Migrace dat, ETL a načítání pro migrace Oracle
Tento článek je druhou částí sedmidílné série, která obsahuje pokyny k migraci z Oracle na Azure Synapse Analytics. Tento článek se zaměřuje na osvědčené postupy pro ETL a migraci zatížení.
Aspekty migrace dat
Při migraci dat, ETL a načítání ze staršího datového skladu Oracle a datových mart do Azure Synapse je potřeba vzít v úvahu mnoho faktorů.
Počáteční rozhodnutí o migraci dat z Oracle
Při plánování migrace z existujícího prostředí Oracle zvažte následující otázky související s daty:
Měly by se migrovat nepoužívané struktury tabulek?
Jaký je nejlepší přístup k migraci, který minimalizuje riziko a dopad na uživatele?
Při migraci datových mart: zůstaňte fyzicky nebo virtuální?
V dalších částech jsou tyto body popsány v kontextu migrace z Oracle.
Chcete migrovat nepoužívané tabulky?
Je vhodné migrovat jenom používané tabulky. Tabulky, které nejsou aktivní, je možné místo migrace archivovat, aby byla data v budoucnu dostupná. Nejlepší je použít systémová metadata a soubory protokolů místo dokumentace k určení, které tabulky se používají, protože dokumentace může být zahlcená.
Tabulky a protokoly systémového katalogu Oracle obsahují informace, které se dají použít k určení, kdy byla daná tabulka naposledy přístupná – která se pak dá použít k rozhodnutí, jestli je tabulka kandidátem na migraci.
Pokud jste licencovali sadu Oracle Diagnostic Pack, máte přístup k historii aktivní relace, kterou můžete použít k určení, kdy byla tabulka naposledy přístupná.
Tip
Ve starších systémech není neobvyklé, že se tabulky v průběhu času stanou redundantními – ve většině případů je není potřeba migrovat.
Tady je příklad dotazu, který hledá použití konkrétní tabulky v daném časovém intervalu:
SELECT du.username,
s.sql_text,
MAX(ash.sample_time) AS last_access ,
sp.object_owner ,
sp.object_name ,
sp.object_alias as aliased_as ,
sp.object_type ,
COUNT(*) AS access_count
FROM v$active_session_history ash
JOIN v$sql s ON ash.force_matching_signature = s.force_matching_signature
LEFT JOIN v$sql_plan sp ON s.sql_id = sp.sql_id
JOIN DBA_USERS du ON ash.user_id = du.USER_ID
WHERE ash.session_type = 'FOREGROUND'
AND ash.SQL_ID IS NOT NULL
AND sp.object_name IS NOT NULL
AND ash.user_id <> 0
GROUP BY du.username,
s.sql_text,
sp.object_owner,
sp.object_name,
sp.object_alias,
sp.object_type
ORDER BY 3 DESC;
Spuštění tohoto dotazu může chvíli trvat, pokud jste spustili řadu dotazů.
Jaký je nejlepší přístup k migraci, který minimalizuje riziko a dopad na uživatele?
Tato otázka se často objevuje, protože společnosti můžou chtít snížit dopad změn na datový model datového skladu, aby se zlepšila flexibilita. Společnosti často vidí příležitost k další modernizaci nebo transformaci dat během migrace ETL. Tento přístup přináší vyšší riziko, protože současně mění více faktorů, což ztěžuje porovnání výsledků starého systému a nových. Provádění změn datového modelu zde může mít vliv také na upstreamové nebo podřízené úlohy ETL do jiných systémů. Z tohoto rizika je lepší po migraci datového skladu přepracovat toto škálování.
I když se datový model záměrně mění v rámci celkové migrace, je vhodné stávající model migrovat tak, jak je, do Azure Synapse, a ne provádět žádné změny přípravy na nové platformě. Tento přístup minimalizuje vliv na stávající produkční systémy a zároveň přináší výhody z výkonu a elastické škálovatelnosti platformy Azure pro jednorázové opětovné technické úlohy.
Tip
Migrujte stávající model tak, jak je na začátku, i když je v budoucnu naplánována změna datového modelu.
Migrace datového tržiště: Zůstaňte fyzicky nebo virtuální?
