Co je Tvůrce modelů a jak funguje?
ML.NET Model Builder je intuitivní grafické rozšíření sady Visual Studio pro sestavování, trénování a nasazování vlastních modelů strojového učení. Využívá automatizované strojové učení (AutoML) k prozkoumání různých algoritmů a nastavení strojového učení, které vám pomůže najít ten, který nejlépe vyhovuje vašemu scénáři.
K používání Tvůrce modelů nepotřebujete odborné znalosti strojového učení. Potřebujete jen nějaká data a problém, který je potřeba vyřešit. Tvůrce modelů vygeneruje kód pro přidání modelu do aplikace .NET.

Vytvoření projektu Tvůrce modelů
Když poprvé spustíte Tvůrce modelů, požádá vás o pojmenování projektu a pak v projektu vytvoří mbconfig konfigurační soubor. Soubor mbconfig sleduje všechno, co v Tvůrci modelů děláte, abyste mohli znovu otevřít relaci.
Po trénování se vygenerují tři soubory v souboru *.mbconfig:
- Model.consumption.cs: Tento soubor obsahuje schémata
ModelInputPredictaModelOutputtaké funkci vygenerovanou pro využívání modelu. - Model.training.cs: Tento soubor obsahuje trénovací kanál (transformace dat, algoritmus, hyperparametry algoritmů) zvolený Tvůrcem modelů k trénování modelu. Tento kanál můžete použít k opětovnému trénování modelu.
- Model.zip: Jedná se o serializovaný soubor ZIP, který představuje trénovaný ML.NET model.
Při vytváření mbconfig souboru se zobrazí výzva k zadání názvu. Tento název se použije u souborů spotřeby, trénování a modelu. V tomto případě se používá název Model.
Scénář
Do Tvůrce modelů můžete přinést mnoho různých scénářů a vygenerovat model strojového učení pro vaši aplikaci.
Scénář je popis typu předpovědi, kterou chcete použít. Příklad:
- Predikce objemu prodeje budoucích produktů na základě historických prodejních dat
- Klasifikovat mínění jako pozitivní nebo negativní na základě hodnocení zákazníků.
- Zjistěte, jestli je bankovní transakce podvodná.
- Nasměrujte problémy se zpětnou vazbou zákazníků na správný tým ve vaší společnosti.
Každý scénář se mapuje na jinou úlohu strojového učení, která zahrnuje:
| Úloha | Scénář |
|---|---|
| Binární klasifikace | Klasifikace dat |
| Klasifikace s více třídami | Klasifikace dat |
| Klasifikace obrázku | Klasifikace obrázku |
| Klasifikace textu | Klasifikace textu |
| Regrese | Predikce hodnot |
| Doporučení | Doporučení |
| Prognostika | Prognostika |
Například scénář klasifikace mínění jako pozitivní nebo negativní by spadal pod úlohu binární klasifikace.
Další informace o různých úlohách ML podporovaných ML.NET naleznete v tématu Úlohy strojového učení v ML.NET.
Který scénář strojového učení je pro mě správný?
V Tvůrci modelů je potřeba vybrat scénář. Typ scénáře závisí na tom, jaký typ předpovědi se pokoušíte provést.
Tabelární
Klasifikace dat
Klasifikace se používá ke kategorizaci dat do kategorií.
Ukázkový vstup
Ukázkový výstup
| SepalLength | SepalWidth | Délka okvětních | Šířka okvětního lístku | Druh |
|---|---|---|---|---|
| 5,1 | 3.5 | 1.4 | 0,2 | setosa |
| Predikované druhy |
|---|
| setosa |
Predikce hodnot
Predikce hodnot, která spadá pod regresní úlohu, se používá k predikci čísel.
