Řešení potíží a identifikace pomalých dotazů na flexibilním serveru Azure Database for PostgreSQL
PLATÍ PRO:  Flexibilní server Azure Database for PostgreSQL
Flexibilní server Azure Database for PostgreSQL
Tento článek popisuje, jak identifikovat a diagnostikovat původní příčinu pomalých dotazů.
V tomto článku se dozvíte:
- Jak identifikovat pomalé dotazy
- Jak identifikovat pomalý postup spolu s ním. Identifikujte pomalý dotaz mezi seznamem dotazů, které patří do stejné pomalé uložené procedury.
Požadavky
Průvodce odstraňováním potíží povolte podle kroků popsaných v průvodcích odstraňováním potíží.
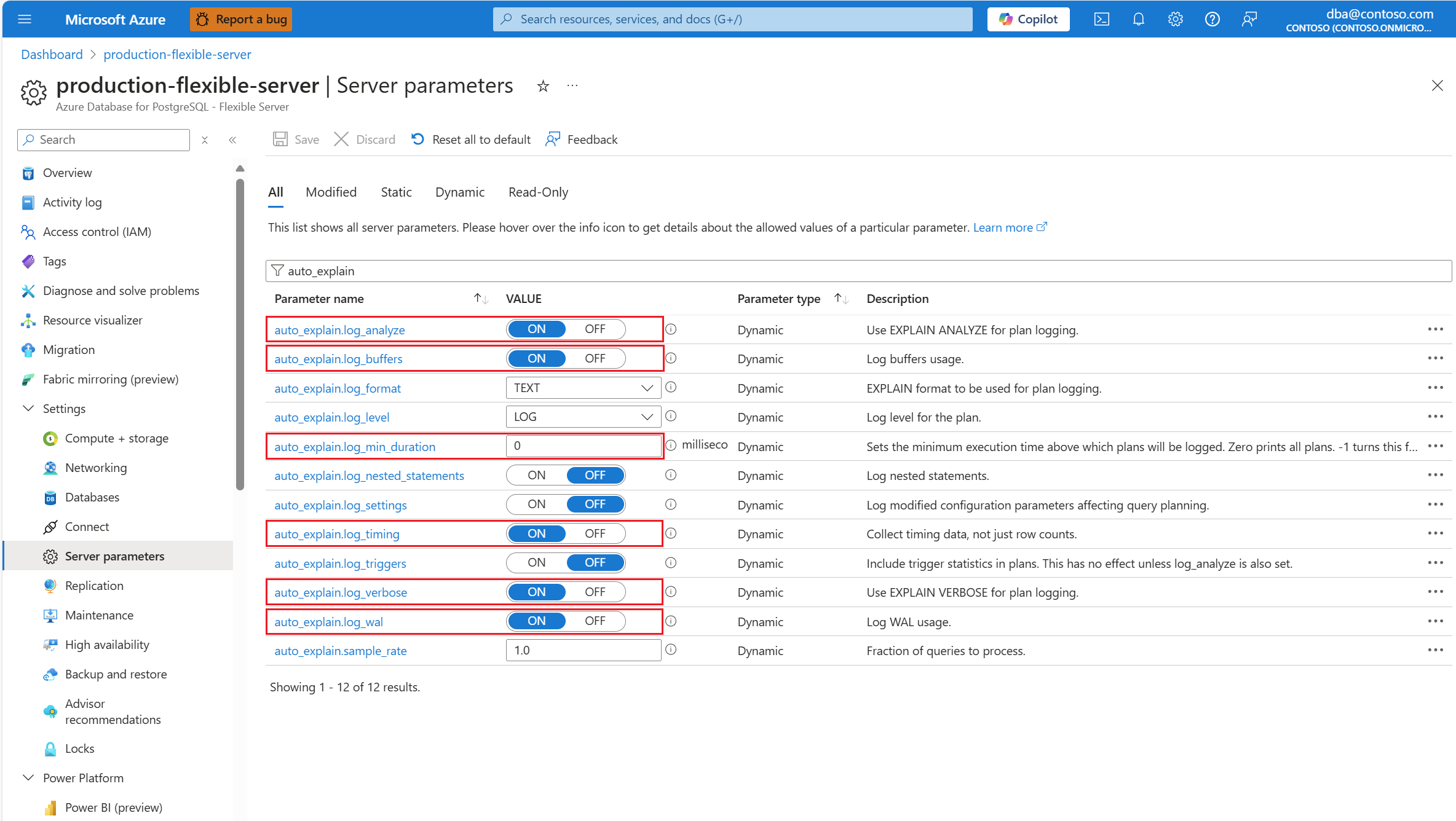
auto_explainNakonfigurujte rozšíření tak, že rozšíření povolíte a načtete.Po nakonfigurování
auto_explainrozšíření změňte následující parametry serveru, které řídí chování rozšíření:auto_explain.log_analyzenaON.auto_explain.log_buffersnaON.auto_explain.log_min_durationpodle toho, co je rozumné ve vašem scénáři.auto_explain.log_timingnaON.auto_explain.log_verbosenaON.

Poznámka:
Pokud nastavíte auto_explain.log_min_duration hodnotu 0, rozšíření spustí protokolování všech spuštěných dotazů na serveru. To může mít vliv na výkon databáze. Je třeba provést správnou hloubkovou kontrolu, aby přišla na hodnotu, která je považována za pomalou na serveru. Pokud se například všechny dotazy dokončí za méně než 30 sekund a to je přijatelné pro vaši aplikaci, doporučujeme aktualizovat parametr na 30000 milisekund. Tím se zapíše jakýkoli dotaz, který trvá déle než 30 sekund.
Identifikace pomalého dotazu
Při použití průvodců odstraňováním potíží a auto_explain rozšíření popisujeme scénář pomocí příkladu.
Máme scénář, kdy využití procesoru narůstá na 90 % a chceme určit příčinu špičky. Pokud chcete scénář ladit, postupujte takto:
Jakmile budete upozorněni scénářem procesoru, v nabídce prostředků ovlivněné instance flexibilního serveru Azure Database for PostgreSQL v části Monitorování vyberte Průvodce odstraňováním potíží.
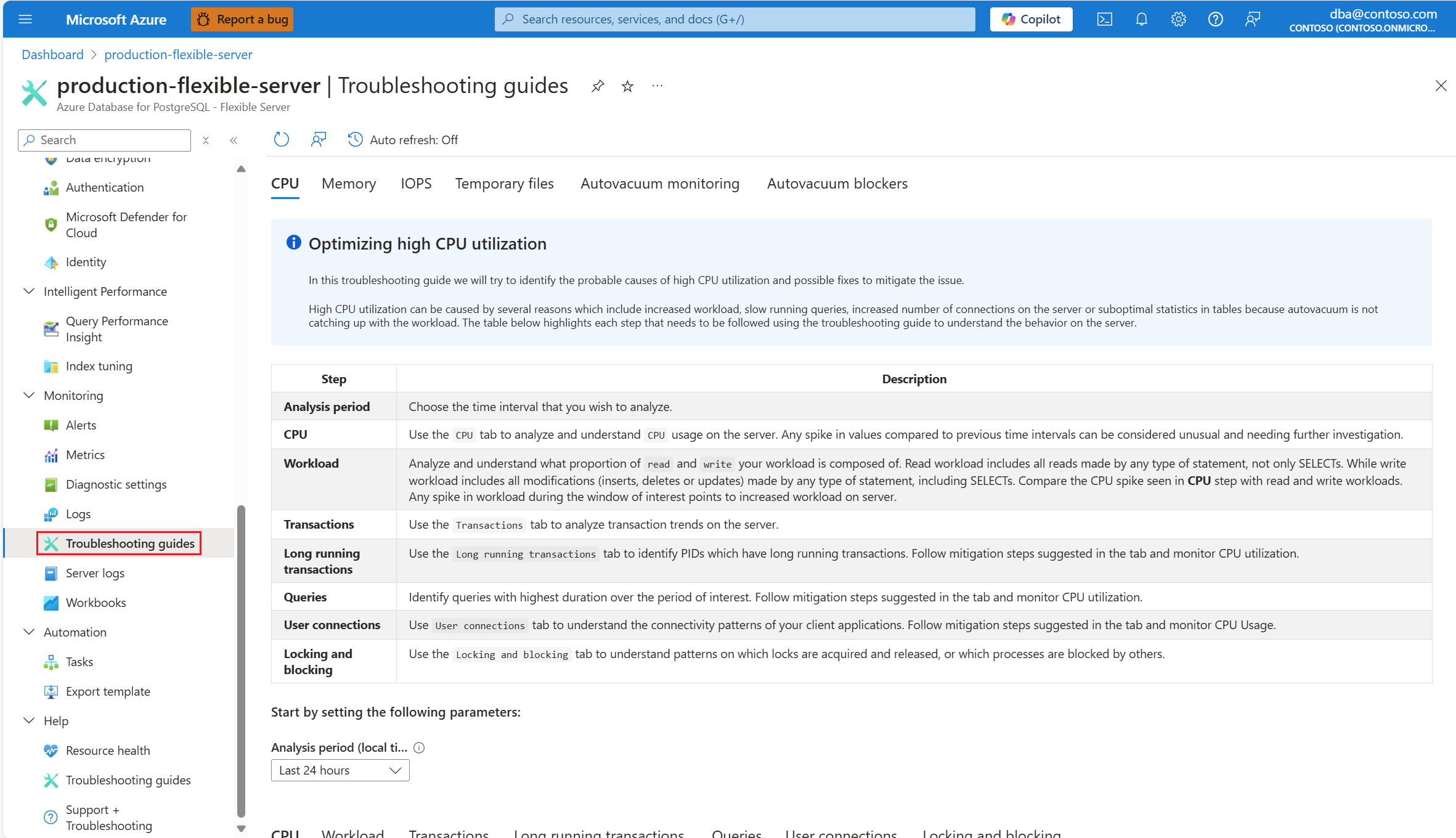
Vyberte kartu CPU. Otevře se průvodce optimalizací vysokého využití procesoru.
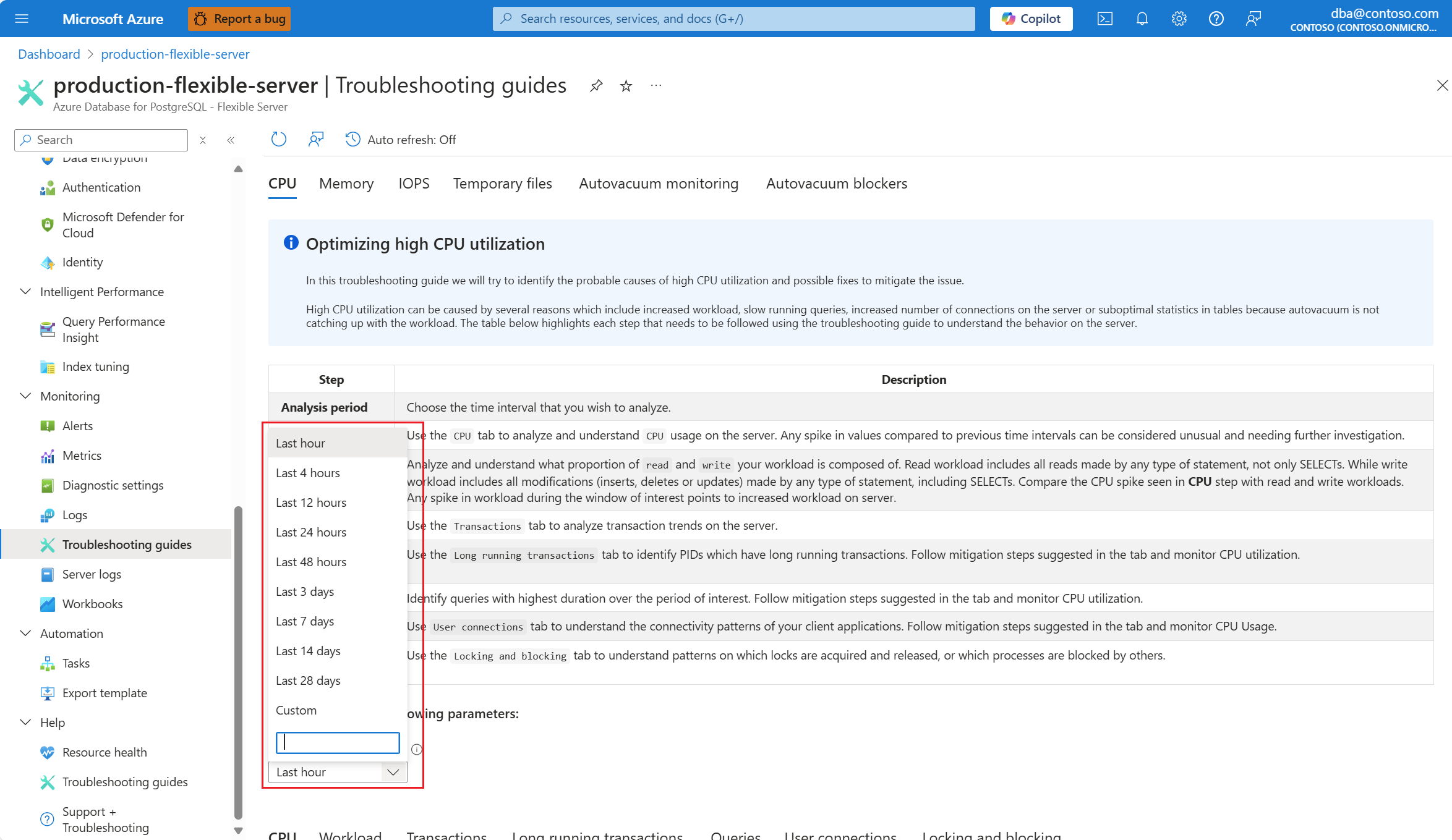
V rozevíracím seznamu Období analýzy (místní čas) vyberte časový rozsah, na který chcete analýzu zaměřit.
