Svrchovanost dat v jednotlivých mikroslužbách
Tip
Tento obsah je výňatek z eBooku, architektury mikroslužeb .NET pro kontejnerizované aplikace .NET, které jsou k dispozici na .NET Docs nebo jako zdarma ke stažení PDF, které lze číst offline.

Důležité pravidlo pro architekturu mikroslužeb je, že každá mikroslužba musí vlastnit svá doménová data a logiku. Stejně jako úplná aplikace vlastní logiku a data, takže každá mikroslužba vlastní svou logiku a data v rámci autonomního životního cyklu s nezávislým nasazením na mikroslužbu.
To znamená, že koncepční model domény se bude lišit mezi subsystémy nebo mikroslužbami. Zvažte podnikové aplikace, kde aplikace pro správu vztahů se zákazníky (CRM), transakční subsystémy nákupu a subsystémy podpory zákazníků každou volání jedinečných atributů a dat entit zákazníka a kde každý využívá jiný ohraničený kontext (BC).
Tento princip je podobný v návrhu řízeném doménou (DDD), kde každý ohraničený kontext nebo autonomní subsystém nebo služba musí vlastnit svůj doménový model (data plus logika a chování). Každý kontext ohraničený DDD koreluje s jednou obchodní mikroslužbou (jednou nebo několika službami). Tento bod o vzoru Ohraničený kontext se rozbalí v další části.
Na druhou stranu tradiční (monolitická data) používaný v mnoha aplikacích je mít jednu centralizovanou databázi nebo jen několik databází. Často se jedná o normalizovanou databázi SQL, která se používá pro celou aplikaci a všechny její interní subsystémy, jak je znázorněno na obrázku 4–7.
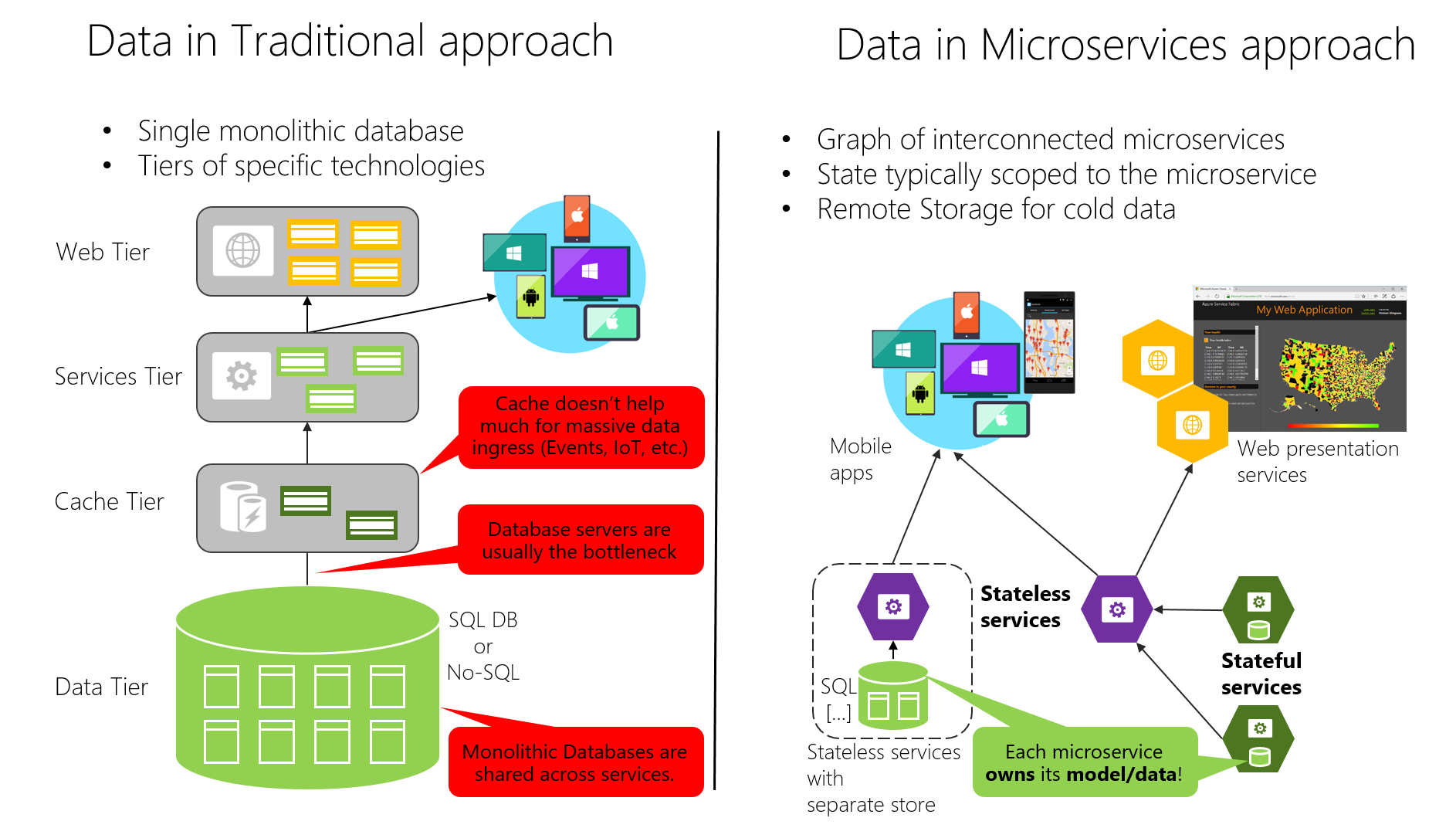
Obrázek 4–7 Porovnání suverenity dat: monolitická databáze a mikroslužby
V tradičním přístupu existuje jedna databáze sdílená napříč všemi službami, obvykle v vrstvené architektuře. V přístupu k mikroslužbám vlastní každá mikroslužba svůj model/data. Centralizovaný přístup k databázi zpočátku vypadá jednodušší a zdá se, že umožňuje opakovaně používat entity v různých subsystémech, aby bylo všechno konzistentní. Realitou je ale to, že máte obrovské tabulky, které obsluhují mnoho různých subsystémů a které zahrnují atributy a sloupce, které nejsou ve většině případů potřeba. Je to jako při pokusu o použití stejné fyzické mapy pro pěší turistiku, jízdu na denní jízdu a zeměpisnou oblast výuky.
