Úvod k rozhraním API pro připojení a odpojování souborů ve službě Azure Synapse Analytics
Tým Azure Synapse Studio vytvořil v balíčku Microsoft Spark Utilities (mssparkutils) dvě nová rozhraní API pro připojení a odpojení. Tato rozhraní API můžete použít k připojení vzdáleného úložiště (Azure Blob Storage nebo Azure Data Lake Storage Gen2) ke všem pracovním uzlům (uzel ovladače a pracovní uzly). Jakmile je úložiště na místě, můžete k přístupu k datům použít místní souborové rozhraní API, jako by byla uložena v místním systému souborů. Další informace naleznete v tématu Úvod do nástrojů Microsoft Spark Utilities.
V článku se dozvíte, jak používat rozhraní API pro připojení nebo odpojení ve vašem pracovním prostoru. Naučíte se:
- Jak připojit Data Lake Storage Gen2 nebo Blob Storage
- Přístup k souborům pod přípojným bodem prostřednictvím místního rozhraní API systému souborů
- Přístup k souborům pod přípojným bodem pomocí
mssparkutils fsrozhraní API - Přístup k souborům pod přípojným bodem pomocí rozhraní API pro čtení Sparku
- Jak odpojit přípojný bod
Upozorňující
Připojení sdílené složky Azure je dočasně zakázané. Místo toho můžete použít připojení Data Lake Storage Gen2 nebo Azure Blob Storage, jak je popsáno v další části.
Úložiště Azure Data Lake Storage Gen1 se nepodporuje. Před použitím rozhraní API pro připojení můžete migrovat do Data Lake Storage Gen2 podle pokynů k migraci Azure Data Lake Storage Gen1 na Gen2.
Připojení úložiště
Tato část ukazuje, jak krok za krokem připojit Data Lake Storage Gen2 jako příklad. Připojení služby Blob Storage funguje podobně.
Příklad předpokládá, že máte jeden účet Data Lake Storage Gen2 s názvem storegen2. Účet má jeden kontejner s názvem mycontainer , ke /test kterému se chcete připojit ve fondu Sparku.
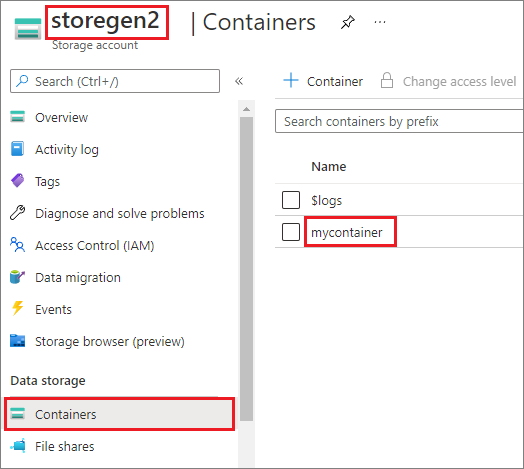
Pokud chcete připojit volaný mycontainerkontejner, musíte nejprve zkontrolovat, mssparkutils jestli máte oprávnění pro přístup k kontejneru. Azure Synapse Analytics v současné době podporuje tři metody ověřování pro operaci připojení triggeru: linkedService, accountKeya sastoken.
Připojení pomocí propojené služby (doporučeno)
Doporučujeme připojení triggeru přes propojenou službu. Tato metoda zabraňuje únikům zabezpečení, protože mssparkutils neukládá žádné tajné nebo ověřovací hodnoty samotné.
mssparkutils Místo toho vždy načte hodnoty ověřování z propojené služby, aby bylo možné požadovat data objektů blob ze vzdáleného úložiště.
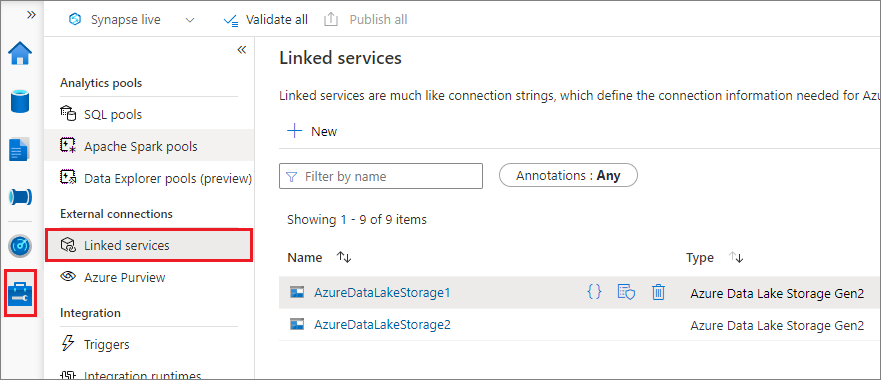
Můžete vytvořit propojenou službu pro Data Lake Storage Gen2 nebo Blob Storage. Azure Synapse Analytics v současné době podporuje dvě metody ověřování při vytváření propojené služby:
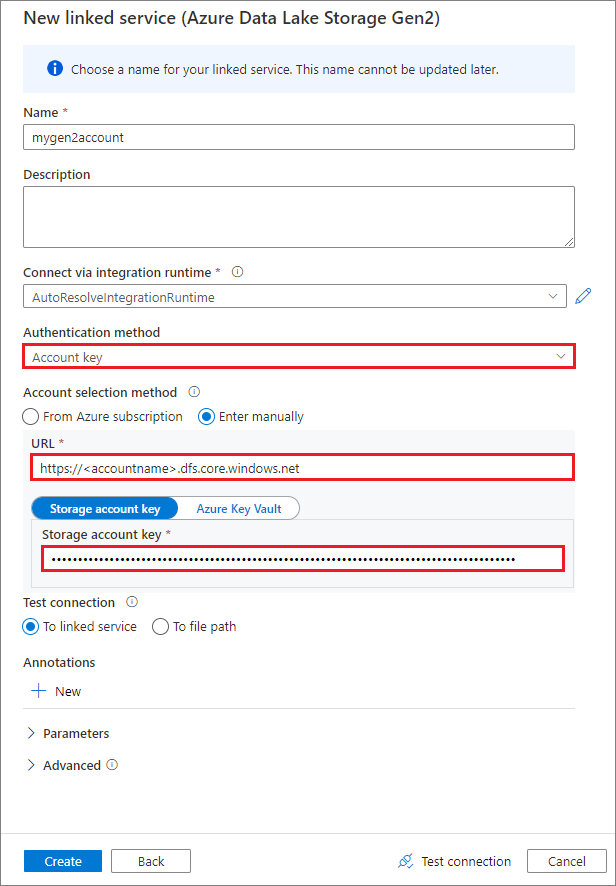
Vytvoření propojené služby pomocí klíče účtu
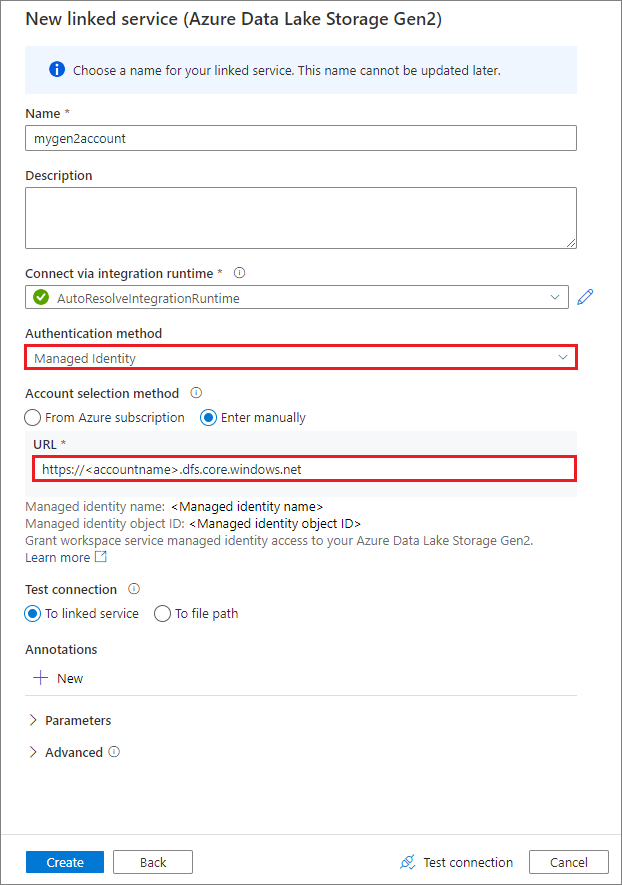
Vytvoření propojené služby pomocí spravované identity přiřazené systémem
Důležité
- Pokud výše vytvořená propojená služba pro Azure Data Lake Storage Gen2 používá spravovaný privátní koncový bod (s identifikátorem URI dfs), potřebujeme vytvořit další sekundární spravovaný privátní koncový bod pomocí možnosti Azure Blob Storage (s identifikátorem URI objektu blob), aby se interní kód fsspec/adlfs mohl připojit pomocí rozhraní BlobServiceClient.
