Monitorování Site Recovery s využitím protokolů Azure Monitoru
Tento článek popisuje, jak monitorovat počítače replikované službou Azure Site Recovery pomocí protokolů služby Azure Monitor a Log Analytics.
Protokoly služby Azure Monitor poskytují datovou platformu protokolu, která shromažďuje protokoly aktivit a prostředků spolu s dalšími daty monitorování. V protokolech služby Azure Monitor používáte Log Analytics k zápisu a testování dotazů protokolu a interaktivní analýze dat protokolů. Můžete vizualizovat a dotazovat se na výsledky protokolu a nakonfigurovat výstrahy, které budou provádět akce na základě monitorovaných dat.
V případě Site Recovery můžete použít protokoly služby Azure Monitor, které vám pomůžou provést následující akce:
- Monitorujte stav a stav Site Recovery. Můžete například monitorovat stav replikace, stav testovacího převzetí služeb při selhání, události Site Recovery, cíle bodů obnovení (RPO) pro chráněné počítače a rychlost změn disků a dat.
- Nastavte upozornění pro Site Recovery. Můžete například nakonfigurovat výstrahy pro stav počítače, stav testovacího převzetí služeb při selhání nebo stav úlohy Site Recovery.
Použití protokolů služby Azure Monitor s Site Recovery je podporováno pro replikaci z Azure do Azure a replikaci virtuálního počítače nebo fyzického serveru VMware do Azure .
Poznámka:
Pokud chcete získat protokoly dat četnosti změn a protokoly rychlosti nahrávání pro VMware a fyzické počítače, musíte na procesový server nainstalovat agenta monitorování Microsoftu. Tento agent odešle protokoly replikujících počítačů do pracovního prostoru. Tato funkce je dostupná jenom pro verzi agenta mobility 9.30 a vyšší.
Požadavky
Zde je seznam toho, co k tomu potřebujete:
- Nejméně jeden počítač je chráněn v trezoru služby Recovery Services.
- Pracovní prostor služby Log Analytics pro ukládání protokolů Site Recovery Přečtěte si informace o nastavení pracovního prostoru.
- Základní znalosti o tom, jak psát, spouštět a analyzovat dotazy na protokoly v Log Analytics. Další informace.
Než začnete, doporučujeme, abyste si prostudovali běžné dotazy k monitorování.
Protokoly událostí dostupné pro Azure Site Recovery
Azure Site Recovery poskytuje následující tabulky specifické pro prostředky a starší verze. Každá událost poskytuje podrobná data o konkrétní sadě artefaktů souvisejících se službou Site Recovery.
Tabulky specifické pro prostředky:
Starší tabulky:
- Události Azure Site Recovery
- Replikované položky Azure Site Recovery
- Statistiky replikace Azure Site Recovery
- Body služby Azure Site Recovery
- Rychlost nahrávání dat replikace Azure Site Recovery
- Četnost změn dat chráněného disku azure Site Recovery
- Podrobnosti replikované položky azure Site Recovery
Konfigurace Site Recovery pro odesílání protokolů
V trezoru vyberte Nastavení>diagnostiky Přidat nastavení diagnostiky.
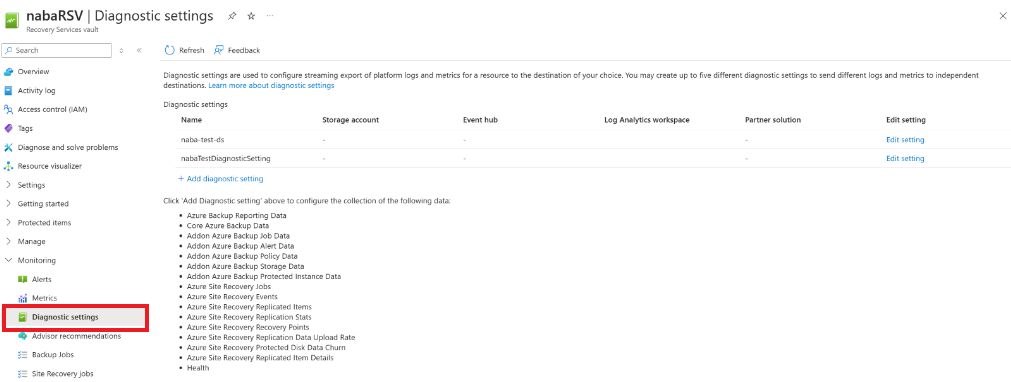
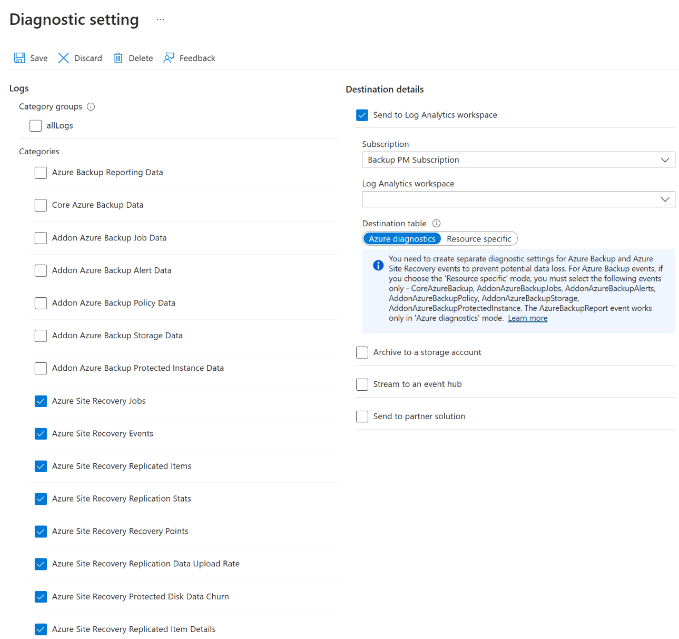
V nastavení diagnostiky zadejte název a zaškrtněte políčko Odeslat do Log Analytics.
Vyberte předplatné protokolů Služby Azure Monitor a pracovní prostor služby Log Analytics.
V přepínači vyberte Azure Diagnostics .
V seznamu protokolů vyberte všechny protokoly s předponou AzureSiteRecovery. Pak vyberte OK.
Protokoly Site Recovery se začnou pouštět do tabulky (AzureDiagnostics) ve vybraném pracovním prostoru.
Konfigurace monitorovacího agenta Microsoftu na procesovém serveru pro odesílání protokolů četnosti změn a nahrávání
Informace o četnosti změn dat a informace o rychlosti nahrávání zdrojových dat pro místní počítače VMware nebo fyzické počítače můžete zaznamenat. Aby to bylo možné, musí být na procesovém serveru nainstalovaný agent Microsoft Monitoring Agent.
Přejděte do pracovního prostoru služby Log Analytics a vyberte Upřesnit nastavení.
Vyberte stránku Připojené zdroje a dále vyberte Windows Servery.
Stáhněte agenta systému Windows (64bitová verze) na procesovém serveru.
Dokončete instalaci agenta zadáním získaného ID a klíče pracovního prostoru.
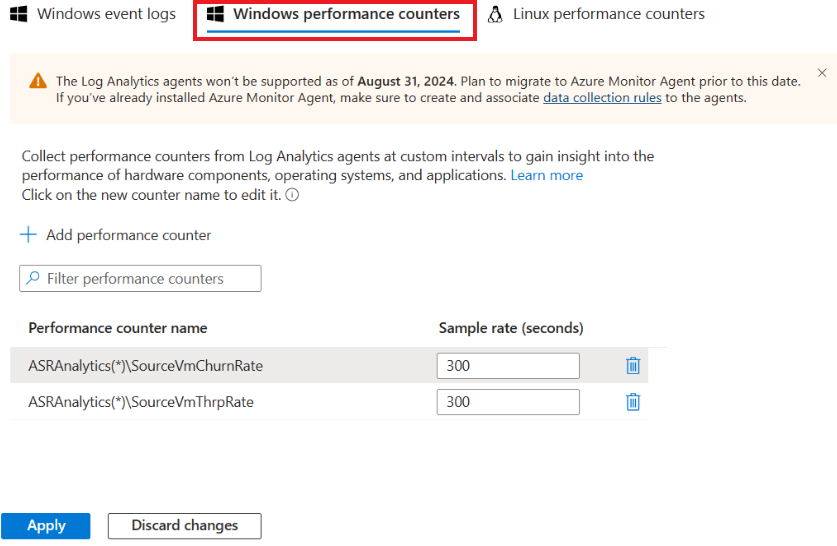
Po dokončení instalace přejděte do pracovního prostoru služby Log Analytics a vyberte správu starších agentů. Přejděte na stránku Data a vyberte čítače výkonu Systému Windows.
Vyberte + , pokud chcete přidat následující dva čítače s ukázkovým intervalem 300 sekund:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Data četnosti změn a nahrávání se začnou do pracovního prostoru přidávat.
V současné době nelze prohledávat následující čítače Site Recovery:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Dají se ale přidat vložením celých jmen.
Poznámka:
V současné době nemůžete tyto čítače hledat. Můžete je ale přidat zkopírováním a vložením jejich celých jmen.
- SourceVmThrpRate ukazuje síť prostřednictvím přenosové rychlosti zdroje.
- SourceVmChurnRate ukazuje rychlost změny dat na disku na zdrojovém virtuálním počítači.
Dotazování protokolů – příklady
Načítáte data z protokolů pomocí dotazů protokolu zapsaných pomocí dotazovacího jazyka Kusto. Tato část obsahuje několik příkladů běžných dotazů, které můžete použít pro monitorování Site Recovery.
Poznámka:
Některé z příkladů používají replicationProviderName_s nastavené na A2A. Tím se načte virtuální počítače Azure replikované do sekundární oblasti Azure pomocí Site Recovery. V těchto příkladech můžete A2A nahradit inMageRcm, pokud chcete načíst místní virtuální počítače VMware nebo fyzické servery replikované do Azure pomocí Site Recovery.
Stav replikace dotazů
Tento dotaz vykreslí výsečový graf pro aktuální stav replikace všech chráněných virtuálních počítačů Azure, rozdělený do tří stavů: Normální, Upozornění nebo Kritické.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Verze Mobility dotazu
Tento dotaz vykreslí výsečový graf pro virtuální počítače Azure replikované pomocí Site Recovery, rozdělený podle verze agenta mobility, na kterém běží.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
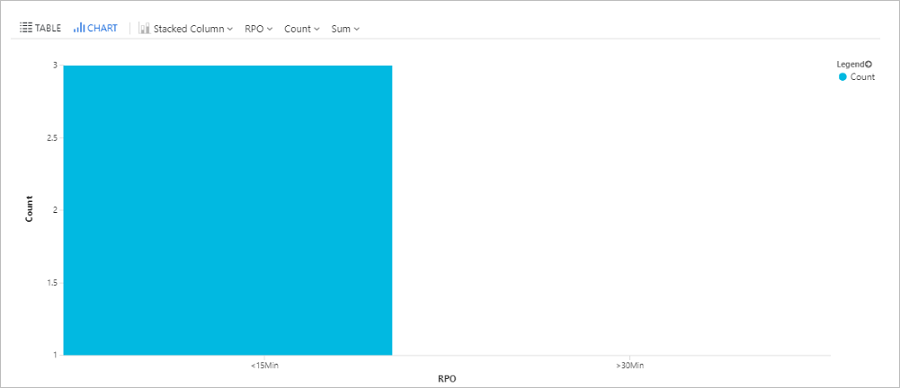
Čas bodu obnovení dotazu
Tento dotaz vykreslí pruhový graf virtuálních počítačů Azure replikovaných pomocí Site Recovery, rozdělený podle cíle bodu obnovení (RPO): Méně než 15 minut, mezi 15 až 30 minutami a více než 30 minut.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart
Dotazování úloh Site Recovery
Tento dotaz načte všechny úlohy Site Recovery (pro všechny scénáře zotavení po havárii), aktivované za posledních 72 hodin a jejich stav dokončení.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Dotazování událostí Site Recovery
Tento dotaz načte všechny události Site Recovery (pro všechny scénáře zotavení po havárii) vyvolané za posledních 72 hodin spolu se závažností.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Dotazování stavu testovacího převzetí služeb při selhání (výsečový graf)
Tento dotaz vykreslí výsečový graf pro testovací stav převzetí služeb při selhání virtuálních počítačů Azure replikovaných pomocí Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Dotazování stavu testovacího převzetí služeb při selhání (tabulka)
Tento dotaz vykreslí tabulku pro testovací stav převzetí služeb při selhání virtuálních počítačů Azure replikovaných pomocí Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
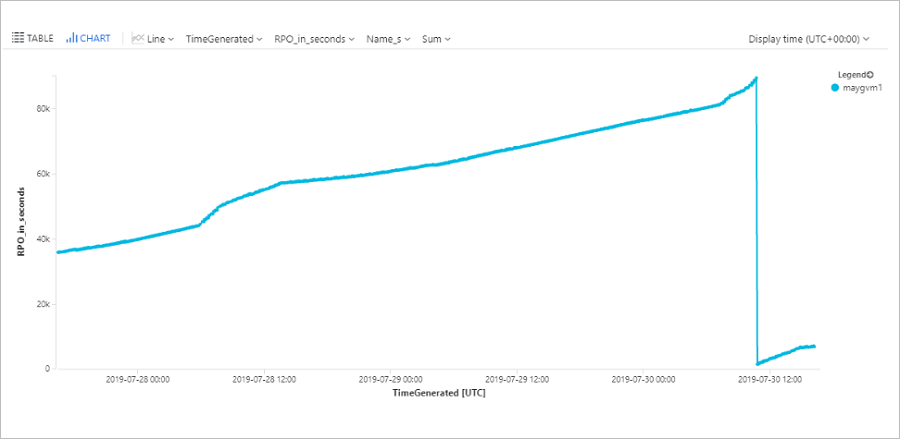
Dotazování na cíl bodu obnovení počítače
Tento dotaz vykreslí graf trendu, který sleduje cíl bodu obnovení konkrétního virtuálního počítače Azure (ContosoVM123) za posledních 72 hodin.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart
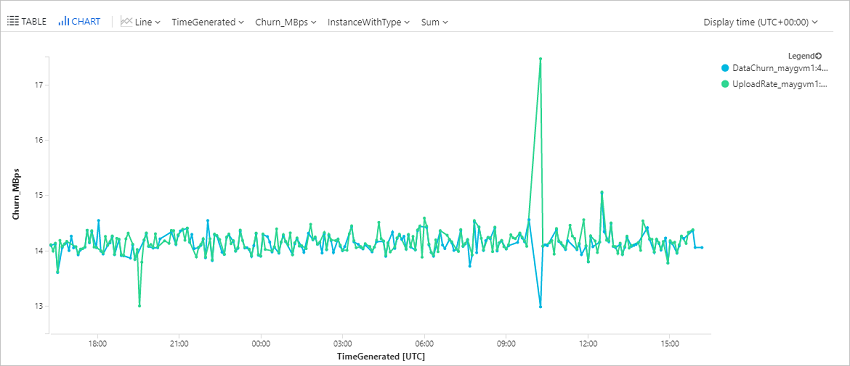
Dotazování četnosti změn dat (četnost změn) a frekvence nahrávání pro virtuální počítač Azure
Tento dotaz vykreslí graf trendu pro konkrétní virtuální počítač Azure (ContosoVM123), který představuje rychlost změn dat (zápis bajtů za sekundu) a rychlost nahrávání dat.
