Použití doporučení indexů vytvořených laděním indexů na flexibilním serveru Azure Database for PostgreSQL
Ladění indexu zachovává doporučení, která provádí v sadě tabulek umístěných ve intelligentperformance schématu azure_sys v databázi.
V současné době je možné tyto informace číst pomocí sestavení stránky webu Azure Portal pro tento účel nebo spuštěním dotazů načíst data ze dvou zobrazení dostupných uvnitř intelligent performance azure_sys databáze.
Využívání doporučení indexu prostřednictvím webu Azure Portal
Přihlaste se k webu Azure Portal a vyberte instanci flexibilního serveru Azure Database for PostgreSQL.
V nabídce vyberte Ladění indexu v části Inteligentní výkon .
Pokud je funkce povolená, ale zatím se nevygenerují žádná doporučení, obrazovka vypadá takto:
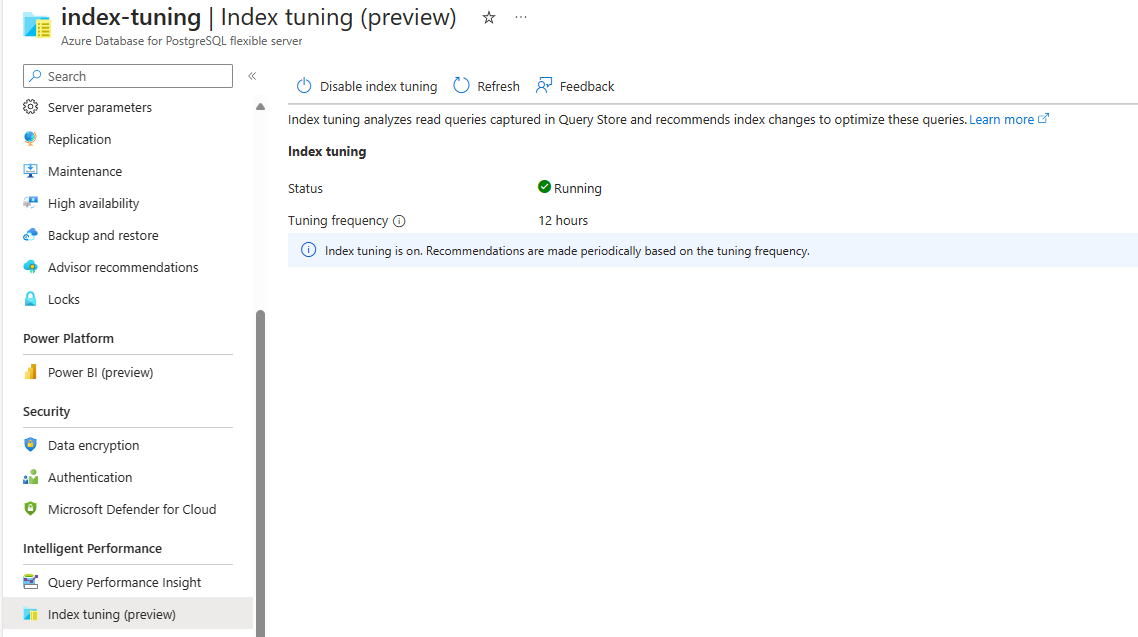
Pokud je tato funkce aktuálně zakázaná a v minulosti nikdy nevygeneroval doporučení, obrazovka vypadá takto:
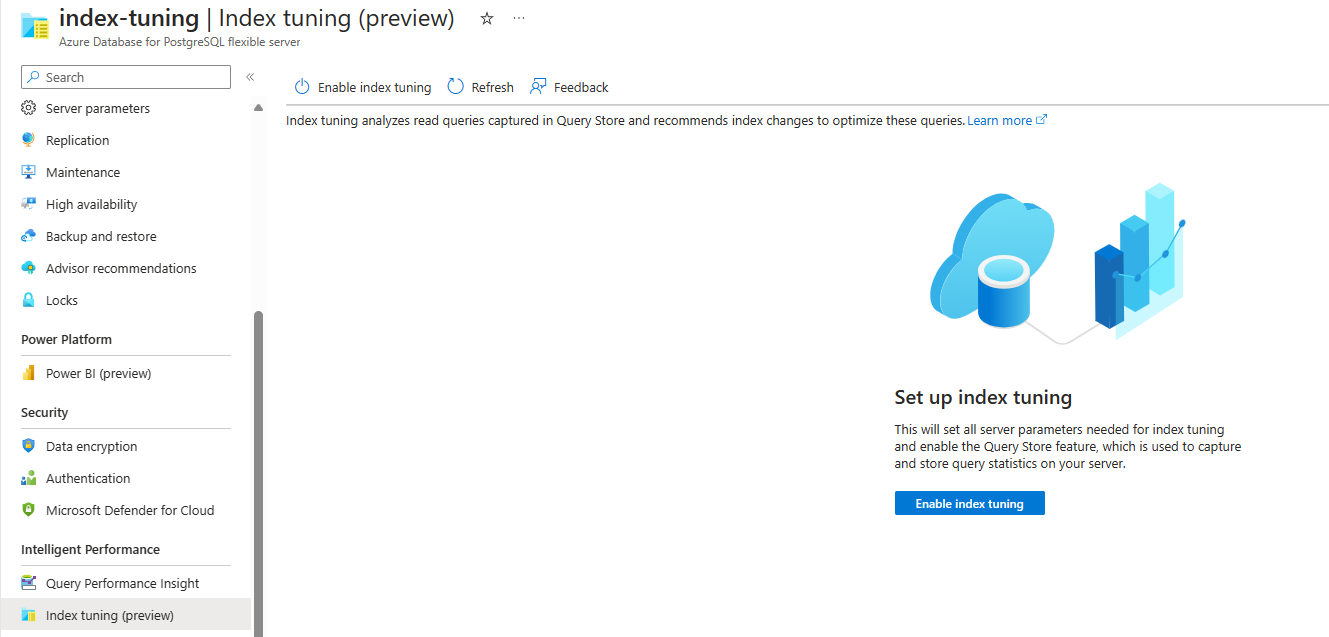
Pokud je tato funkce povolená a zatím se nevygenerují žádná doporučení, obrazovka vypadá takto:
Pokud je tato funkce zakázaná, ale někdy vytvořila doporučení, obrazovka vypadá takto:
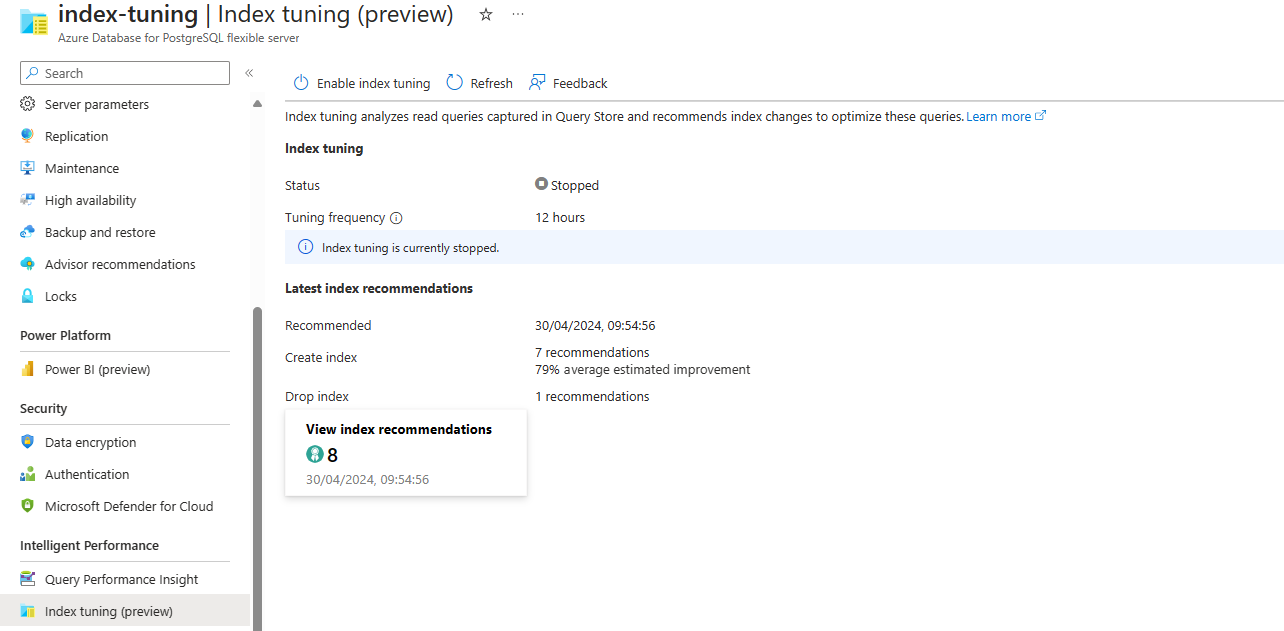
Pokud jsou k dispozici doporučení, vyberte pro zobrazení souhrnu doporučení indexu přístup k úplnému seznamu:
