Integrace Azure Stream Analytics se službou Azure Machine Learning
Modely strojového učení můžete implementovat jako uživatelem definovanou funkci (UDF) v úlohách Azure Stream Analytics, abyste mohli provádět vyhodnocování a předpovědi v reálném čase u streamovaných vstupních dat. Azure Machine Learning umožňuje používat jakýkoli oblíbený opensourcový nástroj, jako je TensorFlow, scikit-learn nebo PyTorch, k přípravě, trénování a nasazování modelů.
Požadavky
Před přidáním modelu strojového učení jako funkce do úlohy Stream Analytics proveďte následující kroky:
Pomocí služby Azure Machine Learning nasaďte model jako webovou službu.
Koncový bod strojového učení musí mít přidružený swagger , který stream Analytics pomáhá pochopit schéma vstupu a výstupu. Tuto ukázkovou definici swaggeru můžete použít jako referenci, abyste měli jistotu, že jste ji nastavili správně.
Ujistěte se, že webová služba přijímá a vrací serializovaná data JSON.
Nasaďte model ve službě Azure Kubernetes Service pro vysoce škálovaná produkční nasazení. Pokud webová služba nedokáže zpracovat počet požadavků přicházejících z vaší úlohy, sníží se výkon úlohy Stream Analytics, což má vliv na latenci. Modely nasazené ve službě Azure Container Instances se podporují jenom v případě, že používáte Azure Portal.
Přidání modelu strojového učení do úlohy
Funkce Azure Machine Learning můžete do úlohy Stream Analytics přidat přímo z webu Azure Portal nebo editoru Visual Studio Code.
portál Azure
Na webu Azure Portal přejděte k úloze Stream Analytics a v části Topologie úloh vyberte Funkce. Pak v rozevírací nabídce + Přidat vyberte službu Azure Machine Learning Service.
Ve formuláři funkce služby Azure Machine Learning Service vyplňte následující hodnoty vlastností:
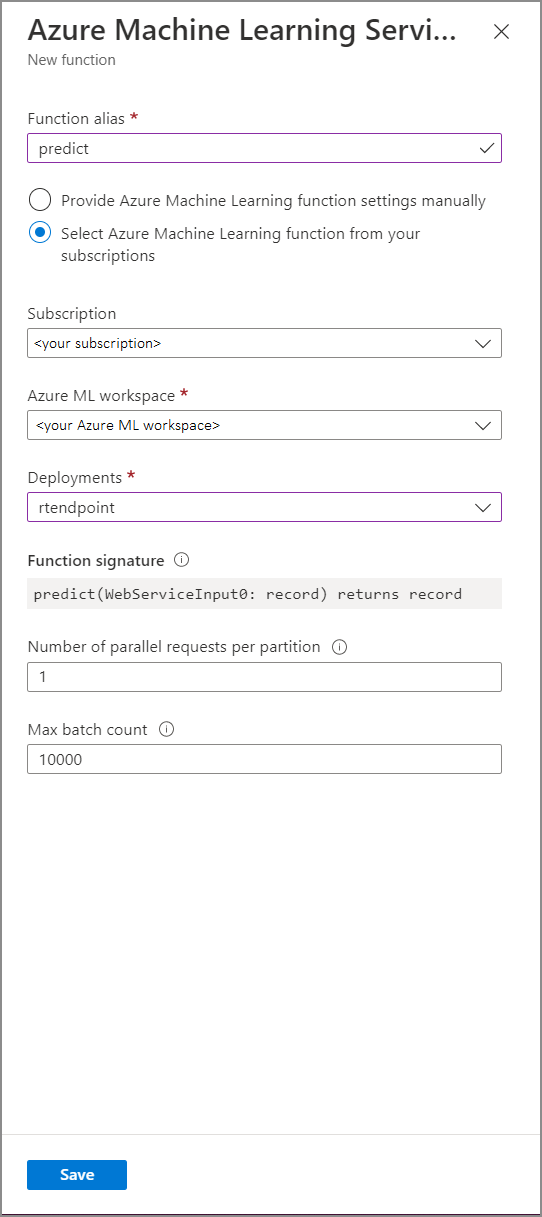
Následující tabulka popisuje jednotlivé vlastnosti funkcí služby Azure Machine Learning v Stream Analytics.
| Vlastnost | Popis |
|---|---|
| Alias funkce | Zadejte název pro vyvolání funkce v dotazu. |
| Předplatné | Vaše předplatné Azure. |
| Pracovní prostor služby Azure Machine Learning | Pracovní prostor Azure Machine Learning, který jste použili k nasazení modelu jako webové služby. |
| Koncový bod | Webová služba hostující váš model. |
| Podpis funkce | Podpis webové služby odvozený ze specifikace schématu rozhraní API. Pokud se váš podpis nepodaří načíst, zkontrolujte, že jste ve skriptu bodování zadali ukázkový vstup a výstup, abyste schéma automaticky vygenerovali. |
| Počet paralelních požadavků na oddíl | Jedná se o pokročilou konfiguraci pro optimalizaci vysoké propustnosti. Toto číslo představuje souběžné požadavky odeslané z každého oddílu vaší úlohy do webové služby. Úlohy se šesti jednotkami streamování (SU) a nižšími mají jeden oddíl. Úlohy s 12 SU mají dva oddíly, 18 jednotek SU mají tři oddíly atd. Pokud má vaše úloha například dva oddíly a tento parametr nastavíte na čtyři, bude z vaší úlohy do vaší webové služby osm souběžných požadavků. |
| Maximální počet v dávce | Jedná se o pokročilou konfiguraci pro optimalizaci vysoké propustnosti. Toto číslo představuje maximální počet událostí,kteréch |
Volání koncového bodu strojového učení z dotazu
Když dotaz Stream Analytics vyvolá UDF služby Azure Machine Learning, úloha vytvoří serializovaný požadavek JSON pro webovou službu. Požadavek je založený na schématu specifickém pro model, které Stream Analytics odvodí z swaggeru koncového bodu.
Upozorňující
Koncové body služby Machine Learning se při testování pomocí editoru dotazů na webu Azure Portal nevyvolá, protože úloha není spuštěná. K otestování volání koncového bodu z portálu je potřeba spustit úlohu Stream Analytics.
Následující dotaz Stream Analytics je příkladem toho, jak vyvolat uživatelem definovanou službu Azure Machine Learning:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Pokud vstupní data odesílaná do UDF ML nejsou konzistentní se schématem, které se očekává, koncový bod vrátí odpověď s kódem chyby 400, což způsobí, že vaše úloha Stream Analytics přejde do stavu selhání. Doporučujeme povolit protokoly prostředků pro úlohu, které vám umožní snadno ladit a řešit takové problémy. Proto důrazně doporučujeme:
- Ověření vstupu do UDF ML nemá hodnotu null.
- Ověřte typ každého pole, které je vstupem do UDF ML, a ujistěte se, že odpovídá očekávanému koncovému bodu.
Poznámka:
Funkce definované uživatelem ML se vyhodnocují pro každý řádek daného kroku dotazu, i když je volána pomocí podmíněného výrazu (tj. CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Pokud je to potřeba, vytvořte pomocí klauzule WITH rozbíhající se cesty, volejte uživatelem definovaného strojového učení pouze tam, kde je to potřeba, a teprve potom pomocí funkce UNION znovu sloučit cesty.
Předání více vstupních parametrů do UDF
Nejběžnějšími příklady vstupů pro modely strojového učení jsou numpy pole a datové rámce. Pomocí UDF javascriptu můžete vytvořit pole a pomocí klauzule vytvořit datový rámec serializovaný ve WITH formátu JSON.
Vytvoření vstupního pole
Můžete vytvořit UDF javascriptu, který přijímá N počet vstupů, a vytvořit pole, které se dá použít jako vstup do UDF služby Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Jakmile do úlohy přidáte UDF JavaScriptu, můžete pomocí následujícího dotazu vyvolat UDF služby Azure Machine Learning:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
Následující JSON je příklad požadavku:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Vytvoření datového rámce Pandas nebo PySpark
Klauzuli můžete použít WITH k vytvoření serializovaného datového rámce JSON, který se dá předat jako vstup do UDF služby Azure Machine Learning, jak je znázorněno níže.
Následující dotaz vytvoří datový rámec tak, že vybere potřebná pole a použije datový rámec jako vstup do uživatelem definovaného uživatelem služby Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Následující JSON je ukázkový požadavek z předchozího dotazu:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Optimalizace výkonu definovaných uživatelem ve službě Azure Machine Learning
Když model nasadíte do služby Azure Kubernetes Service, můžete profilovat model a určit využití prostředků. Můžete také povolit App Insights pro vaše nasazení, abyste porozuměli rychlostem požadavků, doby odezvy a četnostem selhání.
Pokud máte scénář s vysokou propustností událostí, možná budete muset v Stream Analytics změnit následující parametry, abyste dosáhli optimálního výkonu s nízkou koncovou latencí:
- Maximální počet dávek.
- Počet paralelních požadavků na oddíl
Určení správné velikosti dávky
Po nasazení webové služby odešlete vzorový požadavek s různými velikostmi dávek od 50 a jeho zvýšením v řádu stovek. Například 200, 500, 1000, 2000 atd. Všimněte si, že po určité velikosti dávky se zvýší latence odpovědi. Poté, co se latence odezvy zvýší, by měla být maximální počet dávek pro vaši úlohu.
Určení počtu paralelních požadavků na oddíl
Při optimálním škálování by vaše úloha Stream Analytics měla být schopná odeslat do webové služby několik paralelních požadavků a během několika milisekund získat odpověď. Latence odpovědi webové služby může přímo ovlivnit latenci a výkon vaší úlohy Stream Analytics. Pokud volání z vaší úlohy do webové služby trvá dlouho, pravděpodobně se zobrazí zvýšení zpoždění vodoznaku a může se také zobrazit zvýšení počtu nevyřízených vstupních událostí.
Nízkou latenci dosáhnete tím, že zajistíte, aby byl cluster Azure Kubernetes Service (AKS) zřízený se správným počtem uzlů a replik. Je důležité, aby vaše webová služba byla vysoce dostupná a vrátila úspěšné odpovědi. Pokud se vaší úloze zobrazí chyba, která se dá opakovat, například odpověď na nedostupnost služby (503), automaticky se zopakuje s exponenciálním vypnutím. Pokud vaše úloha obdrží jednu z těchto chyb jako odpověď z koncového bodu, úloha přejde do stavu selhání.
- Chybný požadavek (400)
- Konflikt (409)
- Nenalezena (404)
- Neautorizováno (401)
Omezení
Pokud používáte službu spravovaného koncového bodu Azure ML, může Stream Analytics v současné době přistupovat jenom ke koncovým bodům, které mají povolený přístup k veřejné síti. Přečtěte si další informace na stránce o privátních koncových bodech Azure ML.