Ve starších prostředích datového skladu Oracle je běžné vytvářet mnoho datových mart, která jsou strukturovaná tak, aby poskytovala dobrý výkon pro ad hoc samoobslužné dotazy a sestavy pro dané oddělení nebo obchodní funkci v rámci organizace. Datové tržiště se obvykle skládá z podmnožina datového skladu, která obsahuje agregované verze dat ve formě, která uživatelům umožňuje snadno dotazovat tato data pomocí rychlé doby odezvy. Uživatelé můžou používat uživatelsky přívětivé nástroje pro dotazy, jako je Microsoft Power BI, které podporují interakci podnikových uživatelů s datovými tržištěmi. Forma dat v datovém tržiště je obecně dimenzionálním datovým modelem. Jedním z použití datových mart je zveřejnění dat v použitelné podobě, i když je podkladový datový model skladu něco jiného, například trezor dat.
K implementaci robustních režimů zabezpečení dat můžete použít samostatná datová tržiště pro jednotlivé organizační jednotky v rámci organizace. Omezte přístup k určitým datovým martům, která jsou relevantní pro uživatele, a odstraňte, obfuskujte nebo anonymizujte citlivá data.
Pokud jsou tato datová tržiště implementovaná jako fyzické tabulky, budou k jejich pravidelnému sestavování a aktualizaci vyžadovat další prostředky úložiště a zpracování. Data v tržiště budou také aktuální jenom jako poslední operace aktualizace, takže nemusí být vhodná pro vysoce nestálé datové řídicí panely.
Tip
Virtualizace datových mart může ušetřit na prostředcích úložiště a zpracování.
S nástupem škálovatelných architektur MPP s nižšími náklady, jako je Azure Synapse, a jejich vlastní charakteristiky výkonu, můžete poskytovat funkce datového tržiště bez vytvoření instance tržiště jako sady fyzických tabulek. Jednou z metod je efektivní virtualizace datových mart prostřednictvím zobrazení SQL do hlavního datového skladu. Dalším způsobem je virtualizovat datová tržiště prostřednictvím vrstvy virtualizace pomocí funkcí, jako jsou zobrazení v Azure nebo virtualizačních produktech třetích stran . Tento přístup zjednodušuje nebo eliminuje potřebu dodatečného zpracování úložiště a agregace a snižuje celkový počet databázových objektů, které se mají migrovat.
Existuje další potenciální výhoda tohoto přístupu. Implementací logiky agregace a spojení v rámci vrstvy virtualizace a prezentováním externích nástrojů pro vytváření sestav prostřednictvím virtualizovaného zobrazení se zpracování potřebné k vytvoření těchto zobrazení odešle do datového skladu. Datový sklad je obecně nejlepším místem pro spouštění spojení, agregací a dalších souvisejících operací s velkými objemy dat.
Primárními ovladači pro implementaci virtuálního datového tržiště přes fyzické datové tržiště jsou:
Větší flexibilita: Virtuální datové tržiště se snadněji mění než fyzické tabulky a přidružené procesy ETL.
Nižší celkové náklady na vlastnictví: Virtualizovaná implementace vyžaduje méně úložišť dat a kopií dat.
Odstranění úloh ETL pro migraci a zjednodušení architektury datového skladu ve virtualizovaném prostředí
Výkon: Přestože fyzická datová tržiště dříve fungovala lépe, virtualizační produkty teď implementují inteligentní techniky ukládání do mezipaměti, které tento rozdíl zmírňují.
Tip
Výkon a škálovatelnost Služby Azure Synapse umožňuje virtualizaci bez snížení výkonu.
Migrace dat z Oracle
Pochopení vašich dat
V rámci plánování migrace byste měli podrobně porozumět objemu dat, která se mají migrovat, protože to může mít vliv na rozhodnutí o přístupu k migraci. Pomocí systémových metadat můžete určit fyzické místo, které zabírají nezpracovaná data v tabulkách, které se mají migrovat. V tomto kontextu nezpracovaná data znamenají množství místa používaného řádky dat v tabulce, s výjimkou režijních nákladů, jako jsou indexy a komprese. Největší tabulky faktů obvykle obsahují více než 95 % dat.
