Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Synapse Analytics je analytická služba, která spojuje podnikové datové sklady a analýzy velkých objemů dat. Poskytuje vám svobodu dotazovat se na data podle vašich podmínek.
Poznámka:
Další informace o službě Azure Synapse Analytics najdete v tomto videu s vysvětlením vylepšení přesunu dat.
Komponenty architektury Synapse SQL
Vyhrazený fond SQL (dříve SQL DW) využívá rozšiřující architekturu k distribuci výpočetního zpracování dat přes více uzlů. Jednotka škálování je abstrakce výpočetního výkonu, který se označuje jako jednotka datového skladu. Výpočetní funkce jsou oddělené od úložiště, což umožňuje jejich škálování nezávisle na datech v systému.
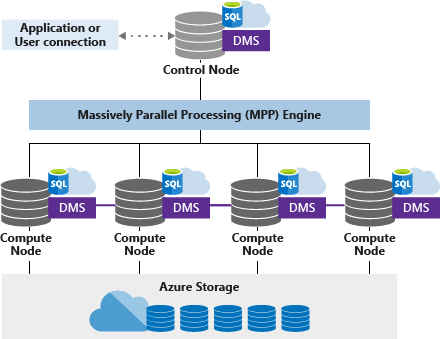
Vyhrazený SQL pool (dříve SQL DW) používá architekturu založenou na uzlech. Aplikace se připojují a vydávají příkazy T-SQL k řídicímu uzlu. Řídicí uzel hostuje distribuovaný dotazovací modul, který optimalizuje dotazy pro paralelní zpracování, a pak předává operace výpočetním uzlům, aby fungovaly paralelně.
Výpočetní uzly ukládají veškerá data uživatelů ve službě Azure Storage a spouští paralelní dotazy. DMS (Data Movement Service) je interní služba na úrovni systému, která podle potřeby přesunuje data mezi uzly, aby bylo možné spouštět dotazy paralelně a získat přesné výsledky.
S odděleným úložištěm a výpočetními prostředky můžete při použití vyhrazeného fondu SQL (dříve SQL DW) provést:
- Upravte výpočetní výkon nezávisle na vašich potřebách úložiště.
- Zvětšete nebo zmenšete výpočetní výkon ve vyhrazeném fondu SQL (dříve SQL DW) bez přesunu dat.
- pozastavit výpočetní kapacitu a zachovat neporušená data, zatímco platíte pouze za úložiště,
- obnovit výpočetní kapacitu za provozu.
Azure Storage
Vyhrazený fond SQL (dříve SQL DW) využívá Službu Azure Storage k zabezpečení vašich uživatelských dat. Vzhledem k tomu, že jsou vaše data uložená a spravovaná službou Azure Storage, platí se za využití úložiště samostatné poplatky. Data se horizontálně rozdělují do distribucí , aby se optimalizoval výkon systému. Při definování tabulky můžete zvolit, který model horizontálního dělení se má pro distribuci dat použít. Podporují se tyto vzory horizontálního dělení:
- Hash
- Round Robin
- Replikace
Řídicí uzel
Mozkem této architektury je řídicí uzel. Jde o front-end, který komunikuje se všemi aplikacemi a připojeními. Distribuovaný dotazovací modul běží na řídicím uzlu pro optimalizaci a koordinaci paralelních dotazů. Když odešlete dotaz T-SQL, řídicí uzel ho transformuje na dotazy spuštěné paralelně pro každou distribuci.
Výpočetní uzly
Výpočetní uzly poskytují výpočetní výkon. Distribuce se mapují na výpočetní uzly pro zpracování. Když platíte za další výpočetní prostředky, distribuce se znovu namapují na dostupné výpočetní uzly. Počet výpočetních uzlů se pohybuje od 1 do 60 a určuje se úrovní služby pro Synapse SQL.
Každý výpočetní uzel má ID uzlu, které je viditelné v systémových zobrazeních. ID výpočetního uzlu můžete zobrazit vyhledáním sloupce node_id v systémových zobrazeních, jejichž názvy začínají sys.pdw_nodes. Seznam těchto systémových zobrazení najdete v tématu Systémová zobrazení Synapse SQL.