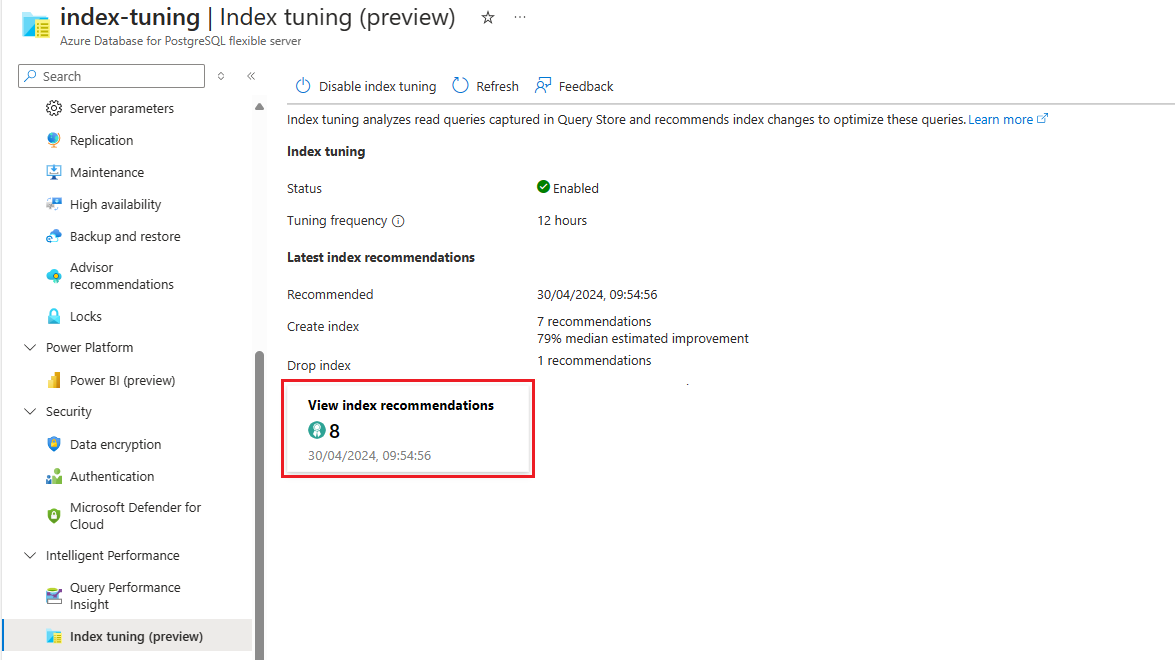
V seznamu se zobrazují všechna dostupná doporučení s podrobnostmi o jednotlivých z nich. Ve výchozím nastavení je seznam seřazený podle posledního doporučeného pořadí v sestupném pořadí a zobrazuje nejnovější doporučení v horní části. Můžete ale řadit podle libovolného jiného sloupce a pomocí pole filtrování omezit seznam položek zobrazených na ty položky, jejichž databáze, schéma nebo názvy tabulek obsahují zadaný text:
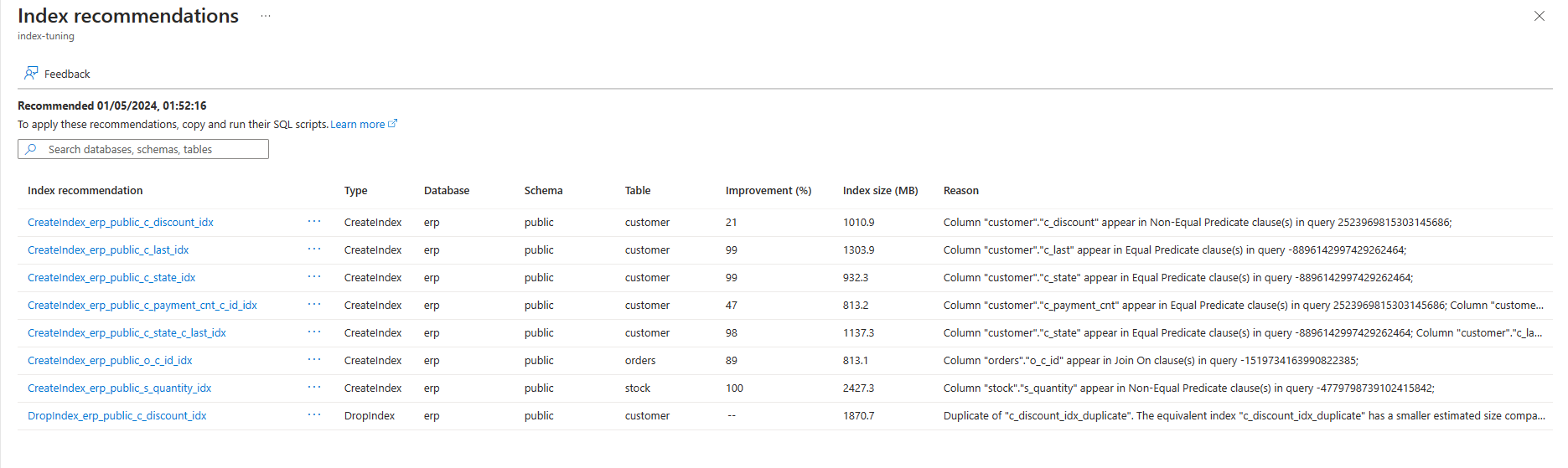
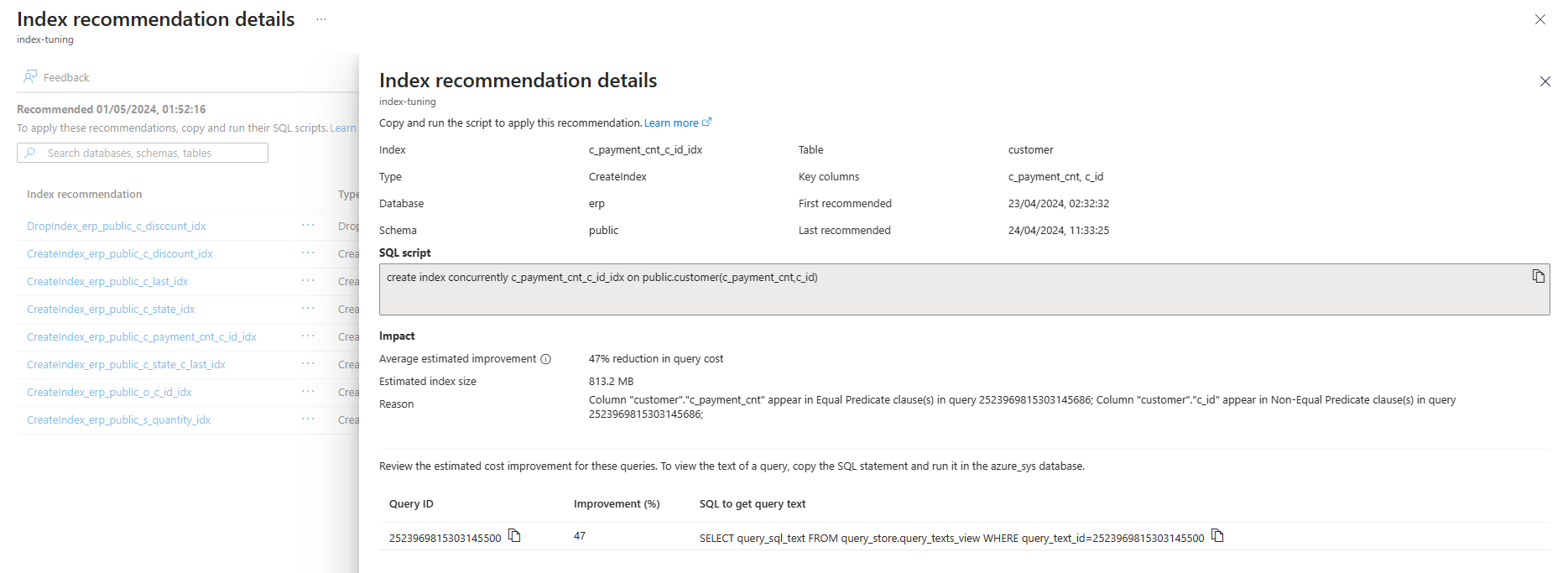
Pokud chcete zobrazit další informace o jakémkoli konkrétním doporučení, vyberte název tohoto doporučení a na pravé straně obrazovky se otevře podokno podrobností o doporučení indexu, kde se zobrazí všechny dostupné podrobnosti o doporučení:






Využívání doporučení indexů prostřednictvím zobrazení dostupných v databázi azure_sys
- Připojte se k
azure_sysdatabázi dostupné na vašem serveru s libovolnou rolí, která má oprávnění k připojení k instanci.publicČlenové role mohou číst z těchto zobrazení. - Spuštěním dotazů v
sessionszobrazení načtěte podrobnosti o relacích doporučení. - Spuštěním dotazů v
recommendationszobrazení načtěte doporučení vytvořená laděním indexu pro CREATE INDEX a DROP INDEX.
Zobrazení
Zobrazení v azure_sys databázi poskytují pohodlný způsob, jak získat přístup k doporučením indexu vygenerovaným laděním indexů a načítat je. Konkrétně zobrazení createindexrecommendations dropindexrecommendations obsahují podrobné informace o doporučeních CREATE INDEX a DROP INDEX. Tato zobrazení zveřejňují data, jako je ID relace, název databáze, typ poradce, časy spuštění a zastavení relace ladění, ID doporučení, typ doporučení, důvod doporučení a další relevantní podrobnosti. Dotazováním na tato zobrazení můžou uživatelé snadno přistupovat k doporučením indexů vytvořeným laděním indexů a analyzovat je.
intelligentperformance.sessions
Zobrazení sessions zveřejňuje všechny podrobnosti pro všechny relace ladění indexu.
| název sloupce | datový typ | Popis |
|---|---|---|
| session_id | Uuid | Globálně jedinečný identifikátor přiřazený ke každé nové relaci ladění, která se zahájí. |
| database_name | varchar(64) | Název databáze, ve které byl spuštěn kontext relace ladění indexu. |
| session_type | intelligentperformance.recommendation_type | Označuje typy doporučení, která by mohla tato relace ladění indexu vytvořit. Možné hodnoty jsou: CreateIndex, DropIndex. Relace typu CreateIndex můžou vytvářet doporučení typu CreateIndex . Relace typu DropIndex můžou vytvářet doporučení DropIndex nebo ReIndex typy. |
| run_type | intelligentperformance.recommendation_run_type | Označuje způsob, jakým byla tato relace zahájena. Možné hodnoty jsou: Scheduled. Relace se automaticky provádějí podle hodnoty index_tuning.analysis_interval, jsou přiřazeny typ Scheduledspuštění . |
| state | intelligentperformance.recommendation_state | Označuje aktuální stav relace. Možné hodnoty jsou: Error, Success, InProgress. Relace, jejichž spuštění selhalo, jsou nastaveny jako Error. Relace, které správně dokončily provádění, ať už vygenerovaly doporučení, jsou nastaveny jako Success. Relace, které se stále spouští, jsou nastaveny jako InProgress. |
| start_time | časové razítko bez časového pásma | Časové razítko, ve kterém byla spuštěna relace ladění, která toto doporučení vytvořila. |
| stop_time | časové razítko bez časového pásma | Časové razítko, ve kterém byla spuštěna relace ladění, která toto doporučení vytvořila. Hodnota NULL, pokud probíhá relace nebo byla přerušena kvůli nějaké chybě. |
| recommendations_count | integer | Celkový počet doporučení vytvořených v této relaci |
intelligentperformance.recommendations
Zobrazení recommendations zveřejňuje všechny podrobnosti pro všechna doporučení vygenerovaná v jakékoli relaci ladění, jejíž data jsou stále k dispozici v podkladových tabulkách.
| název sloupce | datový typ | Popis |
|---|---|---|
| recommendation_id | integer | Číslo, které jednoznačně identifikuje doporučení na celém serveru. |
| last_known_session_id | Uuid | Každé relaci ladění indexu má přiřazen globálně jedinečný identifikátor. Hodnota v tomto sloupci představuje relaci, která toto doporučení vytvořila naposledy. |
| database_name | varchar(64) | Název databáze, ve které byl vytvořen kontext doporučení. |
| recommendation_type | intelligentperformance.recommendation_type | Označuje typ vytvořeného doporučení. Možné hodnoty jsou: CreateIndex, DropIndex, ReIndex. |
| initial_recommended_time | časové razítko bez časového pásma | Časové razítko, ve kterém byla spuštěna relace ladění, která toto doporučení vytvořila. |
| last_recommended_time | časové razítko bez časového pásma | Časové razítko, ve kterém byla spuštěna relace ladění, která toto doporučení vytvořila. |
| times_recommended | integer | Časové razítko, ve kterém byla spuštěna relace ladění, která toto doporučení vytvořila. |
| reason | text | Důvod odůvodnění, proč bylo toto doporučení vytvořeno. |
| recommendation_context | json | Obsahuje seznam identifikátorů dotazů pro dotazy ovlivněné doporučením, typ doporučeného indexu, název schématu a název tabulky, pro kterou se index doporučuje, sloupce indexu, název indexu a odhadovanou velikost v bajtech doporučeného indexu. |
Důvody pro vytvoření doporučení indexu
Když ladění indexu doporučuje vytvoření indexu, přidá alespoň jeden z následujících důvodů:
| Důvod |
|---|
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
Důvody pro vyřazení doporučení indexu
Při ladění indexu se identifikují všechny indexy, které jsou označené jako neplatné, navrhuje ho odstranit z následujícího důvodu:
The index is invalid and the recommended recovery method is to reindex.
Další informace o tom, proč a kdy jsou indexy označené jako neplatné, najdete v oficiální dokumentaci k REINDEX v PostgreSQL.
Důvody pro vyřazení doporučení indexu
Při ladění indexu zjistí index, který se alespoň nepoužívá pro počet dnů nastavených index_tuning.unused_min_period, navrhuje, aby ho shodil s následujícím důvodem:
The index is unused in the past <days_unused> days.
Když ladění indexu zjistí duplicitní indexy, jeden z duplicit přežije a navrhne vyřazení zbývajících indexů. Zadaný důvod má vždy následující počáteční text:
Duplicate of <surviving_duplicate>.
Následuje další text, který vysvětluje důvod, proč byly vybrány pro odstranění jednotlivých duplicit:
| Důvod |
|---|
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
Pokud je index nejen vyměnitelný z důvodu duplikace, ale také se nepoužívá pro alespoň počet dnů nastavených index_tuning.unused_min_periodv , k důvodu se připojí následující text:
Also, the index is unused in the past <days_unused> days.
Použití doporučení indexu
Doporučení indexu obsahují příkaz SQL, který můžete provést pro implementaci doporučení.
Následující části ukazují, jak lze tento příkaz získat pro konkrétní doporučení.
Jakmile budete mít příkaz, můžete k připojení k serveru použít libovolného klienta PostgreSQL a použít doporučení.
Získání příkazu SQL prostřednictvím stránky ladění indexu na webu Azure Portal
Přihlaste se k webu Azure Portal a vyberte instanci flexibilního serveru Azure Database for PostgreSQL.
V nabídce vyberte Ladění indexu v části Inteligentní výkon .
Za předpokladu, že ladění indexu už vytvořilo doporučení, vyberte souhrn doporučení k indexu, abyste získali přístup k seznamu dostupných doporučení.
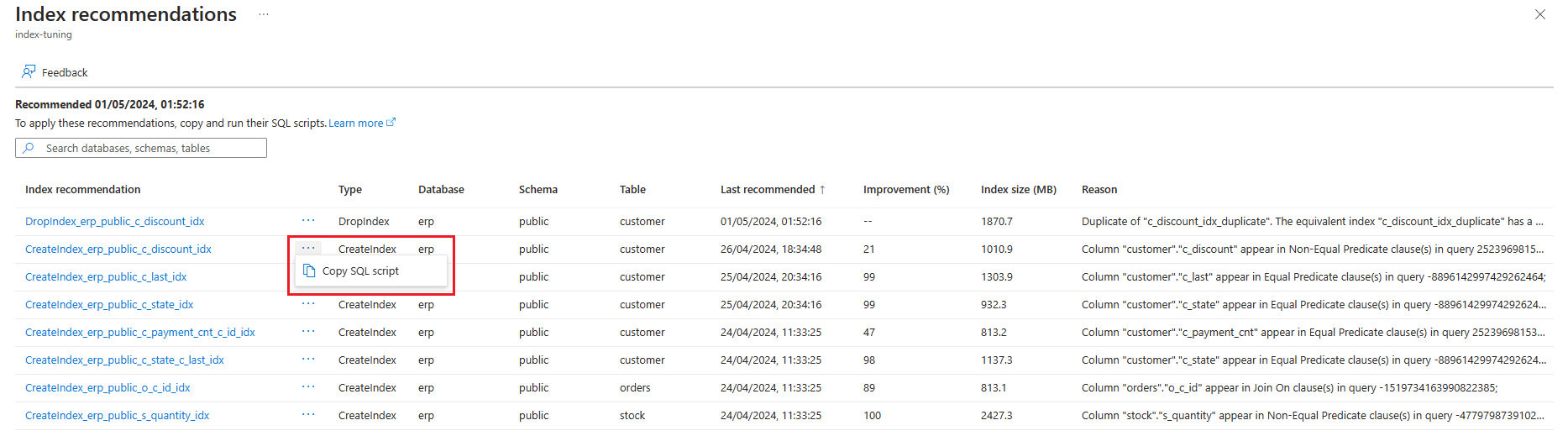
Ze seznamu doporučení:
Vyberte tři tečky napravo od doporučení, pro které chcete získat příkaz SQL, a vyberte Kopírovat skript SQL.
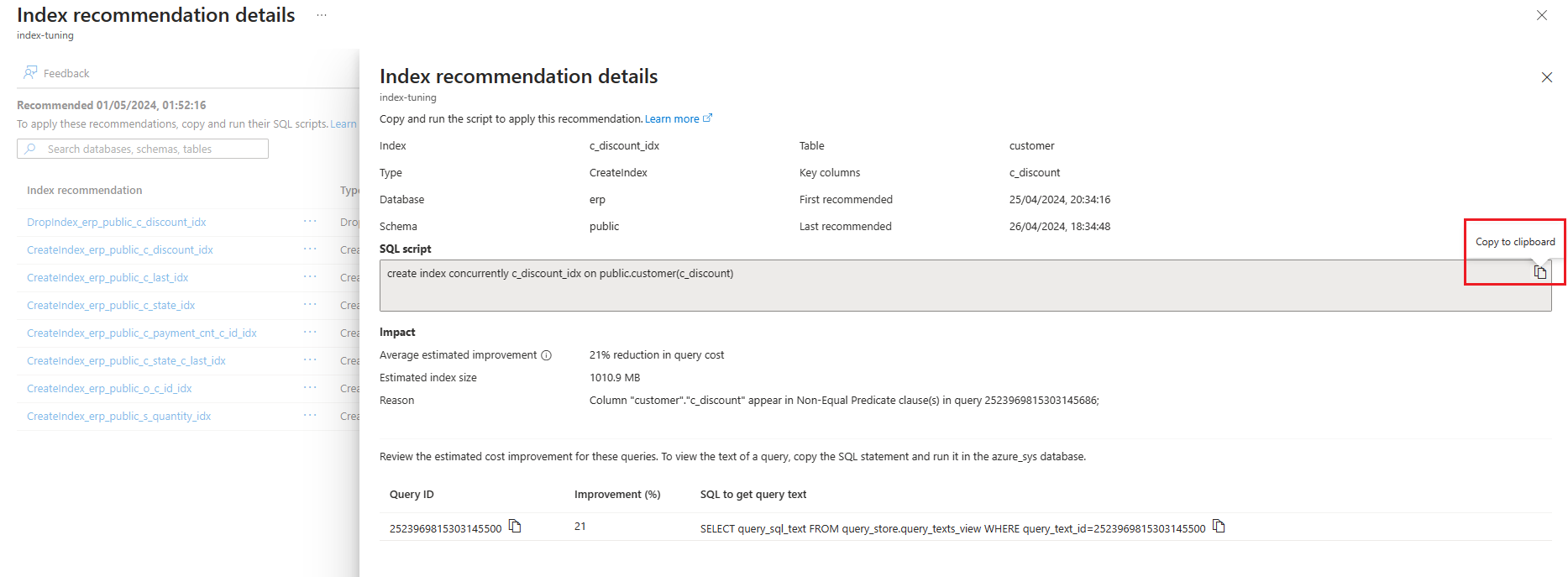
Nebo vyberte název doporučení, aby se zobrazily podrobnosti o doporučení indexu, a výběrem ikony kopie do schránky v textovém poli skriptu SQL zkopírujte příkaz SQL.

Související obsah
- Ladění indexů na flexibilním serveru Azure Database for PostgreSQL
- Konfigurace ladění indexů na flexibilním serveru Azure Database for PostgreSQL
- Monitorování výkonu pomocí úložiště dotazů
- Scénáře použití pro úložiště dotazů – Flexibilní server Azure Database for PostgreSQL
- Osvědčené postupy pro úložiště dotazů – Flexibilní server Azure Database for PostgreSQL
- Query Performance Insight pro flexibilní server Azure Database for PostgreSQL