Rychlý start: Transformace dat pomocí definice úlohy Apache Spark
V tomto rychlém startu použijete Azure Synapse Analytics k vytvoření kanálu pomocí definice úlohy Apache Spark.
Požadavky
- Předplatné Azure: Pokud nemáte předplatné Azure, vytvořte si před zahájením bezplatný účet Azure.
- Pracovní prostor Azure Synapse: Vytvořte pracovní prostor Synapse pomocí webu Azure Portal podle pokynů v rychlém startu: Vytvoření pracovního prostoru Synapse.
- Definice úlohy Apache Spark: Vytvořte definici úlohy Apache Sparku v pracovním prostoru Synapse podle pokynů v kurzu: Vytvoření definice úlohy Apache Spark v synapse Studiu.
Přejděte do synapse Studia.
Po vytvoření pracovního prostoru Azure Synapse máte dva způsoby, jak otevřít Synapse Studio:
- Otevřete pracovní prostor Synapse na webu Azure Portal. Na kartě Otevřít Synapse Studio v části Začínáme vyberte Otevřít.
- Otevřete Azure Synapse Analytics a přihlaste se ke svému pracovnímu prostoru.
V tomto rychlém startu použijeme jako příklad pracovní prostor s názvem sampletest.
Vytvoření kanálu s definicí úlohy Apache Spark
Kanál obsahuje logický tok pro spuštění sady aktivit. V této části vytvoříte kanál, který obsahuje aktivitu definice úlohy Apache Spark.
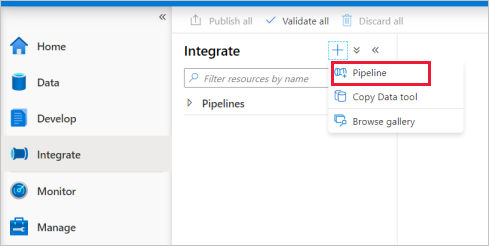
Přejděte na kartu Integrace . Vyberte ikonu plus vedle záhlaví kanálů a vyberte Kanál.
Na stránce Nastavení vlastností kanálu zadejte ukázku pro Název.
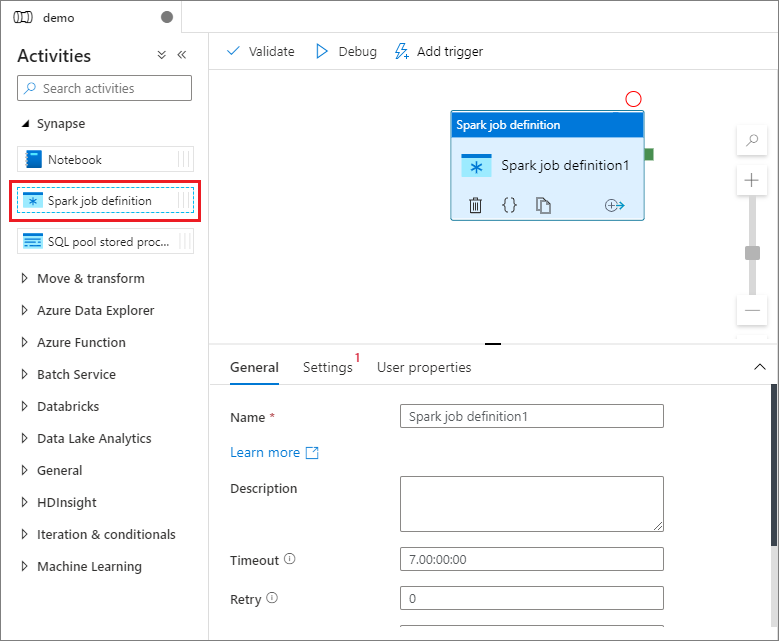
V části Synapse v podokně Aktivity přetáhněte definici úlohy Sparku na plátno kanálu.
Nastavení plátna definice úlohy Apache Sparku
Jakmile vytvoříte definici úlohy Apache Sparku, budete automaticky odesláni na plátno definice úlohy Sparku.
Obecné nastavení
Na plátně vyberte modul definice úlohy Sparku.
Na kartě Obecné zadejte ukázku pro Název.
(Možnost) Můžete také zadat popis.
Časový limit: Maximální doba, po kterou může aktivita běžet. Výchozí hodnota je sedm dní, což je také maximální povolená doba. Formát je ve formátu D.HH:MM:SS.
Opakování: Maximální počet pokusů o opakování
Interval opakování: Počet sekund mezi jednotlivými pokusy o opakování.
Zabezpečený výstup: Při kontrole se výstup z aktivity nezachytí v protokolování.
Zabezpečený vstup: Při kontrole se vstup z aktivity nezachytí v protokolování.
