Připojení k Azure Data Exploreru s využitím Apache Sparku pro službu Azure Synapse Analytics
Tento článek popisuje, jak získat přístup k databázi Azure Data Exploreru ze sady Synapse Studio pomocí Apache Sparku pro Azure Synapse Analytics.
Předpoklady
- Vytvořte cluster a databázi Azure Data Exploreru.
- Máte existující pracovní prostor Azure Synapse Analytics nebo vytvořte nový pracovní prostor podle kroků v rychlém startu: Vytvoření pracovního prostoru Azure Synapse.
- Vytvořte existující fond Apache Sparku nebo vytvořte nový fond pomocí postupu v rychlém startu: Vytvoření fondu Apache Spark pomocí webu Azure Portal.
- Vytvoření aplikace Microsoft Entra zřízením aplikace Microsoft Entra
- Přidělte aplikaci Microsoft Entra přístup k vaší databázi pomocí postupu v tématu Správa oprávnění databáze Azure Data Exploreru.
Přejít na Synapse Studio
V pracovním prostoru Azure Synapse vyberte Spustit Synapse Studio. Na domovské stránce nástroje Synapse Studio vyberte Data a přejděte do části Data Průzkumník objektů.
Připojení databáze Azure Data Exploreru do pracovního prostoru Azure Synapse
Připojení vytvoření databáze Azure Data Exploreru do pracovního prostoru se provádí prostřednictvím propojené služby. S propojenou službou Azure Data Exploreru můžete procházet a zkoumat data, číst a zapisovat z Apache Sparku pro Azure Synapse. V kanálu můžete také spouštět úlohy integrace.
Z datového Průzkumník objektů pomocí následujícího postupu přímo připojte cluster Azure Data Exploreru:
+ Vyberte ikonu u dat.
Vyberte Připojení pro připojení k externím datům.
Vyberte Azure Data Explorer (Kusto).
Zvolte Pokračovat.
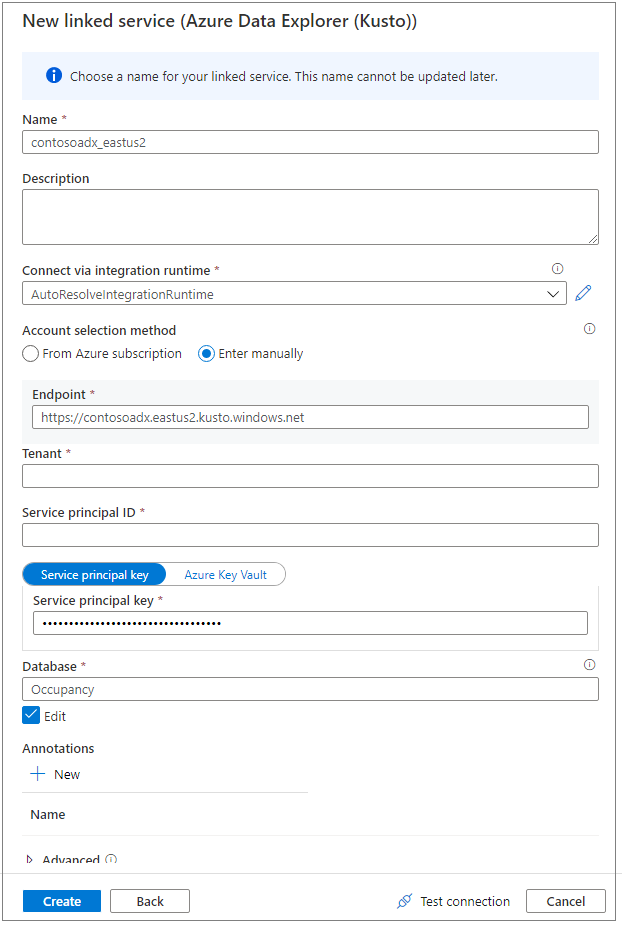
K pojmenování propojené služby použijte popisný název. Název se zobrazí v datovém Průzkumník objektů a používá moduly runtime Azure Synapse pro připojení k databázi.
Vyberte cluster Azure Data Exploreru z vašeho předplatného nebo zadejte identifikátor URI.
Zadejte ID instančního objektu a klíč instančního objektu. Ujistěte se, že má tento instanční objekt přístup k databázi pro operaci čtení a přístup ingestoru pro příjem dat.
Zadejte název databáze Azure Data Exploreru.
Vyberte Test připojení , abyste měli správná oprávnění.
Vyberte Vytvořit.
Poznámka:
(Volitelné) Test připojení neověřuje přístup k zápisu. Ujistěte se, že ID instančního objektu má přístup k zápisu do databáze Azure Data Exploreru.
Clustery a databáze Azure Data Exploreru se zobrazí na kartě Propojení v části Azure Data Explorer .
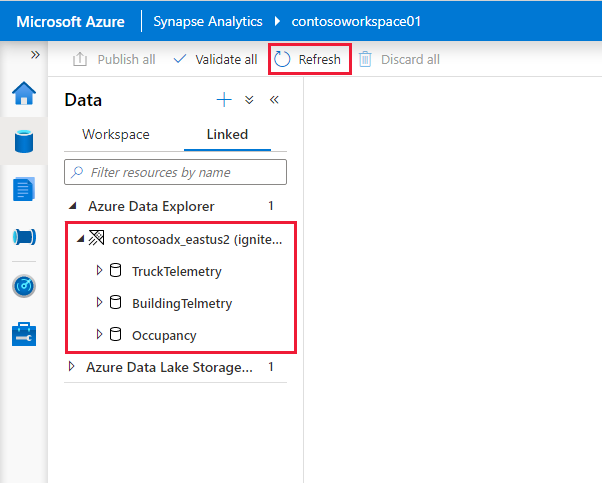
Než budete moct pracovat s propojenou službou z poznámkového bloku, musíte ji publikovat do pracovního prostoru. Klepněte na tlačítko Publikovat na panelu nástrojů, zkontrolujte čekající změny a klepněte na tlačítko OK.
Poznámka:
V aktuální verzi se databázové objekty vyplní na základě oprávnění účtu Microsoft Entra k databázím Azure Data Exploreru. Když spustíte poznámkové bloky Nebo úlohy integrace Apache Sparku, použijí se přihlašovací údaje ve službě propojení (například instanční objekt).
Rychlá interakce s akcemi generovanými kódem
Když kliknete pravým tlačítkem myši na databázi nebo tabulku, zobrazí se seznam ukázkových poznámkových bloků Sparku. Vyberte možnost čtení, zápisu nebo streamování dat do Azure Data Exploreru.

Tady je příklad čtení dat. Připojte poznámkový blok k fondu Sparku a spusťte buňku.

Poznámka:
První spuštění může trvat déle než tři minuty, než zahájí relaci Sparku. Následná spuštění budou výrazně rychlejší.
Omezení
Konektor Azure Data Exploreru se v současné době nepodporuje u virtuálních sítí spravovaných službou Azure Synapse.