- V případě, že sekundární spravovaný privátní koncový bod není správně nakonfigurovaný, zobrazí se chybová zpráva typu ServiceRequestError: Nejde se připojit k hostiteli [storageaccountname].blob.core.windows.net:443 ssl:True [Název nebo služba není známá]
Poznámka:
Pokud jako metodu ověřování vytvoříte propojenou službu pomocí spravované identity, ujistěte se, že soubor MSI pracovního prostoru má roli Přispěvatel dat objektů blob služby Storage připojeného kontejneru.
Po úspěšném vytvoření propojené služby můžete kontejner snadno připojit ke svému fondu Spark pomocí následujícího kódu Pythonu:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Poznámka:
Pokud není k dispozici, budete možná muset importovat mssparkutils :
from notebookutils import mssparkutils
Nedoporučujeme připojit kořenovou složku bez ohledu na to, jakou metodu ověřování používáte.
Parametry připojení:
- fileCacheTimeout: Objekty blob se ve výchozím nastavení ukládají do místní dočasné složky po dobu 120 sekund. Během této doby blobfuse nekontroluje, jestli je soubor aktuální, nebo ne. Parametr může být nastavený tak, aby změnil výchozí časový limit. Pokud více klientů současně upravuje soubory, aby nedocházelo k nekonzistence mezi místními a vzdálenými soubory, doporučujeme zkrátit dobu mezipaměti nebo dokonce změnit na 0 a vždy získat nejnovější soubory ze serveru.
- časový limit: Časový limit operace připojení je ve výchozím nastavení 120 sekund. Parametr může být nastavený tak, aby změnil výchozí časový limit. Pokud dojde k příliš velkému počtu exekutorů nebo když vyprší časový limit připojení, doporučujeme zvýšit hodnotu.
- scope: Parametr oboru se používá k určení rozsahu připojení. Výchozí hodnota je "job". Pokud je obor nastavený na úlohu, připojení se zobrazí pouze pro aktuální cluster. Pokud je obor nastavený na "pracovní prostor", je připojení viditelné pro všechny poznámkové bloky v aktuálním pracovním prostoru a přípojný bod se automaticky vytvoří, pokud neexistuje. Přidejte stejné parametry do rozhraní API pro odpojení přípojného bodu. Připojení na úrovni pracovního prostoru je podporováno pouze pro ověřování propojených služeb.
Můžete použít následující parametry:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Připojení prostřednictvím tokenu sdíleného přístupového podpisu nebo klíče účtu
Kromě připojení prostřednictvím propojené služby mssparkutils podporuje explicitní předání klíče účtu nebo tokenu sdíleného přístupového podpisu (SAS) jako parametru pro připojení cíle.
Z bezpečnostních důvodů doporučujeme ukládat klíče účtu nebo tokeny SAS ve službě Azure Key Vault (jak ukazuje následující příklad snímku obrazovky). Pak je můžete načíst pomocí mssparkutil.credentials.getSecret rozhraní API. Další informace najdete v tématu Správa klíčů účtu úložiště pomocí služby Key Vault a Azure CLI (starší verze).
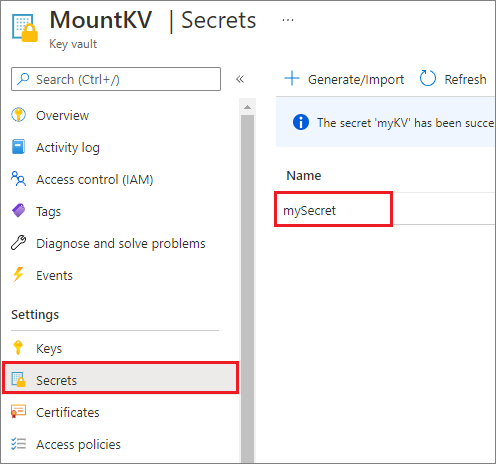
Tady je ukázkový kód:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Poznámka:
Z bezpečnostních důvodů neukládejte přihlašovací údaje do kódu.