Ukázkový vstup
Ukázkový výstup
| vendor_id | rate_code | passenger_count | trip_time_in_secs | trip_distance | payment_type | fare_amount |
|---|---|---|---|---|---|---|
| CMT | 1 | 1 | 1271 | 3.8 | CRD | 17.5 |
| Predikované jízdné |
|---|
| 4.5 |
Doporučení
Scénář doporučení předpovídá seznam navrhovaných položek pro konkrétního uživatele na základě toho, jak se jim líbí a nelíbí se ostatním uživatelům.
Scénář doporučení můžete použít, když máte sadu uživatelů a sadu "produktů", jako jsou například položky k nákupu, filmů, knih nebo televizních pořadů, společně se sadou "hodnocení" těchto produktů uživatelů.
Ukázkový vstup
Ukázkový výstup
| ID uživatele | ID produktu | Rating |
|---|---|---|
| 1 | 2 | 4.2 |
| Predikované hodnocení |
|---|
| 4.5 |
Prognostika
Scénář prognózování používá historická data s časovou řadou nebo sezónní komponentou.
Scénář prognózování můžete použít k prognózování poptávky nebo prodeje produktu.
Ukázkový vstup
Ukázkový výstup
| Datum | SaleQty |
|---|---|
| 1/1/1970 | 1000 |
| 3denní prognóza |
|---|
| [1000,1001,1002] |
Počítačové zpracování obrazu
Klasifikace obrázku
Klasifikace obrázků se používá k identifikaci obrázků různých kategorií. Například různé typy terénu nebo zvířat nebo výrobní vady.
Scénář klasifikace obrázků můžete použít, pokud máte sadu obrázků a chcete je klasifikovat do různých kategorií.
Ukázkový vstup
Ukázkový výstup

| Predikovaný popisek |
|---|
| Pes |
Detekce objektů
Rozpoznávání objektů se používá k vyhledání a kategorizaci entit v rámci obrázků. Například vyhledání a identifikace aut a lidí na obrázku.
Rozpoznávání objektů můžete použít v případech, kdy obrázky obsahují více objektů různých typů.
Ukázkový vstup
Ukázkový výstup

Zpracování přirozeného jazyka
Klasifikace textu
Klasifikace textu kategorizuje nezpracovaný textový vstup.
Scénář klasifikace textu můžete použít, pokud máte sadu dokumentů nebo komentářů a chcete je klasifikovat do různých kategorií.
Příklad vstupu
Příklad výstupu
| Přehled |
|---|
| Opravdu se mi líbí tento steak! |
| Smýšlení |
|---|
| Kladné |
Prostředí
Model strojového učení můžete trénovat místně na počítači nebo v cloudu v Azure v závislosti na scénáři.
Při místním trénování pracujete v rámci omezení prostředků počítače (procesor, paměť a disk). Při trénování v cloudu můžete vertikálně navýšit kapacitu prostředků tak, aby splňovaly požadavky vašeho scénáře, zejména pro velké datové sady.
| Scénář | Místní procesor | Místní GPU | Azure |
|---|---|---|---|
| Klasifikace dat | ✔️ | ❌ | ❌ |
| Predikce hodnot | ✔️ | ❌ | ❌ |
| Doporučení | ✔️ | ❌ | ❌ |
| Prognostika | ✔️ | ❌ | ❌ |
| Klasifikace obrázku | ✔️ | ✔️ | ✔️ |
| Detekce objektů | ❌ | ❌ | ✔️ |
| Klasifikace textu | ✔️ | ✔️ | ❌ |
Data
Jakmile zvolíte svůj scénář, Tvůrce modelů vás požádá o zadání datové sady. Data se používají k trénování, vyhodnocování a výběru nejvhodnějšího modelu pro váš scénář.
Tvůrce modelů podporuje datové sady ve formátech .tsv, .csv, .txt a databází SQL. Pokud máte soubor .txt, měly by být sloupce odděleny pomocí ,, ;nebo \t.
Pokud se datová sada skládá z obrázků, podporované typy souborů jsou .jpg a .png.
Další informace najdete v tématu Načtení trénovacích dat do Model Builderu.
