Modelování relací
Tento článek popisuje proces modelování, který vám pomůže navrhnout řešení Azure Table Storage.
Vytváření doménových modelů je klíčovým krokem při návrhu složitých systémů. Proces modelování obvykle používáte k identifikaci entit a vztahů mezi nimi jako způsob, jak porozumět obchodní doméně a informovat návrh systému. Tato část se zaměřuje na to, jak můžete přeložit některé běžné typy relací nalezené v doménových modelech na návrhy pro službu Table Service. Proces mapování z logického datového modelu na fyzický datový model založený na NoSQL se liší od toho, který se používá při návrhu relační databáze. Návrh relačních databází obvykle předpokládá proces normalizace dat optimalizovaný pro minimalizaci redundance a deklarativní možnosti dotazování, která abstrahuje způsob fungování databáze.
Vztahy 1:N
Relace 1:N mezi objekty obchodní domény se vyskytují často: například jedno oddělení má mnoho zaměstnanců. Ve službě Table Service můžete implementovat několik způsobů, jak implementovat relace 1:N s klady a nevýhodymi, které můžou být pro konkrétní scénář relevantní.
Představte si příklad velkého multinárodního/regionálního podniku s desítkami tisíc oddělení a zaměstnaneckých entit, kde má každé oddělení mnoho zaměstnanců a každého zaměstnance, jak je spojené s jedním konkrétním oddělením. Jedním z přístupů je ukládání samostatných oddělení a entit zaměstnanců, jako jsou tyto:

Tento příklad ukazuje implicitní relaci 1:N mezi typy na základě hodnoty PartitionKey . Každé oddělení může mít mnoho zaměstnanců.
Tento příklad také ukazuje entitu oddělení a související entity zaměstnanců ve stejném oddílu. Pro různé typy entit můžete použít různé oddíly, tabulky nebo dokonce účty úložiště.
Alternativním přístupem je denormalizovat data a ukládat pouze entity zaměstnanců s denormalizovanými daty oddělení, jak je znázorněno v následujícím příkladu. V tomto konkrétním scénáři nemusí být tento denormalizovaný přístup nejlepší, pokud potřebujete změnit podrobnosti manažera oddělení, protože k tomu potřebujete aktualizovat každého zaměstnance v oddělení.
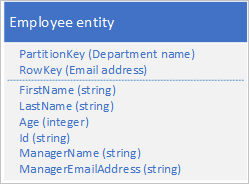
Další informace naleznete v modelu denormalizace dále v této příručce.
Následující tabulka shrnuje výhody a nevýhody jednotlivých přístupů uvedených výše pro ukládání entit zaměstnanců a oddělení, které mají relaci 1:N. Měli byste také zvážit, jak často očekáváte provádění různých operací: Může být přijatelné mít návrh, který zahrnuje nákladnou operaci, pokud k této operaci dochází jen zřídka.
| Přístup | Výhody | Nevýhody |
|---|---|---|
| Oddělení typů entit, stejného oddílu, stejné tabulky |
|
|
| Samostatné typy entit, různé oddíly nebo tabulky nebo účty úložiště |
|
|
| Denormalizace do jednoho typu entity |
|
|
*Další informace naleznete v tématu Transakce skupin entit
Způsob výběru mezi těmito možnostmi a to, které z výhod a nevýhod jsou nejvýznamnější, závisí na konkrétních scénářích aplikace. Jak často například upravujete entity oddělení; proveďte všechny dotazy zaměstnanců, které potřebují další informace o oddělení; Jak blízko jsou limity škálovatelnosti oddílů nebo účtu úložiště?
Relace 1:1
Doménové modely můžou zahrnovat relace 1:1 mezi entitami. Pokud potřebujete implementovat relaci 1:1 ve službě Table Service, musíte také zvolit, jak propojit dvě související entity, když je potřebujete načíst obě. Tento odkaz může být buď implicitní, založený na konvenci v hodnotách klíče, nebo explicitní uložením odkazu ve formě hodnot PartitionKey a RowKey v každé entitě na související entitu. Diskuzi o tom, jestli byste měli související entity uložit do stejného oddílu, najdete v části Relace 1:N.
Existují také aspekty implementace, které můžou vést k implementaci relací 1:1 ve službě Table Service:
- Zpracování velkých entit (další informace najdete v tématu Vzor velkých entit).
- Implementace řízení přístupu (další informace najdete v tématu Řízení přístupu pomocí sdílených přístupových podpisů).
Připojení v klientovi
I když existují způsoby, jak modelovat relace ve službě Table Service, neměli byste zapomenout, že dva hlavní důvody použití služby Table service jsou škálovatelnost a výkon. Pokud zjistíte, že modelujete mnoho relací, které by mohly ohrozit výkon a škálovatelnost vašeho řešení, měli byste se zeptat, jestli je potřeba sestavit všechny relace dat do návrhu tabulky. Možná budete moct zjednodušit návrh a zlepšit škálovatelnost a výkon vašeho řešení, pokud necháte klientskou aplikaci provádět všechna potřebná spojení.
Pokud máte například malé tabulky, které obsahují data, která se často nemění, můžete tato data načíst jednou a uložit je do mezipaměti v klientovi. To může zabránit opakovanému zaokrouhlení, aby se načetla stejná data. V příkladech, na které jsme se podívali v této příručce, je pravděpodobné, že sada oddělení v malé organizaci bude malá a bude se často měnit tak, aby byla vhodným kandidátem na data, která klientská aplikace může stáhnout jednou a uložit do mezipaměti jako vyhledávací data.
Vztahy dědičnosti
Pokud vaše klientská aplikace používá sadu tříd, které tvoří součást vztahu dědičnosti k reprezentaci obchodních entit, můžete tyto entity snadno zachovat ve službě Table Service. Můžete mít například následující sadu tříd definovaných v klientské aplikaci, kde Person je abstraktní třída.
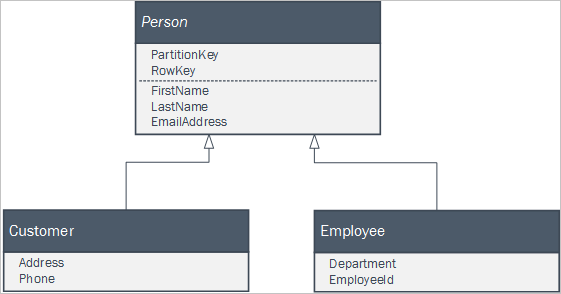
Instance dvou konkrétních tříd ve službě Table Service můžete zachovat pomocí jedné tabulky Osob pomocí entit, které vypadají takto:

Další informace o práci s více typy entit ve stejné tabulce v kódu klienta najdete v části Práce s heterogenními typy entit dále v této příručce. Tady najdete příklady toho, jak rozpoznat typ entity v klientském kódu.