Přístup k souborům pod přípojným bodem pomocí rozhraní MSsparkutils fs API
Hlavním účelem operace připojení je umožnit zákazníkům přístup k datům uloženým ve vzdáleném účtu úložiště pomocí místního rozhraní API systému souborů. K datům můžete přistupovat také pomocí mssparkutils fs rozhraní API s připojenou cestou jako parametrem. Formát cesty použitý tady je trochu jiný.
Za předpokladu, že jste kontejner Data Lake Storage Gen2 připojili mycontainer k /test pomocí rozhraní API pro připojení. Při přístupu k datům prostřednictvím místního rozhraní API systému souborů:
- Pro verze Sparku menší nebo rovnou 3.3 je
/synfs/{jobId}/test/{filename}formát cesty . - Pro verze Sparku větší nebo rovno 3.4 je
/synfs/notebook/{jobId}/test/{filename}formát cesty .
Doporučujeme použít mssparkutils.fs.getMountPath() k získání přesné cesty:
path = mssparkutils.fs.getMountPath("/test")
Poznámka:
Když připojíte úložiště s oborem workspace , bod připojení se vytvoří ve /synfs/workspace složce. A musíte použít mssparkutils.fs.getMountPath("/test", "workspace") k získání přesné cesty.
Pokud chcete získat přístup k datům pomocí mssparkutils fs rozhraní API, formát cesty je podobný tomuto: synfs:/notebook/{jobId}/test/{filename}. V tomto případě se místo části připojené cesty můžete podívat, že synfs se používá jako schéma. Samozřejmě můžete pro přístup k datům použít také schéma místního systému souborů. Například file:/synfs/notebook/{jobId}/test/{filename}.
Následující tři příklady ukazují, jak získat přístup k souboru s cestou přípojného bodu pomocí mssparkutils fs.
Seznam adresářů:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Čtení obsahu souboru:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Vytvořte adresář:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Přístup k souborům pod přípojným bodem pomocí rozhraní API pro čtení Sparku
Můžete zadat parametr pro přístup k datům prostřednictvím rozhraní API pro čtení Sparku. Formát cesty je stejný, když používáte mssparkutils fs rozhraní API.
Čtení souboru z připojeného účtu úložiště Data Lake Storage Gen2
Následující příklad předpokládá, že účet úložiště Data Lake Storage Gen2 je již připojený a pak soubor přečtete pomocí cesty připojení:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Poznámka:
Když připojíte úložiště pomocí propojené služby, měli byste před použitím schématu synfs pro přístup k datům vždy explicitně nastavit konfiguraci propojené služby Spark. Podrobnosti najdete v úložišti ADLS Gen2 s propojenými službami .
Čtení souboru z připojeného účtu služby Blob Storage
Pokud jste připojili účet služby Blob Storage a chcete k němu získat přístup pomocí mssparkutils rozhraní SPARK API, musíte token SAS explicitně nakonfigurovat prostřednictvím konfigurace Sparku, než se pokusíte kontejner připojit pomocí rozhraní API pro připojení:
Pokud chcete získat přístup k účtu Blob Storage pomocí
mssparkutilsrozhraní SPARK API po připojení triggeru, aktualizujte konfiguraci Sparku, jak je znázorněno v následujícím příkladu kódu. Tento krok můžete obejít, pokud chcete získat přístup ke konfiguraci Sparku pouze pomocí místního rozhraní API souborů po připojení.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Vytvořte propojenou službu
myblobstorageaccounta připojte účet Blob Storage pomocí propojené služby:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Připojte kontejner Blob Storage a pak soubor načtěte pomocí cesty připojení prostřednictvím místního rozhraní API pro soubory:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Čtení dat z připojeného kontejneru Blob Storage prostřednictvím rozhraní API pro čtení Sparku:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Odpojení přípojného bodu
Pomocí následujícího kódu odpojte přípojný bod (/test v tomto příkladu):
mssparkutils.fs.unmount("/test")
Známá omezení
Mechanismus odpojování není automatický. Po dokončení spuštění aplikace je potřeba odpojit přípojný bod a uvolnit místo na disku, musíte v kódu explicitně volat rozhraní API pro odpojení. V opačném případě bude přípojný bod stále existovat v uzlu po dokončení spuštění aplikace.
Připojení účtu úložiště Data Lake Storage Gen1 se prozatím nepodporuje.