Analýza dat pomocí Azure Machine Learning
Tento kurz používá návrháře služby Azure Machine Learning k vytvoření prediktivního modelu strojového učení. Model je založený na datech uložených v Azure Synapse. Scénář kurzu je předpovědět, jestli si zákazník pravděpodobně koupí kolo nebo ne, aby společnost Adventure Works, obchod s koly, mohla sestavit cílovou marketingovou kampaň.
Požadavky
Pro jednotlivé kroky v tomto kurzu budete potřebovat:
- Předem načtený fond SQL s ukázkovými daty AdventureWorksDW. Pokud chcete zřídit tento fond SQL, přečtěte si téma Vytvoření fondu SQL a výběr načtení ukázkových dat. Pokud už máte datový sklad, ale nemáte ukázková data, můžete ukázková data načíst ručně.
- pracovní prostor Azure Machine Learning. Podle tohoto kurzu vytvořte nový.
Získání dat
Použitá data jsou v zobrazení dbo.vTargetMail v AdventureWorksDW. Pokud chcete použít úložiště dat v tomto kurzu, data se nejprve exportují do účtu Azure Data Lake Storage, protože Azure Synapse v současné době nepodporuje datové sady. Azure Data Factory se dá použít k exportu dat z datového skladu do Azure Data Lake Storage pomocí aktivity kopírování. K importu použijte následující dotaz:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Jakmile jsou data dostupná ve službě Azure Data Lake Storage, úložiště dat ve službě Azure Machine Learning se použijí k připojení ke službám úložiště Azure. Následujícím postupem vytvořte úložiště dat a odpovídající datovou sadu:
Spusťte studio Azure Machine Learning z webu Azure Portal nebo se přihlaste na studio Azure Machine Learning.
V části Spravovat klikněte na Úložiště dat v levém podokně a potom klikněte na Nový úložiště dat.
Zadejte název úložiště dat, vyberte typ jako Azure Blob Storage, zadejte umístění a přihlašovací údaje. Poté klikněte na možnost Vytvořit.
Dále v části Prostředky klikněte na Datové sady v levém podokně. Vyberte Vytvořit datovou sadu s možností Z úložiště dat.
Zadejte název datové sady a vyberte typ, který má být tabulkový. Potom klikněte na Další a přesuňte se dopředu.
V části Vybrat nebo vytvořit úložiště dat vyberte možnost Dříve vytvořené úložiště dat. Vyberte úložiště dat, které bylo vytvořeno dříve. Klepněte na tlačítko Další a zadejte cestu a nastavení souboru. Pokud soubory obsahují záhlaví sloupce, nezapomeňte zadat záhlaví sloupce.
Nakonec kliknutím na Vytvořit vytvořte datovou sadu.
Konfigurace experimentu návrháře
Dále postupujte podle následujících kroků pro konfiguraci návrháře:
V části Autor klikněte na kartu Návrhář v levém podokně.
Vyberte snadno použitelné předem připravené komponenty pro sestavení nového kanálu.
V podokně nastavení napravo zadejte název kanálu.
Vyberte také cílový výpočetní cluster pro celý experiment v tlačítku nastavení na dříve zřízený cluster. Zavřete podokno Nastavení.