Tento dotaz vám poskytne celkovou velikost databáze v Oracle:
SELECT
( SELECT SUM(bytes)/1024/1024/1024 data_size
FROM sys.dba_data_files ) +
( SELECT NVL(sum(bytes),0)/1024/1024/1024 temp_size
FROM sys.dba_temp_files ) +
( SELECT SUM(bytes)/1024/1024/1024 redo_size
FROM sys.v_$log ) +
( SELECT SUM(BLOCK_SIZE*FILE_SIZE_BLKS)/1024/1024/1024 controlfile_size
FROM v$controlfile ) "Size in GB"
FROM dual
Velikost databáze se rovná velikosti (data files + temp files + online/offline redo log files + control files). Celková velikost databáze zahrnuje využité místo a volné místo.
Následující příklad dotazu poskytuje rozpis místa na disku používaného daty tabulek a indexy:
SELECT
owner, "Type", table_name "Name", TRUNC(sum(bytes)/1024/1024) Meg
FROM
( SELECT segment_name table_name, owner, bytes, 'Table' as "Type"
FROM dba_segments
WHERE segment_type in ('TABLE','TABLE PARTITION','TABLE SUBPARTITION' )
UNION ALL
SELECT i.table_name, i.owner, s.bytes, 'Index' as "Type"
FROM dba_indexes i, dba_segments s
WHERE s.segment_name = i.index_name
AND s.owner = i.owner
AND s.segment_type in ('INDEX','INDEX PARTITION','INDEX SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.segment_name
AND s.owner = l.owner
AND s.segment_type IN ('LOBSEGMENT','LOB PARTITION','LOB SUBPARTITION')
UNION ALL
SELECT l.table_name, l.owner, s.bytes, 'LOB Index' as "Type"
FROM dba_lobs l, dba_segments s
WHERE s.segment_name = l.index_name
AND s.owner = l.owner
AND s.segment_type = 'LOBINDEX')
WHERE owner in UPPER('&owner')
GROUP BY table_name, owner, "Type"
HAVING SUM(bytes)/1024/1024 > 10 /* Ignore really small tables */
ORDER BY SUM(bytes) desc;
Kromě toho tým pro migraci databází Microsoftu poskytuje mnoho prostředků, včetně artefaktů skriptu inventáře Oracle. Nástroj Artefakty skriptu inventáře Oracle obsahuje dotaz PL/SQL, který přistupuje k systémovým tabulkám Oracle a poskytuje počet objektů podle typu schématu, typu objektu a stavu. Nástroj také poskytuje hrubý odhad nezpracovaných dat v každém schématu a velikost tabulek v každém schématu s výsledky uloženými ve formátu CSV. Zahrnutá tabulka kalkulačky přebírá jako vstup sdílený svazek clusteru a poskytuje data velikosti.
U jakékoli tabulky můžete přesně odhadnout objem dat, která je potřeba migrovat, extrahováním reprezentativního vzorku dat, například jednoho milionu řádků, do nekomprimovaného plochého datového souboru ASCII s oddělovači. Potom pomocí velikosti tohoto souboru získáte průměrnou nezpracovanou velikost dat na řádek. Nakonec vynásobte průměrnou velikost celkovým počtem řádků v celé tabulce, aby se pro tabulku dala nezpracovaná data. V plánování použijte tuto nezpracovanou velikost dat.
Použití dotazů SQL k vyhledání datových typů
Dotazováním zobrazení statického slovníku DBA_TAB_COLUMNS dat Oracle můžete určit, které datové typy se používají ve schématu a jestli je potřeba některý z těchto datových typů změnit. Pomocí dotazů SQL vyhledejte sloupce v libovolném schématu Oracle s datovými typy, které se nemapují přímo na datové typy v Azure Synapse. Podobně můžete pomocí dotazů spočítat počet výskytů každého datového typu Oracle, který se nemapuje přímo na Azure Synapse. Pomocí výsledků z těchto dotazů v kombinaci s tabulkou porovnání datových typů můžete určit, které datové typy je potřeba změnit v prostředí Azure Synapse.