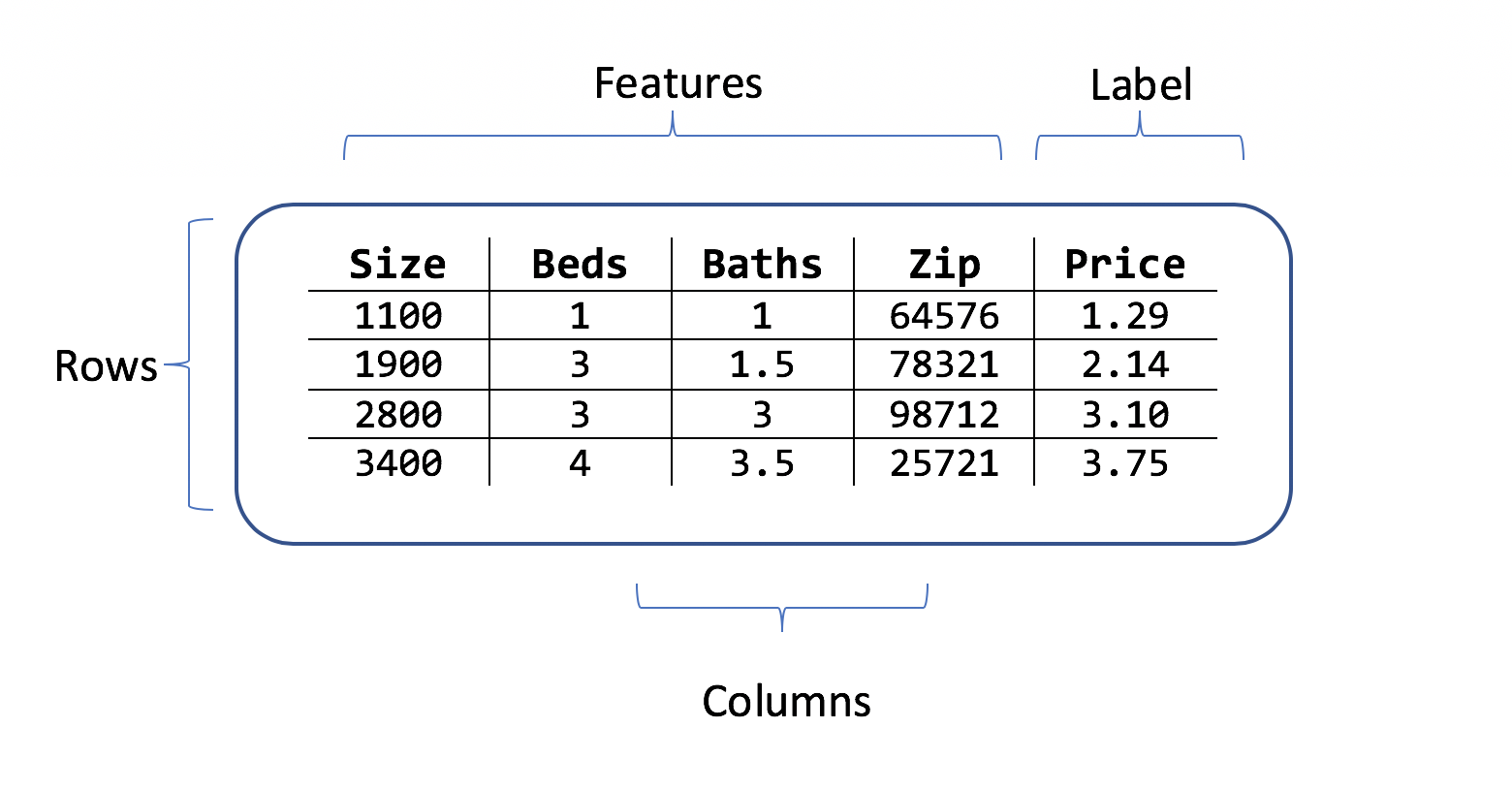
Volba výstupu pro predikci (popisek)
Datová sada je tabulka řádků trénovacích příkladů a sloupců atributů. Každý řádek obsahuje:
- popisek (atribut, který chcete předpovědět)
- funkce (atributy, které se používají jako vstupy k predikci popisku)
V případě scénáře predikce ceny domu mohou být tyto funkce:
- Čtvercové záběry domu.
