Kurz: Analýza textu se službami Azure AI
V tomto kurzu se naučíte používat Analýza textu k analýze nestrukturovaného textu ve službě Azure Synapse Analytics. Analýza textu je služba Azure AI, která umožňuje provádět dolování textu a analýzu textu pomocí funkcí NLP (Natural Language Processing).
Tento kurz ukazuje použití analýzy textu se službou SynapseML k:
- Rozpoznání popisků mínění na úrovni věty nebo dokumentu
- Identifikace jazyka pro daný textový vstup
- Rozpoznávání entit z textu s odkazy na dobře známou znalostní báze
- Extrakce klíčových frází z textu
- Identifikace různých entit v textu a jejich kategorizace do předem definovaných tříd nebo typů
- Identifikace a redakce citlivých entit v daném textu
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
- Pracovní prostor Azure Synapse Analytics s účtem úložiště Azure Data Lake Storage Gen2 nakonfigurovaným jako výchozí úložiště. Musíte být přispěvatelem dat objektů blob úložiště systému souborů Data Lake Storage Gen2, se kterým pracujete.
- Fond Sparku v pracovním prostoru Azure Synapse Analytics Podrobnosti najdete v tématu Vytvoření fondu Sparku v Azure Synapse.
- Kroky předkonfigurace popsané v kurzu Konfigurace služeb Azure AI v Azure Synapse
Začínáme
Otevřete Synapse Studio a vytvořte nový poznámkový blok. Začněte importem SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Konfigurace analýzy textu
Použijte propojenou analýzu textu, kterou jste nakonfigurovali v krocích předkonfigurace.
linked_service_name = "<Your linked service for text analytics>"
Mínění v textu
Analýza mínění v textu poskytuje způsob, jak rozpoznat popisky mínění (například "negativní", "neutrální" a "pozitivní") a skóre spolehlivosti na úrovni věty a dokumentu. Seznam povolených jazyků najdete v podporovaných jazycích v rozhraní API Analýza textu.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Očekávané výsledky
| text | cítění |
|---|---|
| Jsem dnes tak šťastná, je to slunečno! | pozitivní |
| Jsem frustrovaný tímto dopravním provozem v hodině spěchu | negativní |
| Služby Azure AI ve Sparku jsou špatně | neutrální |
Detektor jazyka