Import dat
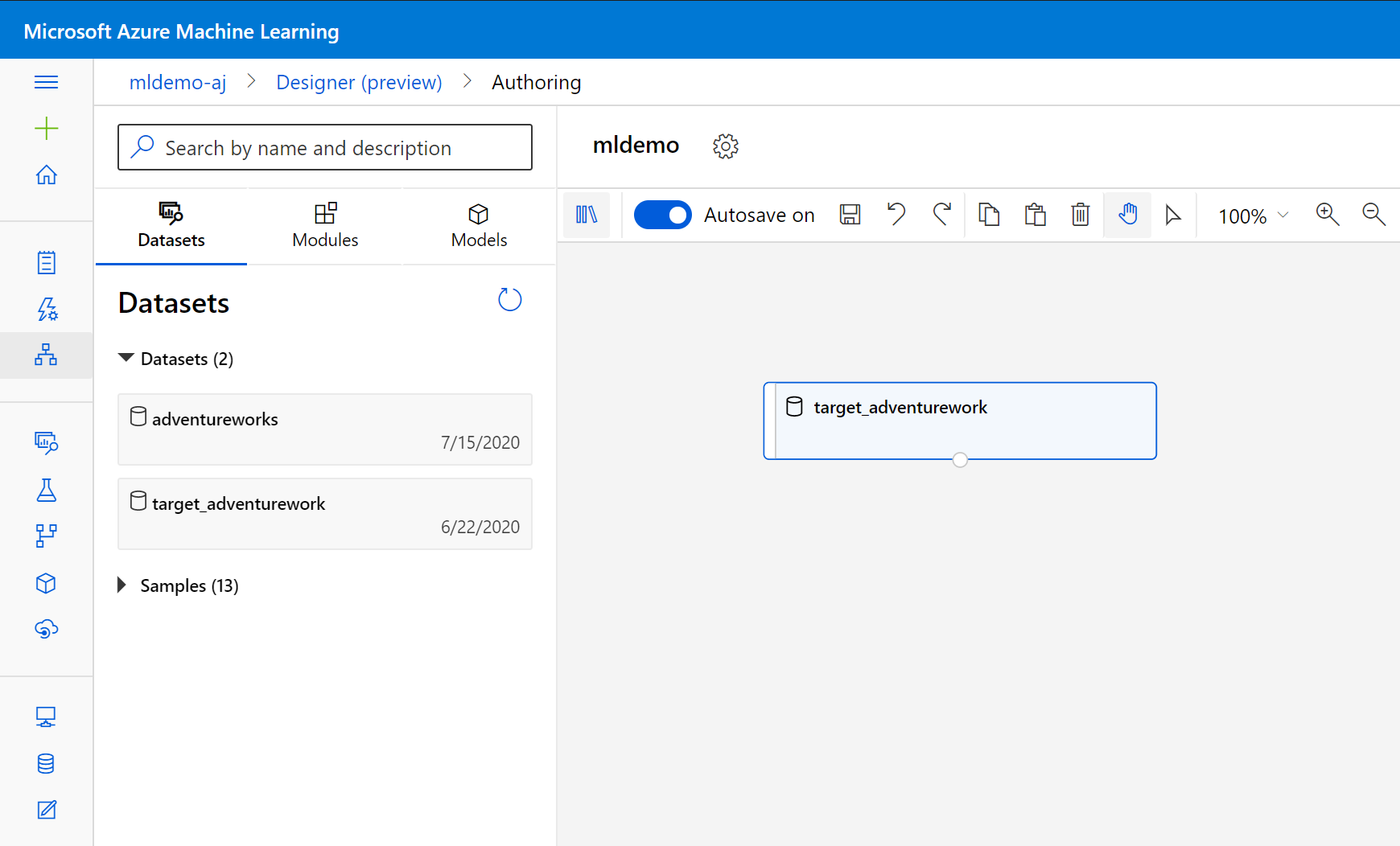
V levém podokně pod vyhledávacím polem vyberte podtábku Datové sady.
Přetáhněte datovou sadu, kterou jste vytvořili dříve, na plátno.
Vyčištění dat
Pokud chcete data vyčistit, odstraňte sloupce, které nejsou pro model relevantní. Postupujte následovně:
V levém podokně vyberte podtabu Součásti .
Přetáhněte položku Vybrat sloupce v datové sadě v části Manipulace s transformací < dat na plátno. Připojte tuto komponentu ke komponentě Dataset .
