Použití rozhraní Livy API k odesílání a spouštění dávkových úloh Livy
Poznámka:
Rozhraní API Livy for Fabric Datoví technici ing je ve verzi Preview.
Platí pro:✅ Datoví technici ing a Datová Věda v Microsoft Fabric
Odešlete dávkové úlohy Sparku pomocí rozhraní API Livy pro prostředky infrastruktury Datoví technici.
Požadavky
Kapacita Fabric Premium nebo zkušební verze se službou Lakehouse
Vzdálený klient, jako je Visual Studio Code s jupyter Notebooks, PySpark a knihovnou MSAL (Microsoft Authentication Library) pro Python
Pro přístup k rozhraní REST API fabric se vyžaduje token aplikace Microsoft Entra. Zaregistrujte aplikaci na platformě Microsoft Identity Platform.
Některá data ve vašem jezeře, tento příklad používá NYC Taxi & Limousine Commission green_tripdata_2022_08 parketový soubor načtený do jezera.
Rozhraní Livy API definuje jednotný koncový bod pro operace. Zástupné symboly {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} a {Fabric_LakehouseID} nahraďte příslušnými hodnotami, když budete postupovat podle příkladů v tomto článku.
Konfigurace editoru Visual Studio Code pro batch rozhraní Livy API
Ve svém Fabric Lakehouse vyberte Nastavení Lakehouse.

Přejděte do části Koncový bod Livy.
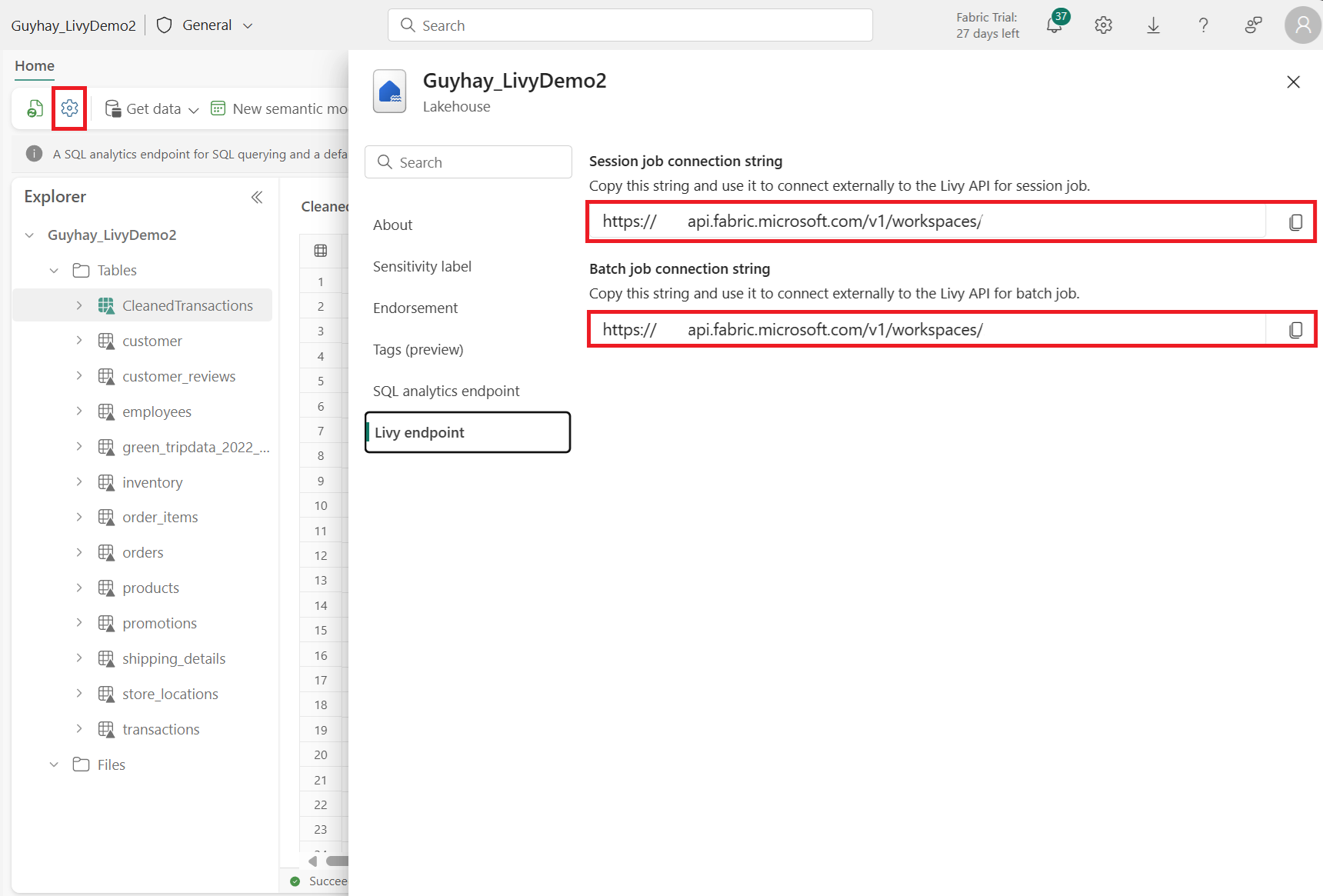
Zkopírujte úlohu Batch připojovací řetězec (druhé červené pole na obrázku) do kódu.
