Vytváření datových sad Azure Machine Learning z Azure Open Datasets
V tomto článku se dozvíte, jak přenést kurátorovaná data rozšiřování do experimentů místního nebo vzdáleného strojového učení pomocí datových sad Azure Machine Learning a Azure Open Datasets.
S datovou sadou Azure Machine Learning vytvoříte odkaz na umístění zdroje dat spolu s kopií jeho metadat. Vzhledem k tomu, že se datové sady lazily vyhodnocují a protože data zůstávají v jejich stávajícím umístění,
- Neriskujte neúmyslné změny původních zdrojů dat.
- Neúčtují se žádné další náklady na úložiště
- Zvýšení rychlosti výkonu pracovního postupu ML
Další informace o tom, kde se datové sady vejdou do celkového pracovního postupu přístupu k datům služby Azure Machine Learning, najdete v článku o bezpečném přístupu k datům .
Azure Open Datasets jsou kurátorované veřejné datové sady, které přidávají funkce specifické pro scénáře, aby se vaše prediktivní řešení obohatila a zlepšila přesnost těchto řešení. Navštivte prostředek katalogu Open Datasets pro data veřejné domény, která vám můžou pomoct trénovat modely strojového učení, například:
Otevřené datové sady jsou hostované v cloudu v Microsoft Azure. Sadu Azure Machine Learning Python SDK i studio Azure Machine Learning zahrnout.
Požadavky
Potřebujete:
Předplatné Azure. Pokud ho nemáte, vytvořte si bezplatný účet před tím, než začnete. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Pracovní prostor Azure Machine Learning.
Nainstalovaná sada Azure Machine Learning SDK pro Python , která obsahuje
azureml-datasetsbalíček.- Vytvořte výpočetní instanci Azure Machine Learning – plně nakonfigurované a spravované vývojové prostředí, které zahrnuje integrované poznámkové bloky a sadu SDK, která už je nainstalovaná.
NEBO
- Pracujte ve vlastním prostředí Pythonu a pomocí těchto pokynů nainstalujte sadu SDK sami.
Poznámka:
Některé třídy datové sady mají závislosti na balíčku azureml-dataprep . Tento balíček je kompatibilní pouze s 64bitovou verzí Pythonu. Pro uživatele s Linuxem jsou tyto třídy podporovány pouze v těchto distribucích Linuxu:
- Debian (8, 9)
- Fedora (27, 28)
- Red Hat Enterprise Linux (7, 8)
- Ubuntu (14.04, 16.04, 18.04)
Vytváření datových sad pomocí sady SDK
Pokud chcete vytvářet datové sady Azure Machine Learning prostřednictvím tříd Azure Open Datasets, ujistěte se, že jste v sadě Python SDK nainstalovali balíček s pip install azureml-opendatasets. V sadě SDK třída každé diskrétní datové sady představuje danou třídu a některé třídy jsou k dispozici jako datový typ služby Azure Machine Learning, datový typ služby Azure Machine Learning FileDataset TabularDataset nebo obojí. Úplný seznam opendatasets tříd najdete v referenční dokumentaci.
Určité opendatasets třídy můžete načíst buď jako prostředky, nebo FileDataset jako TabularDataset prostředky. Soubory pak můžete manipulovat a/nebo je stáhnout přímo. Jiné třídy mohou načíst datovou sadu pouze s použitím get_tabular_dataset() nebo get_file_dataset() funkcí z Datasettřídy v sadě Python SDK.