Data Movement Service
Služba pro přesun dat (DMS) je technologie přenosu dat, která koordinuje přesun dat mezi výpočetními uzly. Některé dotazy vyžadují přesun dat, aby paralelní dotazy vracely přesné výsledky. Když se vyžaduje přesun dat, DMS zajistí, aby se správná data dostala do správného umístění.
Distribuce
Distribuce představuje základní jednotku úložiště a zpracování paralelních dotazů, které se spouští u distribuovaných dat. Když Synapse SQL spustí dotaz, práce se rozdělí na 60 menších dotazů, které běží paralelně.
Každý z 60 menších dotazů běží na jedné z distribucí dat. Každý výpočetní uzel spravuje jednu nebo více distribucí 60. Vyhrazený fond SQL (dříve SQL DW) s maximálním počtem výpočetních prostředků má jednu distribuci na výpočetní uzel. Vyhrazený fond SQL (dříve SQL DW) s minimálními výpočetními prostředky má všechny distribuce na jednom výpočetním uzlu.
Poznámka:
Doporučení pro nejlepší strategii distribuce tabulek, která se má použít na základě vašich úloh, najdete v poradci pro distribuci Sql pro Azure Synapse SQL.
Distribuované tabulky založené na hashování
Tabulka s rozložením podle hash může přinést nejvyšší výkon dotazování pro spojování a agregace u velkých tabulek.
Pro rozdělení dat do tabulky distribuované pomocí hashovací funkce se používá hashovací funkce pro deterministické přiřazení každého řádku k určité distribuci. V definici tabulky je jeden ze sloupců určený jako sloupec distribuce. Funkce hash používá hodnoty ve sloupci distribuce k přiřazení jednotlivých řádků k distribuci.
Následující diagram znázorňuje, jak se nedistribuovaná tabulka uloží jako tabulka s distribucí podle hash.

- Každý řádek patří do jedné distribuce.
- Deterministický hashovací algoritmus přiřadí každý řádek k jedné distribuci.
- Počet řádků v tabulkách se liší podle rozdělení, jak ukazují různé velikosti tabulek.
Při výběru distribučního sloupce existují důležité informace o výkonu, například jedinečnost, nerovnoměrná distribuce dat a typy dotazů, které běží v systému.
Distribuované tabulky s rozdělováním metodou round-robin.
Tabulka s kruhovým dotazem je nejjednodušší tabulka, která slouží k vytvoření a zajištění rychlého výkonu při použití jako pracovní tabulky pro načtení.
Distribuovaná tabulka s round-robin distribuuje data v tabulce rovnoměrně, ale bez další optimalizace. Nejprve se náhodně vybere rozdělení a poté se bloky řádků postupně přiřazují k rozdělením. Načtení dat do kruhové tabulky je rychlé, ale výkon dotazu může být často lepší u hash distribuovaných tabulek. Spojení v tabulkách s kruhovým dotazováním vyžadují přemístit data, což trvá delší dobu.
Replikované tabulky
Replikovaná tabulka poskytuje nejrychlejší výkon dotazů u malých tabulek.
Tabulka, která se replikuje, ukládá do mezipaměti úplnou kopii tabulky na každém výpočetním uzlu. V důsledku toho při replikaci tabulky odpadne nutnost před propojením nebo agregací přenášet data mezi výpočetními uzly. Replikované tabulky jsou nejlépe využitelné u malých tabulek. Vyžaduje se dodatečné úložiště a při zápisu dat se účtují další režijní náklady, díky kterým jsou velké tabulky nepraktické.
Následující diagram znázorňuje replikovanou tabulku, která je uložená v mezipaměti první distribuce na každém výpočetním uzlu.

Související obsah
Teď, když už znáte azure Synapse, se dozvíte, jak rychle vytvořit vyhrazený fond SQL (dříve SQL DW) a načíst ukázková data. Pokud s Azure začínáte, můžou vám pomoct základní koncepty Azure, když narazíte na novou terminologii. Nebo se podívejte na některé z těchto dalších prostředků Azure Synapse.