Pokud chcete najít sloupce s datovými typy, které se nemapují na datové typy v Azure Synapse, spusťte následující dotaz po nahrazení <owner_name> příslušným vlastníkem schématu:
SELECT owner, table_name, column_name, data_type
FROM dba_tab_columns
WHERE owner in ('<owner_name>')
AND data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
ORDER BY 1,2,3;
Pokud chcete spočítat počet nemapovatelných datových typů, použijte následující dotaz:
SELECT data_type, count(*)
FROM dba_tab_columns
WHERE data_type NOT IN
('BINARY_DOUBLE', 'BINARY_FLOAT', 'CHAR', 'DATE', 'DECIMAL', 'FLOAT', 'LONG', 'LONG RAW', 'NCHAR', 'NUMERIC', 'NUMBER', 'NVARCHAR2', 'SMALLINT', 'RAW', 'REAL', 'VARCHAR2', 'XML_TYPE')
GROUP BY data_type
ORDER BY data_type;
Microsoft nabízí Pomocník s migrací SQL Serveru (SSMA) pro Oracle k automatizaci migrace datových skladů ze starších prostředí Oracle, včetně mapování datových typů. Službu Azure Database Migration Services můžete použít také k plánování a migraci z prostředí, jako je Oracle. Dodavatelé třetích stran také nabízejí nástroje a služby pro automatizaci migrace. Pokud už nástroj ETL třetí strany používáte v prostředí Oracle, můžete tento nástroj použít k implementaci všech požadovaných transformací dat. V další části se seznámíte s migrací stávajících procesů ETL.
Aspekty migrace ETL
Počáteční rozhodnutí o migraci Oracle ETL
Pro zpracování ETL/ELT starší datové sklady Oracle často používají vlastní skripty, nástroje ETL třetích stran nebo kombinaci přístupů, které se v průběhu času vyvinuly. Při plánování migrace do Azure Synapse určete nejlepší způsob implementace požadovaného zpracování ETL/ELT v novém prostředí a zároveň minimalizaci nákladů a rizik.
Tip
Naplánujte přístup k migraci ETL předem a podle potřeby využijte zařízení Azure.
Následující vývojový diagram shrnuje jeden přístup:
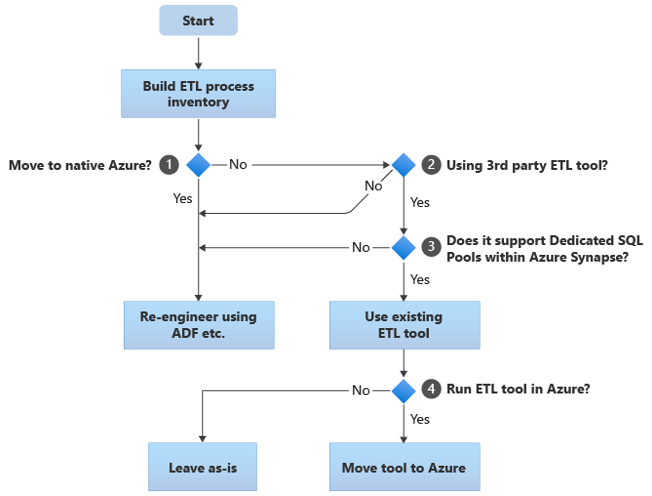
Jak je znázorněno v vývojovém diagramu, počátečním krokem je vždy sestavení inventáře procesů ETL/ELT, které je potřeba migrovat. U standardních integrovaných funkcí Azure nemusí některé existující procesy přesouvat. Pro účely plánování je důležité pochopit rozsah migrace. Dále zvažte otázky v rozhodovacím stromu vývojového diagramu:
Přejít do nativního Azure? Odpověď závisí na tom, jestli migrujete do zcela nativního prostředí Azure. Pokud ano, doporučujeme přepracovat zpracování ETL pomocí kanálů a aktivit v kanálech Azure Data Factory nebo Azure Synapse.
Používáte nástroj ETL třetí strany? Pokud nepřesouváte do zcela nativního prostředí Azure, zkontrolujte, jestli se už používá existující nástroj ETL třetích stran . V prostředí Oracle můžete zjistit, že některé nebo všechny zpracování ETL provádí vlastní skripty pomocí nástrojů specifických pro Oracle, jako je Oracle SQL Developer, Oracle SQL*Loader nebo Oracle Data Pump. V tomto případě je potřeba znovu provést analýzu pomocí azure Data Factory.