- Počet ložnic a koupelen.
- PSČ.
Popisek je historická cena domu pro tento řádek čtvercových záběrů, ložnice a koupelnové hodnoty a PSČ.
Ukázkové datové sady
Pokud ještě nemáte vlastní data, vyzkoušejte některou z těchto datových sad:
| Scénář | Příklad | Data | Popisek | Funkce |
|---|---|---|---|---|
| Klasifikace | Predikce prodejních anomálií | údaje o prodeji produktů | Prodej produktu | Month |
| Predikce mínění komentářů na webu | data komentářů na webu | Popisek (1, když negativní mínění, 0, když je kladné) | Komentář, Rok | |
| Predikce podvodných transakcí platební karty | Údaje o platební kartě | Třída (1 v případě podvodu, 0 jinak) | Amount, V1-V28 (anonymizované funkce) | |
| Predikce typu problému v úložišti GitHub | Data problému GitHubu | Plocha | Název, popis | |
| Predikce hodnot | Předpověď ceny jízdy taxíkem | údaje o jízdě taxíkem | Jízdné | Doba jízdy, vzdálenost |
| Klasifikace obrázku | Predikce kategorie květiny | obrázky květin | Typ květiny: daisy, pampeliška, růže, slunečnice, tulipány | Samotná data obrázku |
| Doporučení | Predikce filmů, které bude někdo chtít | hodnocení filmů | Uživatelé, Filmy | Hodnocení |
Trénink
Jakmile vyberete svůj scénář, prostředí, data a popisek, vytrénuje Model Builder model.
Co je trénování?
Trénování je automatický proces, pomocí kterého Tvůrce modelů naučí váš model, jak odpovědět na otázky pro váš scénář. Po vytrénování může váš model vytvářet předpovědi se vstupními daty, která předtím neviděla. Pokud například předpovídáte ceny domů a nový dům přichází na trh, můžete předpovědět jeho prodejní cenu.
Vzhledem k tomu, že Tvůrce modelů používá automatizované strojové učení (AutoML), nevyžaduje během trénování žádný vstup ani ladění.
Jak dlouho mám trénovat?
Tvůrce modelů používá AutoML k prozkoumání více modelů, abyste našli model s nejlepším výkonem.
Delší doba trénování umožňuje AutoML zkoumat více modelů s širší škálou nastavení.
Následující tabulka shrnuje průměrnou dobu potřebnou k získání dobrého výkonu pro sadu ukázkových datových sad na místním počítači.
| Velikost datové sady | Average time to train |
|---|---|
| 0–10 MB | 10 s |
| 10–100 MB | 10 minut |
| 100 AŽ 500 MB | 30 min. |
| 500 – 1 GB | 60 min. |
| 1 GB+ | 3 a více hodin |
Tato čísla představují pouze vodítko. Přesná délka trénování závisí na:
- Počet funkcí (sloupců), které se používají jako vstup do modelu.
- Typ sloupců.
- Úloha ML.
- Výkon procesoru, disku a paměti počítače používaného k trénování.
Obecně se doporučuje, abyste jako datové sady s méně než 100 řádky používali více než 100 řádků, které nemusí vést k žádným výsledkům.
Evaluate
Vyhodnocení je proces měření toho, jak je model dobrý. Tvůrce modelů používá trénovaný model k vytváření předpovědí s novými testovacími daty a následně měří, jak jsou předpovědi dobré.
Tvůrce modelů rozdělí trénovací data na trénovací sadu a testovací sadu. Trénovací data (80 %) se používají k trénování modelu a testovací data (20 %) se uchovávají zpět k vyhodnocení modelu.
