálu typů grafů, včetně pruhových grafů, bodových grafů, spojnicových grafů a dalších. Klíč Zadejte rozsah hodnot pro osu x. Hodnota Zadejte rozsah hodnot pro hodnoty osy y. Skupina Řad Pomocí této konfigurace můžete určit skupiny pro agregaci. Agregace Tato metoda slouží k agregaci dat ve vizualizaci. Konfigurace se automaticky ukládají ve výstupním obsahu poznámkového bloku.
Poznámka:
Ve výchozím nastavení funkce display(df) vezme prvních 1 000 řádků dat k vykreslení grafů. Vyberte Možnost Agregace u všech výsledků a pak vyberte Použít pro použití generování grafu z celého datového rámce. Úloha Sparku se aktivuje při změně nastavení grafu. Dokončení výpočtu a vykreslení grafu může trvat několik minut.
Po dokončení úlohy můžete zobrazit konečnou vizualizaci a pracovat s ní.

display() summary view
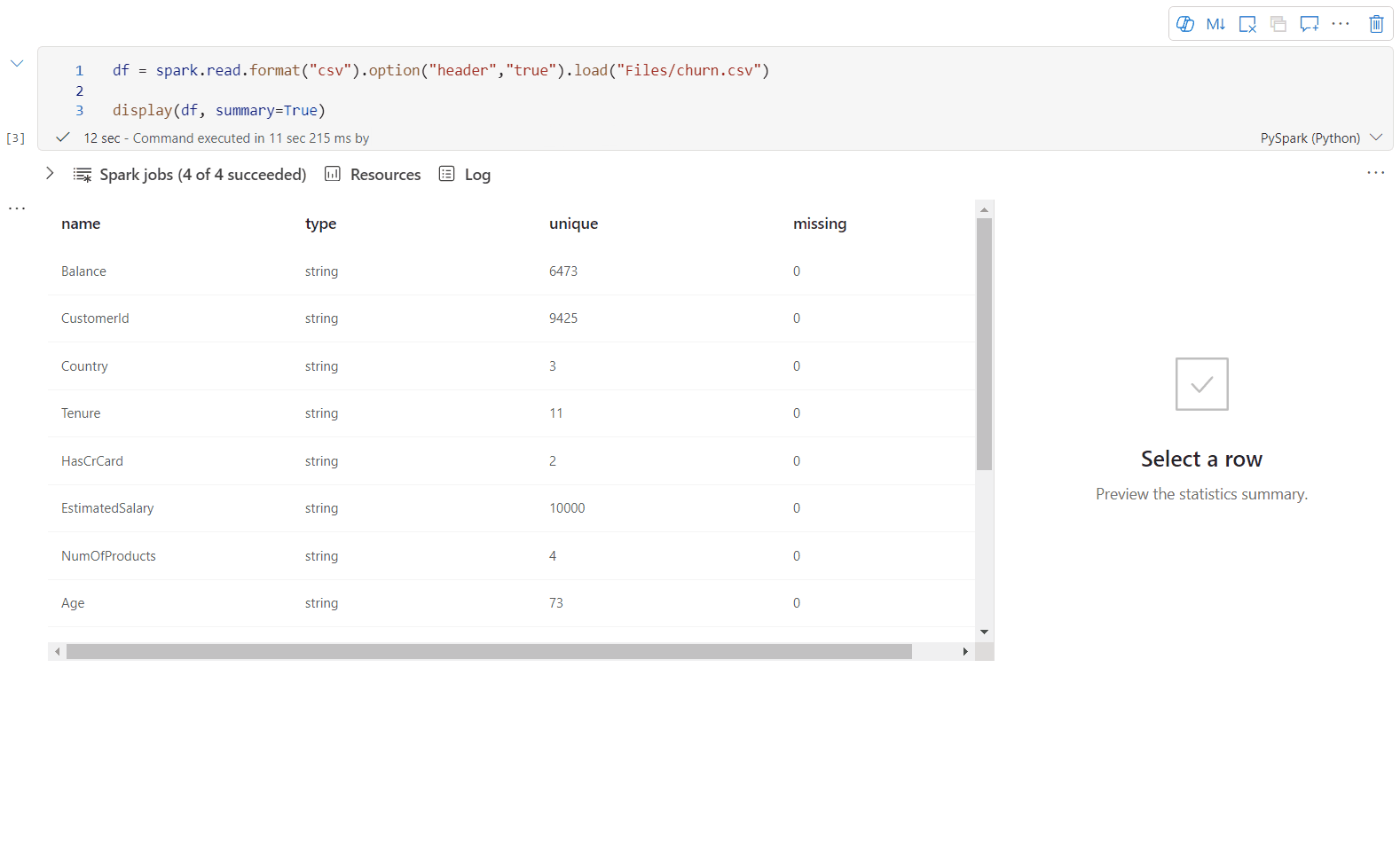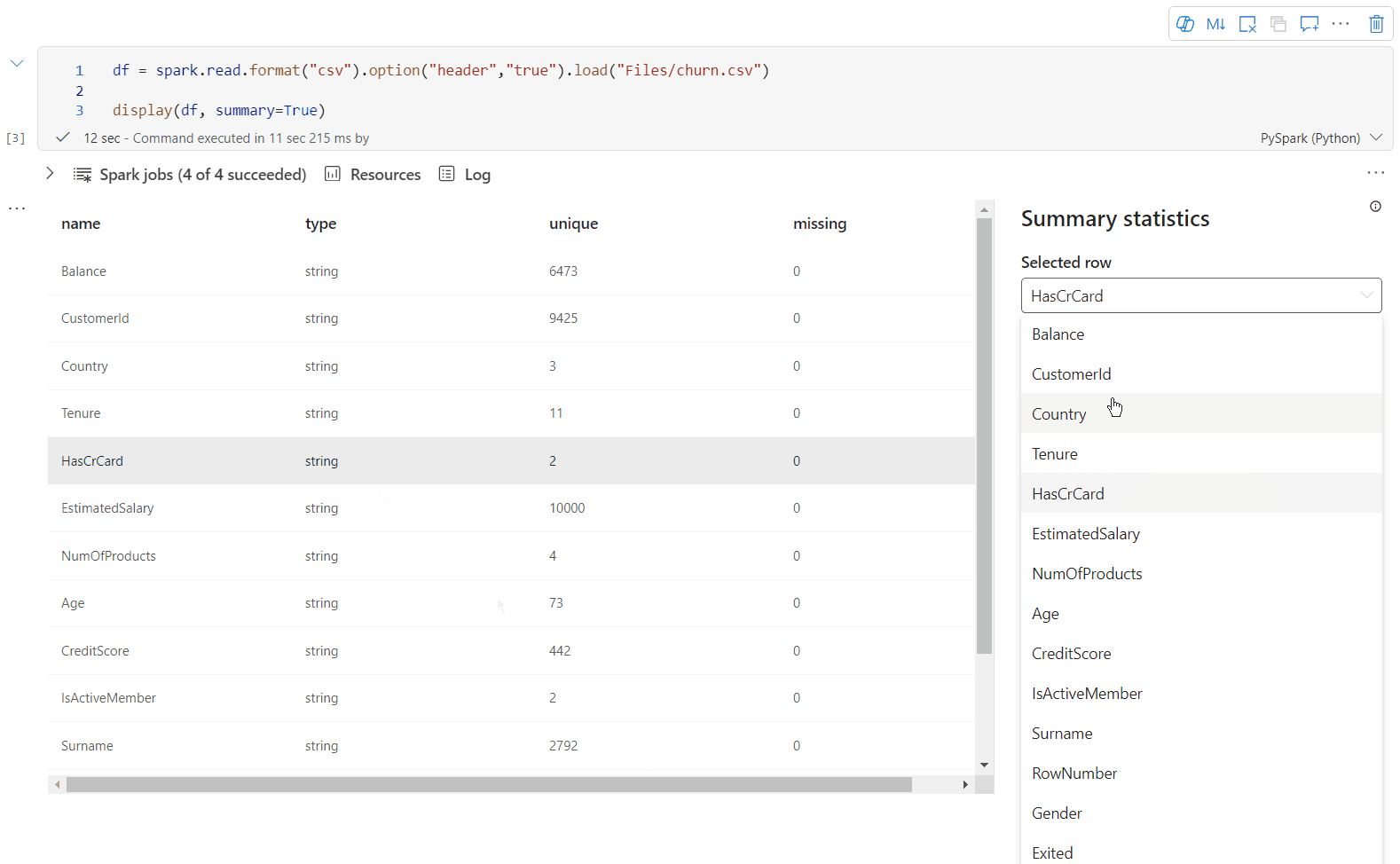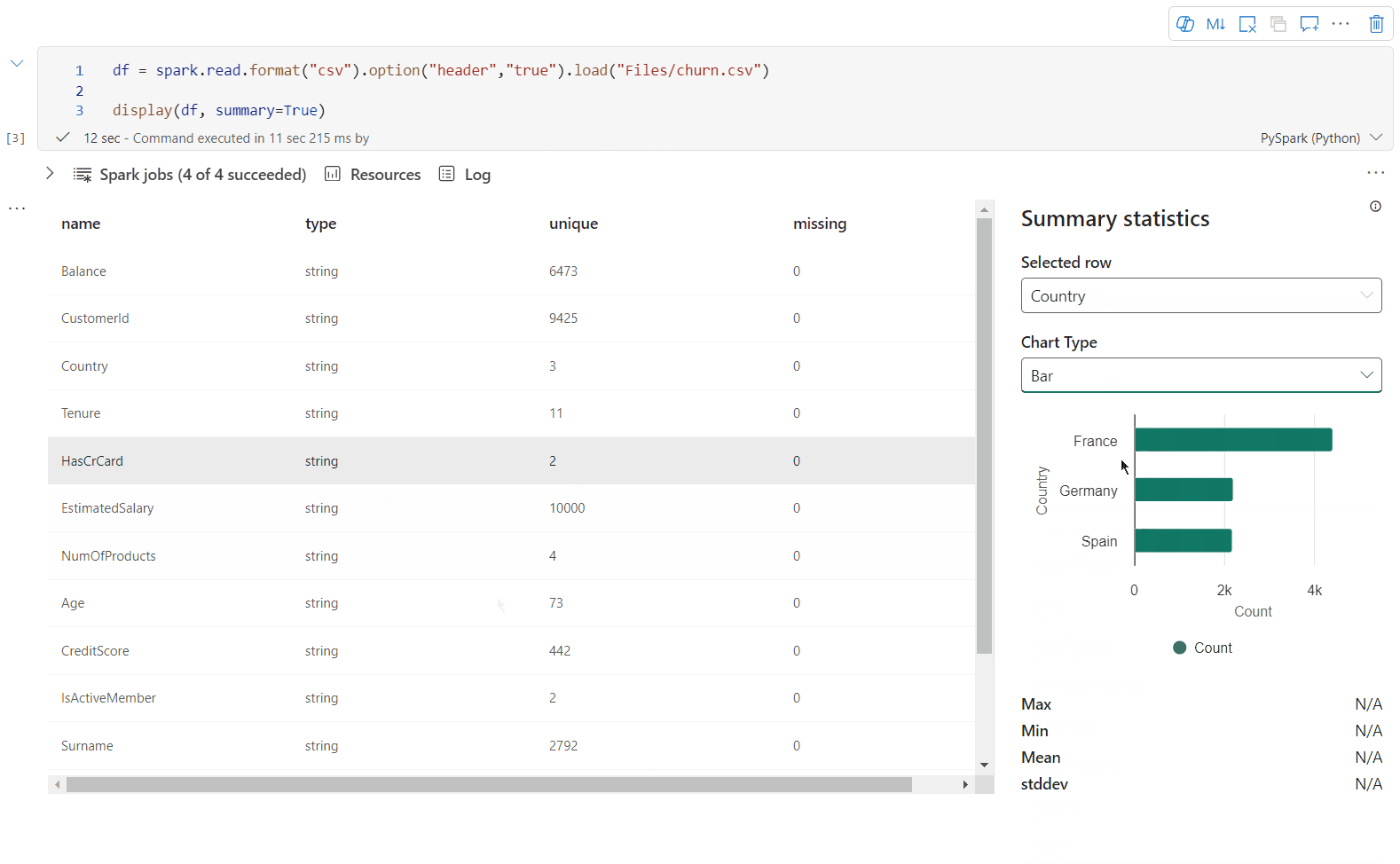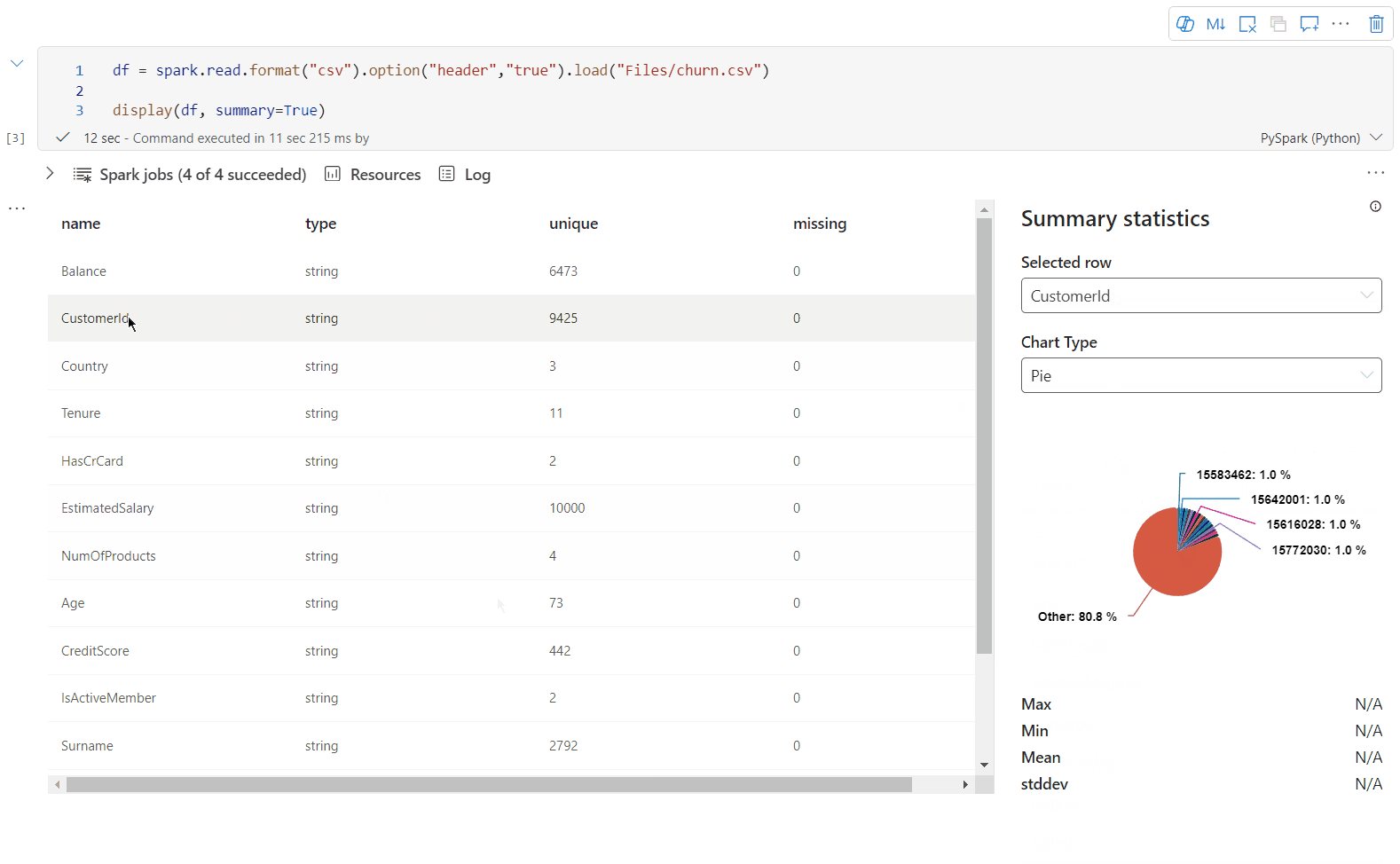
Pomocí display(df; summary = true) zkontrolujte souhrn statistik daného datového rámce Apache Spark. Souhrn obsahuje název sloupce, typ sloupce, jedinečné hodnoty a chybějící hodnoty pro každý sloupec. Můžete také vybrat konkrétní sloupec a zobrazit jeho minimální hodnotu, maximální hodnotu, střední hodnotu a směrodatnou odchylku.