Podporuje třetí strana vyhrazené fondy SQL v rámci Azure Synapse? Zvažte, jestli existují velké investice do dovedností v nástroji ETL třetích stran, nebo jestli tento nástroj používají existující pracovní postupy a plány. Pokud ano, určete, jestli nástroj může efektivně podporovat Azure Synapse jako cílové prostředí. V ideálním případě bude nástroj obsahovat nativní konektory, které můžou používat zařízení Azure, jako je PolyBase nebo COPY INTO , pro nejúčinnější načítání dat. I bez nativních konektorů ale obecně existuje způsob, jak volat externí procesy, jako je PolyBase nebo
COPY INTO, a předávat příslušné parametry. V tomto případě použijte stávající dovednosti a pracovní postupy s Azure Synapse jako novým cílovým prostředím.Pokud pro zpracování ELT používáte integrátor dat Oracle , potřebujete znalostní moduly ODI pro Azure Synapse. Pokud vám tyto moduly nejsou ve vaší organizaci k dispozici, ale máte ODI, můžete k vygenerování plochých souborů použít ODI. Tyto ploché soubory je pak možné přesunout do Azure a ingestovat je do Azure Data Lake Storage pro načtení do Azure Synapse.
Spouštíte nástroje ETL v Azure? Pokud se rozhodnete zachovat existující nástroj ETL třetí strany, můžete tento nástroj spustit v prostředí Azure (nikoli na existujícím místním serveru ETL) a nechat službu Data Factory zpracovat celkovou orchestraci existujících pracovních postupů. Proto se rozhodněte, jestli stávající nástroj necháte spuštěný tak, jak je, nebo ho přesunete do prostředí Azure, abyste dosáhli výhod nákladů, výkonu a škálovatelnosti.
Tip
Zvažte spuštění nástrojů ETL v Azure za účelem využití výhod výkonu, škálovatelnosti a nákladů.
Opětovné zkonstruování existujících skriptů specifických pro Oracle
Pokud některé nebo všechny existující zpracování ETL/ELT skladu Oracle zpracovává vlastní skripty, které používají nástroje specifické pro Oracle, jako jsou Oracle SQL*Plus, Oracle SQL Developer, Oracle SQL*Loader nebo Oracle Data Pump, musíte tyto skripty pro prostředí Azure Synapse překódovat. Podobně platí, že pokud byly procesy ETL implementovány pomocí uložených procedur v Oracle, musíte tyto procesy překódovat.
Některé prvky procesu ETL se dají snadno migrovat, například jednoduchým hromadným načtením dat do pracovní tabulky z externího souboru. Tyto části procesu je možné dokonce automatizovat, například pomocí Azure Synapse COPY INTO nebo PolyBase místo SQL*Loaderu. Další části procesu, které obsahují libovolné složité procedury SQL a/nebo uložené procedury, budou trvat delší dobu, než se překonstruují.
Tip
Inventář úloh ETL, které se mají migrovat, by měly zahrnovat skripty a uložené procedury.
Jedním ze způsobů, jak otestovat Oracle SQL kvůli kompatibilitě s Azure Synapse, je zachytit některé reprezentativní příkazy SQL z spojení Oracle v$active_session_history a v$sql získat sql_text, a pak předponovat tyto dotazy EXPLAIN. Za předpokladu, že migrovaný datový model podobný jako v Azure Synapse spustíte tyto EXPLAIN příkazy v Azure Synapse. Jakékoli nekompatibilní SQL zobrazí chybu. Tyto informace můžete použít k určení měřítka úlohy přepočítávání.
Tip
Umožňuje EXPLAIN najít nekompatibilitu SQL.
V nejhorším případě může být nutné ruční přepočítávání. K dispozici jsou ale produkty a služby od partnerů Microsoftu, které pomáhají s opětovným inženýrstvím kódu specifického pro Oracle.
Tip
Partneři nabízejí produkty a dovednosti, které vám pomůžou s opětovným inženýrstvím kódu specifického pro Oracle.
Použití existujících nástrojů ETL třetích stran
V mnoha případech se stávající starší systém datového skladu již naplní a udržuje produktem ETL třetí strany. Seznam aktuálních partnerů microsoftu pro integraci dat pro Azure Synapse najdete v tématu Partneři pro integraci dat Azure Synapse pro Azure Synapse.
