Používání bloků
K maximalizaci zrychlení aplikace můžete použít provázání. Svázání rozdělí vlákna na stejné obdélníkové podmnožiny nebo dlaždice. Pokud použijete odpovídající velikost dlaždice a algoritmus dlaždic, můžete z kódu C++ AMP získat ještě větší akceleraci. Základní součásti provazování jsou:
tile_staticproměnné. Hlavní výhodou svázání je získání výkonu ztile_staticpřístupu. Přístup k datům vtile_staticpaměti může být výrazně rychlejší než přístup k datům v globálním prostoru (arrayneboarray_viewobjektech). Pro každou dlaždici se vytvoří instancetile_staticproměnné a všechna vlákna na dlaždici mají přístup k proměnné. V typickém dlaždicovém algoritmu se data zkopírují dotile_staticpaměti jednou z globální paměti a poté se k paměti přistupujetile_staticmnohokrát.tile_barrier::wait – metoda. Volání, které
tile_barrier::waitpozastaví provádění aktuálního vlákna, dokud se všechna vlákna ve stejné dlaždici nedostanou ktile_barrier::waitvolání . Nemůžete zaručit pořadí, ve které budou vlákna spuštěna, pouze že žádná vlákna na dlaždici se neprovedou po volánítile_barrier::wait, dokud všechna vlákna nedosáhly volání. To znamená, že pomocítile_barrier::waittéto metody můžete provádět úlohy na dlaždici po dlaždicích, nikoli na bázi vláken po vláknech. Typický algoritmus provazování má kód pro inicializacitile_staticpaměti pro celou dlaždici následovaný volánímtile_barrier::wait.tile_barrier::waitNásledující kód obsahuje výpočty, které vyžadují přístup ke všem hodnotámtile_static.Místní a globální indexování Máte přístup k indexu vlákna vzhledem k celému
array_viewobjektu neboarrayobjektu a indexu vzhledem k dlaždici. Použití místního indexu může usnadnit čtení a ladění kódu. K přístupu ktile_staticproměnným a globálnímu indexování pro přístup karrayproměnným aarray_viewproměnným se obvykle používá místní indexování.tiled_extent třídy a třídy tiled_index Místo objektu
parallel_for_eachve volání použijetetiled_extentobjektextent. Místo objektuparallel_for_eachve volání použijetetiled_indexobjektindex.
Pokud chcete využít výhod svázání, musí váš algoritmus rozdělit výpočetní doménu na dlaždice a pak data dlaždic zkopírovat do tile_static proměnných, aby byl rychlejší přístup.
Příklad globálních, dlaždicových a místních indexů
Poznámka:
Hlavičky C++ AMP jsou zastaralé od sady Visual Studio 2022 verze 17.0.
Zahrnutím všech hlaviček AMP se vygenerují chyby sestavení. Před zahrnutím záhlaví AMP definujte _SILENCE_AMP_DEPRECATION_WARNINGS upozornění.
Následující diagram představuje 8x9 matici dat, která jsou uspořádána do dlaždic 2x3.
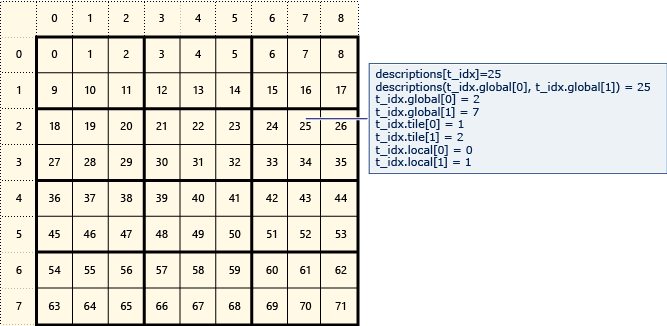
Následující příklad zobrazuje globální indexy, dlaždice a místní indexy této dlaždice matice. Objekt array_view je vytvořen pomocí prvků typu Description. Obsahuje Description globální indexy, dlaždice a místní indexy prvku v matici. Kód ve volání parallel_for_each nastaví hodnoty globálního, dlaždicového a místního indexu každého prvku. Výstup zobrazí hodnoty ve Description strukturách.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Hlavní práce příkladu je v definici objektu array_view a volání parallel_for_each.
Vektor
Descriptionstruktur je zkopírován do objektu 8x9array_view.Metoda
parallel_for_eachse volá s objektemtiled_extentjako výpočetní doménou. Objekttiled_extentje vytvořen volánímextent::tile()metodydescriptionsproměnné. Parametry typu voláníextent::tile(),<2,3>zadejte, že jsou vytvořeny 2x3 dlaždice. Matice 8x9 je tedy rozdělena na 12 dlaždic, čtyři řádky a tři sloupce.Metoda
parallel_for_eachje volána pomocí objektutiled_index<2,3>(t_idx) jako indexu. Parametry typu indexu (t_idx) musí odpovídat parametrům typu výpočetní domény (descriptions.extent.tile< 2, 3>()).Při každém spuštění vlákna vrátí index
t_idxinformace o tom, ve které dlaždici je vlákno (tiled_index::tilevlastnost) a umístění vlákna v rámci dlaždice (tiled_index::localvlastnost).
Synchronizace dlaždic – tile_static a tile_barrier::wait
Předchozí příklad znázorňuje rozložení a indexy dlaždic, ale není sám o sobě velmi užitečný. Svázání se stane užitečným v případech, kdy jsou dlaždice nedílnou součástí algoritmu a využívají tile_static proměnné. Vzhledem k tomu, že všechna vlákna na dlaždici mají přístup k tile_static proměnným, používají se volání tile_barrier::wait k synchronizaci přístupu k tile_static proměnným. I když všechna vlákna na dlaždici mají přístup k tile_static proměnným, neexistuje žádné zaručené pořadí provádění vláken na dlaždici. Následující příklad ukazuje, jak pomocí tile_static proměnných a tile_barrier::wait metody vypočítat průměrnou hodnotu každé dlaždice. Tady jsou klíče pro pochopení příkladu:
RawData je uložena v matici 8x8.
Velikost dlaždice je 2x2. Tím se vytvoří mřížka 4x4 dlaždic a průměry lze uložit v matici 4x4 pomocí objektu
array. Existuje pouze omezený počet typů, které můžete zachytit pomocí odkazu ve funkci s omezeným přístupem AMP. Třídaarrayje jedním z nich.Velikost matice a velikost vzorku jsou definovány pomocí
#definepříkazů, protože parametry typu naarray,array_viewextentatiled_indexmusí být konstantní hodnoty. Můžete také použítconst int staticdeklarace. Jako další výhoda je triviální změnit velikost vzorku pro výpočet průměru nad 4x4 dlaždic.Pro
tile_statickaždou dlaždici je deklarováno pole 2x2 s plovoucími hodnotami. Přestože deklarace je v cestě kódu pro každé vlákno, vytvoří se pro každou dlaždici v matici pouze jedno pole.Existuje řádek kódu, který zkopíruje hodnoty v každé dlaždici
tile_staticdo pole. Pro každé vlákno po zkopírování hodnoty do pole se provádění ve vlákně zastaví kvůli volánítile_barrier::wait.Když všechna vlákna na dlaždici dosáhla bariéry, je možné vypočítat průměr. Vzhledem k tomu, že se kód spouští pro každé vlákno, existuje příkaz
if, který vypočítává průměr pouze v jednom vlákně. Průměr je uložen v proměnné průměrů. Bariéra je v podstatě konstrukce, která řídí výpočty podle dlaždice, podobně jako můžete použít smyčkufor.Data v
averagesproměnné, protože se jedná oarrayobjekt, musí být zkopírována zpět do hostitele. Tento příklad používá operátor převodu vektoru.V úplném příkladu můžete změnit SAMPLESIZE na 4 a kód se spustí správně bez jakýchkoli dalších změn.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Konflikty časování
Může být lákavé vytvořit proměnnou tile_static s názvem total a zvýšit tuto proměnnou pro každé vlákno, například takto:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Prvním problémem tohoto přístupu je, že tile_static proměnné nemohou mít inicializátory. Druhým problémem je, že u přiřazení totalexistuje časová podmínka, protože všechna vlákna na dlaždici mají přístup k proměnné v žádném konkrétním pořadí. Můžete naprogramovat algoritmus, který umožní přístup pouze jednomu vláknu k celkovému součtu v každé bariérě, jak je znázorněno dále. Toto řešení ale není rozšiřitelné.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Ploty paměti
Existují dva druhy přístupů k paměti, které je potřeba synchronizovat – globální přístup k paměti a tile_static přístup k paměti. Objekt concurrency::array přiděluje pouze globální paměť. V concurrency::array_view závislosti na tom, jak byla vytvořena, může odkazovat na globální paměť, tile_static paměť nebo obojí. Je potřeba synchronizovat dva druhy paměti:
globální paměť
tile_static
Plot paměti zajišťuje, že přístup k paměti je k dispozici pro jiná vlákna na dlaždici vlákna a že přístupy k paměti jsou prováděny v souladu s pořadím programu. Aby bylo zajištěno, kompilátory a procesory nepřeuspořádá čtení a zápisy přes plot. V jazyce C++ AMP se plot paměti vytvoří voláním jedné z těchto metod:
tile_barrier::wait – metoda: Vytvoří plot kolem globální i
tile_staticpaměti.tile_barrier::wait_with_all_memory_fence Metoda: Vytvoří plot kolem globální i
tile_staticpaměti.tile_barrier::wait_with_global_memory_fence Metoda: Vytvoří plot kolem pouze globální paměti.
tile_barrier::wait_with_tile_static_memory_fence Metoda: Vytvoří plot pouze kolem
tile_staticpaměti.
Volání konkrétního plotu, který potřebujete, může zlepšit výkon vaší aplikace. Typ bariéry ovlivňuje způsob, jakým kompilátor a příkazy hardwaru přeuspořádá. Pokud například používáte globální plot paměti, vztahuje se pouze na globální přístup k paměti, a proto kompilátor a hardware může změnit pořadí čtení a zápisů do tile_static proměnných na dvou stranách plotu.
V dalším příkladu bariéra synchronizuje zápisy do tileValuestile_static proměnné. V tomto příkladu se tile_barrier::wait_with_tile_static_memory_fence volá místo tile_barrier::wait.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Viz také
C++ AMP (C++ Accelerated Massive Parallelism)
tile_static Keyword