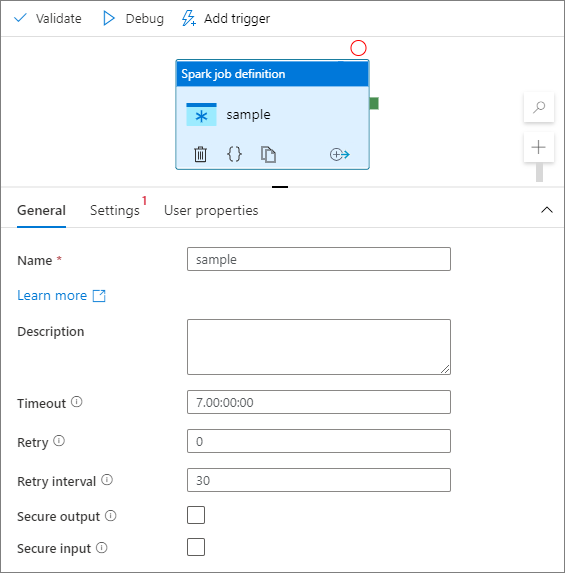
Karta Nastavení
Na tomto panelu můžete odkazovat na definici úlohy Sparku, která se má spustit.
Rozbalte seznam definic úloh Sparku, můžete zvolit existující definici úlohy Apache Sparku. Novou definici úlohy Apache Spark můžete vytvořit také tak , že vyberete tlačítko Nový a odkazujete na definici úlohy Sparku, která se má spustit.
(Volitelné) Můžete vyplnit informace o definici úlohy Apache Spark. Pokud jsou následující nastavení prázdná, použije se ke spuštění nastavení samotné definice úlohy Sparku. Pokud následující nastavení nejsou prázdná, nahradí tato nastavení nastavení samotné definice úlohy Spark.
Vlastnost Popis Hlavní definiční soubor Hlavní soubor použitý pro úlohu. V úložišti vyberte soubor PY/JAR/ZIP. Pokud chcete soubor nahrát do účtu úložiště, vyberte Nahrát soubor .
Ukázka:abfss://…/path/to/wordcount.jarOdkazy z podsložek Prohledání podsložek z kořenové složky hlavního definičního souboru se tyto soubory přidají jako referenční soubory. Složky s názvem "jars", "pyFiles", "files" nebo "archives" se naskenují a v názvu složek se rozlišují malá a velká písmena. Název hlavní třídy Plně kvalifikovaný identifikátor nebo hlavní třída, která je v hlavním definičním souboru.
Ukázka:WordCountArgumenty příkazového řádku Argumenty příkazového řádku můžete přidat kliknutím na tlačítko Nový . Je třeba poznamenat, že přidání argumentů příkazového řádku přepíše argumenty příkazového řádku definované definicí úlohy Spark.