Komunita Oracle často používá několik oblíbených produktů ETL. V následujících odstavcích jsou popsány nejoblíbenější nástroje ETL pro sklady Oracle. Všechny tyto produkty můžete spouštět na virtuálním počítači v Azure a používat je ke čtení a zápisu databází a souborů Azure.
Tip
Využijte investice do stávajících nástrojů třetích stran ke snížení nákladů a rizik.
Načítání dat z Oracle
Možnosti dostupné při načítání dat z Oracle
Při přípravě na migraci dat z datového skladu Oracle se rozhodněte, jak se budou data fyzicky přesouvat z existujícího místního prostředí do Azure Synapse v cloudu a jaké nástroje se použijí k provedení přenosu a načítání. Podívejte se na následující otázky, které jsou popsány v následujících částech.
Extrahujete data do souborů nebo je přesunete přímo přes síťové připojení?
Orchestrujete proces ze zdrojového systému nebo z cílového prostředí Azure?
Které nástroje použijete k automatizaci a správě procesu migrace?
Přenos dat prostřednictvím souborů nebo síťového připojení?
Po vytvoření databázových tabulek, které se mají migrovat v Azure Synapse, můžete přesunout data, která naplní tyto tabulky ze staršího systému Oracle a do nového prostředí. Existují dva základní přístupy:
Extrakce souboru: Extrahujte data z tabulek Oracle do plochých souborů s oddělovači, obvykle ve formátu CSV. Data tabulky můžete extrahovat několika způsoby:
- Používejte standardní nástroje Oracle, jako jsou SQL*Plus, SQL Developer a SQLcl.
- Pomocí integrátoru dat Oracle (ODI) vygenerujte ploché soubory.
- Pomocí konektoru Oracle ve službě Data Factory můžete tabulky Oracle paralelně uvolnit, abyste umožnili načítání dat podle oddílů.
- Použijte nástroj ETL třetí strany.
Příklady extrakce dat tabulky Oracle najdete v dodatku k článku.
Tento přístup vyžaduje místo k vytvoření extrahovaných datových souborů. Prostor může být místní pro zdrojovou databázi Oracle, pokud je k dispozici dostatečné úložiště nebo vzdálené ve službě Azure Blob Storage. Nejlepšího výkonu dosáhnete, když se soubor zapíše místně, protože se tím zabrání režijním nákladům na síť.
Pokud chcete minimalizovat požadavky na úložiště a přenos sítě, komprimujte extrahované datové soubory pomocí nástroje, jako je gzip.
Po extrakci přesuňte ploché soubory do služby Azure Blob Storage. Microsoft nabízí různé možnosti pro přesun velkých objemů dat, mezi které patří:
- AzCopy pro přesun souborů přes síť do Azure Storage
- Azure ExpressRoute pro přesun hromadných dat přes privátní síťové připojení.
- Azure Data Box pro přesun souborů do fyzického úložného zařízení, které odesíláte do datového centra Azure pro načítání.
Další informace najdete v tématu Přenos dat do a z Azure.
Přímé extrahování a načítání přes síť: cílové prostředí Azure odesílá požadavek na extrakci dat, obvykle prostřednictvím příkazu SQL, do staršího systému Oracle, aby extrahovali data. Výsledky se odesílají přes síť a načtou se přímo do Azure Synapse, aniž by bylo nutné přikládat data do zprostředkujících souborů. Limitující faktor v tomto scénáři je obvykle šířka pásma síťového připojení mezi databází Oracle a prostředím Azure. U mimořádně velkých objemů dat nemusí být tento přístup praktický.
Tip
Seznamte se s objemy dat, které se mají migrovat, a dostupnou šířku pásma sítě, protože tyto faktory ovlivňují rozhodování o přístupu k migraci.
Existuje také hybridní přístup, který používá obě metody. Můžete například použít přímý přístup k extrakci sítě pro menší tabulky dimenzí a ukázky větších tabulek faktů a rychle poskytnout testovací prostředí v Azure Synapse. U velkých objemových historických tabulek faktů můžete použít přístup k extrakci a přenosu souborů pomocí Azure Data Boxu.
Orchestrace z Oracle nebo Azure?
