Kurz: Analýza mínění v recenzích filmů pomocí předem natrénovaného modelu TensorFlow v ML.NET
V tomto kurzu se dozvíte, jak pomocí předem natrénovaného modelu TensorFlow klasifikovat mínění v komentářích k webu. Binární klasifikátor mínění je konzolová aplikace jazyka C# vyvinutá pomocí sady Visual Studio.
Model TensorFlow použitý v tomto kurzu byl vytrénován pomocí recenzí filmů z databáze IMDB. Jakmile dokončíte vývoj aplikace, budete moct zadat text recenze videa a aplikace vám řekne, jestli má recenze pozitivní nebo negativní mínění.
V tomto kurzu se naučíte:
- Načtení předem vytrénovaného modelu TensorFlow
- Transformace textu komentáře webu na funkce vhodné pro model
- Použití modelu k vytvoření předpovědi
Zdrojový kód pro tento kurz najdete v úložišti dotnet/samples .
Požadavky
- Visual Studio 2022 s nainstalovanou úlohou Vývoj desktopových aplikací .NET
Nastavení
Vytvoření aplikace
Vytvořte konzolovou aplikaci jazyka C# s názvem TextClassificationTF. Klikněte na tlačítko Další .
Jako architekturu, kterou chcete použít, zvolte .NET 6. Klikněte na tlačítko Vytvořit.
Vytvořte v projektu adresář s názvem Data , do který uložíte soubory datové sady.
Nainstalujte balíček NuGet Microsoft.ML:
Poznámka
Tato ukázka používá nejnovější stabilní verzi uvedených balíčků NuGet, pokud není uvedeno jinak.
V Průzkumník řešení klikněte pravým tlačítkem na projekt a vyberte Spravovat balíčky NuGet. Jako zdroj balíčku zvolte "nuget.org" a pak vyberte kartu Procházet . Vyhledejte Microsoft.ML, vyberte požadovaný balíček a pak vyberte tlačítko Nainstalovat . V instalaci pokračujte souhlasem s licenčními podmínkami pro balíček, který si zvolíte. Opakujte tento postup pro Microsoft.ML.TensorFlow, Microsoft.ML.SampleUtils a SciSharp.TensorFlow.Redist.
Přidání modelu TensorFlow do projektu
Poznámka
Model pro tento kurz je z úložiště GitHub dotnet/machinelearning-testdata . Model je ve formátu TensorFlow SavedModel.
Stáhněte sentiment_model soubor ZIP a rozbalte ho.
Soubor ZIP obsahuje:
-
saved_model.pb: samotný model TensorFlow. Model přijímá celočíselné pole prvků s pevnou délkou (velikost 600) představující text v revizní řetězci IMDB a vypíše dvě pravděpodobnosti, které se sčítají k 1: pravděpodobnost, že vstupní recenze má kladné mínění, a pravděpodobnost, že kontrola vstupu má negativní mínění. -
imdb_word_index.csv: mapování z jednotlivých slov na celočíselnou hodnotu. Mapování slouží ke generování vstupních funkcí pro model TensorFlow.
-
Zkopírujte obsah nejvnitřnějšího
sentiment_modeladresáře do adresáře projektusentiment_modelTextClassificationTF. Tento adresář obsahuje model a další podpůrné soubory potřebné pro tento kurz, jak je znázorněno na následujícím obrázku: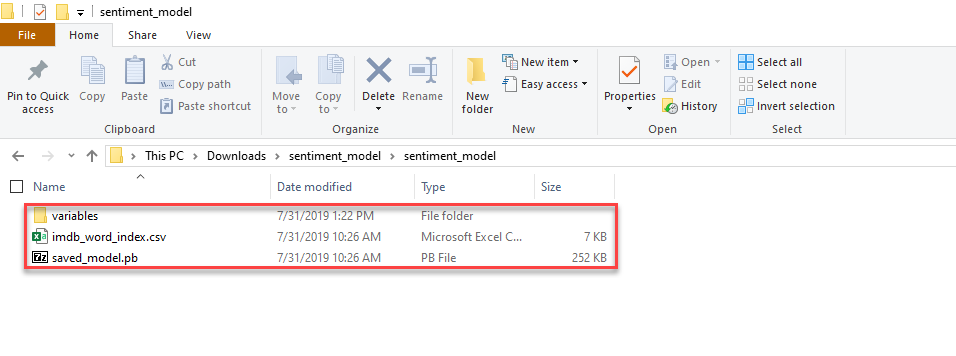
V Průzkumník řešení klikněte pravým tlačítkem na každý ze souborů v adresáři
sentiment_modela podadresáři a vyberte Vlastnosti. V části Upřesnit změňte hodnotu Kopírovat do výstupního adresáře na Kopírovat, pokud je novější.
Přidání příkazů using a globálních proměnných
Na začátek souboru Program.cs přidejte následující další
usingpříkazy:using Microsoft.ML; using Microsoft.ML.Data; using Microsoft.ML.Transforms;Vytvořte globální proměnnou hned za příkazy using, ve které se uloží cesta k uloženému souboru modelu.
string _modelPath = Path.Combine(Environment.CurrentDirectory, "sentiment_model");-
_modelPathje cesta k souboru natrénovaného modelu.
-
Modelování dat
Recenze filmů jsou volný text. Vaše aplikace převede text do vstupního formátu očekávaného modelem v několika samostatných fázích.
První je rozdělit text na samostatná slova a pomocí poskytnutého mapovacího souboru namapovat každé slovo na celočíselné kódování. Výsledkem této transformace je celočíselné pole s proměnnou délkou o délce odpovídající počtu slov ve větě.
| Vlastnost | Hodnota | Typ |
|---|---|---|
| Text recenze | tento film je opravdu dobrý | řetězec |
| VariableLengthFeatures | 14,22,9,66,78,... | int[] |
Pole funkcí s proměnlivou délkou se pak změní na pevnou délku 600. To je délka, kterou model TensorFlow očekává.
| Vlastnost | Hodnota | Typ |
|---|---|---|
| Text recenze | tento film je opravdu dobrý | řetězec |
| VariableLengthFeatures | 14,22,9,66,78,... | int[] |
| Funkce | 14,22,9,66,78,... | int[600] |
V dolní části souboru Program.cs vytvořte třídu pro vstupní data:
/// <summary> /// Class to hold original sentiment data. /// </summary> public class MovieReview { public string? ReviewText { get; set; } }Třída
MovieReviewvstupních dat mástringpro komentáře uživatelů (ReviewText).Vytvořte třídu pro funkce proměnné délky za
MovieReviewtřídou :/// <summary> /// Class to hold the variable length feature vector. Used to define the /// column names used as input to the custom mapping action. /// </summary> public class VariableLength { /// <summary> /// This is a variable length vector designated by VectorType attribute. /// Variable length vectors are produced by applying operations such as 'TokenizeWords' on strings /// resulting in vectors of tokens of variable lengths. /// </summary> [VectorType] public int[]? VariableLengthFeatures { get; set; } }Vlastnost
VariableLengthFeaturesmá VectorType atribut, který jej označí jako vektor. Všechny vektorové prvky musí být stejného typu. V sadách dat s velkým počtem sloupců načítání více sloupců jako jednoho vektoru snižuje počet předplatných dat při použití transformací dat.Tato třída se používá v
ResizeFeaturesakci. Názvy jeho vlastností (v tomto případě pouze jedna) se používají k označení sloupců v objektu DataView, které lze použít jako vstup pro vlastní akci mapování.Vytvořte třídu pro funkce s pevnou délkou za
VariableLengthtřídou:/// <summary> /// Class to hold the fixed length feature vector. Used to define the /// column names used as output from the custom mapping action, /// </summary> public class FixedLength { /// <summary> /// This is a fixed length vector designated by VectorType attribute. /// </summary> [VectorType(Config.FeatureLength)] public int[]? Features { get; set; } }Tato třída se používá v
ResizeFeaturesakci. Názvy jeho vlastností (v tomto případě pouze jedna) se používají k označení sloupců v objektu DataView, které lze použít jako výstup vlastní akce mapování.Všimněte si, že název vlastnosti
Featuresje určen modelem TensorFlow. Název této vlastnosti nelze změnit.Vytvořte třídu pro predikci za
FixedLengthtřídou :/// <summary> /// Class to contain the output values from the transformation. /// </summary> public class MovieReviewSentimentPrediction { [VectorType(2)] public float[]? Prediction { get; set; } }MovieReviewSentimentPredictionje třída předpovědi použitá po trénování modelu.MovieReviewSentimentPredictionmá jednofloatpole (Prediction) aVectorTypeatribut.Vytvořte další třídu pro uložení konfiguračních hodnot, jako je délka vektoru funkce:
static class Config { public const int FeatureLength = 600; }
Vytvoření MLContextu, vyhledávacího slovníku a akce pro změnu velikosti funkcí
Třída MLContext je výchozím bodem pro všechny operace ML.NET. Inicializací mlContext se vytvoří nové prostředí ML.NET, které lze sdílet mezi objekty pracovního postupu vytváření modelu. Koncepčně DBContext je podobný jako v Entity Frameworku.