Vyberte kartu Dotazy . Zobrazuje podrobnosti o všech dotazech spuštěných v intervalu, kdy se zobrazilo 90% využití procesoru. Ze snímku to vypadá, že dotaz s nejpomalejší průměrnou dobou provádění během časového intervalu byl ~2,6 minuty a dotaz během intervalu běžel 22krát. Tento dotaz je nejpravděpodobnější příčinou špiček procesoru.
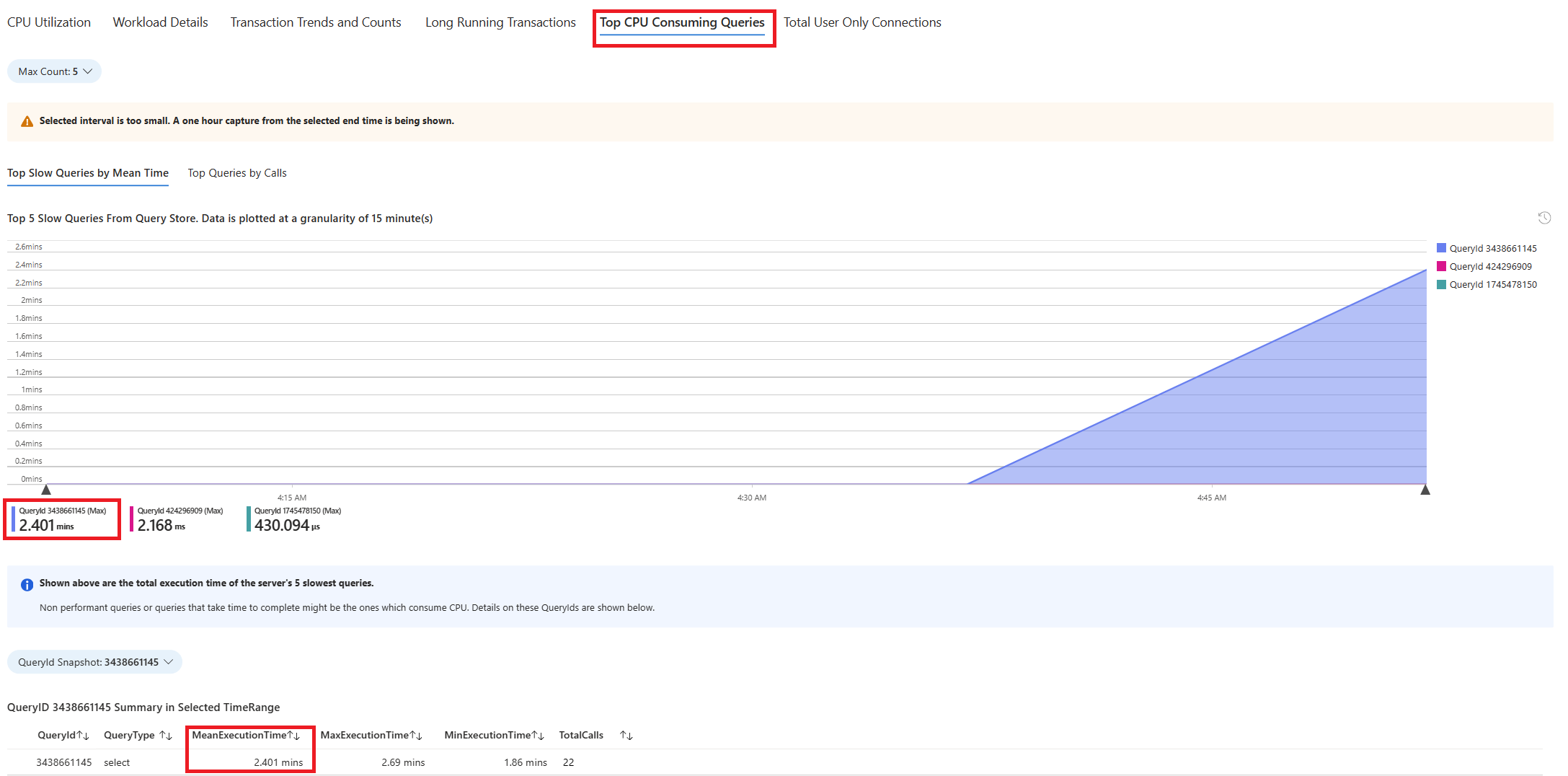
Pokud chcete načíst skutečný text dotazu, připojte se k
azure_sysdatabázi a spusťte následující dotaz.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- V tomto příkladu byl nalezen pomalý dotaz:
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Pokud chcete zjistit, jaký přesný plán vysvětlení se vygeneroval, použijte protokoly flexibilního serveru Azure Database for PostgreSQL. Pokaždé, když dotaz během tohoto časového intervalu dokončil provádění,
auto_explainby rozšíření mělo v protokolech zapsat položku. V nabídce prostředků v části Monitorování vyberte Protokoly.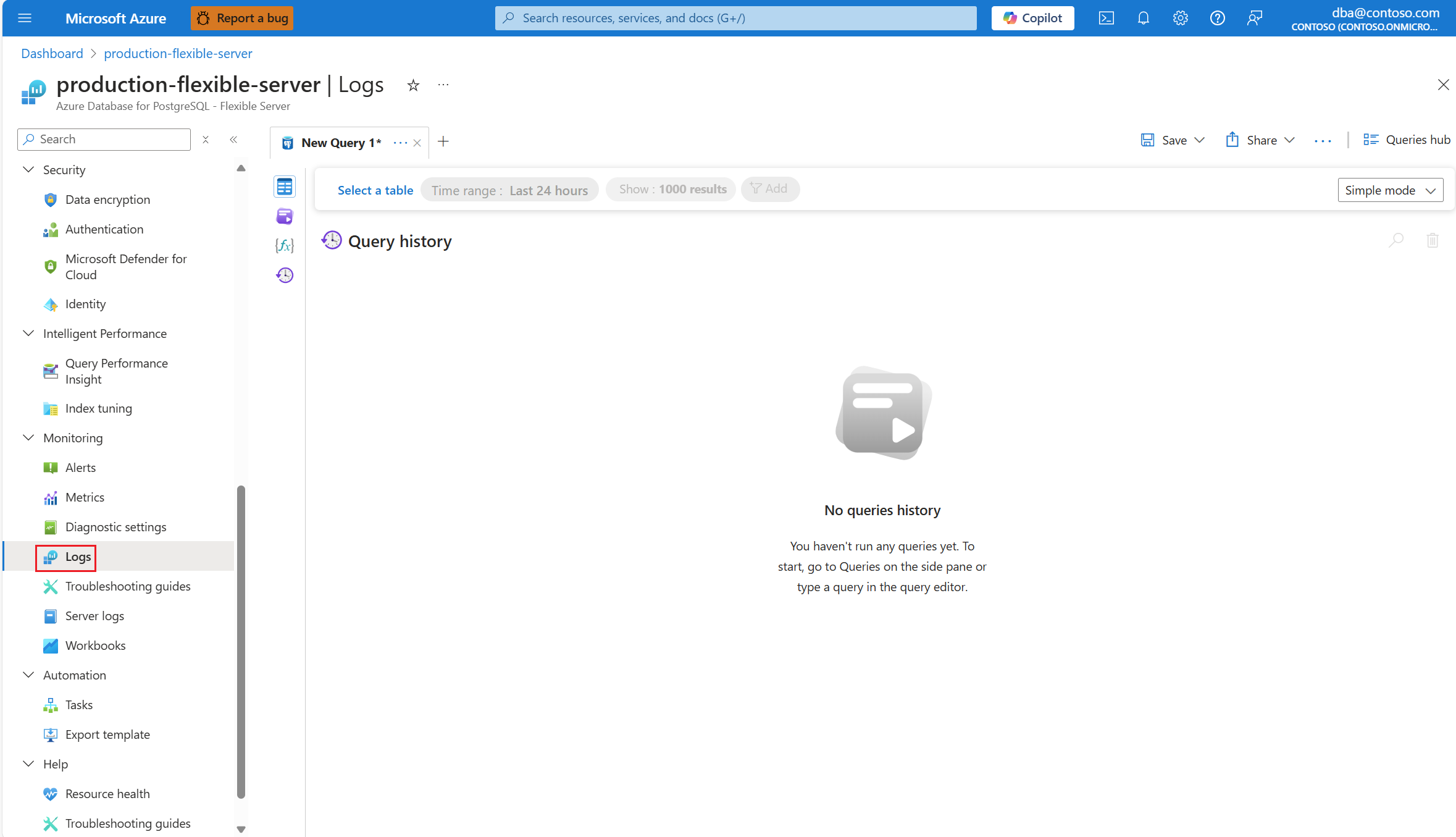
Vyberte časový rozsah, ve kterém bylo nalezeno 90% využití procesoru.
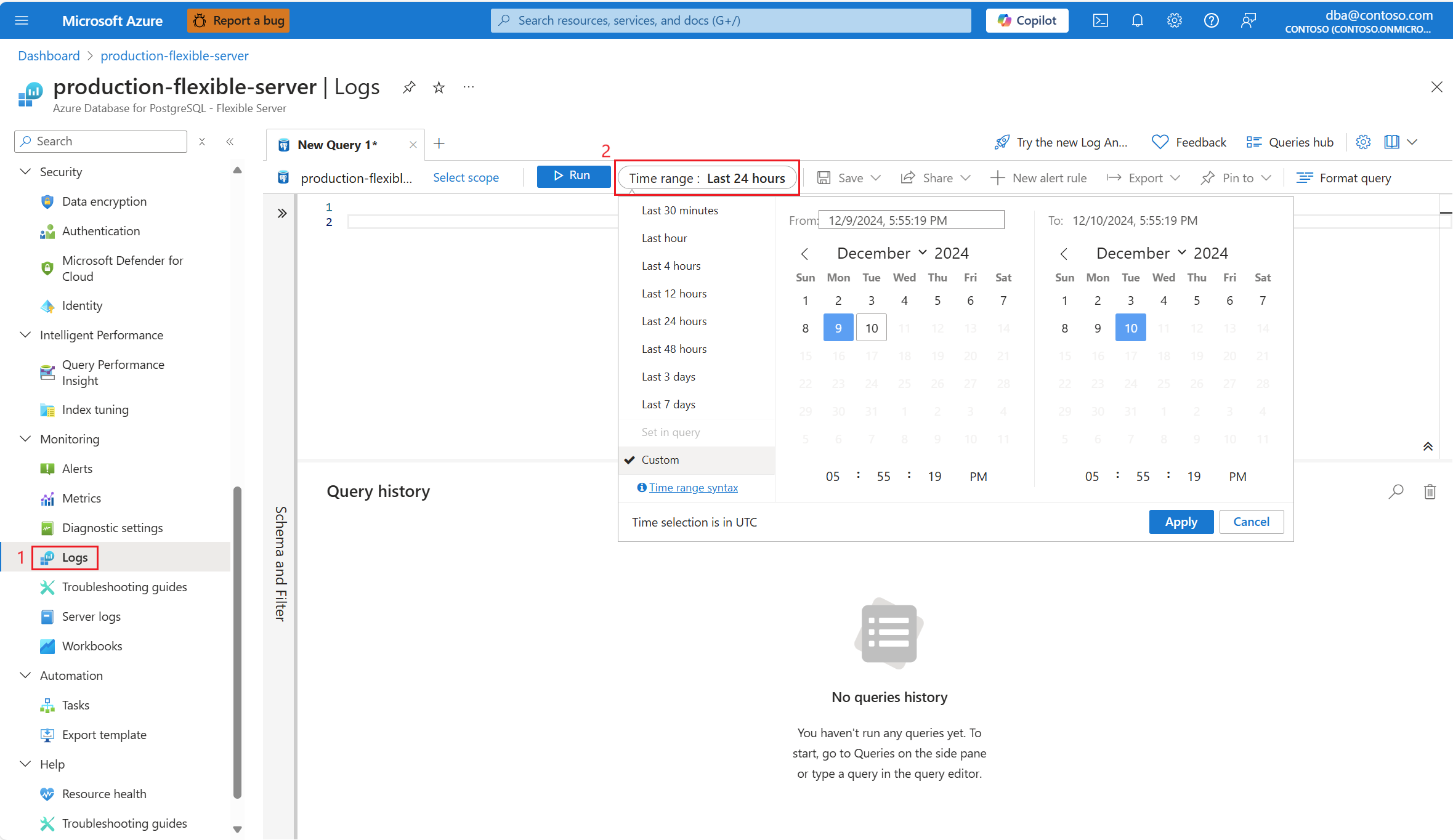
Spuštěním následujícího dotazu načtěte výstup funkce EXPLAIN ANALYZE pro identifikovaný dotaz.