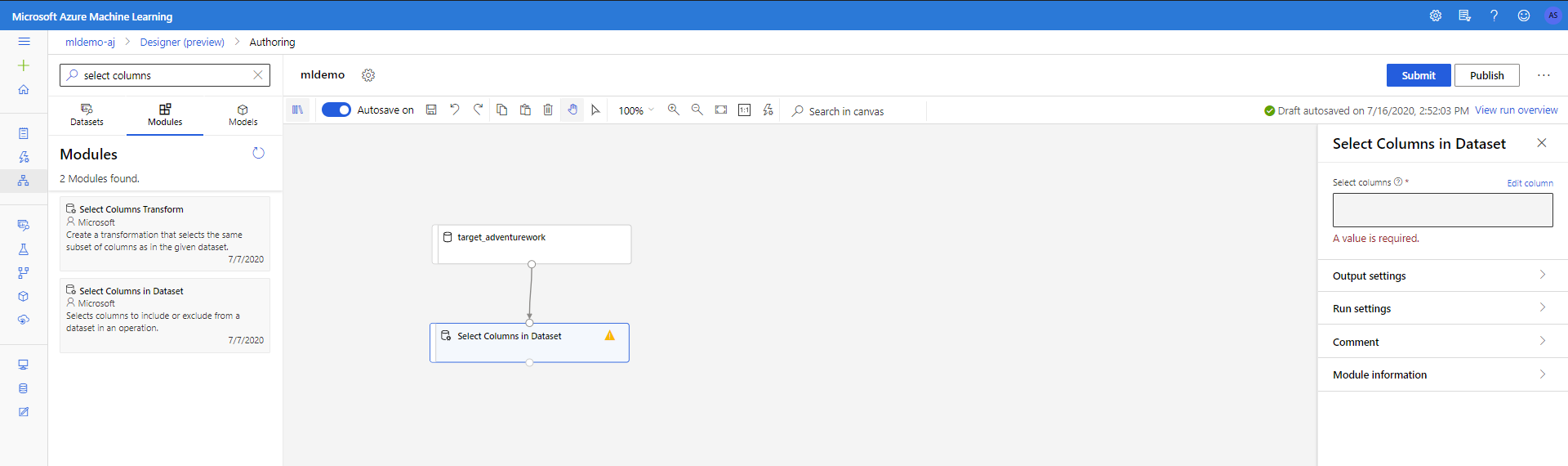
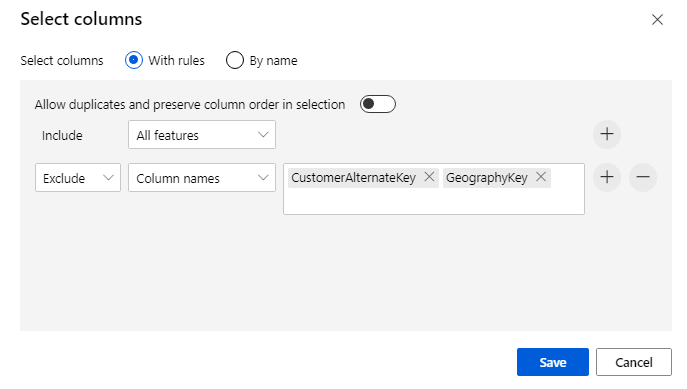
Kliknutím na komponentu otevřete podokno vlastností. Klikněte na Upravit sloupec a určete sloupce, které chcete vypustit.
Vylučte dva sloupce: CustomerAlternateKey a GeographyKey. Klikněte na Uložit.

Vytvoření modelu
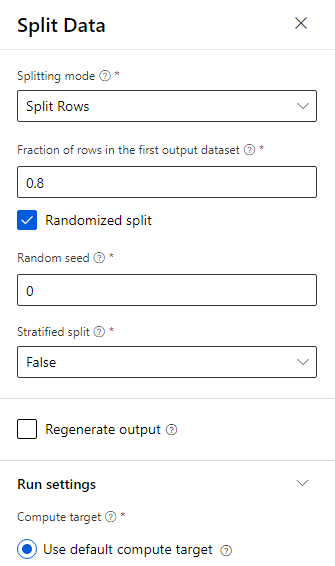
Data jsou rozdělená na 80–20: 80 % na trénování modelu strojového učení a 20 % k otestování modelu. Algoritmy se dvěma třídami se používají v tomto problému s binární klasifikací.