Tento kód ukazuje, že třída MNIST opendatasets může vrátit buď a TabularDataset , nebo FileDataset:
from azureml.core import Dataset
from azureml.opendatasets import MNIST
# MNIST class can return either TabularDataset or FileDataset
tabular_dataset = MNIST.get_tabular_dataset()
file_dataset = MNIST.get_file_dataset()
V tomto příkladu je diabetes opendatasets třída k dispozici pouze jako TabularDataset. To vyžaduje použití get_tabular_dataset().
from azureml.opendatasets import Diabetes
from azureml.core import Dataset
# Diabetes class can return ONLY TabularDataset and must be called from the static function
diabetes_tabular = Diabetes.get_tabular_dataset()
Registrace datových sad
Zaregistrujte datovou sadu Azure Machine Learning ve svém pracovním prostoru, abyste ji mohli sdílet s ostatními a opakovaně ji používat napříč experimenty ve vašem pracovním prostoru. Když zaregistrujete datovou sadu Azure Machine Learning vytvořenou z otevřených datových sad, nebudou se okamžitě stahovat žádná data, ale později (například během trénování) budou data přístupná při vyžádání z centrálního úložiště.
K registraci datových sad v pracovním prostoru použijte metodu register() .
titanic_ds = titanic_ds.register(workspace=workspace,
name='titanic_ds',
description='titanic training data')
Vytváření datových sad pomocí studia
Datové sady Azure Machine Learning můžete vytvářet také z Azure Open Datasets pomocí studio Azure Machine Learning. Toto konsolidované webové rozhraní zahrnuje nástroje strojového učení pro provádění scénářů datových věd pro odborníky na datové vědy na všech úrovních dovedností.
Poznámka:
Datové sady vytvořené prostřednictvím studio Azure Machine Learning se automaticky zaregistrují do pracovního prostoru.
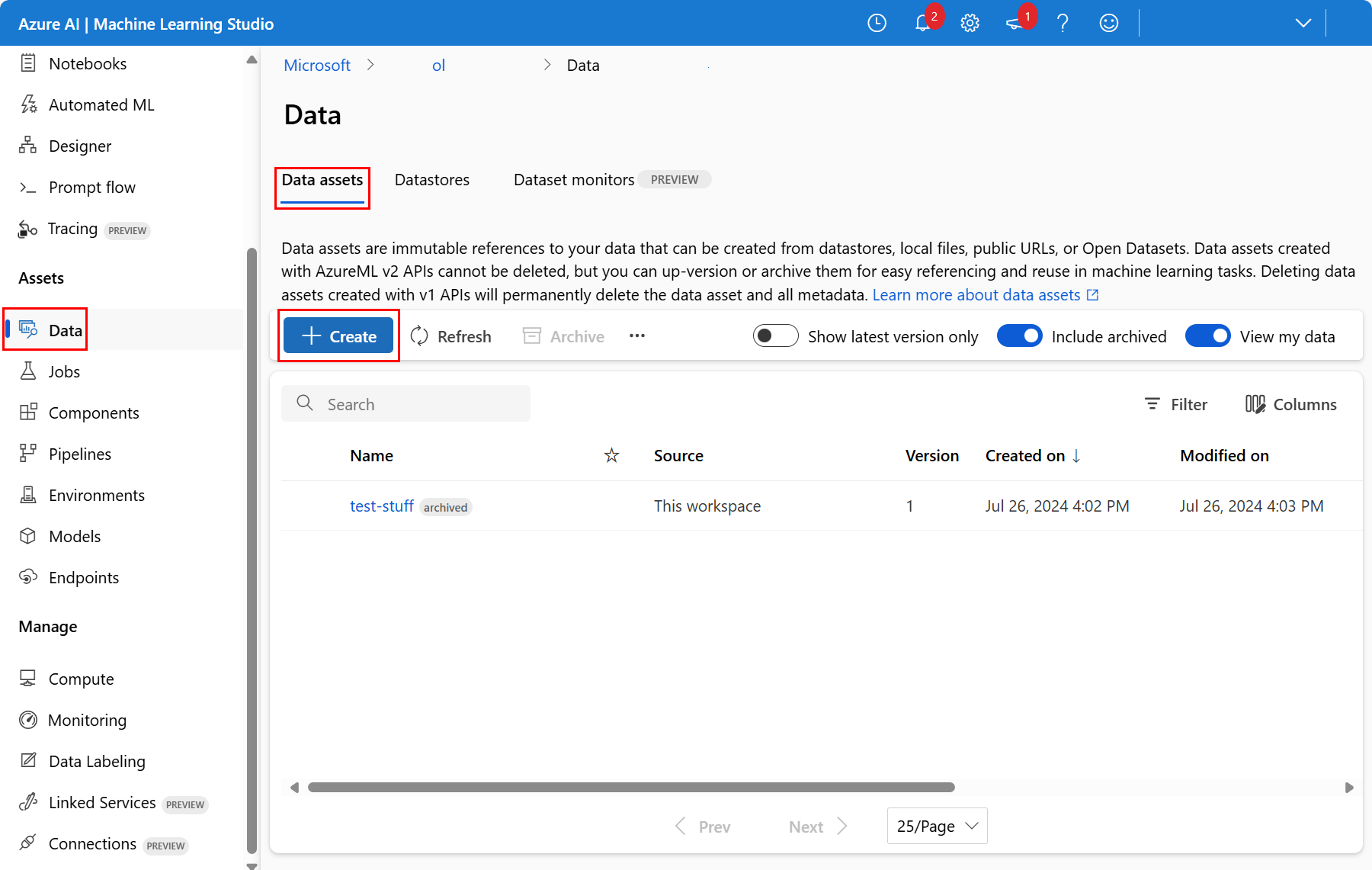
V pracovním prostoru vyberte data v levém navigačním panelu. Na kartě Datové prostředky vyberte Vytvořit, jak je znázorněno na tomto snímku obrazovky:
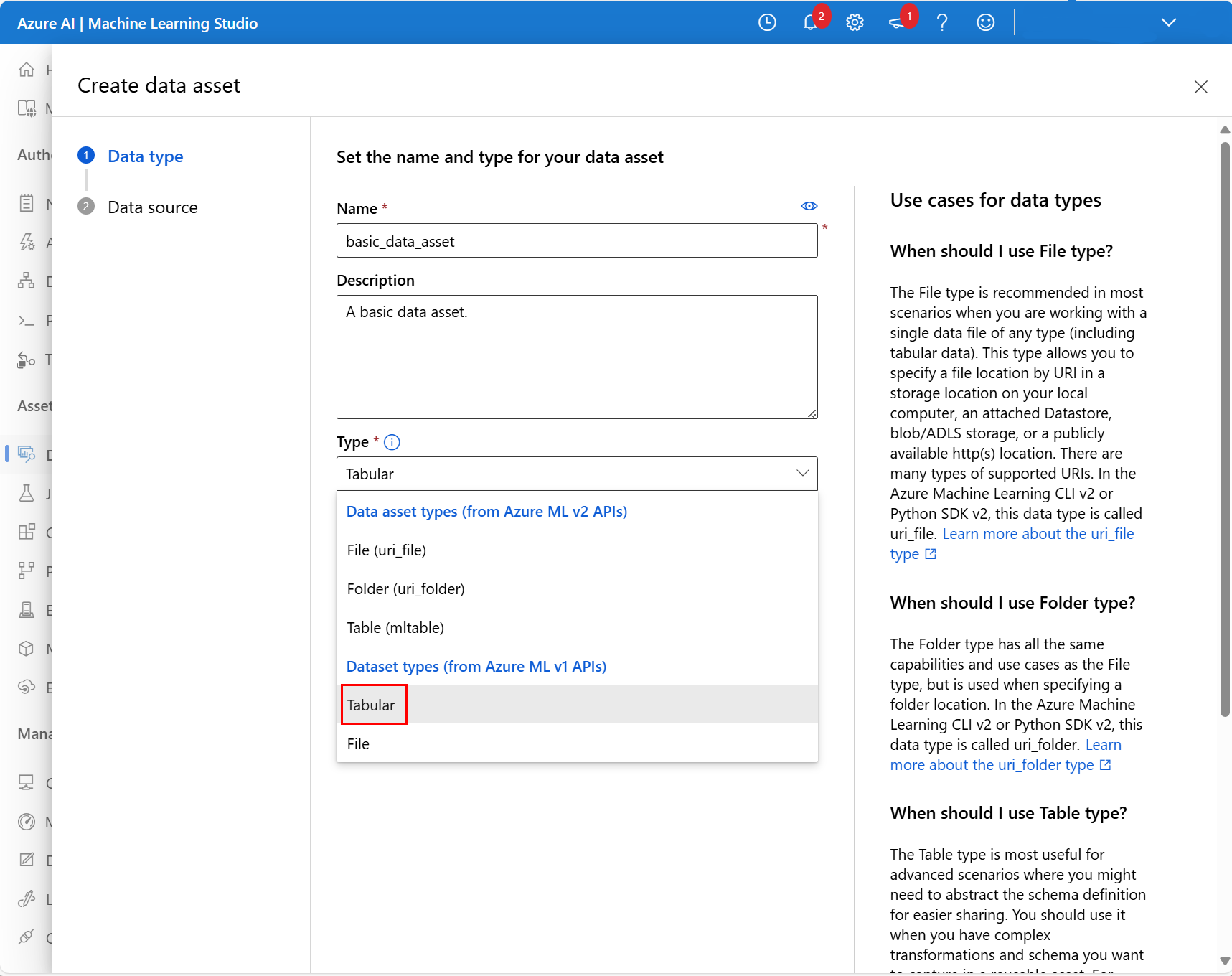
Na další obrazovce přidejte název a volitelný popis nového datového prostředku. Potom v rozevíracím seznamu Typ vyberte Tabulkový, jak je znázorněno na tomto snímku obrazovky:
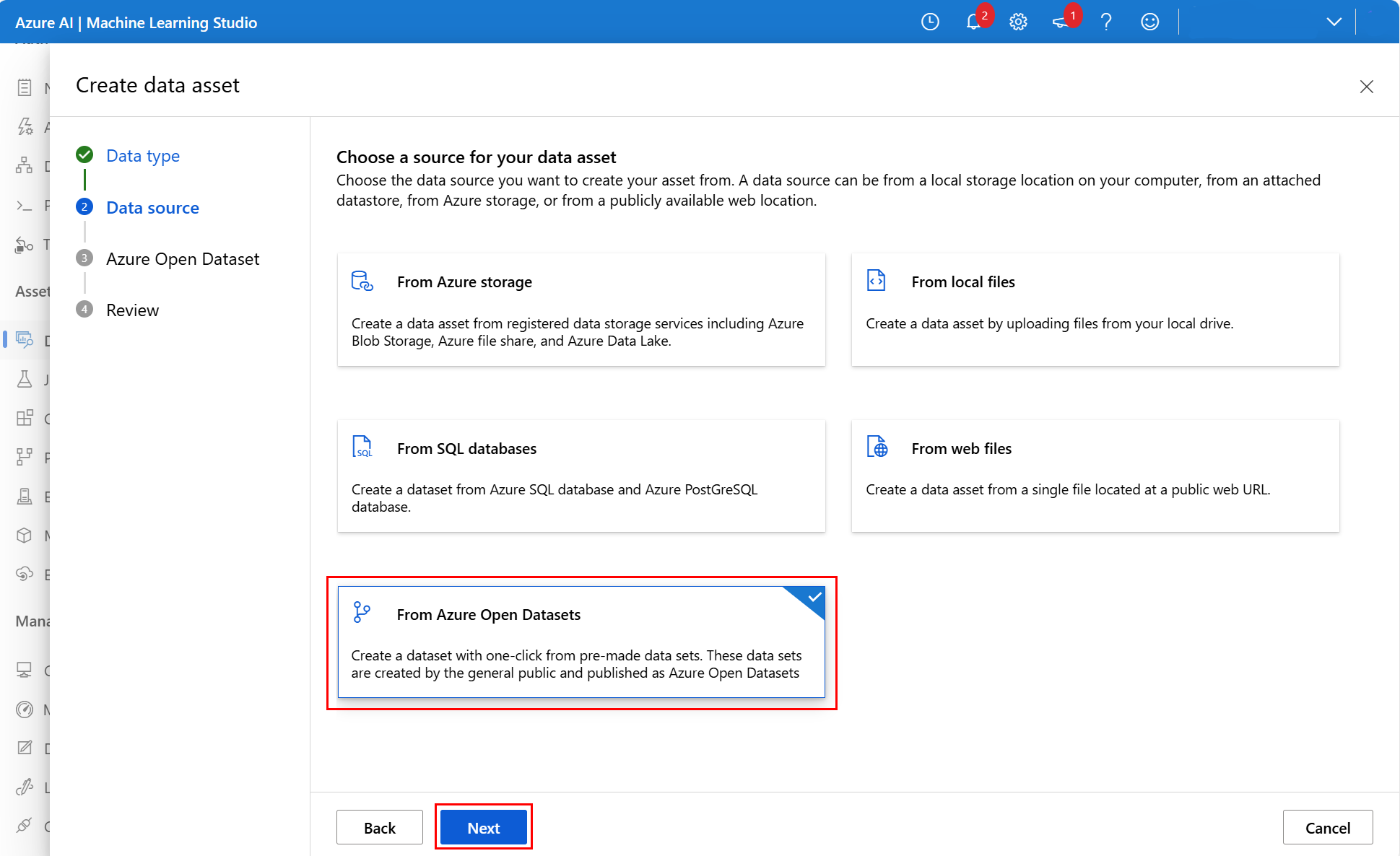
Na další obrazovce vyberte Z Azure Open Datasets a pak vyberte Další, jak je znázorněno na tomto snímku obrazovky:
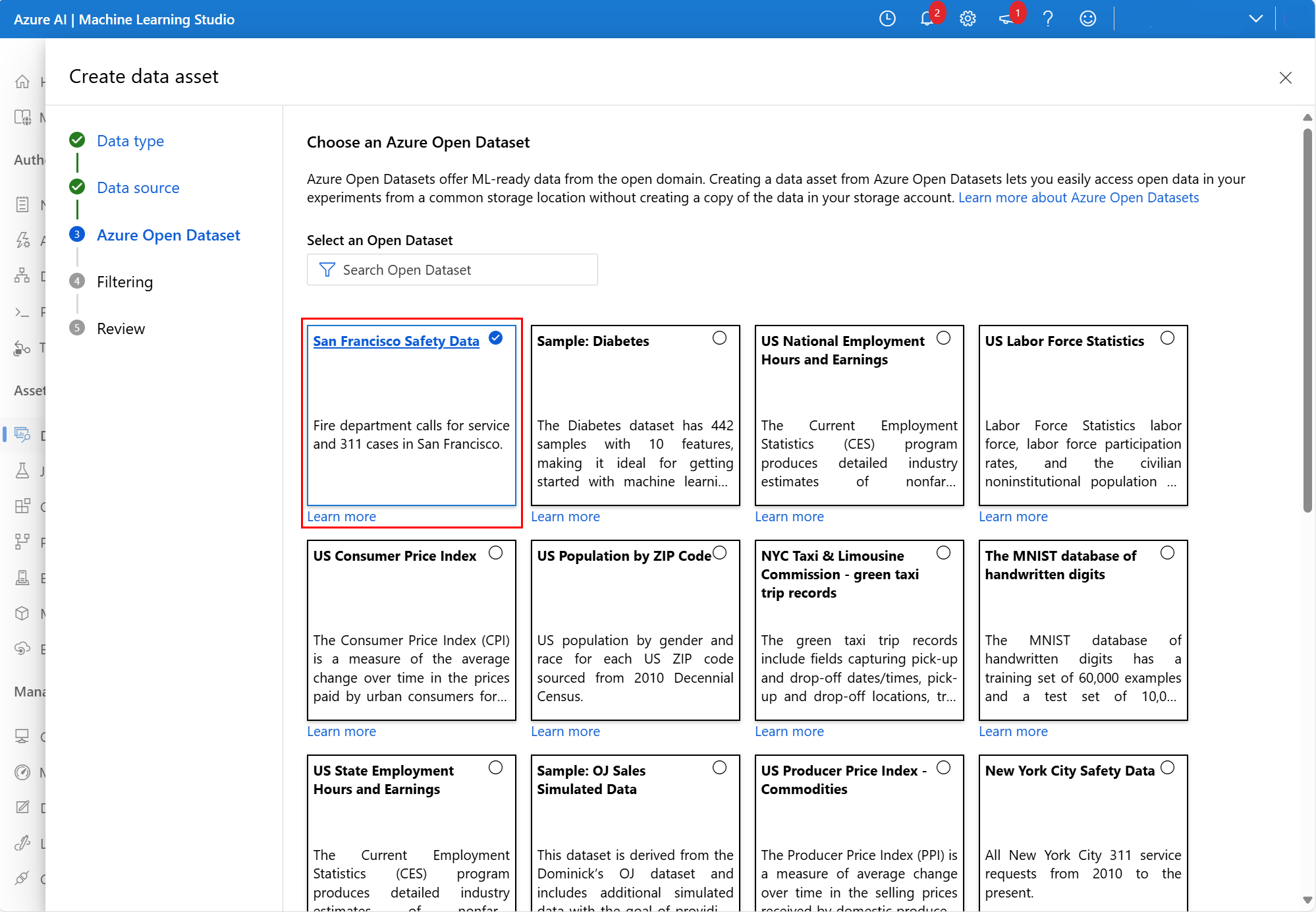
Na další obrazovce vyberte dostupnou datovou sadu Azure Open Dataset. Na tomto snímku obrazovky jsme vybrali datovou sadu dat zabezpečení San Francisco:
V případě potřeby se posuňte dolů a vyberte Další, jak je znázorněno na tomto snímku obrazovky:
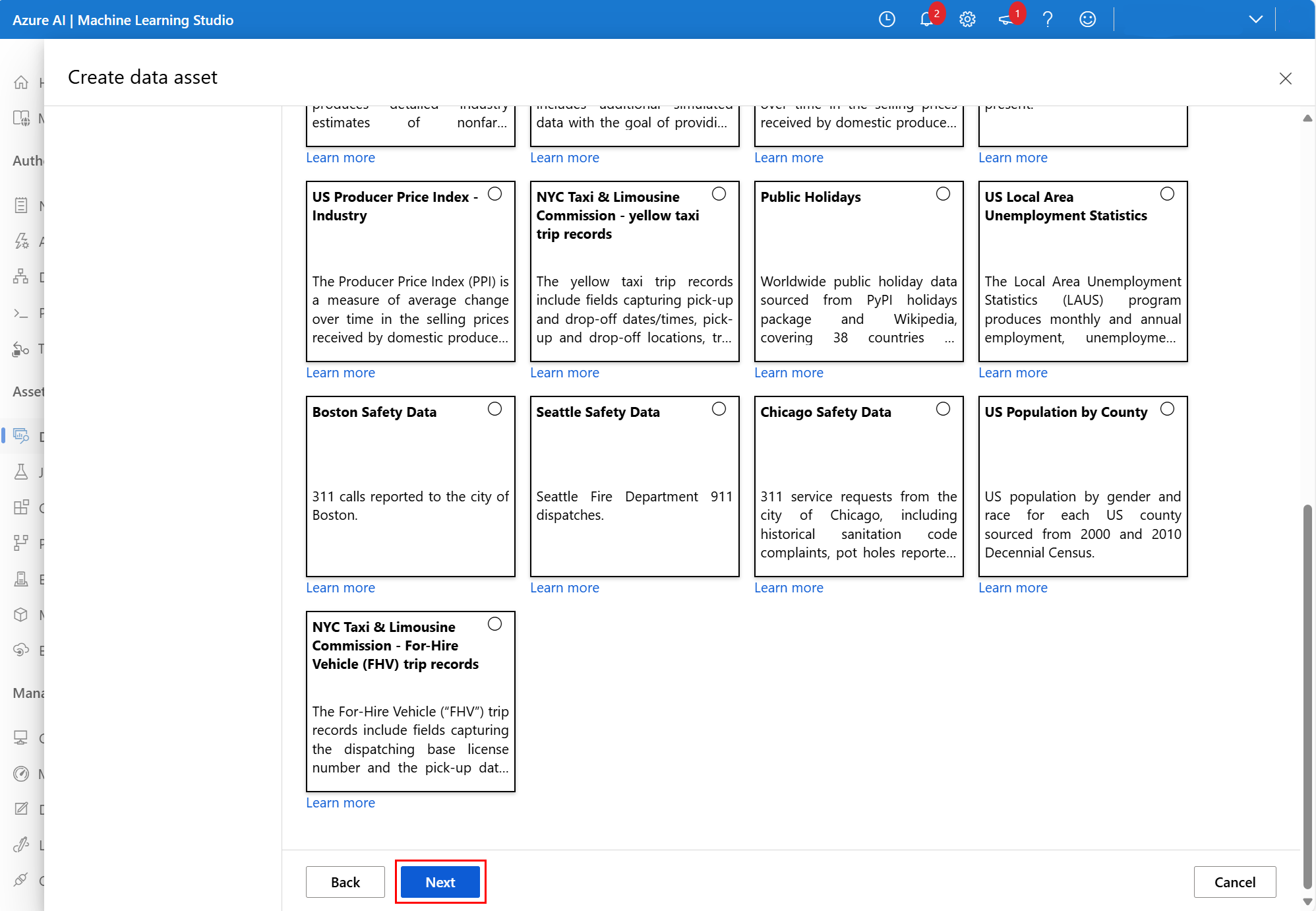
Volitelně můžete filtrovat data s dostupnými filtry, které jsou vhodné pro zvolenou datovou sadu. Pro datovou sadu Dat o bezpečnosti San Francisca nastavíme filtrovaný rozsah kalendářních dat mezi počátečním datem 1. července 2024 a 17. červencem 2024. Vyberte Další, jak je znázorněno na tomto snímku obrazovky:

Na další obrazovce zkontrolujte nastavení nového datového prostředku a proveďte potřebné změny. Až to vypadá dobře, vyberte Vytvořit , jak je znázorněno na tomto snímku obrazovky:
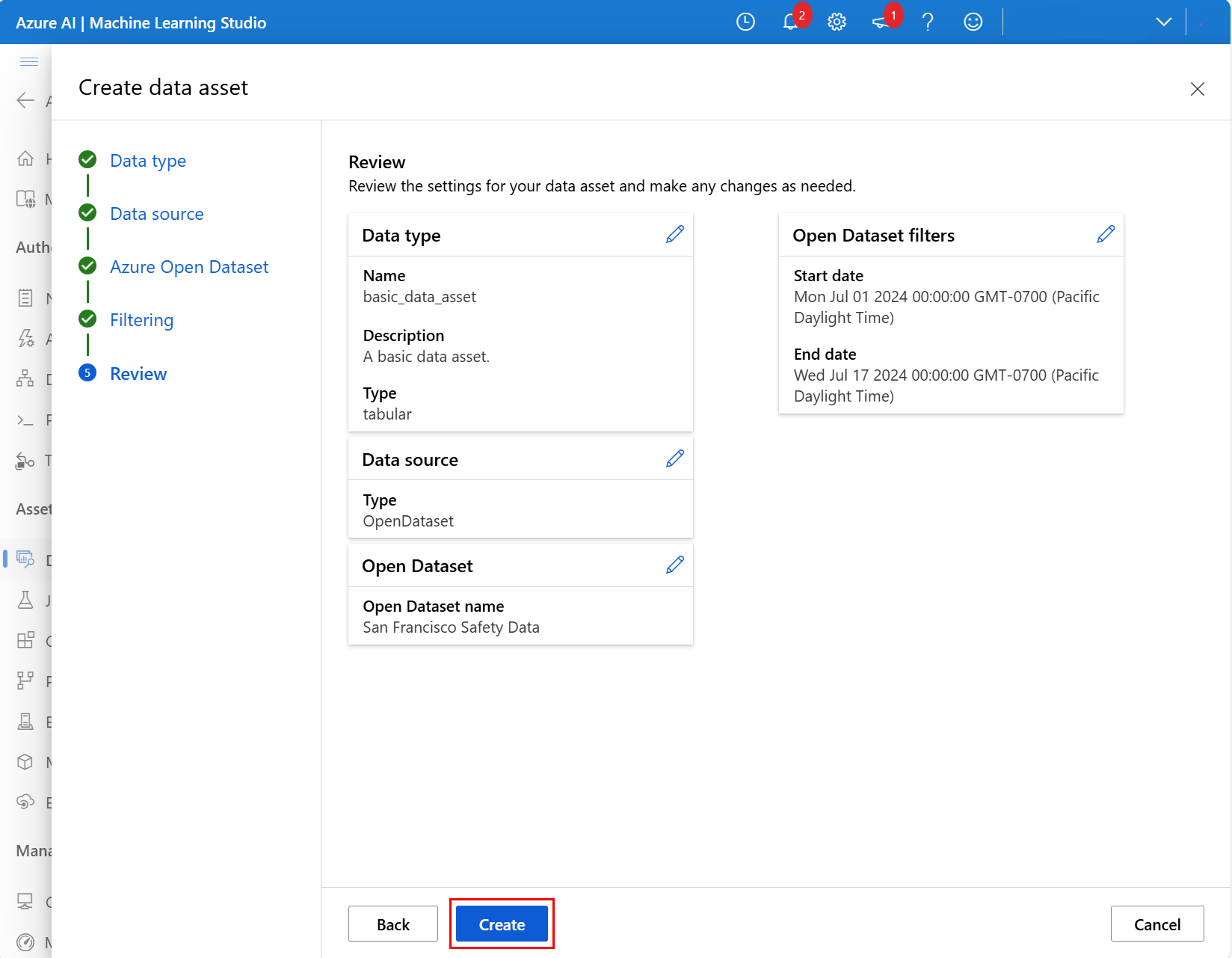
Další informace o popisech polí a rozsahech kalendářních dat datové sady San Francisco Safety najdete v prostředku San Francisco Safety Data . Další informace o dalších datových sadách najdete v prostředku Azure Open Datasets Catalog .







Datová sada je teď dostupná ve vašem pracovním prostoru v části Datové sady. Můžete ho použít stejným způsobem jako ostatní datové sady, které jste vytvořili.
Přístup k datovým sadám pro experimenty
Datové sady můžete použít v experimentech strojového učení pro trénovací modely ML. Další informace najdete v tématu Další informace o tom, jak trénovat s datovými sadami.
Příklady poznámkových bloků
Příklady a ukázky funkcí Open Datasets najdete v těchto ukázkových poznámkových blocích.
Další kroky
- Trénování prvního modelu ML
- Trénujte pomocí datových sad.
- Vytvořte datovou sadu Azure Machine Learning.