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Sloupec zprávy ukládá plán provádění, jak je znázorněno v tomto výstupu:
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Dotaz se spustil přibližně 2,5 minuty, jak je znázorněno v průvodci odstraňováním potíží. Hodnota duration 150692,864 ms z výstupu prováděcího plánu ho potvrdí. Pomocí výstupu funkce EXPLAIN ANALYZE můžete dále řešit potíže a vyladit dotaz.
Poznámka:
Pozorovatel, že dotaz během intervalu běžel 22krát a zobrazené protokoly obsahují jednu z těchto položek zachycených během intervalu.
Identifikace pomalého dotazu v uložené proceduře
Pomocí průvodců odstraňováním potíží a auto_explain rozšířením vysvětlujeme scénář pomocí příkladu.
Máme scénář, kdy využití procesoru narůstá na 90 % a chceme určit příčinu špičky. Pokud chcete scénář ladit, postupujte takto:
Jakmile budete upozorněni scénářem procesoru, v nabídce prostředků ovlivněné instance flexibilního serveru Azure Database for PostgreSQL v části Monitorování vyberte Průvodce odstraňováním potíží.
Vyberte kartu CPU. Otevře se průvodce optimalizací vysokého využití procesoru.
V rozevíracím seznamu Období analýzy (místní čas) vyberte časový rozsah, na který chcete analýzu zaměřit.