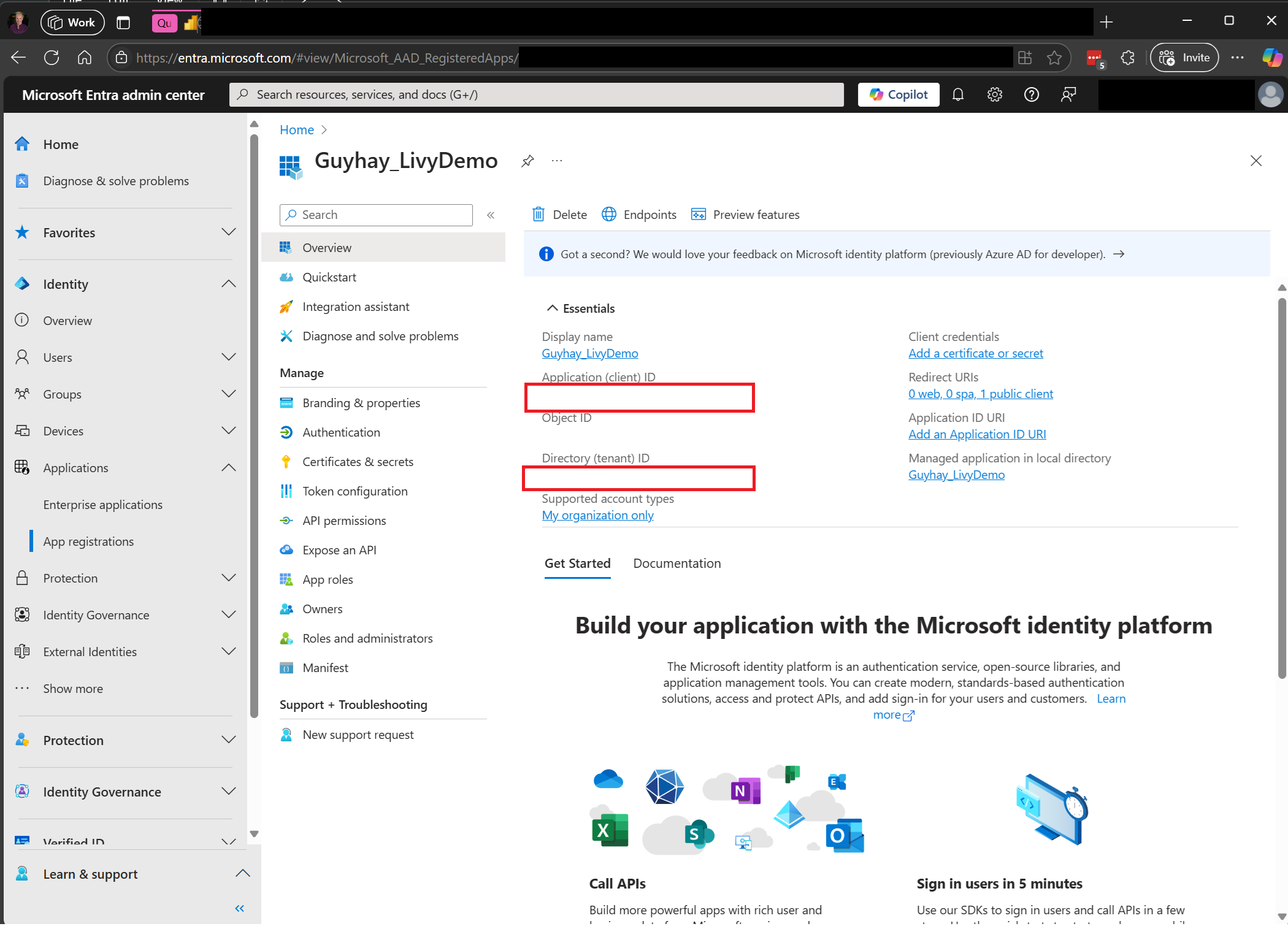
Přejděte do Centra pro správu Microsoft Entra a zkopírujte ID aplikace (klienta) i ID adresáře (tenanta) do kódu.



Vytvoření datové části Sparku a nahrání do lakehouse
Vytvoření poznámkového bloku v editoru
.ipynbVisual Studio Code a vložení následujícího kóduimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Uložte soubor Pythonu místně. Tato datová část kódu Pythonu obsahuje dva příkazy Sparku, které pracují s daty v Lakehouse a je potřeba je nahrát do vašeho Lakehouse. Budete potřebovat cestu ABFS zátěže, abyste ji mohli uvést v dávkové úloze rozhraní API Livy ve Visual Studio Code, a také název tabulky Lakehouse v příkazu SQL SELECT.

Nahrajte datovou část Pythonu do části soubory vašeho Lakehouse. >Načíst soubory > nahrání dat > klikněte do pole Soubory nebo vstup.

Jakmile je soubor v části Soubory vašeho Lakehouse, klikněte na tři tečky napravo od názvu souboru datové části a vyberte Vlastnosti.

Zkopírujte tuto cestu ABFS do buňky poznámkového bloku v kroku 1.



Vytvoření dávkové relace sparkového rozhraní API Livy
Vytvořte poznámkový blok v editoru
.ipynbVisual Studio Code a vložte následující kód.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Spusťte buňku poznámkového bloku, měla by se v prohlížeči zobrazit automaticky otevíraná nabídka, která vám umožní zvolit identitu pro přihlášení.
Jakmile zvolíte identitu pro přihlášení, budete také požádáni o schválení oprávnění rozhraní API pro registraci aplikací Microsoft Entra.
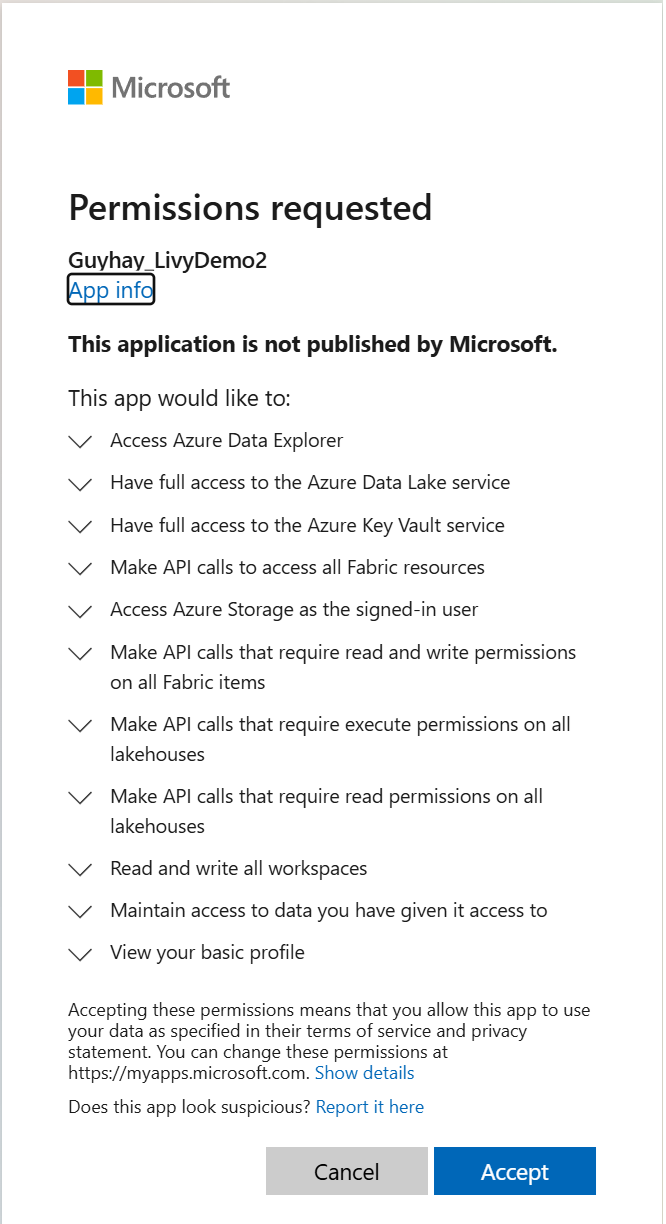
Po dokončení ověřování zavřete okno prohlížeče.

