Kurz: Vytvoření aplikace strojového učení s využitím Apache Spark MLlib a Azure Synapse Analytics
V tomto článku se dozvíte, jak pomocí Apache Spark MLlib vytvořit aplikaci strojového učení, která provede jednoduchou prediktivní analýzu otevřené datové sady Azure. Spark poskytuje integrované knihovny strojového učení. Tento příklad používá klasifikaci prostřednictvím logistické regrese.
SparkML a MLlib jsou základní knihovny Sparku, které poskytují mnoho nástrojů, které jsou užitečné pro úlohy strojového učení, včetně nástrojů, které jsou vhodné pro:
- Klasifikace
- Regrese
- Clustering
- Modelování témat
- Rozklad singulárových hodnot (SVD) a analýza hlavních komponent (PCA)
- Testování hypotéz a výpočet výběrové statistiky
Principy klasifikace a logistické regrese
Klasifikace, oblíbená úloha strojového učení, je proces řazení vstupních dat do kategorií. Úkolem klasifikačního algoritmu je zjistit, jak přiřadit popisky ke vstupním datům, která zadáte. Můžete si například představit algoritmus strojového učení, který přijímá informace o akciích jako vstup a rozděluje akcie do dvou kategorií: akcie, které byste měli prodávat, a akcie, které byste měli zachovat.
Logistická regrese je algoritmus, který můžete použít ke klasifikaci. Rozhraní API logistické regrese Sparku je užitečné pro binární klasifikaci nebo klasifikaci vstupních dat do jedné ze dvou skupin. Další informace o logistické regresi najdete na Wikipedii.
Souhrnně řečeno, proces logistické regrese vytváří logistickou funkci , kterou můžete použít k predikci pravděpodobnosti, že vstupní vektor patří do jedné nebo druhé skupiny.
Příklad prediktivní analýzy dat taxislužby NYC
V tomto příkladu použijete Spark k provedení prediktivní analýzy dat s tipem taxislužby z New Yorku. Data jsou k dispozici prostřednictvím služby Azure Open Datasets. Tato podmnožina datové sady obsahuje informace o žlutých cestách taxíkem, včetně informací o jednotlivých cestách, počátečním a koncovém čase a umístění, nákladech a dalších zajímavých atributech.
Důležité
Za načtení těchto dat z umístění úložiště se můžou účtovat další poplatky.
V následujících krocích vytvoříte model, který předpovídá, jestli konkrétní cesta obsahuje tip nebo ne.
Vytvoření modelu strojového učení Apache Sparku
Vytvořte poznámkový blok pomocí jádra PySpark. Pokyny najdete v tématu Vytvoření poznámkového bloku.
Importujte typy požadované pro tuto aplikaci. Zkopírujte následující kód a vložte ho do prázdné buňky a stiskněte klávesy Shift+Enter. Nebo buňku spusťte pomocí modré ikony přehrávání nalevo od kódu.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorKvůli jádru PySpark nemusíte explicitně vytvářet žádné kontexty. Kontext Sparku se automaticky vytvoří při spuštění první buňky kódu.
Vytvoření vstupního datového rámce
Vzhledem k tomu, že nezpracovaná data jsou ve formátu Parquet, můžete použít kontext Sparku k přímému načtení souboru do paměti jako datového rámce. I když kód v následujících krocích používá výchozí možnosti, je možné vynutit mapování datových typů a dalších atributů schématu v případě potřeby.
Spuštěním následujících řádků vytvořte datový rámec Sparku vložením kódu do nové buňky. Tento krok načte data prostřednictvím rozhraní Open Datasets API. Načtení všech těchto dat vygeneruje přibližně 1,5 miliardy řádků.
V závislosti na velikosti bezserverového fondu Apache Sparku můžou být nezpracovaná data příliš velká nebo můžou trvat příliš dlouhou dobu, než se na nich pracuje. Tato data můžete filtrovat na něco menšího. Následující příklad kódu používá
start_dateaend_datek použití filtru, který vrací data za jeden měsíc.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Nevýhodou jednoduchého filtrování je, že ze statistického hlediska může do dat vnést předsudky. Dalším přístupem je použití vzorkování integrovaného do Sparku.
Následující kód zmenšuje datovou sadu na přibližně 2 000 řádků, pokud se použije po předchozím kódu. Tento krok vzorkování můžete použít místo jednoduchého filtru nebo ve spojení s jednoduchým filtrem.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Teď je možné se podívat na data a zjistit, co bylo přečteno. V závislosti na velikosti datové sady je obvykle lepší zkontrolovat data s podmnožinou než úplnou sadou.
Následující kód nabízí dva způsoby zobrazení dat. První způsob je základní. Druhý způsob poskytuje mnohem bohatší prostředí mřížky spolu s možností graficky vizualizovat data.
#sampled_taxi_df.show(5) display(sampled_taxi_df)V závislosti na velikosti vygenerované datové sady a potřebě mnohokrát experimentovat nebo spouštět poznámkový blok můžete chtít datovou sadu ukládat do mezipaměti místně v pracovním prostoru. Existují tři způsoby, jak provést explicitní ukládání do mezipaměti:
- Uložte datový rámec místně jako soubor.
- Uložte datový rámec jako dočasnou tabulku nebo zobrazení.
- Uložte datový rámec jako trvalou tabulku.
První dva z těchto přístupů jsou zahrnuté v následujících příkladech kódu.
Vytvoření dočasné tabulky nebo zobrazení poskytuje různé přístupové cesty k datům, ale trvá jenom po dobu trvání relace instance Sparku.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Příprava dat
Data v nezpracované podobě často nejsou vhodná k předání přímo do modelu. S daty musíte provést řadu akcí, abyste je dostali do stavu, ve kterém je model může využívat.
V následujícím kódu provedete čtyři třídy operací:
- Odebrání odlehlých hodnot nebo nesprávných hodnot prostřednictvím filtrování.
- Odebrání sloupců, které nejsou potřeba.
- Vytvoření nových sloupců odvozených z nezpracovaných dat, aby model fungoval efektivněji. Tato operace se někdy nazývá featurizace.
- Označování. Vzhledem k tomu, že provádíte binární klasifikaci (jestli na dané cestě bude tip nebo ne), je potřeba převést částku tipu na hodnotu 0 nebo 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Potom provedete druhé předání dat a přidáte konečné funkce.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Vytvoření modelu logistické regrese
Posledním úkolem je převést označená data do formátu, který je možné analyzovat prostřednictvím logistické regrese. Vstupem do algoritmu logistické regrese musí být sada dvojic vektorů popisku a funkce, kde vektorem funkce je vektor čísel, které představují vstupní bod.
Takže je potřeba převést sloupce kategorií na čísla. Konkrétně je potřeba převést sloupce a weekdayString na trafficTimeBins celočíselné reprezentace. Existuje několik přístupů k provedení převodu. Následující příklad používá OneHotEncoder přístup, který je běžný.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Výsledkem této akce je nový datový rámec se všemi sloupci ve správném formátu pro trénování modelu.
Trénování modelu logistické regrese
Prvním úkolem je rozdělit datovou sadu na trénovací sadu a testovací nebo ověřovací sadu. Rozdělení je zde libovolné. Experimentujte s různými nastaveními rozdělení a zjistěte, jestli ovlivňují model.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Teď, když jsou k dispozici dva datové rámce, je dalším úkolem vytvořit vzorec modelu a spustit ho pro trénovací datový rámec. Pak můžete provést ověření proti testovacímu datovému rámci. Experimentujte s různými verzemi vzorce modelu, abyste viděli dopad různých kombinací.
Poznámka
Pokud chcete model uložit, přiřaďte oboru prostředků serveru Azure SQL Database roli Přispěvatel dat v objektech blob služby Storage. Podrobný postup najdete v tématu Přiřazování rolí Azure s využitím webu Azure Portal. Tento krok můžou provést jenom členové s oprávněními vlastníka.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
Výstup z této buňky je:
Area under ROC = 0.9779470729751403
Vytvoření vizuální reprezentace predikce
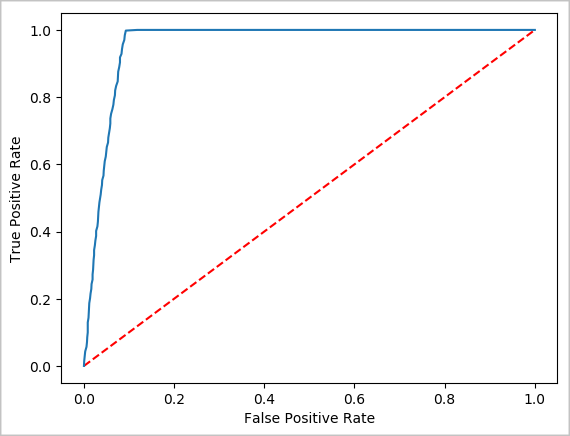
Teď můžete vytvořit konečnou vizualizaci, která vám pomůže zdůvodnění výsledků tohoto testu. Křivka ROC je jedním ze způsobů, jak zkontrolovat výsledek.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Vypnutí instance Sparku
Po spuštění aplikace zavřením karty vypněte poznámkový blok a uvolněte prostředky. Nebo vyberte Ukončit relaci na stavovém panelu v dolní části poznámkového bloku.
Viz také
Další kroky
Poznámka
Některá z oficiální dokumentace k Apache Sparku závisí na použití konzoly Spark, která není k dispozici v Apache Sparku v Azure Synapse Analytics. Místo toho použijte prostředí poznámkového bloku nebo IntelliJ .