Ukázka:abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultFond Apache Sparku V seznamu můžete vybrat fond Apache Spark. Referenční informace k kódu Pythonu Další soubory kódu Pythonu používané pro referenci v hlavním definičním souboru.
Podporuje předávání souborů (.py, .py3, .zip) do vlastnosti "pyFiles". Přepíše vlastnost "pyFiles" definovanou v definici úlohy Sparku.Referenční soubory Další soubory používané pro odkazování v hlavním definičním souboru. Dynamicky přidělovat exekutory Toto nastavení se mapuje na vlastnost dynamického přidělení v konfiguraci Sparku pro přidělení exekutorů aplikací Sparku. Minimální exekutory Minimální počet exekutorů, které se mají přidělit v zadaném fondu Sparku pro úlohu. Maximální počet exekutorů Maximální počet exekutorů, které se mají přidělit v zadaném fondu Sparku pro úlohu. Velikost ovladače Počet jaderachch Konfigurace Sparku Zadejte hodnoty pro vlastnosti konfigurace Sparku uvedené v článku: Konfigurace Sparku – Vlastnosti aplikace. Uživatelé můžou použít výchozí konfiguraci a přizpůsobenou konfiguraci. 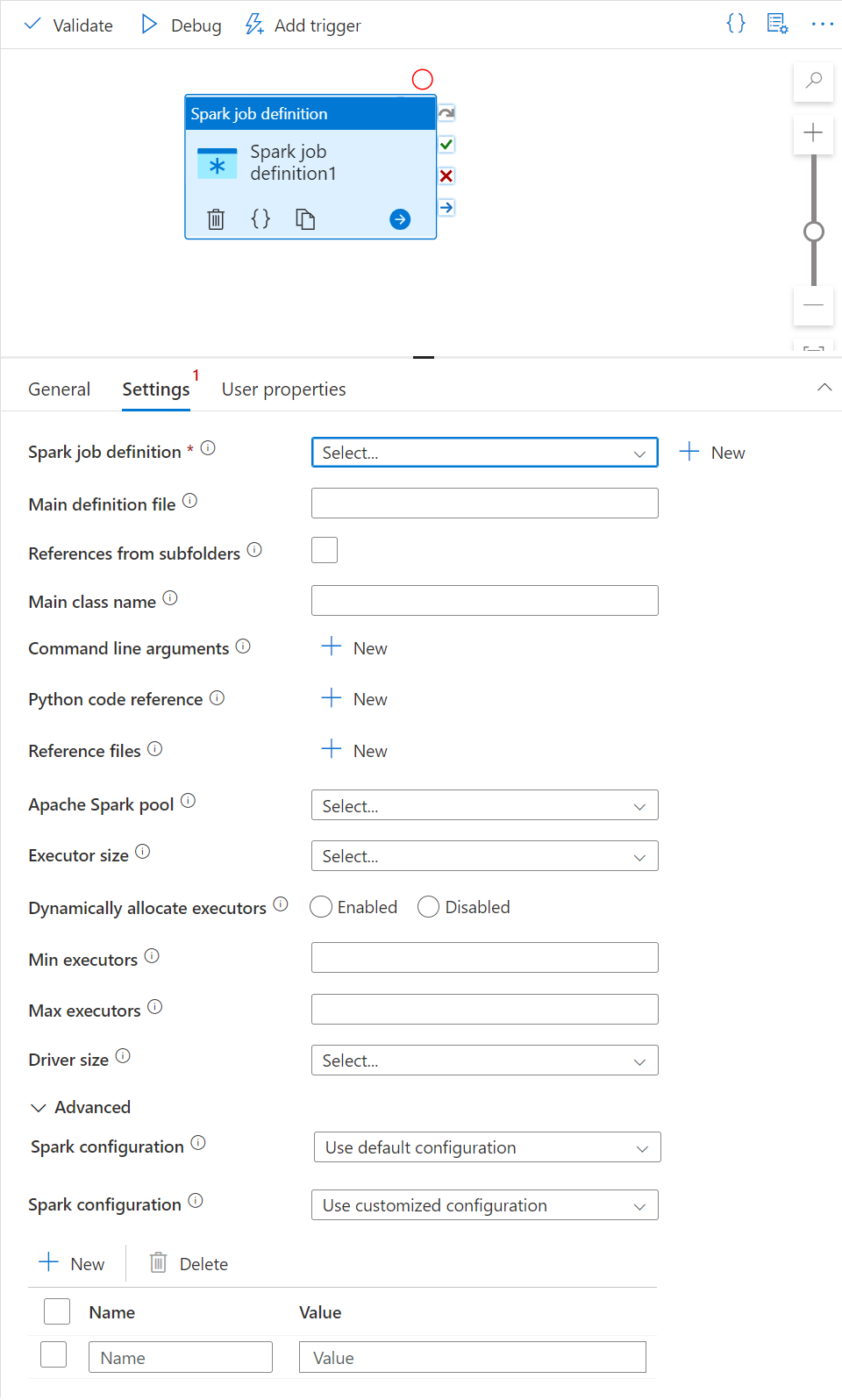
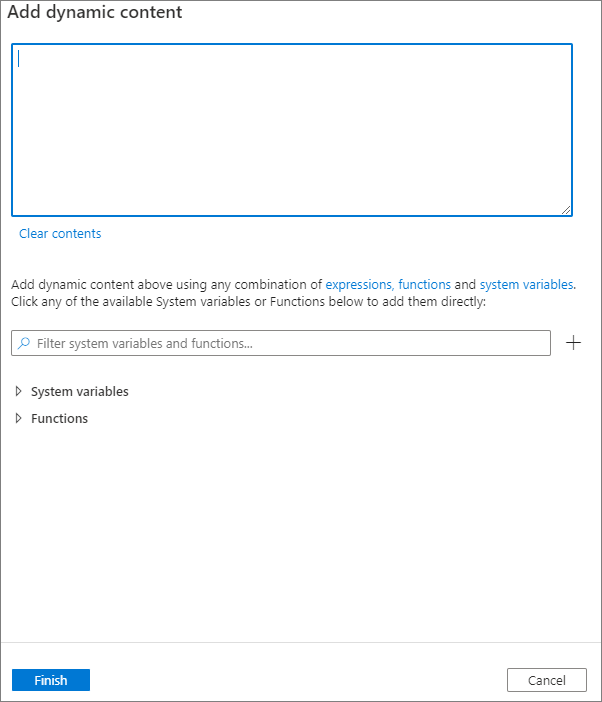
Dynamický obsah můžete přidat kliknutím na tlačítko Přidat dynamický obsah nebo stisknutím klávesové zkratky Alt+Shift+D. Na stránce Přidat dynamický obsah můžete k dynamickému obsahu použít libovolnou kombinaci výrazů, funkcí a systémových proměnných.
Karta Vlastnosti uživatele
Na tomto panelu můžete přidat vlastnosti aktivity definice úlohy Apache Spark.

Související obsah
V následujících článcích se dozvíte o podpoře azure Synapse Analytics: