Vysoká dostupnost (spolehlivost) na flexibilním serveru Azure Database for PostgreSQL
PLATÍ PRO:  Flexibilní server Azure Database for PostgreSQL
Flexibilní server Azure Database for PostgreSQL
Tento článek popisuje vysokou dostupnost na flexibilním serveru Azure Database for PostgreSQL, který zahrnuje zóny dostupnosti a obnovení mezi oblastmi a provozní kontinuitu. Podrobnější přehled spolehlivosti v Azure najdete v tématu Spolehlivost Azure.
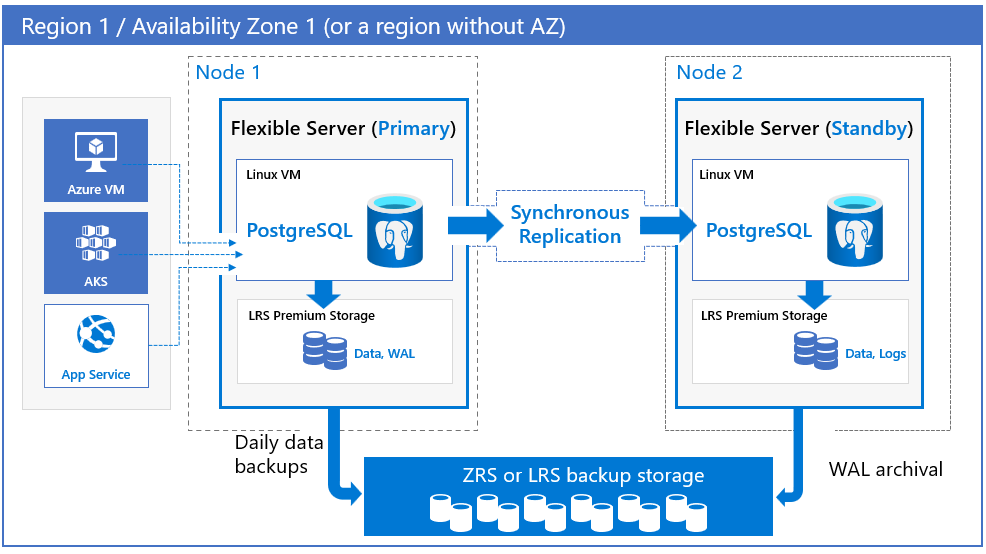
Flexibilní server Azure Database for PostgreSQL nabízí podporu vysoké dostupnosti tím, že zřídí fyzicky oddělené primární a pohotovostní repliky, a to buď v rámci stejné zóny dostupnosti (zónově redundantní), nebo napříč zónami dostupnosti (zónově redundantní). Tento model s vysokou dostupností je navržený tak, aby se v případě selhání nikdy neztratila potvrzená data. Při nastavení vysoké dostupnosti (HA) se data synchronně zapíší na primární i pohotovostní servery. Model je navržený tak, aby se databáze nestala jediným bodem selhání ve vaší softwarové architektuře. Další informace o podpoře vysoké dostupnosti a zóny dostupnosti najdete v tématu Podpora zón dostupnosti.
Podpora zón dostupnosti
Zóny dostupnosti jsou fyzicky oddělené skupiny datacenter v rámci každé oblasti Azure. Když jedna zóna selže, můžou služby převzít služby při selhání jedné ze zbývajících zón.
Další informace o zónách dostupnosti v Azure najdete v tématu Co jsou zóny dostupnosti?
Flexibilní server Azure Database for PostgreSQL podporuje zónově redundantní i zónové modely pro konfigurace s vysokou dostupností. Obě konfigurace vysoké dostupnosti umožňují automatické převzetí služeb při selhání s nulovou ztrátou dat během plánovaných i neplánovaných událostí.
Zónově redundantní. Zónově redundantní vysoká dostupnost nasadí pohotovostní repliku do jiné zóny s funkcí automatického převzetí služeb při selhání. Redundance zón poskytuje nejvyšší úroveň dostupnosti, ale vyžaduje, abyste nakonfigurovali redundanci aplikací napříč zónami. Z tohoto důvodu zvolte redundanci zóny, pokud chcete ochranu před selháními na úrovni zóny dostupnosti a kdy je latence napříč zónami dostupnosti přijatelná. I když může mít latence vliv na zápisy a potvrzení kvůli synchronní replikaci, nemá to vliv na dotazy na čtení. Tento dopad je velmi specifický pro vaše úlohy, typ skladové položky, který vyberete, a oblast.
Pro primární i pohotovostní servery můžete zvolit oblast a zóny dostupnosti. Server pohotovostní repliky je zřízený ve zvolené zóně dostupnosti ve stejné oblasti s podobným výpočetním výkonem, úložištěm a konfigurací sítě jako primární server. Datové soubory a soubory transakčních protokolů (protokoly s předstihem, a.k.a WAL) se ukládají v místně redundantním úložišti (LRS) v každé zóně dostupnosti a automaticky ukládají tři kopie dat. Zónově redundantní konfigurace poskytuje fyzickou izolaci celého zásobníku mezi primárními a pohotovostními servery.

Zonální. Vyberte zónové nasazení, pokud chcete dosáhnout nejvyšší úrovně dostupnosti v rámci jedné zóny dostupnosti, ale s nejnižší latencí sítě. Pro nasazení primárního databázového serveru můžete zvolit oblast a zónu dostupnosti. Pohotovostní server repliky se automaticky zřizuje a spravuje ve stejné zóně dostupnosti – s podobným výpočetním prostředím, úložištěm a konfigurací sítě – jako primární server. Zónová konfigurace chrání databáze před selháními na úrovni uzlu a pomáhá také snížit výpadky aplikace během plánovaných a neplánovaných výpadků. Data z primárního serveru se replikují do pohotovostní repliky v synchronním režimu. V případě jakéhokoli přerušení primárního serveru dojde k automatickému převzetí služeb při selhání na pohotovostní repliku.


Poznámka:
Zónově i zónově redundantní modely nasazení se chovají stejně. Různé diskuze v následujících částech platí pro obě, pokud není uvedeno jinak.
Požadavky
Redundance zón:
Možnost redundance zón je dostupná jenom v oblastech, které podporují zóny dostupnosti.
Zónová redundance není podporována pro:
- Skladová položka jednoúčelového serveru Azure Database for PostgreSQL
- Úroveň výpočetních prostředků s možností nárazu
- Oblasti s dostupností s jednou zónou
Zónový:
- Možnost zónového nasazení je dostupná ve všech oblastech Azure, kde můžete nasadit flexibilní server.
Funkce vysoké dostupnosti
Pohotovostní replika se nasadí ve stejné konfiguraci virtuálního počítače, včetně virtuálních jader, úložiště, nastavení sítě – jako primárního serveru.
Můžete přidat podporu zóny dostupnosti pro existující databázový server.
Pohotovostní repliku můžete odebrat zakázáním vysoké dostupnosti.
Pro zónově redundantní dostupnost můžete zvolit zóny dostupnosti pro primární a pohotovostní databázové servery.
Operace jako zastavení, spuštění a restartování se na primárním i pohotovostním databázovém serveru provádějí zároveň.
V zónově redundantních a zónových modelech se automatické zálohování pravidelně provádí z primárního databázového serveru. Současně se transakční protokoly průběžně archivují v úložišti záloh z pohotovostní repliky. Pokud oblast podporuje zóny dostupnosti, ukládají se zálohovaná data v zónově redundantním úložišti (ZRS). V oblastech, které nepodporují zóny dostupnosti, se zálohovaná data ukládají v místním redundantním úložišti (LRS).
Klienti se vždy připojují ke koncovému názvu hostitele primárního databázového serveru.
Všechny změny parametrů serveru se použijí také na pohotovostní repliku.
Restartováním serveru je možné zajistit převzetí všech změn statických parametrů serveru.
Pravidelné aktivity údržby, jako jsou upgrady podverze, probíhají nejprve v pohotovostním režimu a kvůli snížení výpadků se pohotovostní režim zvýší na primární, aby úlohy mohly zůstat zapnuté, zatímco úlohy údržby se použijí na zbývajícím uzlu.
Monitorování stavu vysoké dostupnosti
Monitorování stavu vysoké dostupnosti (HA) na flexibilním serveru Azure Database for PostgreSQL poskytuje nepřetržitý přehled o stavu a připravenosti instancí s podporou vysoké dostupnosti. Tato funkce monitorování využívá architekturu kontroly stavu prostředků Azure (RHC) k detekci a upozorňování na všechny problémy, které můžou mít vliv na připravenost nebo celkovou dostupnost vaší databáze. Posouzením klíčových metrik, jako je stav připojení, stav převzetí služeb při selhání a stav replikace dat, umožňuje monitorování stavu vysoké dostupnosti proaktivní řešení potíží a pomáhá udržovat dobu provozu a výkon vaší databáze.
Zákazníci můžou monitorování stavu vysoké dostupnosti využít k:
- Získejte přehled o stavu primárních i pohotovostních replik v reálném čase s indikátory stavu, které odhalí potenciální problémy, jako je snížení výkonu nebo blokování sítě.
- Nakonfigurujte výstrahy pro včasné oznámení o jakýchkoli změnách stavu vysoké dostupnosti a zajistěte okamžitou akci pro řešení potenciálních přerušení.
- Optimalizujte připravenost převzetí služeb při selhání tím, že identifikujete a řešíte problémy, než ovlivní databázové operace.
Podrobný průvodce konfigurací a interpretací stavu vysoké dostupnosti najdete v hlavním článku Monitorování stavu vysoké dostupnosti pro flexibilní server Azure Database for PostgreSQL.
Omezení vysoké dostupnosti
Vzhledem k synchronní replikaci na pohotovostní server, zejména s zónově redundantní konfigurací, můžou aplikace zaznamenat zvýšenou latenci zápisu a potvrzení.
Pohotovostní repliku není možné používat pro dotazy na čtení.
V závislosti na úloze a aktivitě na primárním serveru může proces převzetí služeb při selhání trvat déle než 120 sekund, protože obnovení zahrnuté v pohotovostní replice může být povýšeno.
Pohotovostní server obvykle obnovuje soubory WAL na 40 MB/s. U větších skladových položek se tato rychlost může zvýšit až na 200 MB/s. Pokud vaše úloha tento limit překročí, můžete zaznamenat delší dobu, než se obnovení dokončí během převzetí služeb při selhání nebo po vytvoření nového pohotovostního režimu.
Restartováním primárního databázového serveru se restartuje také pohotovostní replika.
Konfigurace dalšího pohotovostního režimu není podporována.
Konfiguraci úloh správy iniciovaných zákazníkem není možné naplánovat během časového období spravované údržby.
Plánované události, jako je škálování výpočetních prostředků a škálování úložiště, probíhají nejprve v pohotovostním režimu a pak na primárním serveru. V současné době server pro tyto plánované operace nepředvádí převzetí služeb při selhání.
Pokud je logické dekódování nebo logická replikace nakonfigurovaná s flexibilním serverem s nakonfigurovanou dostupností, v případě převzetí služeb při selhání na pohotovostní server se sloty logické replikace nekopírují na pohotovostní server. Pokud chcete zachovat sloty logické replikace a zajistit konzistenci dat po převzetí služeb při selhání, doporučujeme použít rozšíření PG Failover Slots. Další informace o povolení tohoto rozšíření najdete v dokumentaci.
Konfigurace zón dostupnosti mezi privátními (virtuálními sítěmi) a veřejným přístupem s privátními koncovými body se nepodporuje. Je nutné nakonfigurovat zóny dostupnosti v rámci virtuální sítě (rozložené mezi zónami dostupnosti v rámci oblasti) nebo veřejný přístup s privátními koncovými body.
Zóny dostupnosti se konfigurují jenom v rámci jedné oblasti. Zóny dostupnosti není možné konfigurovat napříč oblastmi.
SLA
Zonální model nabízí smlouvu SLA o provozu 99,95 %.
Model redundance zón nabízí smlouvu SLA o době provozu 99,99 %.
Vytvoření flexibilního serveru Azure Database for PostgreSQL s povolenou zónou dostupnosti
Informace o vytvoření flexibilního serveru Azure Database for PostgreSQL pro zajištění vysoké dostupnosti pomocí zón dostupnosti najdete v rychlém startu: Vytvoření flexibilního serveru Azure Database for PostgreSQL na webu Azure Portal.
Opětovné nasazení a migrace zóny dostupnosti
Informace o povolení nebo zakázání konfigurace vysoké dostupnosti na flexibilním serveru v zónově redundantních i zónových modelech nasazení najdete v tématu Správa vysoké dostupnosti na flexibilním serveru.
Komponenty a pracovní postup s vysokou dostupností
Dokončování transakcí
Zápisy a potvrzení aktivované transakcí aplikace se nejprve protokolují do WAL na primárním serveru. Ty se pak streamují na pohotovostní server pomocí protokolu streamování Postgres. Jakmile se protokoly zachovají v pohotovostním úložišti serveru, primární server se potvrdí pro dokončení zápisu. Teprve potom aplikace potvrdí potvrzení své transakce. Tato další doba odezvy zvyšuje latenci vaší aplikace. Procento dopadu závisí na aplikaci. Tento proces potvrzení nečeká, až se protokoly použijí na pohotovostní server. Pohotovostní server je trvale v režimu obnovení, dokud se neskončí.
Kontrola stavu
Monitorování stavu flexibilního serveru pravidelně kontroluje stav primárního i pohotovostního režimu. Pokud monitorování stavu po několika příkazech ping zjistí, že primární server není dostupný, služba pak zahájí automatické převzetí služeb při selhání na pohotovostní server. Algoritmus monitorování stavu je založený na několika datových bodech, aby se zabránilo falešně pozitivním situacím.
Režimy převzetí služeb při selhání
Flexibilní server podporuje dva režimy převzetí služeb při selhání, plánované převzetí služeb při selhání a neplánované převzetí služeb při selhání. Po odstranění replikace v obou režimech server pohotovostního režimu spustí obnovení před povýšení jako primární a otevře se pro čtení a zápis. Díky automatické aktualizaci položek DNS s novým koncovým bodem primárního serveru se aplikace můžou k serveru připojit pomocí stejného koncového bodu. Na pozadí se vytvoří nový pohotovostní server, aby vaše aplikace zachovala připojení.
Stav vysoké dostupnosti
Stav primárních a pohotovostních serverů se průběžně monitoruje a k nápravě problémů se provádějí příslušné akce, včetně aktivace převzetí služeb při selhání na pohotovostní server. Následující tabulka uvádí možné stavy vysoké dostupnosti:
| Stav | Popis |
|---|---|
| Spouštějící | V procesu vytvoření nového pohotovostního serveru. |
| Replikace dat | Jakmile se pohotovostní režim vytvoří, zachytí se primárním serverem. |
| Zdravý | Replikace je v stabilním stavu a v pořádku. |
| Převzetí služeb při selhání | Databázový server probíhá v procesu převzetí služeb při selhání do pohotovostního režimu. |
| Odebírání pohotovostního režimu | V procesu odstraňování pohotovostního serveru. |
| Nepovoleno | Vysoká dostupnost není povolená. |
Poznámka:
Vysokou dostupnost můžete povolit i při vytváření serveru nebo později. Pokud povolíte nebo zakážete vysokou dostupnost během fáze po vytvoření, doporučuje se provoz při nízké aktivitě primárního serveru.
Operace se stabilním stavem
Klientské aplikace PostgreSQL jsou připojené k primárnímu serveru pomocí názvu databázového serveru. Čtení aplikací se obsluhuje přímo z primárního serveru. Zároveň se potvrzení a zápisy potvrdí do aplikace až po zachování dat protokolu na primárním serveru i v pohotovostní replice. Kvůli této dodatečné odezvě můžou aplikace očekávat zvýšenou latenci zápisů a potvrzení. Stav vysoké dostupnosti můžete monitorovat na portálu.
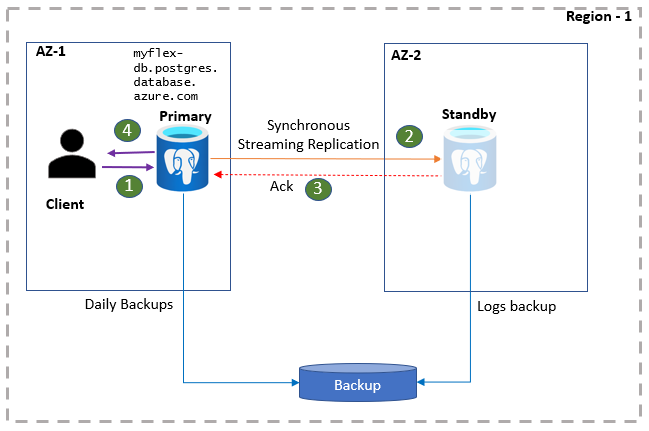
- Klienti se připojují k flexibilnímu serveru a provádějí operace zápisu.
- Změny se replikují do pohotovostní lokality.
- Primární obdrží potvrzení.
- Zápisy a potvrzení jsou potvrzeny.
Obnovení serverů s vysokou dostupností k určitému bodu v čase
Pro flexibilní servery nakonfigurované s vysokou dostupností se data protokolů replikují v reálném čase na pohotovostní server. Všechny chyby uživatelů na primárním serveru , například náhodné vyřazení tabulky nebo nesprávné aktualizace dat, se replikují do pohotovostní repliky. Pohotovostní režim tedy nemůžete použít k zotavení z takových logických chyb. Pokud chcete tyto chyby obnovit, musíte provést obnovení k určitému bodu v čase ze zálohy. Pomocí funkce obnovení k určitému bodu v čase flexibilního serveru můžete provést obnovení k času před výskytem chyby. Nový databázový server se obnoví jako flexibilní server s jednou zónou s novým uživatelským názvem serveru pro databáze nakonfigurované s vysokou dostupností. Obnovený server můžete použít pro několik případů použití:
Obnovený server můžete použít pro produkční prostředí a volitelně povolit vysokou dostupnost s pohotovostní replikou v jedné zóně nebo jiné zóně ve stejné oblasti.
Pokud chcete obnovit objekt, exportujte ho z obnoveného databázového serveru a naimportujte ho do produkčního databázového serveru.
Pokud chcete naklonovat databázový server pro účely testování a vývoje nebo provést obnovení pro jakékoli jiné účely, můžete provést obnovení k určitému bodu v čase.
Informace o tom, jak provést obnovení flexibilního serveru k určitému bodu v čase, najdete v tématu Obnovení flexibilního serveru k určitému bodu v čase.
Podpora převzetí služeb při selhání
Plánované převzetí služeb při selhání
Plánované výpadky zahrnují pravidelné aktualizace softwaru Azure a upgrady podverze. K vrácení primárního serveru do upřednostňované zóny dostupnosti můžete použít také plánované převzetí služeb při selhání. Při konfiguraci vysoké dostupnosti se tyto operace nejprve použijí na pohotovostní repliku, zatímco aplikace budou nadále přistupovat k primárnímu serveru. Po aktualizaci pohotovostní repliky se vyprázdní připojení primárního serveru a aktivuje se převzetí služeb při selhání, které aktivuje pohotovostní repliku tak, aby byla primární se stejným názvem databázového serveru. Klientské aplikace se musí znovu připojit se stejným názvem databázového serveru k novému primárnímu serveru a mohou pokračovat v jejich operacích. Nový pohotovostní server je vytvořen ve stejné zóně jako původní primární server.
U jiných operací iniciovaných uživatelem, jako je škálování výpočetních prostředků nebo škálování úložiště, se změny použijí nejprve v pohotovostním režimu následované primárním serverem. Služba v současné době nepodporuje převzetí služeb při selhání na pohotovostní server, proto při provádění operace škálování na primárním serveru dojde ke krátkému výpadku aplikací.
Tuto funkci můžete použít také k převzetí služeb při selhání na pohotovostní server s omezenou prostojem. Primární může být například v jiné zóně dostupnosti než aplikace po neplánovaném převzetí služeb při selhání. Primární server chcete přenést zpět do předchozí zóny, abyste mohli aplikaci společně přidělit.
Při provádění této funkce je pohotovostní server nejprve připravený, aby se zajistilo, že je zachycena nedávnými transakcemi, což aplikaci umožní pokračovat v provádění čtení a zápisů. Pohotovostní režim se pak zvýší a připojení k primárnímu serveru jsou přerušena. Aplikace může pokračovat v zápisu na primární server, zatímco nový pohotovostní server je vytvořen na pozadí. Toto jsou kroky spojené s plánovaným převzetím služeb při selhání:
| Step | Popis | Byl očekáváný výpadek aplikace? |
|---|---|---|
| 0 | Počkejte, až se pohotovostní server zachytí s primárním serverem. | No |
| 2 | Interní monitorovací systém zahájí pracovní postup převzetí služeb při selhání. | No |
| 3 | Zápisy aplikací se zablokují, když je pohotovostní server blízko primárního pořadového čísla protokolu (LSN). | Ano |
| 4 | Pohotovostní server je povýšen na nezávislý server. | Ano |
| 5 | Záznam DNS se aktualizuje o IP adresu nového pohotovostního serveru. | Ano |
| 6 | Aplikace pro opětovné připojení a obnovení jeho čtení a zápisu pomocí nové primární. | No |
| 7 | Vytvoří se nový pohotovostní server v jiné zóně. | No |
| 8 | Pohotovostní server začne obnovovat protokoly (z objektu blob Azure), které během svého zřízení vynechal. | No |
| 9 | Vytvoří se stabilní stav mezi primárním a pohotovostním serverem. | No |
| 10 | Proces plánovaného převzetí služeb při selhání je dokončený. | No |
Výpadek aplikace začíná v kroku 3 a může pokračovat v operaci po kroku 5. Zbývající kroky probíhají na pozadí, aniž by to mělo vliv na zápisy a potvrzení aplikace.
Tip
S flexibilním serverem můžete volitelně naplánovat aktivity údržby iniciované Platformou Azure tak, že zvolíte 60minutové časové období v den, kdy se očekává, že aktivity v databázích budou nízké. Úlohy údržby Azure, jako jsou opravy nebo upgrady podverze, by během tohoto okna probíhaly. Pokud nevyberete vlastní okno, pro váš server je vybraný systém přidělený 13:00 –7:00 místního času. Tyto aktivity údržby iniciované Azure se také provádějí na pohotovostní replice pro flexibilní servery, které jsou nakonfigurované se zónami dostupnosti.
Seznam možných plánovaných výpadků najdete v tématu Plánované výpadky.
Neplánované převzetí služeb při selhání
Neplánované výpadky můžou nastat v důsledku nepředvídatelných přerušení, jako jsou selhání hardwaru, problémy se sítí a chyby softwaru. Pokud databázový server nakonfigurovaný s vysokou dostupností neočekávaně klesne, aktivuje se pohotovostní replika a klienti můžou pokračovat v provozu. Pokud není nakonfigurovaná vysoká dostupnost(HA), pak pokud pokus o restartování selže, automaticky se zřídí nový databázový server. I když se neplánovaný výpadek nedá vyhnout, flexibilní server pomáhá zmírnit výpadky tím, že automaticky provádí operace obnovení bez nutnosti zásahu člověka.
Informace o neplánovaných převzetí služeb při selhání a výpadkech, včetně možných scénářů, najdete v tématu Zmírnění neplánovaných výpadků.
Testování převzetí služeb při selhání (vynucené převzetí služeb při selhání)
Při vynuceném převzetí služeb při selhání můžete při spouštění produkční úlohy simulovat neplánovaný scénář výpadku aplikace a sledovat výpadky aplikace. Vynucené převzetí služeb při selhání můžete použít také v případech, kdy primární server přestane reagovat.
Vynucené převzetí služeb při selhání zprovozní primární server a zahájí pracovní postup převzetí služeb při selhání, ve kterém se provádí operace pohotovostního povýšení. Jakmile pohotovostní režim dokončí proces obnovení až do posledního potvrzeného data, bude povýšen na primární server. Aktualizují se záznamy DNS a vaše aplikace se může připojit k primárnímu serveru se zvýšenou úroveň. Vaše aplikace může pokračovat v zápisu na primární server, zatímco nový pohotovostní server je navázán na pozadí, což nemá vliv na dobu provozu.
Při vynuceném převzetí služeb při selhání postupujte následovně:
| Step | Popis | Byl očekáváný výpadek aplikace? |
|---|---|---|
| 0 | Primární server se krátce po přijetí žádosti o převzetí služeb při selhání zastaví. | Ano |
| 2 | Aplikace narazí na výpadky, protože primární server je mimo provoz. | Ano |
| 3 | Interní monitorovací systém zjistí selhání a zahájí převzetí služeb při selhání na pohotovostní server. | Ano |
| 4 | Pohotovostní server přejde do režimu obnovení před úplným povýšení jako nezávislý server. | Ano |
| 5 | Proces převzetí služeb při selhání čeká na dokončení pohotovostního obnovení. | Ano |
| 6 | Jakmile je server vzhůru, záznam DNS se aktualizuje se stejným názvem hostitele, ale použije IP adresu pohotovostního režimu. | Ano |
| 7 | Aplikace se může znovu připojit k novému primárnímu serveru a pokračovat v operaci. | No |
| 8 | Navazuje se pohotovostní server v upřednostňované zóně. | No |
| 9 | Pohotovostní server začne obnovovat protokoly (z objektu blob Azure), které během svého zřízení vynechal. | No |
| 10 | Vytvoří se stabilní stav mezi primárním a pohotovostním serverem. | No |
| 11 | Proces vynucené převzetí služeb při selhání je dokončený. | No |
Očekává se, že se výpadek aplikace spustí po kroku 1 a trvá až do dokončení kroku 6. Zbývající kroky probíhají na pozadí, aniž by to mělo vliv na zápisy a potvrzení aplikace.
Důležité
Kompletní proces převzetí služeb při selhání zahrnuje převzetí služeb při selhání (a) na pohotovostní server po primárním selhání a (b) navazování nového pohotovostního serveru v stabilním stavu. Vzhledem k tomu, že u vaší aplikace dochází k výpadkům, dokud nedojde k převzetí služeb při selhání do pohotovostního režimu, změřte výpadek z hlediska aplikace nebo klienta místo celkového kompletního procesu převzetí služeb při selhání.
Důležité informace při provádění vynucených převzetí služeb při selhání
Celkový koncový čas operace může být považován za delší než skutečný výpadek, ke které aplikace došlo.
Důležité
Vždy sledujte výpadky z pohledu aplikace.
Neprovádějte okamžité převzetí služeb při selhání back-to-back. Počkejte alespoň 15 až 20 minut mezi převzetím služeb při selhání a povolte úplné navázání nového pohotovostního serveru.
Pokud chcete snížit výpadky, doporučujeme provést vynucené převzetí služeb při selhání během období nízké aktivity.
Osvědčené postupy pro statistiky PostgreSQL po převzetí služeb při selhání
Po převzetí služeb při selhání PostgreSQL primární mechanismus pro zachování optimálního výkonu databáze zahrnuje pochopení jedinečných rolí pg_statistic a tabulek pg_stat_* . Tabulka pg_statistic obsahuje statistiky optimalizátoru, které jsou pro plánovač dotazů zásadní. Tyto statistiky zahrnují distribuce dat v tabulkách a zůstávají nedotčené po převzetí služeb při selhání a zajišťují, aby plánovač dotazů mohl efektivně optimalizovat provádění dotazů na základě přesných historických informací o distribuci dat.
Naproti tomu tabulky, které zaznamenávají statistiky aktivit, pg_stat_* jako je počet kontrol, čtení řazených kolekcí členů a aktualizace, se při převzetí služeb při selhání resetují. Příkladem takové tabulky je pg_stat_user_tables, který sleduje aktivitu pro uživatelem definované tabulky. Toto resetování je navržené tak, aby přesně odráželo provozní stav nového primárního serveru, ale také znamená ztrátu historických metrik aktivit, které by mohly informovat proces automatického úklidu a další provozní efektivitu.
Vzhledem k tomuto rozdílu je osvědčeným postupem po převzetí služeb při selhání PostgreSQL spuštění ANALYZE. Tato akce aktualizuje pg_stat_* tabulky, jako je pg_stat_user_tablesnapříklad , s čerstvými statistikami aktivit, pomáhá procesu automatického úklidu a zajištění optimálního výkonu databáze ve své nové roli. Tento proaktivní krok překlenuje mezeru mezi zachováním základních statistik optimalizátoru a aktualizací metrik aktivit tak, aby odpovídal aktuálnímu stavu databáze.
Prostředí pro zónu dolů
Zónové: Pokud se chcete zotavit ze selhání na úrovni zóny, můžete provést obnovení k určitému bodu v čase pomocí zálohy. Pokud chcete obnovit nejnovější data, můžete zvolit vlastní bod obnovení s nejnovějším časem. Nový flexibilní server se nasadí v jiné nefikované zóně. Doba potřebná k obnovení závisí na předchozím zálohování a objemu transakčních protokolů, které se mají obnovit.
Další informace o obnovení k určitému bodu v čase najdete v tématu Zálohování a obnovení na flexibilním serveru Azure Database for PostgreSQL.
Zónově redundantní: Flexibilní server se automaticky převezme při selhání na pohotovostní server během 60 až 120 sekund s nulovou ztrátou dat.
Konfigurace bez zón dostupnosti
I když se nedoporučuje, můžete flexibilní server nakonfigurovat bez povolené vysoké dostupnosti. Pro flexibilní servery nakonfigurované bez vysoké dostupnosti poskytuje služba místní redundantní úložiště se třemi kopiemi dat, zónově redundantním zálohováním (v oblastech, kde je podporováno) a integrovanou odolnost serveru k automatickému restartování chybového serveru a přemístění serveru do jiného fyzického uzlu. V této konfiguraci se nabízí smlouva SLA o dostupnosti 99,9 %. Během plánovaných nebo neplánovaných událostí převzetí služeb při selhání služba udržuje dostupnost serverů pomocí následujícího automatizovaného postupu:
- Zřídí se nový výpočetní virtuální počítač s Linuxem.
- Úložiště s datovými soubory se mapuje na nový virtuální počítač.
- Databázový stroj PostgreSQL je na novém virtuálním počítači online.
Následující obrázek ukazuje přechod mezi selháním virtuálního počítače a úložištěm.

Zotavení po havárii napříč oblastmi a provozní kontinuita
V případě havárie v celé oblasti může Azure poskytovat ochranu před regionálními nebo velkými zeměpisnými katastrofami s zotavením po havárii tím, že využívá jinou oblast. Další informace o architektuře zotavení po havárii Azure najdete v tématu Architektura zotavení po havárii Azure do Azure.
Flexibilní server poskytuje funkce, které chrání data a snižují výpadky pro důležité databáze během plánovaných a neplánovaných výpadků. Flexibilní server založený na infrastruktuře Azure, která nabízí robustní odolnost a dostupnost, nabízí funkce provozní kontinuity, které poskytují ochranu proti chybám, řeší požadavky na dobu obnovení a snižují riziko ztráty dat. Při navrhování aplikací byste měli zvážit odolnost proti výpadkům – plánovanou dobu obnovení (RTO) a expozici ztráty dat – cíl bodu obnovení (RPO). Například vaše databáze pro důležité obchodní informace vyžaduje přísnější dobu provozu než testovací databáze.
Zotavení po havárii v geografické oblasti s více oblastmi
Geograficky redundantní zálohování a obnovení
Geograficky redundantní zálohování a obnovení umožňuje obnovit server v jiné oblasti v případě havárie. Poskytuje také alespoň 99,9999999999999999 % (16 devítek) stálost zálohovaných objektů za rok.
Geograficky redundantní zálohování je možné nakonfigurovat pouze při vytváření serveru. Pokud je server nakonfigurovaný s geograficky redundantním zálohováním, data záloh a transakční protokoly se kopírují do spárované oblasti asynchronně prostřednictvím replikace úložiště.
Další informace o geograficky redundantním zálohování a obnovení najdete v tématu geograficky redundantní zálohování a obnovení.
Čtení replik
Repliky pro čtení mezi oblastmi je možné nasadit za účelem ochrany databází před selháními na úrovni oblasti. Repliky pro čtení se aktualizují asynchronně pomocí technologie fyzické replikace PostgreSQL a můžou zpožďovat primární replikaci. Repliky pro čtení se podporují ve výpočetních úrovních pro obecné účely a optimalizovány pro paměť.
Další informace o funkcích a aspektech čtení replik najdete v tématu Repliky pro čtení.
Detekce výpadků, oznámení a správa
Pokud je váš server nakonfigurovaný s geograficky redundantním zálohováním, můžete provést geografické obnovení ve spárované oblasti. Nový server se zřídí a obnoví na poslední dostupná data, která byla zkopírována do této oblasti.
Můžete také použít repliky pro čtení mezi oblastmi. V případě selhání oblasti můžete provést operaci zotavení po havárii zvýšením úrovně repliky pro čtení na samostatný server pro čtení i zápis. Očekává se, že cíl bodu obnovení bude až 5 minut (ztráta dat možná), s výjimkou případu závažného regionálního selhání, kdy se cíl bodu obnovení může v době selhání blížit prodlevě replikace.
Další informace o zmírnění neplánovaných výpadků a zotavení po regionální havárii najdete v tématu Zmírnění neplánovaných výpadků.