V editoru Visual Studio Code byste měli vidět vrácený token Microsoft Entra.
Přidejte další buňku poznámkového bloku a vložte tento kód.
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Spusťte buňku poznámkového bloku. Při vytváření dávkové úlohy Livy by se měly zobrazit dva řádky.






Odeslání příkazu spark.sql pomocí dávkové relace rozhraní Livy API
Přidejte další buňku poznámkového bloku a vložte tento kód.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Spusťte buňku poznámkového bloku. Při vytváření a spuštění úlohy Livy Batch by se mělo zobrazit několik řádků.

Vraťte se do svého Lakehouse a zobrazte změny.

Zobrazení úloh v centru monitorování
K centru monitorování se dostanete tak, že vyberete Možnost Monitorování v navigačních odkazech na levé straně a zobrazíte různé aktivity Apache Sparku.
Po dokončení dávkové úlohy můžete stav relace zobrazit tak, že přejdete na Monitorování.
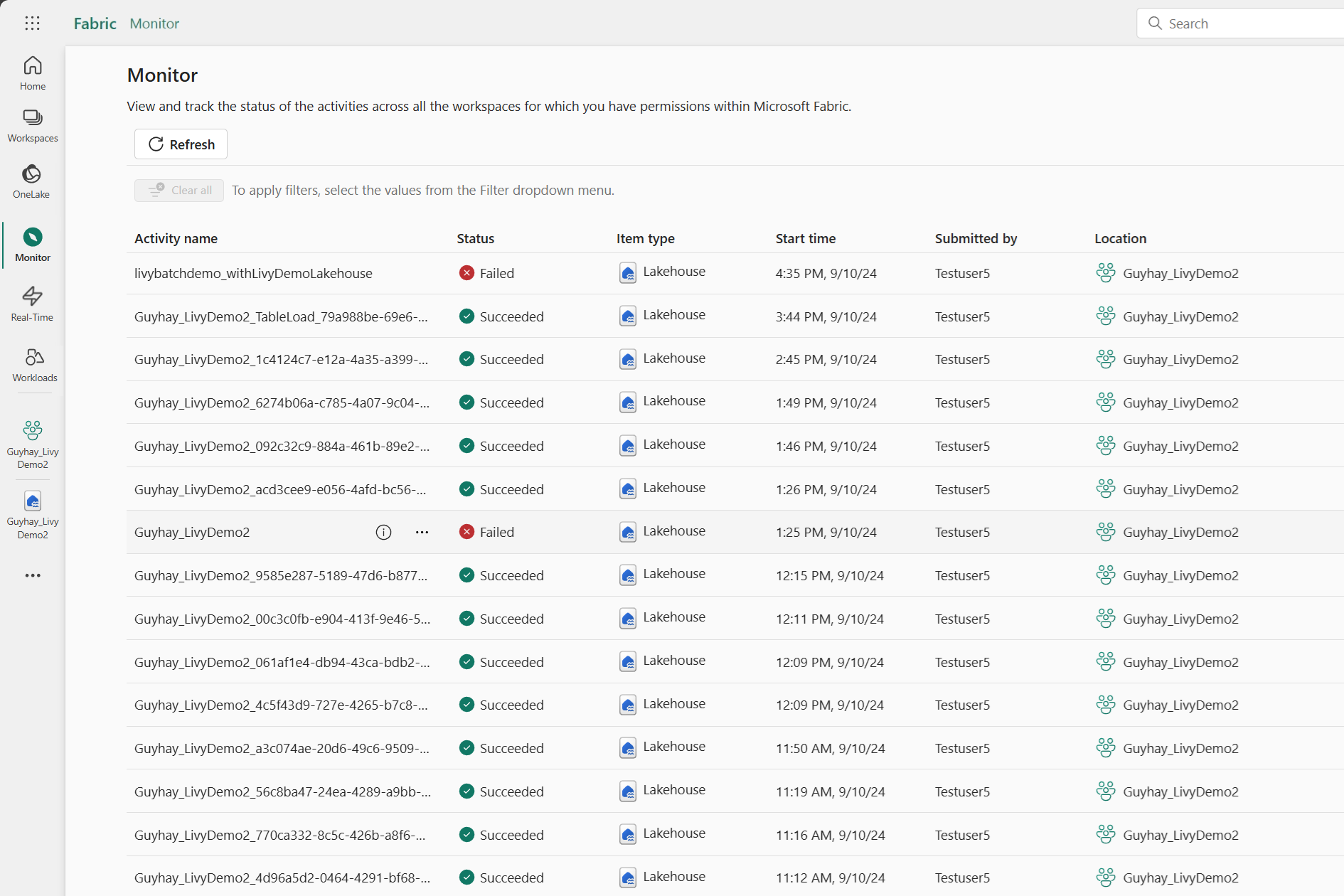
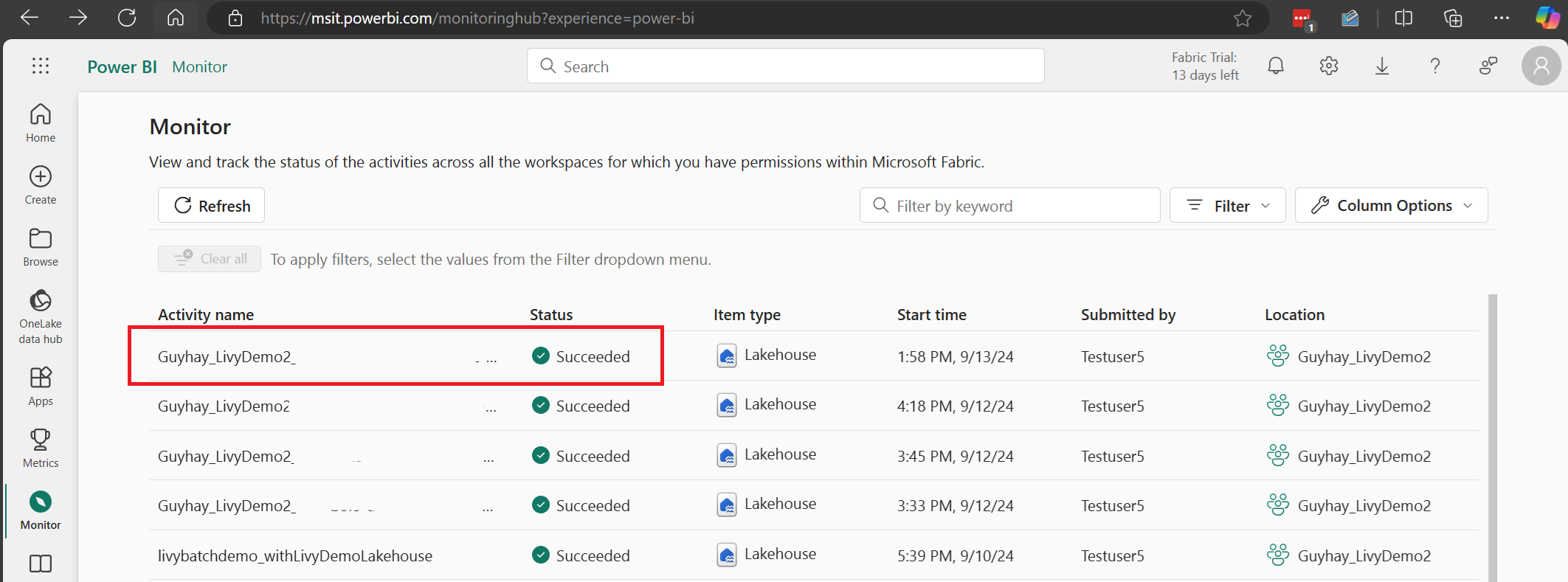
Vyberte a otevřete název poslední aktivity.
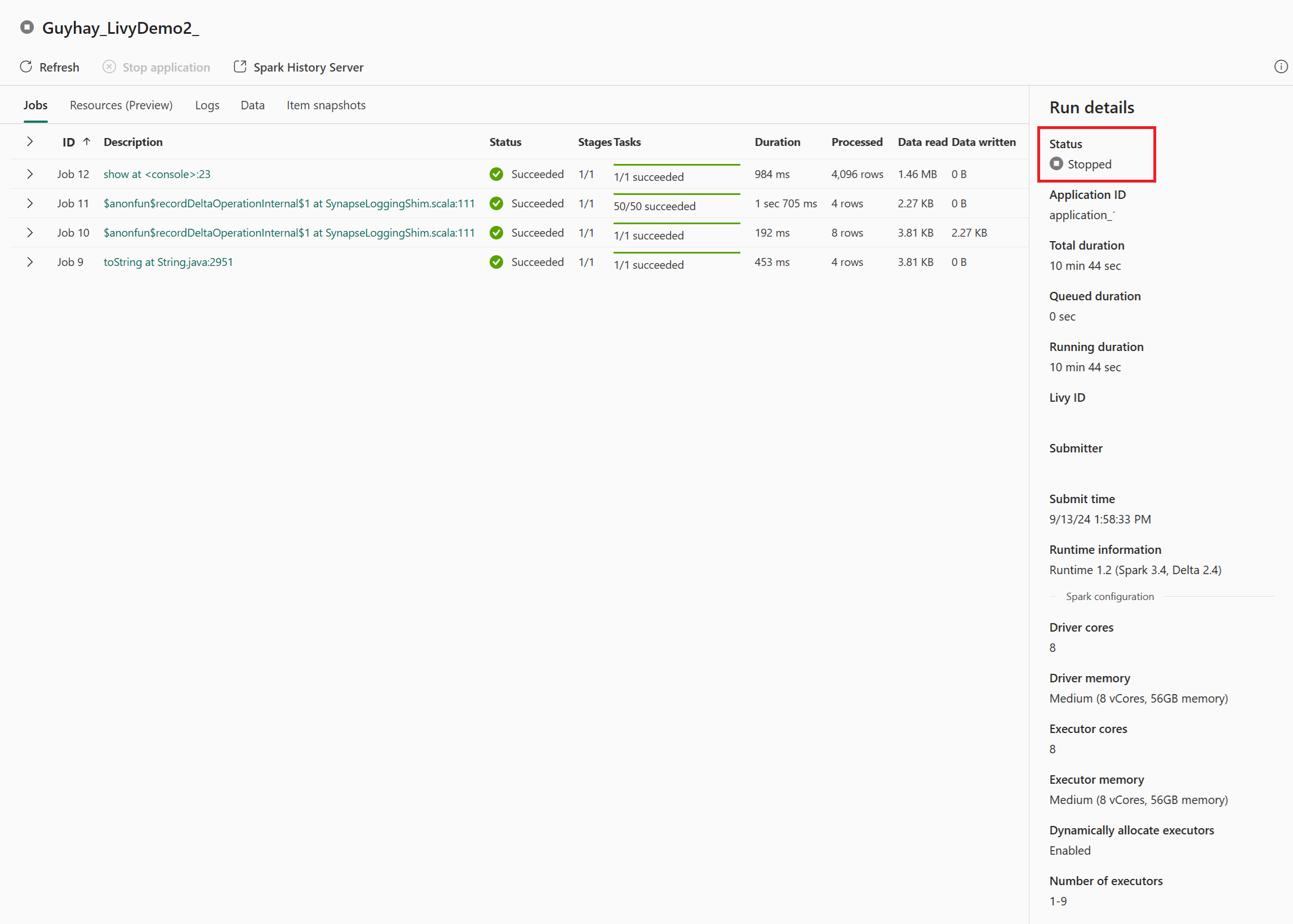
V tomto případě relace rozhraní Livy API uvidíte předchozí dávkové odeslání, podrobnosti o spuštění, verze Sparku a konfiguraci. Všimněte si stavu zastavení v pravém horním rohu.



K rekapitulace celého procesu potřebujete vzdáleného klienta, jako je Visual Studio Code, token aplikace Microsoft Entra, adresa URL koncového bodu rozhraní Livy API, ověřování vůči vaší službě Lakehouse, datová část Sparku ve vašem Lakehouse a nakonec dávková relace rozhraní Livy API.