Console.WriteLine("Hello World!")Nahraďte řádek následujícím kódem pro deklaraci a inicializaci proměnné mlContext:MLContext mlContext = new MLContext();Vytvořte slovník pro kódování slov jako celých čísel pomocí
LoadFromTextFilemetody pro načtení dat mapování ze souboru, jak je znázorněno v následující tabulce:Word Index Děti 362 chci 181 Špatně 355 effects 302 Pocit 547 Přidejte níže uvedený kód a vytvořte vyhledávací mapu:
var lookupMap = mlContext.Data.LoadFromTextFile(Path.Combine(_modelPath, "imdb_word_index.csv"), columns: new[] { new TextLoader.Column("Words", DataKind.String, 0), new TextLoader.Column("Ids", DataKind.Int32, 1), }, separatorChar: ',' );Přidejte pro
Actionzměnu velikosti pole slov integer proměnné délky na celočíselné pole s pevnou velikostí s dalšími řádky kódu:Action<VariableLength, FixedLength> ResizeFeaturesAction = (s, f) => { var features = s.VariableLengthFeatures; Array.Resize(ref features, Config.FeatureLength); f.Features = features; };
Načtení předem natrénovaného modelu TensorFlow
Přidejte kód pro načtení modelu TensorFlow:
TensorFlowModel tensorFlowModel = mlContext.Model.LoadTensorFlowModel(_modelPath);Po načtení modelu můžete extrahovat jeho vstupní a výstupní schéma. Schémata se zobrazují pouze pro zájem a učení. Tento kód nepotřebujete, aby konečná aplikace fungovala:
DataViewSchema schema = tensorFlowModel.GetModelSchema(); Console.WriteLine(" =============== TensorFlow Model Schema =============== "); var featuresType = (VectorDataViewType)schema["Features"].Type; Console.WriteLine($"Name: Features, Type: {featuresType.ItemType.RawType}, Size: ({featuresType.Dimensions[0]})"); var predictionType = (VectorDataViewType)schema["Prediction/Softmax"].Type; Console.WriteLine($"Name: Prediction/Softmax, Type: {predictionType.ItemType.RawType}, Size: ({predictionType.Dimensions[0]})");Vstupní schéma je pole s pevnou délkou celočíselných zakódovaných slov. Výstupní schéma je plovoucí pole pravděpodobností označující, jestli je mínění recenze záporné, nebo kladné . Tyto hodnoty se sčítají na 1, protože pravděpodobnost, že jsou kladné, je doplňkem pravděpodobnosti negativního mínění.
Vytvoření kanálu ML.NET
Vytvořte kanál a rozdělte vstupní text na slova pomocí transformace TokenizeIntoWords , která rozdělí text na slova jako další řádek kódu:
IEstimator<ITransformer> pipeline = // Split the text into individual words mlContext.Transforms.Text.TokenizeIntoWords("TokenizedWords", "ReviewText")Transformace TokenizeIntoWords používá mezery k parsování textu nebo řetězce na slova. Vytvoří nový sloupec a rozdělí každý vstupní řetězec na vektor podřetězc na základě uživatelem definovaného oddělovače.
Namapujte slova na jejich celočíselné kódování pomocí vyhledávací tabulky, kterou jste deklarovali výše:
// Map each word to an integer value. The array of integer makes up the input features. .Append(mlContext.Transforms.Conversion.MapValue("VariableLengthFeatures", lookupMap, lookupMap.Schema["Words"], lookupMap.Schema["Ids"], "TokenizedWords"))Změňte celočíselné kódování proměnné délky na kódování s pevnou délkou, kterou vyžaduje model:
// Resize variable length vector to fixed length vector. .Append(mlContext.Transforms.CustomMapping(ResizeFeaturesAction, "Resize"))Klasifikujte vstup pomocí načteného modelu TensorFlow:
// Passes the data to TensorFlow for scoring .Append(tensorFlowModel.ScoreTensorFlowModel("Prediction/Softmax", "Features"))Výstup modelu TensorFlow se nazývá
Prediction/Softmax. Všimněte si, že názevPrediction/Softmaxje určen modelem TensorFlow. Tento název nelze změnit.Vytvořte nový sloupec pro výstupní predikci:
// Retrieves the 'Prediction' from TensorFlow and copies to a column .Append(mlContext.Transforms.CopyColumns("Prediction", "Prediction/Softmax"));Musíte zkopírovat
Prediction/Softmaxsloupec do sloupce s názvem, který lze použít jako vlastnost ve třídě jazyka C#:Prediction. Znak/není povolen v názvu vlastnosti jazyka C#.
Vytvoření modelu ML.NET z kanálu
Přidejte kód pro vytvoření modelu z kanálu:
// Create an executable model from the estimator pipeline IDataView dataView = mlContext.Data.LoadFromEnumerable(new List<MovieReview>()); ITransformer model = pipeline.Fit(dataView);Model ML.NET se vytvoří z řetězu odhadců v kanálu voláním
Fitmetody . V tomto případě nepřiléháme k vytvoření modelu žádná data, protože model TensorFlow už byl dříve natrénován. Pro splnění požadavkůFitmetody poskytujeme prázdný objekt zobrazení dat.
Použití modelu k vytvoření předpovědi
Přidejte metodu
PredictSentimentnadMovieReviewtřídu:void PredictSentiment(MLContext mlContext, ITransformer model) { }Přidejte následující kód, který vytvoří
PredictionEnginejako první řádek vPredictSentiment()metodě:var engine = mlContext.Model.CreatePredictionEngine<MovieReview, MovieReviewSentimentPrediction>(model);PredictionEngine je rozhraní API pro pohodlí, které umožňuje provádět předpovědi na jedné instanci dat.
PredictionEnginenení bezpečný pro přístup z více vláken. Je přijatelné používat v jednovláknovém nebo prototypovém prostředí. Pokud chcete zvýšit výkon a zabezpečení vláken v produkčních prostředích, použijtePredictionEnginePoolslužbu, která vytvoříPredictionEngineObjectPoolobjekty pro použití v celé aplikaci. Projděte si tohoto průvodce používánímPredictionEnginePoolve webovém rozhraní API ASP.NET Core.Poznámka
PredictionEnginePoolrozšíření služby je aktuálně ve verzi Preview.Přidejte komentář k otestování předpovědi vytrénovaného modelu v
Predict()metodě vytvořením instanceMovieReview:var review = new MovieReview() { ReviewText = "this film is really good" };Předejte data testovacího komentáře do
Prediction Enginemetody přidáním dalších řádků kódu:PredictSentiment()var sentimentPrediction = engine.Predict(review);Funkce Predict() vytvoří předpověď pro jeden řádek dat:
Vlastnost Hodnota Typ Předpověď [0.5459937, 0.454006255] float[] Zobrazte predikci mínění pomocí následujícího kódu:
Console.WriteLine($"Number of classes: {sentimentPrediction.Prediction?.Length}"); Console.WriteLine($"Is sentiment/review positive? {(sentimentPrediction.Prediction?[1] > 0.5 ? "Yes." : "No.")}");Po volání
Fit()metody přidejte voláníPredictSentiment:PredictSentiment(mlContext, model);
Výsledky
Sestavte a spusťte aplikaci.
Výsledky by se měly podobat následujícímu. Během zpracování se zobrazují zprávy. Může se zobrazit upozornění nebo zpracování zpráv. Tyto zprávy byly pro přehlednost odebrány z následujících výsledků.
Number of classes: 2
Is sentiment/review positive ? Yes
Gratulujeme! Teď jste úspěšně vytvořili model strojového učení pro klasifikaci a predikci mínění zpráv opětovným použitím předem natrénovaného TensorFlow modelu v ML.NET.
Zdrojový kód pro tento kurz najdete v úložišti dotnet/samples .
V tomto kurzu jste se naučili:
- Načtení předem natrénovaného modelu TensorFlow
- Transformace textu komentáře webu na funkce vhodné pro model
- Použití modelu k vytvoření předpovědi