Monolitická aplikace s většinou jedinou relační databází má dvě důležité výhody: transakce ACID a jazyk SQL, které pracují ve všech tabulkách a datech souvisejících s vaší aplikací. Tento přístup poskytuje způsob, jak snadno napsat dotaz, který kombinuje data z více tabulek.
Přístup k datům se ale při přechodu na architekturu mikroslužeb stává mnohem složitější. I když používáte transakce ACID v rámci mikroslužby nebo vázaného kontextu, je důležité vzít v úvahu, že data vlastněná každou mikroslužbou jsou pro tuto mikroslužbu soukromá a měla by být přístupná buď synchronně prostřednictvím jejích koncových bodů rozhraní API (REST, gRPC, SOAP atd.), nebo asynchronně prostřednictvím zasílání zpráv (AMQP nebo podobných).
Zapouzdřením dat zajistíte, že mikroslužby jsou volně svázané a mohou se vyvíjet nezávisle na sobě. Pokud by ke stejným datům přistupovalo více služeb, aktualizace schémat by vyžadovaly koordinované aktualizace všech služeb. To by přerušilo autonomii životního cyklu mikroslužeb. Distribuované datové struktury ale znamenají, že nemůžete vytvořit jedinou transakci ACID napříč mikroslužbami. To zase znamená, že pokud obchodní proces zahrnuje více mikroslužeb, musíte použít konečnou konzistenci. Implementace je mnohem obtížnější než jednoduché spojení SQL, protože nemůžete vytvářet omezení integrity nebo používat distribuované transakce mezi samostatnými databázemi, jak to vysvětlíme později. Podobně mnoho dalších funkcí relačních databází není dostupné napříč několika mikroslužbami.
Další možností je, že různé mikroslužby často používají různé druhy databází. Moderní aplikace ukládají a zpracovávají různé druhy dat a relační databáze nejsou vždy nejlepší volbou. V některých případech použití může mít databáze NoSQL, jako je Azure CosmosDB nebo MongoDB, pohodlnější datový model a nabízí lepší výkon a škálovatelnost než databáze SQL, jako je SQL Server nebo Azure SQL Database. V jiných případech je relační databáze stále nejlepším přístupem. Proto aplikace založené na mikroslužbách často používají kombinaci databází SQL a NoSQL, což se někdy označuje jako přístup polyglotní trvalosti .
Dělená a trvalá architektura polyglotu pro úložiště dat má mnoho výhod. Patří mezi ně volně spojené služby a lepší výkon, škálovatelnost, náklady a spravovatelnost. Může však představovat některé problémy správy distribuovaných dat, jak je vysvětleno v části "Identifikace hranic modelu domény" dále v této kapitole.
Vztah mezi mikroslužbami a vzorem ohraničeného kontextu
Koncept mikroslužby vychází ze vzoru vázaných kontextů (BC) v návrhu řízeném doménou (DDD). DDD se zabývá velkými modely jejich rozdělením na několik řadičů základní desky a explicitním rozdělením jejich hranic. Každá BC musí mít svůj vlastní model a databázi; Podobně každá mikroslužba vlastní svá související data. Kromě toho každá BC má obvykle svůj vlastní všudypřítomný jazyk , který pomáhá komunikaci mezi vývojáři softwaru a odborníky na doménu.
Tyto termíny (hlavně entity domény) v všudypřítomných jazycích můžou mít různé názvy v různých ohraničených kontextech, i když různé entity domény sdílejí stejnou identitu (to znamená jedinečné ID, které se používá ke čtení entity z úložiště). Například v vázaném kontextu profilu uživatele může entita domény uživatele sdílet identitu s entitou domény kupujícího v pořadí Ohraničený kontext.
Mikroslužba je tedy jako ohraničený kontext, ale také určuje, že se jedná o distribuovanou službu. Je vytvořený jako samostatný proces pro každý ohraničený kontext a musí používat dříve uvedené distribuované protokoly, jako jsou HTTP/HTTPS, WebSockets nebo AMQP. Model Ohraničený kontext ale neurčuje, jestli je ohraničený kontext distribuovanou službou nebo jestli se jedná o logickou hranici (například obecný subsystém) v rámci monolitické aplikace nasazení.
Je důležité zdůraznit, že definování služby pro každý ohraničený kontext je dobrým místem, kde začít. Nemusíte ale omezovat návrh na něj. Někdy musíte navrhnout ohraničený kontext nebo obchodní mikroslužbu složenou z několika fyzických služeb. V konečném důsledku ale oba vzory -Bounded Context i mikroslužby- úzce souvisejí.
DDD přináší výhody mikroslužeb získáním skutečných hranic ve formě distribuovaných mikroslužeb. Ale nápady jako nesdílejí model mezi mikroslužbami, jsou to, co chcete také v ohraničeném kontextu.
Další materiály
Chris Richardson. Model: Databáze na službu
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Návrh řízený strategickou doménou s mapováním kontextu
https://www.infoq.com/articles/ddd-contextmapping