Detektor jazyka vyhodnocuje textový vstup pro každý dokument a vrací identifikátory jazyka se skóre, které označuje sílu analýzy. Tato schopnost je užitečná pro úložiště obsahu, která shromažďují libovolné texty, u nichž není jazyk znám. Seznam povolených jazyků najdete v podporovaných jazycích v rozhraní API Analýza textu.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Očekávané výsledky
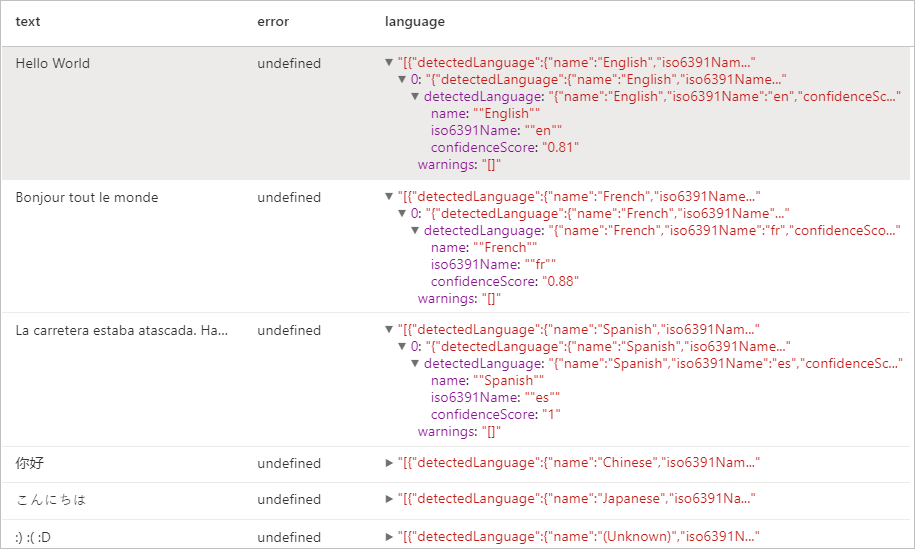
Detektor entit
Detektor entit vrátí seznam rozpoznaných entit s odkazy na dobře známou znalostní báze. Seznam povolených jazyků najdete v podporovaných jazycích v rozhraní API Analýza textu.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Očekávané výsledky
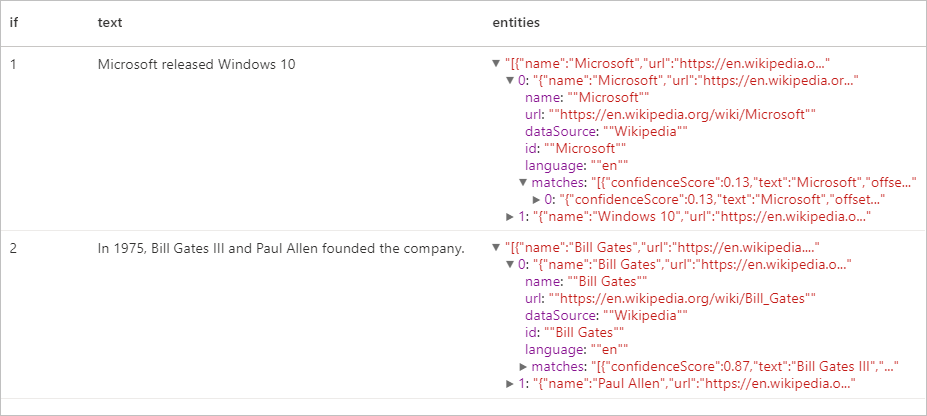
Extrakce klíčových frází
Extrakce klíčových frází vyhodnocuje nestrukturovaný text a vrátí seznam klíčových frází. Tato funkce je užitečná v případě, kdy potřebujete rychle identifikovat hlavní body v kolekci dokumentů. Seznam povolených jazyků najdete v podporovaných jazycích v rozhraní API Analýza textu.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Očekávané výsledky
| text | keyPhrases |
|---|---|
| Ahoj světe. Tohle je nějaký vstupní text, který miluji. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Rozpoznávání pojmenovaných entit (NER, Named Entity Recognition)
Pojmenované rozpoznávání entit (NER) je schopnost identifikovat různé entity v textu a kategorizovat je do předem definovaných tříd nebo typů, jako jsou: osoba, umístění, událost, produkt a organizace. Seznam povolených jazyků najdete v podporovaných jazycích v rozhraní API Analýza textu.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Očekávané výsledky
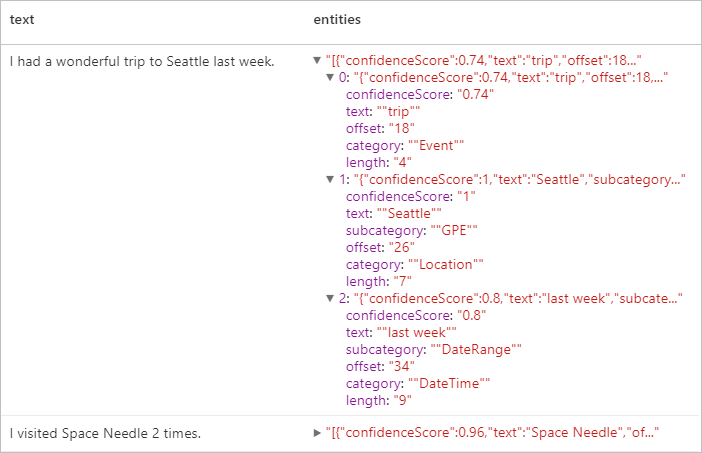
Identifikovatelné osobní údaje (PII) v3.1
Funkce PII je součástí funkce NER a dokáže identifikovat a redigovat citlivé entity v textu, které jsou spojené s jednotlivými osobami, například: telefonní číslo, e-mailová adresa, poštovní adresa, číslo pasu. Seznam povolených jazyků najdete v podporovaných jazycích v rozhraní API Analýza textu.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Očekávané výsledky
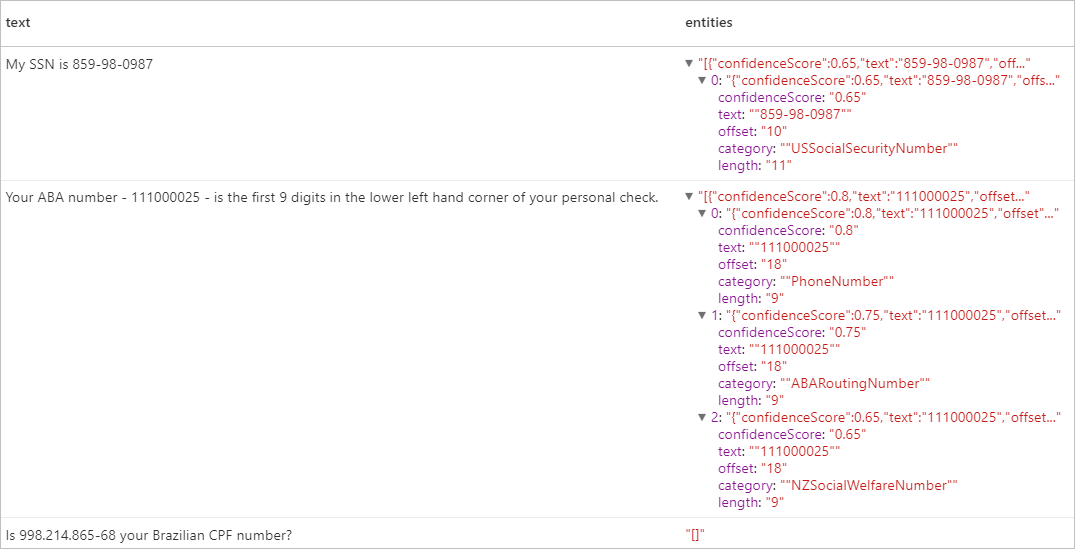
Vyčištění prostředků
Pokud chcete zajistit, aby se instance Sparku vypnula, ukončete všechny připojené relace (poznámkové bloky). Fond se vypne, když se dosáhne doby nečinnosti zadané ve fondu Apache Spark. Relaci zastavení můžete také vybrat ze stavového řádku v pravém horním rohu poznámkového bloku.
