Rychlý start: Hromadné načítání pomocí nástroje Synapse Studio
Načítání dat je snadné pomocí Průvodce hromadným načtením v nástroji Synapse Studio. Synapse Studio je funkce Azure Synapse Analytics. Průvodce hromadným načtením vás provede vytvořením skriptu T-SQL s příkazem COPY, který hromadně načte data do vyhrazeného fondu SQL.
Vstupní body do průvodce hromadného načtení
Data můžete hromadně načíst tak, že kliknete pravým tlačítkem na následující oblast v rámci nástroje Synapse Studio: soubor nebo složka z účtu úložiště Azure, který je připojený k vašemu pracovnímu prostoru.
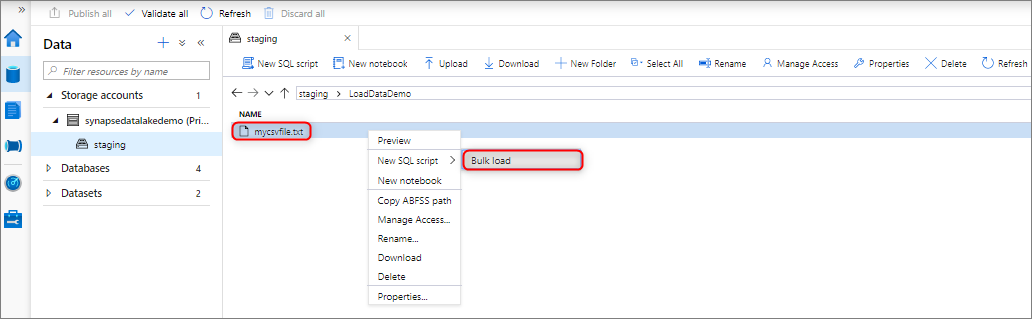
Předpoklady
Průvodce vygeneruje příkaz COPY, který k ověřování používá předávací metodu Microsoft Entra. Váš uživatel Microsoft Entra musí mít přístup k pracovnímu prostoru s alespoň rolí Přispěvatel dat v objektech blob služby Storage pro účet Azure Data Lake Storage Gen2.
Pokud vytváříte novou tabulku, do které chcete načíst, musíte mít požadovaná oprávnění k použití příkazu COPY a vytvořit tabulku.
Propojená služba přidružená k účtu Data Lake Storage Gen2 musí mít přístup k souboru nebo složce , které se mají načíst. Pokud je například mechanismus ověřování pro propojenou službu spravovanou identitou, musí mít spravovaná identita pracovního prostoru k účtu úložiště alespoň oprávnění Čtenář dat objektů blob služby Storage.
Pokud je ve vašem pracovním prostoru povolená virtuální síť, ujistěte se, že integrovaný modul runtime přidružený k propojeným službám účtu Data Lake Storage Gen2 pro zdrojová data a umístění chybového souboru má povolené interaktivní vytváření. Interaktivní vytváření obsahu se vyžaduje pro automatické zjišťování, zobrazení náhledu obsahu zdrojového souboru a procházení účtů úložiště Data Lake Storage Gen2 v průvodci.
Kroky
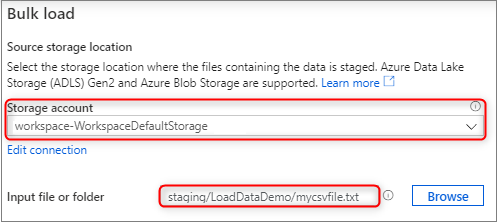
Na panelu Umístění zdrojového úložiště vyberte účet úložiště a soubor nebo složku, ze které načítáte. Průvodce se automaticky pokusí rozpoznat soubory Parquet a textové soubory s oddělovači (CSV), včetně mapování zdrojových polí ze souboru na příslušné cílové datové typy SQL.
Vyberte nastavení formátu souboru, včetně nastavení chyb, pro které se při hromadném načítání zamítnou řádky. Můžete také vybrat náhled dat a podívat se, jak příkaz COPY parsuje soubor, aby vám pomohl nakonfigurovat nastavení formátu souboru. Vyberte Náhled dat při každé změně nastavení formátu souboru, abyste viděli, jak příkaz COPY parsuje soubor s aktualizovaným nastavením.