možnost displayHTML()
Poznámkové bloky prostředků infrastruktury podporují grafiku HTML pomocí funkce displayHTML .
Následující obrázek je příkladem vytváření vizualizací pomocí D3.js.

Pokud chcete vytvořit tuto vizualizaci, spusťte následující kód.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Vložení sestavy Power BI do poznámkového bloku
Důležité
Tato funkce je aktuálně ve verzi PREVIEW. Tyto informace se týkají předběžného produktu, který může být podstatně změněn před dosažením obecného dostupného produktu. Společnost Microsoft neposkytuje žádné záruky, vyjádřené ani předpokládané, pokud jde o informace uvedené zde.
Balíček Powerbiclient Python je teď nativně podporovaný v poznámkových blocích Fabric. Nemusíte provádět žádné další nastavení (například proces ověřování) v poznámkovém bloku Fabric Spark 3.4. Stačí naimportovat powerbiclient a pokračovat ve zkoumání. Další informace o tom, jak používat balíček Powerbiclient, najdete v dokumentaci k Powerbiclient.
Powerbiclient podporuje následující klíčové funkce.
Vykreslení existující sestavy Power BI
Sestavy Power BI můžete do svých poznámkových bloků snadno vkládat a pracovat s nimi pomocí několika řádků kódu.
Následující obrázek je příkladem vykreslení existující sestavy Power BI.

Spuštěním následujícího kódu vykreslíte existující sestavu Power BI.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Vytváření vizuálů sestavy z datového rámce Sparku
Datový rámec Sparku v poznámkovém bloku můžete použít k rychlému vygenerování přehledných vizualizací. Položku sestavy můžete také vytvořit v cílovém pracovním prostoru výběrem možnosti Uložit ve vložené sestavě.
Následující obrázek je příkladem datového QuickVisualize() rámce Sparku.

Spuštěním následujícího kódu vykreslíte sestavu z datového rámce Sparku.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Vytváření vizuálů sestavy z datového rámce pandas
V poznámkovém bloku můžete také vytvářet sestavy založené na datovém rámci pandas.
Následující obrázek je příkladem datového QuickVisualize() rámce pandas.

Spuštěním následujícího kódu vykreslíte sestavu z datového rámce Sparku.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Oblíbené knihovny
Pokud jde o vizualizaci dat, Python nabízí několik knihoven grafů, které jsou součástí mnoha různých funkcí. Ve výchozím nastavení každý fond Apache Spark v prostředcích infrastruktury obsahuje sadu kurátorovaných a oblíbených opensourcových knihoven.
Matplotlib
Standardní knihovny vykreslování, jako je Matplotlib, můžete vykreslit pomocí integrovaných vykreslovacích funkcí pro každou knihovnu.
Následující obrázek je příkladem vytvoření pruhového grafu pomocí knihovny Matplotlib.


Spuštěním následujícího ukázkového kódu nakreslete tento pruhový graf.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Bokeh
Pomocí displayHTML(df) můžete vykreslit HTML nebo interaktivní knihovny, jako je bokeh.
Následující obrázek je příkladem vykreslení glyfů přes mapu pomocí bokeh.

Pokud chcete nakreslit tento obrázek, spusťte následující ukázkový kód.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Pomocí displayHTML() můžete vykreslit HTML nebo interaktivní knihovny, jako je Plotly.
Pokud chcete nakreslit tento obrázek, spusťte následující ukázkový kód.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandy
Výstup HTML datových rámců pandas můžete zobrazit jako výchozí výstup. Poznámkové bloky prostředků infrastruktury automaticky zobrazují stylovaný obsah HTML.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df