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
Dotazování na četnost změn dat (četnost změn) a rychlost nahrávání pro VMware nebo fyzický počítač
Poznámka:
Ujistěte se, že jste na procesovém serveru nastavili agenta monitorování pro načtení těchto protokolů. Postup konfigurace agenta monitorování
Tento dotaz vykreslí graf trendu pro určitý disk, disk0, replikovanou položku win-9r7sfh9qlru, který představuje rychlost změny dat (bajty zápisu za sekundu) a rychlost nahrávání dat. Název disku najdete v okně Disky replikované položky v trezoru služby Recovery Services. Název instance, který se má použít v dotazu, je název DNS počítače následovaný názvem _ a názvem disku, jak je uvedeno v tomto příkladu.
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
Procesový server odešle tato data každých 5 minut do pracovního prostoru služby Log Analytics. Tyto datové body představují průměr vypočítaný po dobu 5 minut.
Souhrn zotavení po havárii dotazu (z Azure do Azure)
Tento dotaz vykreslí souhrnnou tabulku pro virtuální počítače Azure replikované do sekundární oblasti Azure. Zobrazuje název virtuálního počítače, replikaci a stav ochrany, cíl bodu obnovení, stav testovacího převzetí služeb při selhání, verzi agenta mobility, všechny chyby aktivní replikace a zdrojové umístění.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Souhrn zotavení po havárii dotazu (VMware nebo fyzické servery)
Tento dotaz vykreslí souhrnnou tabulku pro virtuální počítače VMware a fyzické servery replikované do Azure. Zobrazuje název počítače, stav replikace a ochrany, cíl bodu obnovení, stav testovacího převzetí služeb při selhání, verzi agenta mobility, všechny chyby aktivní replikace a příslušný procesový server.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Nastavení upozornění – příklady
Upozornění Site Recovery můžete nastavit na základě dat služby Azure Monitor. Přečtěte si další informace o nastavení upozornění protokolu.
Poznámka:
Některé z příkladů používají replicationProviderName_s nastavené na A2A. Tím se nastaví výstrahy pro virtuální počítače Azure, které se replikují do sekundární oblasti Azure. V těchto příkladech můžete A2A nahradit inMageRcm, pokud chcete nastavit upozornění pro místní virtuální počítače VMware nebo fyzické servery replikované do Azure.
Několik počítačů v kritickém stavu
Pokud do kritického stavu přejde více než 20 replikovaných virtuálních počítačů Azure, nastavte upozornění.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pro výstrahu nastavte prahovou hodnotu na 20hodnotu .
Jeden počítač v kritickém stavu
Nastavte upozornění, pokud konkrétní replikovaný virtuální počítač Azure přejde do kritického stavu.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pro výstrahu nastavte prahovou hodnotu na 1hodnotu .
Více počítačů překračuje cíl bodu obnovení
Nastavte upozornění, pokud cíl bodu obnovení pro více než 20 virtuálních počítačů Azure překročí 30 minut.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Pro výstrahu nastavte prahovou hodnotu na 20hodnotu .
Jeden počítač překračuje cíl bodu obnovení
Nastavte upozornění, pokud cíl bodu obnovení pro jeden virtuální počítač Azure překročí 30 minut.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
Pro výstrahu nastavte prahovou hodnotu na 1hodnotu .
Testovací převzetí služeb při selhání pro více počítačů překračuje 90 dnů
Nastavte upozornění, pokud bylo poslední úspěšné testovací převzetí služeb při selhání více než 90 dní, a to pro více než 20 virtuálních počítačů.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pro výstrahu nastavte prahovou hodnotu na 20hodnotu .
Testovací převzetí služeb při selhání jednoho počítače překračuje 90 dnů
Nastavte upozornění, pokud bylo před více než 90 dny poslední úspěšné testovací převzetí služeb při selhání pro konkrétní virtuální počítač.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
Pro výstrahu nastavte prahovou hodnotu na 1hodnotu .
Selhání úlohy Site Recovery
Nastavte upozornění, pokud úloha Site Recovery (v tomto případě úloha Znovunastavení ochrany) selže pro jakýkoli scénář Site Recovery během posledního dne.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
U výstrahy nastavte prahovou hodnotu na 1 a Období na 1440 minut, abyste zkontrolovali selhání za poslední den.
Další kroky
Seznamte se s předem připraveným monitorováním Site Recovery.