Doporučeným přístupem při přechodu na Azure Synapse je orchestrace extrakce a načítání dat z prostředí Azure pomocí SSMA nebo Data Factory. Pro nejúčinnější načítání dat použijte přidružené nástroje, jako je PolyBase nebo COPY INTO. Tento přístup přináší výhody integrovaných funkcí Azure a snižuje úsilí o vytváření opakovaně použitelných kanálů načítání dat. K automatizaci procesu migrace můžete použít kanály načítání dat řízené metadaty.
Doporučený přístup také minimalizuje výkon stávajícího prostředí Oracle během procesu načítání dat, protože proces správy a načítání běží v Azure.
Existující nástroje pro migraci dat
Transformace a přesun dat je základní funkcí všech produktů ETL. Pokud se nástroj pro migraci dat už používá v existujícím prostředí Oracle a jako cílové prostředí podporuje Azure Synapse, zvažte použití nástroje ke zjednodušení migrace dat.
I když stávající nástroj ETL není zavedený, partneři azure Synapse Analytics pro integraci dat nabízejí nástroje ETL pro zjednodušení úlohy migrace dat.
A konečně, pokud plánujete použít nástroj ETL, zvažte spuštění tohoto nástroje v prostředí Azure, abyste využili výhod výkonu, škálovatelnosti a nákladů v cloudu Azure. Tento přístup také uvolní prostředky v datovém centru Oracle.
Shrnutí
Abychom mohli shrnout, naše doporučení pro migraci dat a přidružených procesů ETL z Oracle do Azure Synapse jsou:
Naplánujte si předem, abyste zajistili úspěšné cvičení migrace.
Vytvořte podrobný inventář dat a procesů, které se mají migrovat co nejdříve.
Pomocí systémových metadat a souborů protokolů získáte přesné znalosti o využití dat a procesů. Nespoléhejte na dokumentaci, protože možná není aktuální.
Seznamte se s objemy dat, které se mají migrovat, a šířku pásma sítě mezi místním datovým centrem a cloudovými prostředími Azure.
Zvažte použití instance Oracle na virtuálním počítači Azure jako krokovací kámen pro přesměrování migrace ze starší verze prostředí Oracle.
Použití standardních integrovaných funkcí Azure k minimalizaci úloh migrace
Identifikujte a seznamte se s nejúčinnějšími nástroji pro extrakci a načítání dat v prostředích Oracle i Azure. V každé fázi procesu použijte příslušné nástroje.
Pomocí zařízení Azure, jako je Data Factory, můžete orchestrovat a automatizovat proces migrace a zároveň minimalizovat dopad na systém Oracle.
Příloha: Příklady technik pro extrakci dat Oracle
Při migraci z Oracle do Azure Synapse můžete použít několik technik k extrakci dat Oracle. Následující části ukazují, jak extrahovat data Oracle pomocí Oracle SQL Developer a konektoru Oracle ve službě Data Factory.
Použití Oracle SQL Developer k extrakci dat
Pomocí uživatelského rozhraní Oracle SQL Developer UI můžete exportovat data tabulky do mnoha formátů, včetně csv, jak je znázorněno na následujícím snímku obrazovky:

Mezi další možnosti exportu patří JSON a XML. Pomocí uživatelského rozhraní můžete přidat sadu názvů tabulek do košíku a pak použít export na celou sadu v košíku:

K exportu dat Oracle můžete použít také Oracle SQL Developer Command Line (SQLcl). Tato možnost podporuje automatizaci pomocí skriptu prostředí.
U relativně malých tabulek může být tato technika užitečná, pokud narazíte na problémy s extrahováním dat přes přímé připojení.
Použití konektoru Oracle ve službě Azure Data Factory pro paralelní kopírování
Konektor Oracle ve službě Data Factory můžete použít k paralelnímu uvolnění velkých tabulek Oracle. Konektor Oracle poskytuje integrované dělení dat pro paralelní kopírování dat z Oracle. Možnosti dělení dat najdete na kartě Zdroj aktivity kopírování.

Informace o konfiguraci konektoru Oracle pro paralelní kopírování naleznete v tématu Paralelní kopírování z Oracle.
Další informace o výkonu a škálovatelnosti aktivity kopírování služby Data Factory najdete v aktivita Copy průvodci výkonem a škálovatelností.
Další kroky
Další informace o operacích přístupu k zabezpečení najdete v dalším článku této série: Zabezpečení, přístup a operace pro migrace Oracle.