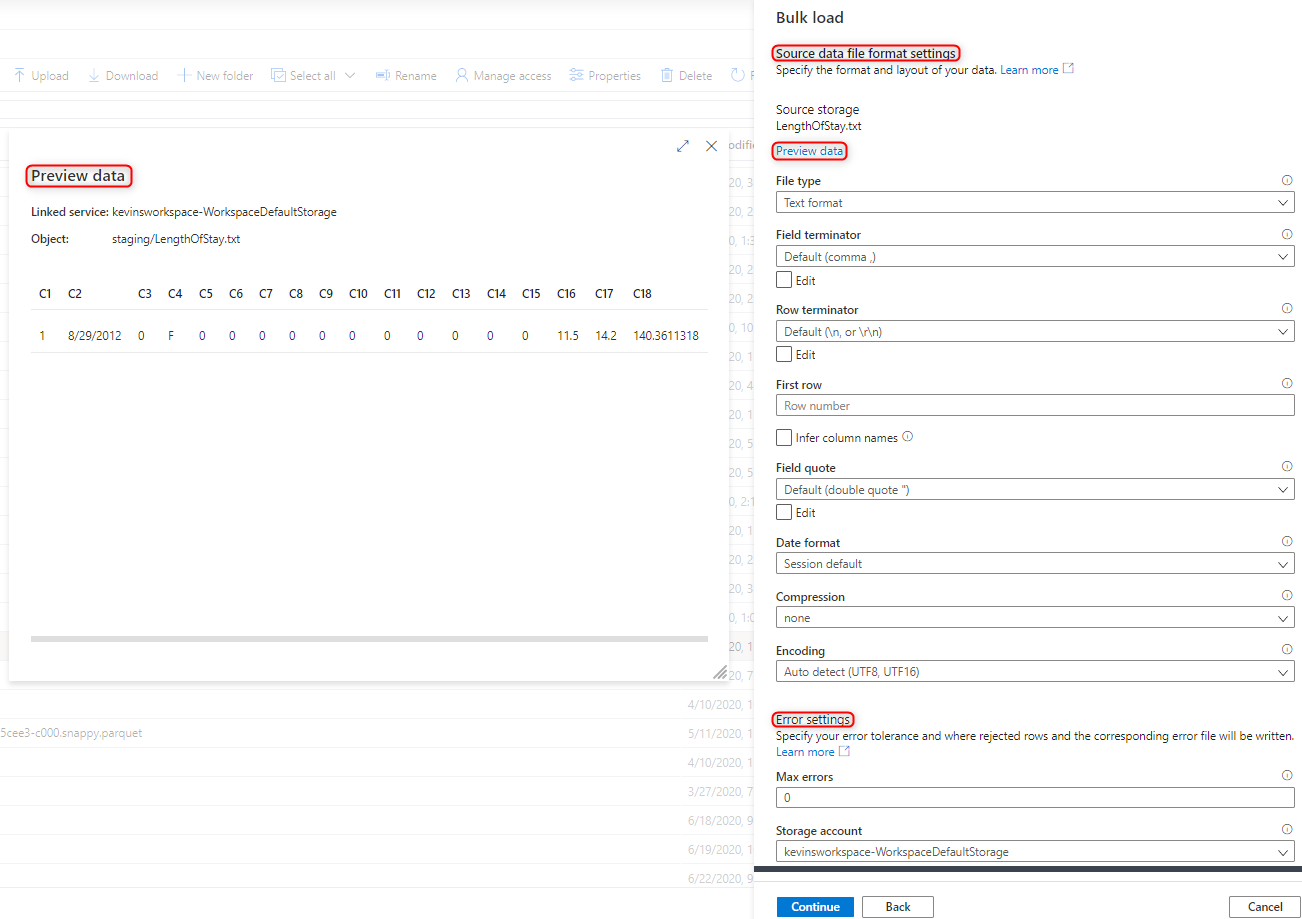
Poznámka:
- Průvodce hromadným načtením nepodporuje zobrazení náhledu dat s ukončovacími znaky víceznakových polí. Když zadáte ukončovací znak víceznakového pole, průvodce zobrazí náhled dat v jednom sloupci.
- Když vyberete Odvozené názvy sloupců, průvodce hromadným načtením analyzuje názvy sloupců z prvního řádku určeného polem prvního řádku . Průvodce hromadným načtením automaticky zvýší
FIRSTROWhodnotu v příkazu COPY o 1, aby tento řádek záhlaví ignoroval. - V příkazu COPY je podporováno zadávání ukončovacích znaků řádku s více znaky. Průvodce hromadným načtením ho ale nepodporuje a vyvolá chybu.
Vyberte vyhrazený fond SQL, který používáte k načtení, včetně toho, jestli bude zatížení pro existující tabulku nebo novou tabulku.
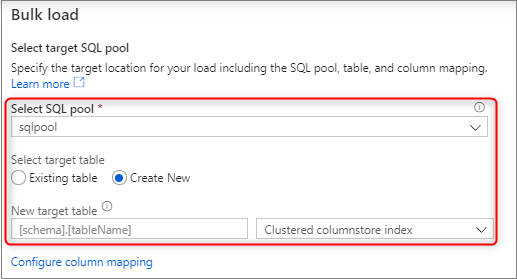
Vyberte Konfigurovat mapování sloupců, abyste měli jistotu, že máte odpovídající mapování sloupců. Názvy sloupců poznámek se rozpoznanou automaticky, pokud jste povolili odvození názvů sloupců. U nových tabulek je konfigurace mapování sloupců důležitá pro aktualizaci datových typů cílových sloupců.
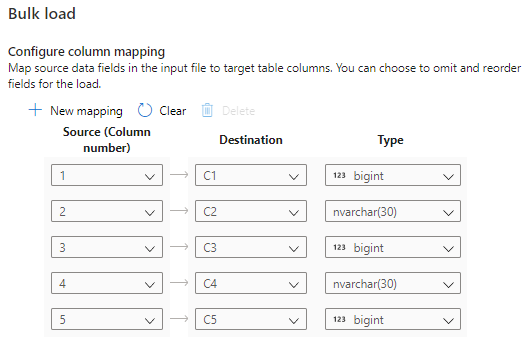
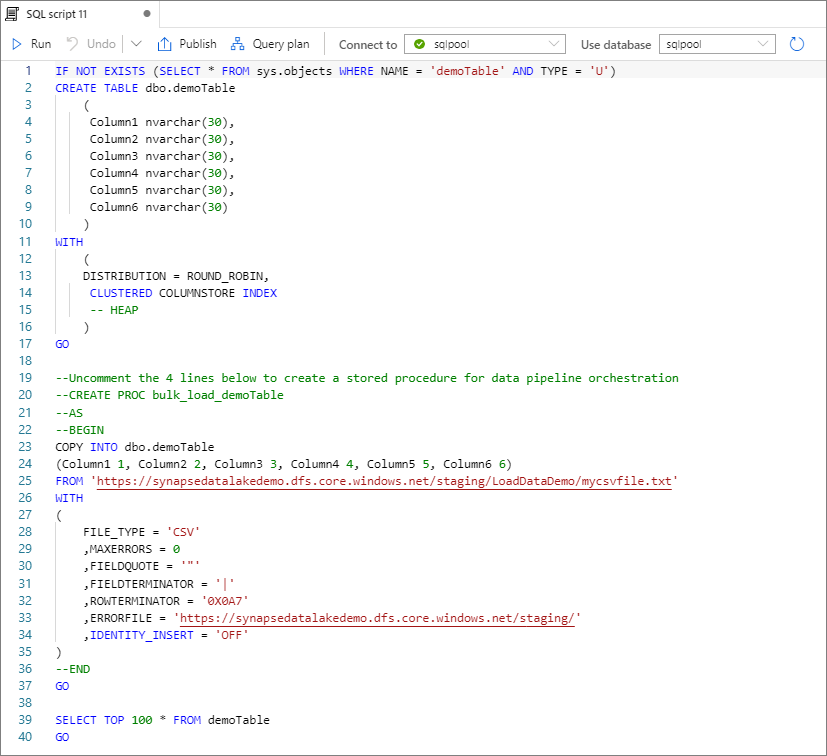
Vyberte Otevřít skript. Skript T-SQL se vygeneruje pomocí příkazu COPY, který se načte z vašeho datového jezera.
Další kroky
- Další informace o možnostech kopírování najdete v článku o příkazu COPY.
- Informace o použití procesu extrakce, transformace a načítání (ETL) najdete v článku s přehledem načítání dat.