Kurz: Oprava sady dovedností pomocí ladicích relací
Sada dovedností ve službě Azure AI Search koordinuje akce dovedností, které analyzují, transformují nebo vytvářejí prohledávatelný obsah. Výstup jedné dovednosti se často stává vstupem jiného. Pokud vstupy závisejí na výstupech, můžou chyby v definicích sady dovedností a přidružení polí vést ke zmeškaným operacím a datům.
Ladicí relace je nástroj webu Azure Portal, který poskytuje ucelenou vizualizaci sady dovedností, která se spouští ve službě Azure AI Search. Pomocí tohoto nástroje můžete přejít k podrobnostem o konkrétních krocích, abyste snadno zjistili, kde může dojít k poklesu akce.
V tomto článku pomocí ladicí relace vyhledejte a opravte chybějící vstupy a výstupy. Kurz je all-inclusive. Poskytuje ukázková data, soubor REST, který vytváří objekty, a pokyny pro ladění problémů v sadě dovedností.
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Požadavky
Azure AI Search. Vytvořte službu nebo vyhledejte existující službu v rámci vašeho aktuálního předplatného. Pro účely tohoto kurzu můžete použít bezplatnou službu. Úroveň Free neposkytuje podporu spravované identity pro Search Azure AI. Pro připojení ke službě Azure Storage musíte použít klíče.
Účet služby Azure Storage se službou Blob Storage, který se používá k hostování ukázkových dat a k zachování dat uložených v mezipaměti vytvořených během ladicí relace. Pokud používáte bezplatnou vyhledávací službu, musí mít účet úložiště povolené sdílené přístupové klíče a musí umožňovat přístup k veřejné síti.
Visual Studio Code s klientem REST
Ukázkový soubor debug-sessions.rest použitý k vytvoření kanálu rozšiřování.
Poznámka:
Tento kurz také používá služby Azure AI pro rozpoznávání jazyka, rozpoznávání entit a extrakci klíčových frází. Vzhledem k tomu, že úloha je tak malá, služby Azure AI se na pozadí klepnou na bezplatné zpracování až na 20 transakcí. To znamená, že toto cvičení můžete dokončit bez nutnosti vytvářet fakturovatelné prostředky služeb Azure AI.
Nastavení ukázkových dat
Tato část vytvoří ukázkovou sadu dat ve službě Azure Blob Storage, aby indexer a sada dovedností měly obsah pro práci.
Stáhněte si ukázková data (clinical-trials-pdf-19) skládající se z 19 souborů.
Vytvořte účet Azure Storage nebo vyhledejte existující účet.
Pokud se chcete vyhnout poplatkům za šířku pásma, zvolte stejnou oblast jako Azure AI Search.
Zvolte typ účtu StorageV2 (pro obecné účely verze 2).
Přejděte na stránky služeb Azure Storage na webu Azure Portal a vytvořte kontejner objektů blob. Osvědčeným postupem je zadat úroveň přístupu "privátní". Pojmenujte kontejner
clinicaltrialdataset.V kontejneru vyberte Nahrát a nahrajte ukázkové soubory, které jste stáhli a rozbalíte v prvním kroku.
Na webu Azure Portal zkopírujte připojovací řetězec pro Azure Storage. Připojovací řetězec můžete získat z přístupových klíčů nastavení>na webu Azure Portal.
Zkopírování klíče a adresy URL
Tento kurz používá klíče rozhraní API k ověřování a autorizaci. Potřebujete koncový bod vyhledávací služby a klíč rozhraní API, který můžete získat z webu Azure Portal.
Přihlaste se k webu Azure Portal, přejděte na stránku Přehled a zkopírujte adresu URL. Příkladem koncového bodu může být
https://mydemo.search.windows.net.V části Klíče nastavení>zkopírujte klíč správce. Klíče správce slouží k přidávání, úpravám a odstraňování objektů. Existují dva zaměnitelné klíče správce. Zkopírujte jeden z nich.
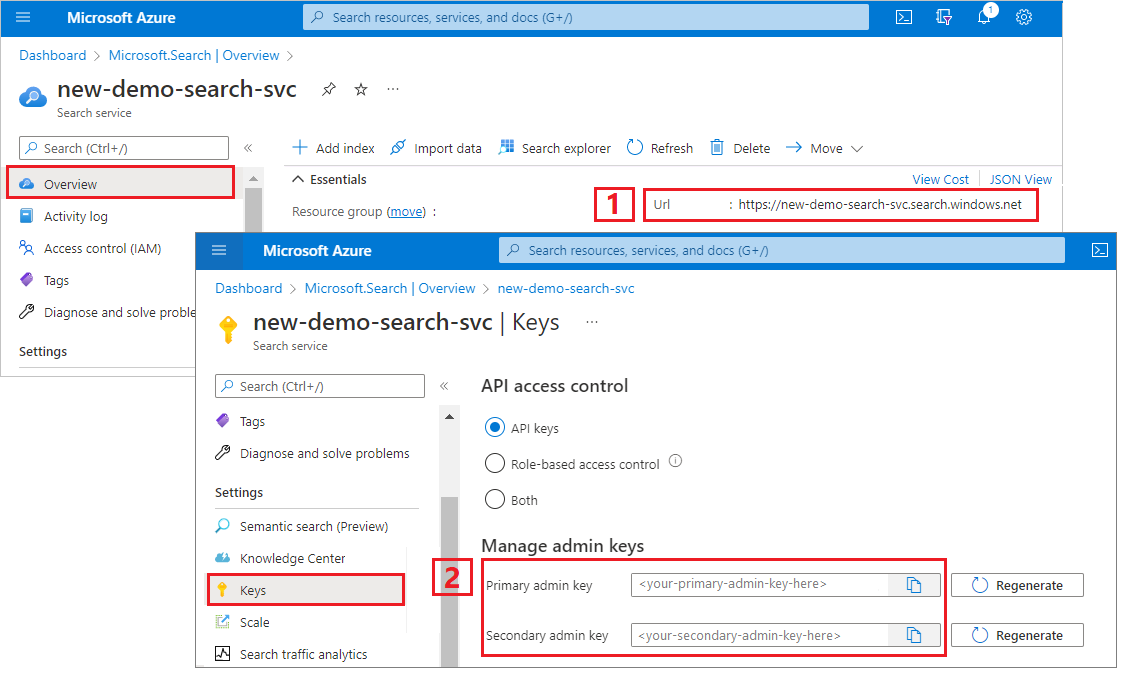
Platný klíč rozhraní API vytváří na základě požadavku vztah důvěryhodnosti mezi aplikací, která požadavek odesílá, a vyhledávací službou, která ji zpracovává.
Vytvoření zdroje dat, sady dovedností, indexu a indexeru
V této části vytvořte pracovní postup "buggy", který můžete opravit v tomto kurzu.
Spusťte Visual Studio Code a otevřete
debug-sessions.restsoubor.Zadejte následující proměnné: adresu URL vyhledávací služby, klíč rozhraní API pro správu vyhledávacích služeb, připojovací řetězec úložiště a název kontejneru objektů blob, který ukládá soubory PDF.
Odešlete všechny žádosti zase. Vytvoření indexeru trvá několik minut.
Zavřete soubor.
Kontrola výsledků na webu Azure Portal
Vzorový kód záměrně vytvoří index chyb v důsledku problémů, ke kterým došlo během provádění sady dovedností. Problém je, že index chybí data.
Na webu Azure Portal na stránce Přehled vyhledávací služby vyberte kartu Indexy.
Vyberte klinické studie.
Do zobrazení JSON v Průzkumníkovi služby Search zadejte tento řetězec dotazu JSON. Vrátí pole pro konkrétní dokumenty (identifikované jedinečným
metadata_storage_pathpolem)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueSpusťte dotaz. Měly by se zobrazit prázdné hodnoty pro
organizationsalocations.Tato pole by měla být naplněna dovedností sady dovedností Pro rozpoznávání entit, která slouží k detekci organizací a umístění kdekoli v obsahu objektu blob. V dalším cvičení budete sadu dovedností ladit, abyste zjistili, co se nepovedlo.
Dalším způsobem, jak prozkoumat chyby a upozornění, je prostřednictvím webu Azure Portal.
Otevřete kartu Indexery a vyberte clinical-trials-idxr.
Všimněte si, že zatímco úloha indexeru proběhla celkově úspěšně, došlo k upozorněním.
Výběrem možnosti Úspěch zobrazíte upozornění (pokud by došlo většinou k chybám, podrobný odkaz by se nezdařil). Zobrazí se dlouhý seznam všech upozornění vygenerovaných indexerem.

Spuštění ladicí relace
V levém navigačním podokně vyhledávací služby v části Správa hledání vyberte Relace ladění.
Vyberte + Přidat ladicí relaci.
Pojmenujte relaci.
V šabloně Indexeru zadejte název indexeru. Indexer obsahuje odkazy na zdroj dat, sadu dovedností a index.
Vyberte účet úložiště.
Uložte relaci.

Otevře se ladicí relace na stránce nastavení. Můžete provést změny počáteční konfigurace a přepsat všechny výchozí hodnoty. Ladicí relace funguje jenom s jedním dokumentem. Výchozí možností je přijmout první dokument v kolekci jako základ vašich ladicích relací. Konkrétní dokument, který chcete ladit, můžete zvolit zadáním jeho identifikátoru URI ve službě Azure Storage.
Po dokončení inicializace ladicí relace byste měli vidět pracovní postup dovedností s mapováními a indexem vyhledávání. Rozšířená datová struktura dokumentu se zobrazí v podokně podrobností na straně. Z následujícího snímku obrazovky jsme ho vyloučili, abyste viděli více pracovního postupu.



Vyhledání problémů se sadou dovedností
Všechny problémy hlášené indexerem jsou označeny jako chyby a upozornění.
Všimněte si, že počet chyb a upozornění je mnohem menší než seznam zobrazený dříve, protože tento seznam obsahuje jenom podrobnosti o chybách jednoho dokumentu. Podobně jako seznam zobrazený indexerem můžete vybrat zprávu s upozorněním a zobrazit podrobnosti tohoto upozornění.
Vyberte Upozornění , která chcete zkontrolovat. Měli byste vidět čtyři:
"Nelze provést dovednost, protože jeden nebo více vstupů dovedností byly neplatné. Chybí požadovaný vstup dovednosti. Name: 'text', Source: '/document/content'."
"Nelze namapovat výstupní pole "umístění" na index vyhledávání. Zkontrolujte vlastnost outputFieldMappings vašeho indexeru. Chybí hodnota /document/merged_content/locations.
"Nelze mapovat výstupní pole "organizace" na index vyhledávání. Zkontrolujte vlastnost outputFieldMappings vašeho indexeru. Chybí hodnota /document/merged_content/organizations.
"Provedené dovednosti, ale mohou mít neočekávané výsledky, protože jeden nebo více vstupů dovedností bylo neplatné. Nepovinný vstup dovednosti chybí. Název: languageCode, Source: /document/languageCode. Problémy s analýzou jazyka výrazů: Chybí hodnota /document/languageCode.
Mnoho dovedností má parametr languageCode. Kontrolou operace můžete vidět, že v tomto kódu jazyka chybí EntityRecognitionSkill.#1vstup kódu , což je stejná dovednost rozpoznávání entit, která má potíže s výstupem "umístění" a "organizace".
Vzhledem k tomu, že všechny čtyři oznámení jsou o této dovednosti, je dalším krokem ladění této dovednosti. Pokud je to možné, začněte tím, že nejprve vyřešíte vstupní problémy, než přejdete k problémům s výstupem.
Oprava chybějících hodnot zadávání dovedností
Na pracovní ploše vyberte dovednost, která hlásí upozornění. V tomto kurzu je to dovednost rozpoznávání entit.
Podokno podrobností o dovednostech se otevře napravo s oddíly pro iterace a příslušné vstupy a výstupy, nastavením dovedností pro definici dovednosti JSON a zprávami pro případné chyby a upozornění, že tato dovednost generuje.

Najeďte myší na každý vstup (nebo vyberte vstup) a zobrazte hodnoty v vyhodnocovači výrazů. Všimněte si, že zobrazený výsledek pro tento vstup nevypadá jako textový vstup. Vypadá to jako řada znaků nového řádku
\n \n\n\n\nmísto textu. Nedostatek textu znamená, že není možné identifikovat žádné entity, takže buď tento dokument nesplňuje požadavky dovednosti, nebo existuje jiný vstup, který by se měl použít.
Přepněte zpět na rozšířenou datovou strukturu a zkontrolujte uzly rozšiřování pro tento dokument. Všimněte si, že
\n \n\n\n\nobjekt "content" nemá žádný zdroj původu, ale jiná hodnota pro "merged_content" má výstup OCR. Ačkoli neexistuje žádná indikace, zdá se, že obsah tohoto SOUBORU PDF je soubor JPEG, jak je důkazem extrahovaného a zpracovávaného textu v "merged_content".
Vraťte se na dovednost a výběrem nastavení sady dovedností otevřete definici JSON.
Změňte výraz z
/document/contentna/document/merged_contenta pak vyberte Uložit. Všimněte si, že upozornění už není uvedené.
V nabídce okna relace vyberte Spustit . Tím se zahájí další spuštění sady dovedností pomocí dokumentu.
Po dokončení provádění relace ladění si všimněte, že počet upozornění se snížil o jeden. Upozornění ukazují, že chyba pro textové zadání je pryč, ale ostatní upozornění zůstávají. Dalším krokem je vyřešení upozornění na chybějící nebo prázdnou hodnotu
/document/languageCode.
