Analýza výkonu úlohy Stream Analytics pomocí metrik a dimenzí
Abyste pochopili stav úlohy Azure Stream Analytics, je důležité vědět, jak používat metriky a dimenze úlohy. K získání metrik a dimenzí, které vás zajímají, můžete použít Azure Portal, rozšíření Visual Studio Code Stream Analytics nebo sadu SDK.
Tento článek ukazuje, jak pomocí metrik a dimenzí úlohy Stream Analytics analyzovat výkon úlohy prostřednictvím webu Azure Portal.
Hlavními metrikami pro určení výkonu úlohy Stream Analytics jsou zpoždění vodoznaku a nevyřízené vstupní události. Pokud zpoždění vodoznaku vaší úlohy neustále roste a vstupní události se nevyříznou, vaše úloha nemůže držet krok s rychlostí vstupních událostí a včas vytvářet výstupy.
Podívejme se na několik příkladů, jak analyzovat výkon úlohy prostřednictvím dat metrik zpoždění vodoznaku jako výchozího bodu.
Zpoždění vodoznaku úlohy nezvýšuje žádný vstup pro určitý oddíl.
Pokud zpoždění vodoznaku vaší trapné paralelní úlohy neustále roste, přejděte na Metriky. Pak pomocí těchto kroků zjistíte, jestli původní příčinou není v některých oddílech vstupního zdroje dostatek dat:
Zkontrolujte, který oddíl má zpoždění zvětšení vodoznaku. Vyberte metriku Zpoždění vodoznaku a rozdělte ji podle dimenze ID oddílu. V následujícím příkladu má oddíl 465 velké zpoždění vodoznaku.

Zkontrolujte, jestli pro tento oddíl chybí nějaká vstupní data. Vyberte metriku vstupních událostí a vyfiltrujte ji na toto konkrétní ID oddílu.



Jakou další akci můžete provést?
Zpoždění vodoznaku pro tento oddíl se zvyšuje, protože do tohoto oddílu neprotékají žádné vstupní události. Pokud je interval tolerance vaší úlohy pro pozdní příjezdy několik hodin a do oddílu neprotékají žádná vstupní data, očekává se, že zpoždění vodoznaku pro tento oddíl se bude dál zvětšovat, dokud nedosáhne zpoždění pozdního příjezdu.
Pokud je například okno pozdního příjezdu 6 hodin a vstupní data neprotékají do vstupního oddílu 1, zpoždění vodoznaku pro výstupní oddíl 1 se zvýší, dokud nedosáhne 6 hodin. Můžete zkontrolovat, jestli vstupní zdroj vytváří data podle očekávání.
Nerovnoměrná distribuce vstupních dat způsobuje zpoždění vodoznaku
Jak je uvedeno v předchozím případě, když má vaše trapná paralelní úloha vysoké zpoždění vodoznaku, první věcí, kterou je potřeba udělat, je rozdělit metriku Zpoždění vodoznaku podle dimenze ID oddílu. Pak můžete zjistit, jestli mají všechny oddíly vysoké zpoždění vodoznaku, nebo jenom několik z nich.
V následujícím příkladu mají oddíly 0 a 1 zpoždění vodoznaku (přibližně 20 až 30 sekund), než mají ostatní osm oddílů. Zpoždění vodoznaku ostatních oddílů jsou vždy stabilní přibližně na 8 až 10 sekundách.

Pojďme se podívat, jak vypadají vstupní data pro všechny tyto oddíly, a to s rozdělením vstupních událostí metriky podle ID oddílu:

Jakou další akci můžete provést?
Jak je znázorněno v příkladu, oddíly (0 a 1) s velkým zpožděním vodoznaku přijímají výrazně více vstupních dat než jiné oddíly. Tato data nazýváme nerovnoměrnou distribuci. Uzly streamování, které zpracovávají oddíly s nerovnoměrnou distribuci dat, musí spotřebovávat více prostředků procesoru a paměti než jiné, jak je znázorněno na následujícím snímku obrazovky.

Uzly streamování, které zpracovávají oddíly s vyšší nerovnoměrnou distribuci dat, budou vykazovat vyšší využití procesoru nebo jednotky streamování (SU). Toto využití ovlivní výkon úlohy a zvýší zpoždění vodoznaku. Pokud chcete tento problém zmírnit, potřebujete znovu rozdělení vstupních dat rovnoměrněji.
Tento problém můžete také ladit s diagramem fyzických úloh, viz Diagram fyzické úlohy: Identifikace nerovnoměrných distribuovaných vstupních událostí (nerovnoměrná distribuce dat).
Přetížení procesoru nebo paměti zvyšuje zpoždění vodoznaku
Když má trapná paralelní úloha zpoždění vodoznaku, může k ní dojít nejen u jednoho nebo několika oddílů, ale u všech oddílů. Jak potvrdíte, že do tohoto případu spadá vaše práce?
Rozdělte metriku zpoždění vodoznaku podle ID oddílu. Příklad:
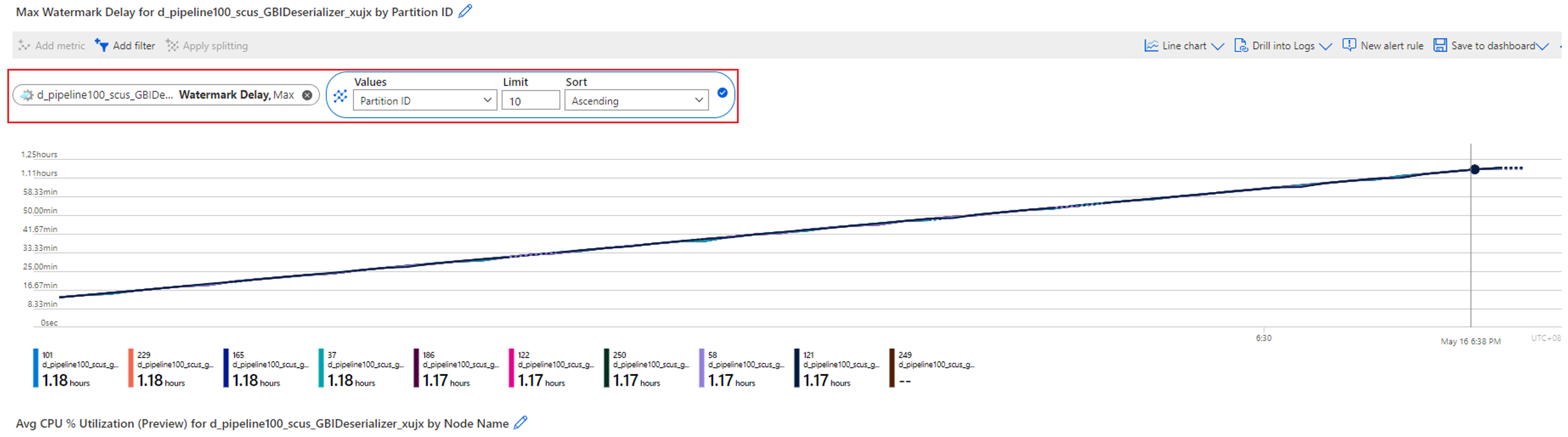
Rozdělte metriku vstupních událostí podle ID oddílu a ověřte, jestli pro každý oddíl dochází ke nerovnoměrné distribuci dat.
Zkontrolujte využití procesoru a SU a zjistěte, jestli je využití ve všech uzlech streamování příliš vysoké.

Pokud je využití procesoru a jednotek SU ve všech uzlech streamování velmi vysoké (více než 80 procent), můžete dojít k závěru, že tato úloha má velké množství dat zpracovávaných v rámci každého uzlu streamování.
Pokud chcete zjistit, kolik oddílů je přiděleno jednomu uzlu streamování, zkontrolujte metriku vstupních událostí . Filtrujte podle ID uzlu streamování s dimenzí Název uzlu a rozdělte ho podle ID oddílu.
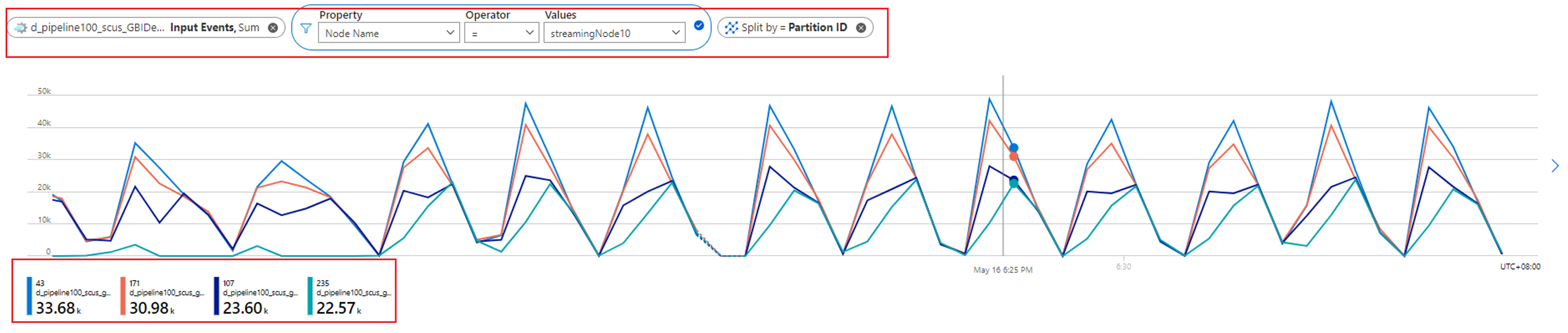
Předchozí snímek obrazovky ukazuje, že čtyři oddíly jsou přiděleny jednomu uzlu streamování, který zabírá přibližně 90 až 100 procent prostředku uzlu streamování. Podobný přístup můžete použít ke kontrole zbývajících uzlů streamování, abyste ověřili, že zpracovávají také data ze čtyř oddílů.



Jakou další akci můžete provést?
Možná budete chtít snížit počet oddílů pro každý uzel streamování, abyste snížili vstupní data pro každý uzel streamování. Abyste toho dosáhli, můžete zdvojnásobit SU, aby každý uzel streamování zpracovával data ze dvou oddílů. Nebo můžete násobit jednotky SU tak, aby každý uzel streamování zpracovával data z jednoho oddílu. Informace o vztahu mezi přiřazením SU a počtem uzlů streamování najdete v tématu Vysvětlení a úprava jednotek streamování.
Co byste měli dělat, když zpoždění vodoznaku stále roste, když jeden uzel streamování zpracovává data z jednoho oddílu? Znovu rozdělte vstup s dalšími oddíly, abyste snížili množství dat v jednotlivých oddílech. Podrobnosti najdete v tématu Použití repartitioningu k optimalizaci úloh Azure Stream Analytics.
Tento problém můžete také ladit pomocí diagramu fyzických úloh, viz Diagram fyzické úlohy: Identifikace příčiny přetíženého procesoru nebo paměti.