Přetáhněte komponentu Rozdělit data na plátno.
V podokně vlastností zadejte 0,8 pro zlomek řádků v první výstupní datové sadě.
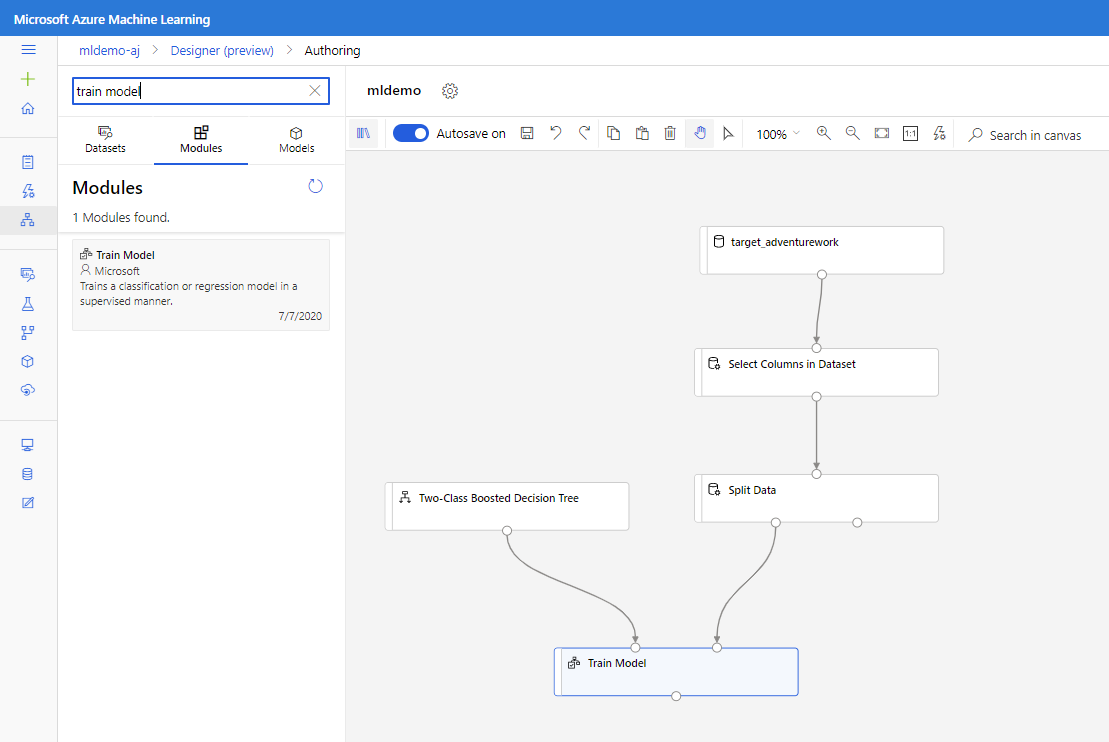
Přetáhněte komponentu rozhodovacího stromu se dvěma třídami na plátno.
Přetáhněte komponentu Train Model na plátno. Zadejte vstupy tak, že je propojíte s komponentami dvoutřídového rozhodovacího stromu (algoritmus ML) a rozdělíte data (data pro trénování algoritmu).
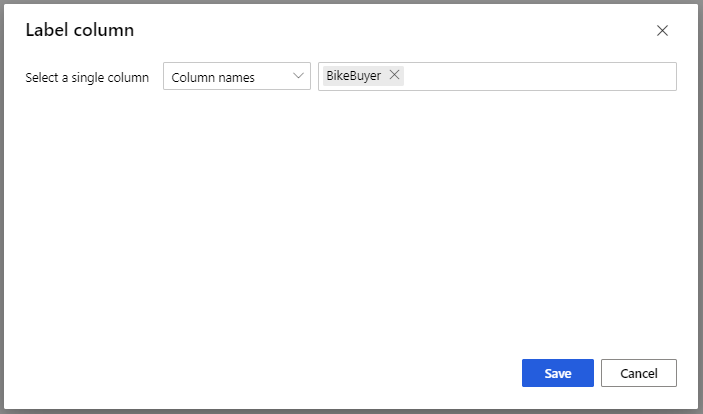
V části Trénování modelu vyberte v části Sloupec Popisek v podokně Vlastnosti možnost Upravit sloupec. Vyberte sloupec BikeBuyer jako sloupec, který chcete předpovědět, a vyberte Uložit.
Určení skóre modelu
Teď otestujte, jak model funguje s testovacími daty. Ve srovnání se dvěma různými algoritmy zjistíte, který z nich funguje lépe. Postupujte následovně:
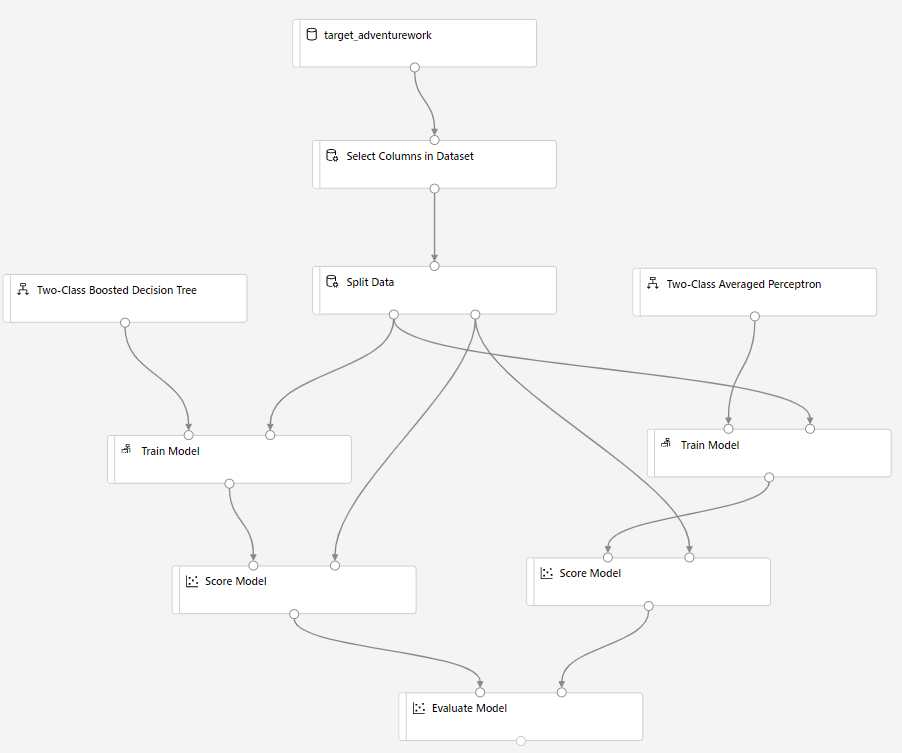
Přetáhněte komponentu Score Model na plátno a připojte ji k komponentám Trénování modelu a Rozdělení dat .
Přetáhněte perceptron se dvěma třídami na plátno experimentu. Porovnáte, jak tento algoritmus funguje ve srovnání s rozhodovacím stromem se dvěma třídami.
Zkopírujte a vložte komponenty trénování modelu a určení skóre modelu na plátně.
Přetáhněte komponentu Vyhodnotit model na plátno a porovnejte dva algoritmy.
Kliknutím na odeslat nastavíte spuštění kanálu.
Po dokončení spuštění klikněte pravým tlačítkem myši na komponentu Vyhodnotit model a klikněte na Vizualizovat výsledky vyhodnocení.
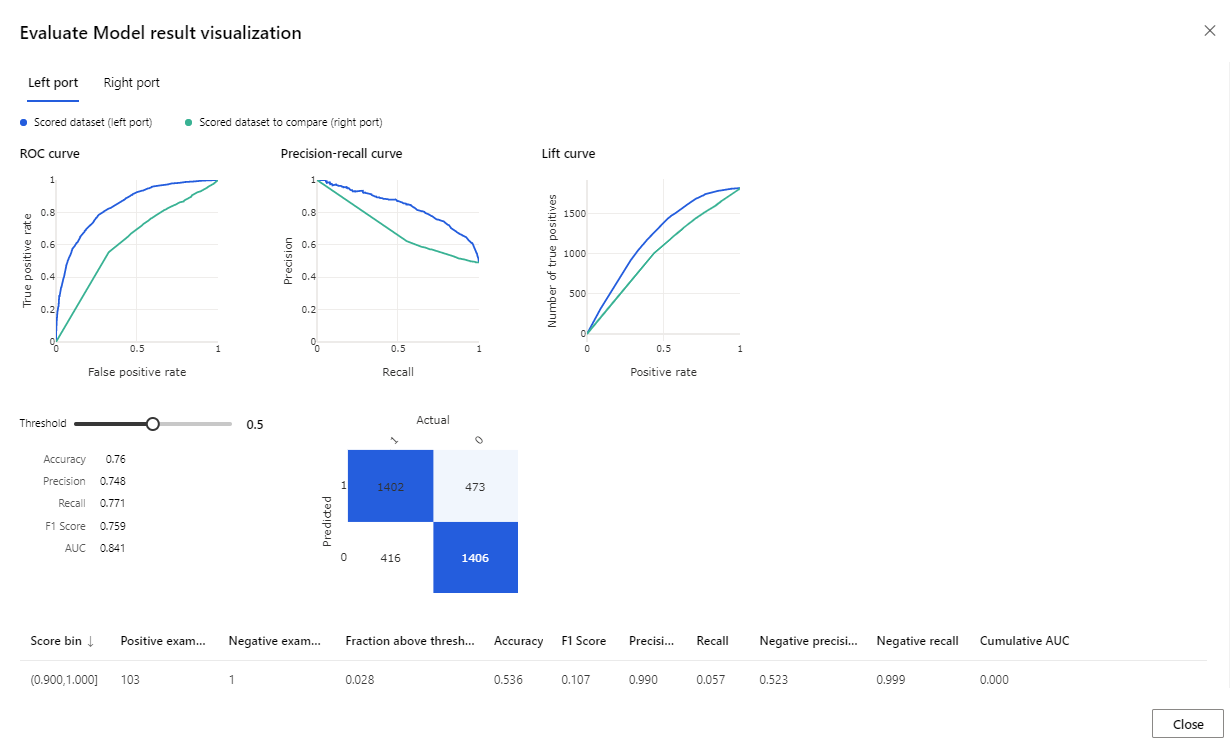

Poskytované metriky jsou křivka ROC, diagram přesnosti a křivka lift. Podívejte se na tyto metriky a podívejte se, že první model fungoval lépe než druhý. Pokud se chcete podívat na to, co první model predikoval, klikněte pravým tlačítkem myši na komponentu Určení skóre modelu a klikněte na Vizualizovat datovou sadu skóre, abyste viděli predikované výsledky.
Do testovací datové sady se přidají dva další sloupce.
- Scored Probabilities (Vyhodnocené pravděpodobnosti): Pravděpodobnost, že si zákazník koupí kolo.
- Scored Labels (Popisky vyhodnocení): Klasifikace prováděná modelem – kupující (1) nebo nekupující (0) kolo. Tato prahová hodnota pravděpodobnosti pro popisky je nastavena na 50 % a je možné ji upravit.
Porovnejte sloupec BikeBuyer (skutečný) s popisky skóre (předpověď), abyste viděli, jak dobře model provedl. V dalším kroku můžete pomocí tohoto modelu vytvářet předpovědi pro nové zákazníky. Tento model můžete publikovat jako webovou službu nebo zapisovat výsledky zpět do Azure Synapse.
Další kroky
Další informace o službě Azure Machine Learning najdete v tématu Úvod do služby Machine Learning v Azure.