Návody porozumět výkonu modelu?
Scénář se mapuje na úlohu strojového učení. Každá úloha ML má vlastní sadu metrik vyhodnocení.
Predikce hodnot
Výchozí metrika pro problémy s predikcí hodnot je RSquared, hodnota rozsahů RSquared mezi 0 a 1. 1 je nejlepší možná hodnota nebo jinými slovy, čím blíže je hodnota RSquared na 1, tím lépe model funguje.
Další metriky hlášené jako absolutní ztráta, kvadratová ztráta a ztráta RMS jsou další metriky, které se dají použít k pochopení výkonu modelu a jeho porovnání s jinými modely predikcí hodnot.
Klasifikace (2 kategorie)
Výchozí metrika pro problémy klasifikace je přesnost. Přesnost definuje poměr správných predikcí, které model provádí přes testovací datovou sadu. Čím blíž k 100 % nebo 1,0 je lepší.
Jiné metriky hlášené jako AUC (oblast pod křivkou), které měří skutečnou kladnou míru vs. falešně pozitivní rychlost by měla být vyšší než 0,50, aby modely byly přijatelné.
Další metriky, jako je skóre F1, lze použít k řízení rovnováhy mezi přesností a úplností.
Klasifikace (3+ kategorie)
Výchozí metrika pro klasifikaci s více třídami je mikropřesnost. Čím blíž je mikropřesnost 100 % nebo 1,0, tím lépe je.
Další důležitou metrikou pro klasifikaci více tříd je přesnost maker, podobně jako mikropřesnost, která je blíže 1,0, tím lepší je. Dobrým způsobem, jak se zamyslet nad těmito dvěma typy přesnosti, je:
- Mikropřesnost: Jak často se příchozí lístek klasifikuje správnému týmu?
- Přesnost maker: Jak často je pro svůj tým správný příchozí lístek?
Další informace o metrikách vyhodnocení
Další informace najdete v tématu Metriky vyhodnocení modelu.
Zlepšení
Pokud skóre výkonu modelu není tak dobré, jak chcete, můžete:
Trénujte delší dobu. S větším časem experimentuje modul automatizovaného strojového učení s více algoritmy a nastavením.
Přidejte další data. Někdy množství dat nestačí k trénování vysoce kvalitního modelu strojového učení. To platí zejména u datových sad, které mají malý počet příkladů.
Vyrovnejte svá data. U klasifikačních úkolů se ujistěte, že je trénovací sada vyvážená mezi kategoriemi. Pokud máte například čtyři třídy pro 100 trénovacích příkladů a dvě první třídy (značka1 a značka2) se používají pro 90 záznamů, ale ostatní dvě třídy (značka3 a značka4) se používají jenom na zbývajících 10 záznamech, nedostatek vyvážených dat může způsobit, že se váš model snaží správně předpovědět značku 3 nebo značku4.
Consume
Po fázi vyhodnocení vypíše Tvůrce modelů soubor modelu a kód, který můžete použít k přidání modelu do aplikace. ML.NET modely se ukládají jako soubor ZIP. Kód pro načtení a použití modelu se do vašeho řešení přidá jako nový projekt. Tvůrce modelů také přidá ukázkovou konzolovou aplikaci, kterou můžete spustit a zobrazit model v akci.
Tvůrce modelů navíc nabízí možnost vytvářet projekty, které model využívají. Tvůrce modelů v současné době vytvoří následující projekty:
- Konzolová aplikace: Vytvoří konzolovou aplikaci .NET, která bude vytvářet předpovědi z modelu.
- Webové rozhraní API: Vytvoří webové rozhraní API ASP.NET Core, které umožňuje využívat model přes internet.
Co dále?
Nainstalujte rozšíření Sady Visual Studio v Tvůrci modelů.
Vyzkoušejte predikci ceny nebo jakýkoli regresní scénář.