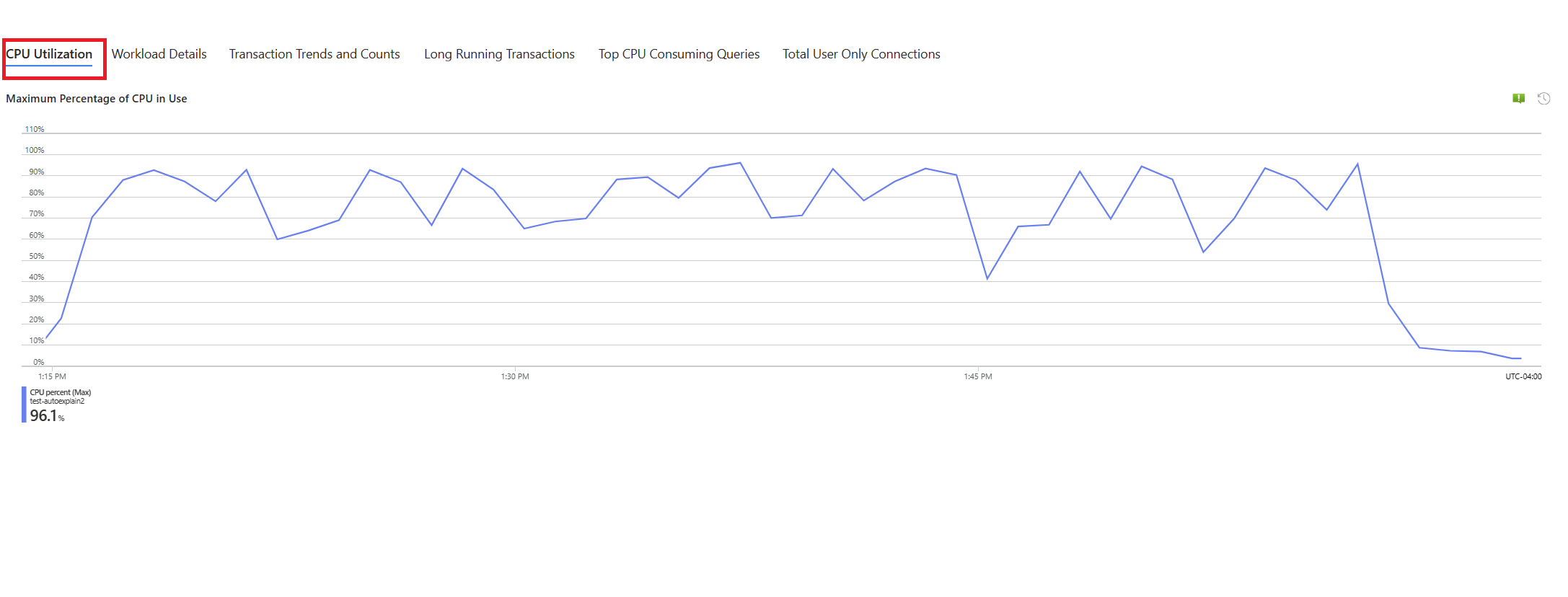
Vyberte kartu Dotazy . Zobrazuje podrobnosti o všech dotazech spuštěných v intervalu, kdy se zobrazilo 90% využití procesoru. Ze snímku to vypadá, že dotaz s nejpomalejší průměrnou dobou provádění během časového intervalu byl ~2,6 minuty a dotaz během intervalu běžel 22krát. Tento dotaz je nejpravděpodobnější příčinou špiček procesoru.

Připojte se k azure_sys databázi a spusťte dotaz, který načte skutečný text dotazu pomocí následujícího skriptu.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- V tomto příkladu byl nalezen pomalý dotaz uložená procedura:
call autoexplain_test ();
- Pokud chcete zjistit, jaký přesný plán vysvětlení se vygeneroval, použijte protokoly flexibilního serveru Azure Database for PostgreSQL. Pokaždé, když dotaz během tohoto časového intervalu dokončil provádění,
auto_explainby rozšíření mělo v protokolech zapsat položku. V nabídce prostředků v části Monitorování vyberte Protokoly. Potom v časovém rozsahu vyberte časové okno, ve kterém chcete analýzu zaměřit.

- Spuštěním následujícího dotazu načtěte výstup analýzy zjištěného dotazu.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
Tento postup obsahuje několik dotazů, které jsou zvýrazněné níže. Vysvětlení analýzy výstupu každého dotazu použitého v uložené proceduře se zaprotokoluje za účelem další analýzy a řešení potíží. Čas spuštění zaprotokolovaných dotazů lze použít k identifikaci nejpomalejších dotazů, které jsou součástí uložené procedury.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Poznámka:
Pro demonstrační účely se zobrazí výstup EXPLAIN ANALYZE pouze s několika dotazy použitými v postupu. Cílem je shromáždit výstup FUNKCE EXPLAIN ANALYZE všech dotazů z protokolů a identifikovat nejpomalejší z nich a pokusit se je vyladit.
Související obsah
- Řešení potíží s vysokým využitím procesoru v Azure Database for PostgreSQL – flexibilní server.
- Řešení potíží s vysokým využitím IOPS na flexibilním serveru Azure Database for PostgreSQL
- Řešení potíží s vysokým využitím paměti na flexibilním serveru Azure Database for PostgreSQL
- Parametry serveru na flexibilním serveru Azure Database for PostgreSQL
- Automatické ladění na flexibilním serveru Azure Database for PostgreSQL