Vyberte dovednost a najeďte myší na
/document/languageCode. Hodnota pro tento vstup je null, což není platný vstup.Stejně jako u předchozího problému začněte tím, že zkontrolujete rozšířenou datovou strukturu pro důkazy o jejích uzlech. Všimněte si, že neexistuje žádný uzel LanguageCode, ale pro jazyk existuje jeden. Takže v nastavení dovedností je překlep.
Zkopírujte výraz
/document/language.V podokně Podrobností o dovednostech vyberte Nastavení dovedností pro dovednost #1 a vložte novou hodnotu.
/document/languageZvolte Uložit.
Vyberte Spustit.
Po dokončení provádění relace ladění můžete zkontrolovat výsledky v podokně podrobností dovedností. Když najedete myší
/document/language, měli byste vidětenjako hodnotu v vyhodnocovači výrazů.
Všimněte si, že vstupní upozornění jsou pryč. Teď zůstávají jenom dvě upozornění týkající se výstupních polí pro organizace a umístění.
Oprava chybějících výstupních hodnot dovedností
Zprávy říkají, že chcete zkontrolovat vlastnost outputFieldMappings vašeho indexeru, takže se tam pustíme.
Vyberte mapování výstupních polí na pracovním povrchu. Všimněte si, že chybí mapování výstupních polí.

V prvním kroku ověřte, že index vyhledávání obsahuje očekávaná pole. V tomto případě má index pole pro "umístění" a "organizace".
Pokud s indexem není žádný problém, dalším krokem je zkontrolovat výstupy dovedností. Stejně jako předtím vyberte rozšířenou datovou strukturu a posuňte uzly a vyhledejte "umístění" a "organizace". Všimněte si, že nadřazený objekt je "obsah" místo "merged_content". Kontext je nesprávný.
Přepněte zpět do podokna podrobností dovedností pro dovednost rozpoznávání entit.
V Nastavení dovedností změňte
contextnadocument/merged_content. V tomto okamžiku byste měli mít tři úpravy definice dovednosti úplně.
Zvolte Uložit.
Vyberte Spustit.
Všechny chyby byly vyřešeny.
Potvrzení změn v sadě dovedností
Při zahájení ladicí relace vytvořila vyhledávací služba kopii sady dovedností. To bylo provedeno k ochraně původní sady dovedností ve vaší vyhledávací službě. Teď, když jste dokončili ladění sady dovedností, je možné potvrdit opravy (přepsat původní sadu dovedností).
Pokud nejste připravení potvrdit změny, můžete také uložit ladicí relaci a později ji znovu otevřít.
V hlavní nabídce relace ladění vyberte Potvrdit změny .
Vyberte OK a potvrďte, že chcete aktualizovat sadu dovedností.
Zavřete relaci ladění a otevřete indexery z levého navigačního podokna.
Vyberte clinical-trials-idxr.
Vyberte Obnovit.
Vyberte Spustit.
Výběrem možnosti Aktualizovat zobrazíte stav příkazů resetování a spuštění.
Po dokončení spuštění indexeru by mělo být zelené zaškrtnutí a vedle časového razítka pro poslední spuštění na kartě Historie spuštění by mělo být slovo Úspěch. Pokud chcete zajistit, aby se změny použily:
V levém navigačním podokně otevřete indexy.
Vyberte index clinical-trials a na kartě Průzkumník služby Search zadejte tento řetězec dotazu:
$select=metadata_storage_path, organizations, locations&$count=truepokud chcete vrátit pole pro konkrétní dokumenty (identifikované jedinečnýmmetadata_storage_pathpolem).Vyberte Hledat.
Výsledky by měly ukázat, že organizace a umístění jsou teď naplněné očekávanými hodnotami.
Vyčištění prostředků
Pokud pracujete s vlastním předplatným, je vhodné vždy na konci projektu zkontrolovat, jestli budete vytvořené prostředky ještě potřebovat. Prostředky, které necháte spuštěné, vás stojí peníze. Prostředky můžete odstraňovat jednotlivě nebo můžete odstranit skupinu prostředků, a odstranit tak celou sadu prostředků najednou.
Prostředky můžete najít a spravovat na webu Azure Portal pomocí odkazu Všechny prostředky nebo skupiny prostředků v levém navigačním podokně.
Bezplatná služba je omezená na tři indexy, indexery a zdroje dat. Jednotlivé položky na webu Azure Portal můžete odstranit, abyste zůstali pod limitem.
Další kroky
Tento kurz se týká různých aspektů definice a zpracování sady dovedností. Další informace o konceptech a pracovních postupech najdete v následujících článcích: