Rychlý start: Vyhledávání spravované instance Azure pro Apache Cassandra pomocí Lucene Indexu (Preview)
Cassandra Lucene Index, odvozený z Stratio Cassandra, je modul plug-in pro Apache Cassandra, který rozšiřuje funkce indexu, aby poskytoval možnosti fulltextového vyhledávání a bezplatné multivariovatelné, geoprostorové a bitemporální vyhledávání. Toho se dosahuje prostřednictvím implementace sekundárních indexů Cassandra založené na Apache Lucene, kde každý uzel clusteru indexuje svá vlastní data. Tento rychlý start ukazuje, jak vyhledat spravovanou instanci Azure pro Apache Cassandra pomocí Lucene Indexu.
Důležité
Lucene Index je ve verzi Public Preview. Tato funkce je poskytována bez smlouvy o úrovni služeb a nedoporučuje se pro produkční úlohy. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Upozorňující
Omezení modulu plug-in indexu Lucene spočívá v tom, že vyhledávání napříč oddíly nejde spustit pouze v indexu – Cassandra potřebuje odeslat dotaz do každého uzlu. To může vést k problémům s výkonem (zatížení paměti a procesoru) pro vyhledávání napříč oddíly, které můžou mít vliv na úlohy stabilního stavu.
Pokud jsou požadavky na vyhledávání významné, doporučujeme nasadit vyhrazené sekundární datové centrum, které se použije jenom pro vyhledávání, s minimálním počtem uzlů, přičemž každý má vysoký počet jader (minimálně 16). Prostory klíčů v primárním (provozním) datovém centru by se pak měly nakonfigurovat tak, aby replikovaly data do sekundárního datového centra (vyhledávání).
Požadavky
Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet.
Nasazení clusteru Azure Managed Instance for Apache Cassandra Můžete to provést prostřednictvím portálu – indexy Lucene se ve výchozím nastavení povolí při nasazení clusterů z portálu. Pokud chcete přidat indexy Lucene do existujícího clusteru, klikněte
Updatev okně přehledu portálu, vyberteCassandra Lucene Indexa kliknutím na aktualizovat nasazení.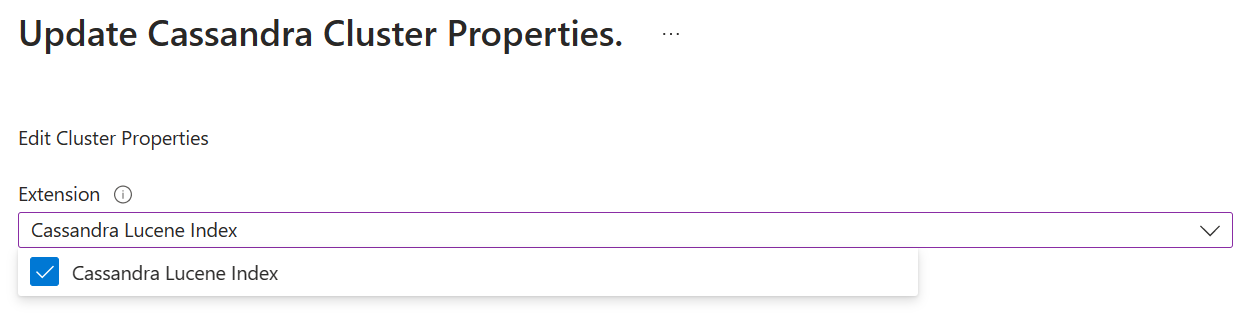
Připojte se ke clusteru z CQLSH.

Vytvoření dat pomocí Lucene Indexu
CQLSHV příkazovém okně vytvořte prostor klíčů a tabulku následujícím způsobem:CREATE KEYSPACE demo WITH REPLICATION = {'class': 'NetworkTopologyStrategy', 'datacenter-1': 3}; USE demo; CREATE TABLE tweets ( id INT PRIMARY KEY, user TEXT, body TEXT, time TIMESTAMP, latitude FLOAT, longitude FLOAT );Teď vytvořte vlastní sekundární index tabulky pomocí Lucene Indexu:
CREATE CUSTOM INDEX tweets_index ON tweets () USING 'com.stratio.cassandra.lucene.Index' WITH OPTIONS = { 'refresh_seconds': '1', 'schema': '{ fields: { id: {type: "integer"}, user: {type: "string"}, body: {type: "text", analyzer: "english"}, time: {type: "date", pattern: "yyyy/MM/dd"}, place: {type: "geo_point", latitude: "latitude", longitude: "longitude"} } }' };Vložte následující ukázkové tweety:
INSERT INTO tweets (id,user,body,time,latitude,longitude) VALUES (1,'theo','Make money fast, 5 easy tips', '2023-04-01T11:21:59.001+0000', 0.0, 0.0); INSERT INTO tweets (id,user,body,time,latitude,longitude) VALUES (2,'theo','Click my link, like my stuff!', '2023-04-01T11:21:59.001+0000', 0.0, 0.0); INSERT INTO tweets (id,user,body,time,latitude,longitude) VALUES (3,'quetzal','Click my link, like my stuff!', '2023-04-02T11:21:59.001+0000', 0.0, 0.0); INSERT INTO tweets (id,user,body,time,latitude,longitude) VALUES (4,'quetzal','Click my link, like my stuff!', '2023-04-01T11:21:59.001+0000', 40.3930, -3.7328); INSERT INTO tweets (id,user,body,time,latitude,longitude) VALUES (5,'quetzal','Click my link, like my stuff!', '2023-04-01T11:21:59.001+0000', 40.3930, -3.7329);
Řízení konzistence čtení
Index, který jste vytvořili dříve, indexuje všechny sloupce v tabulce se zadanými typy a index pro čtení použitý k hledání se aktualizuje jednou za sekundu. Případně můžete explicitně aktualizovat všechny horizontální oddíly indexu prázdným vyhledáváním s konzistencí ALL:
CONSISTENCY ALL SELECT * FROM tweets WHERE expr(tweets_index, '{refresh:true}'); CONSISTENCY QUORUMTeď můžete vyhledávat tweety v určitém rozsahu kalendářních dat:
SELECT * FROM tweets WHERE expr(tweets_index, '{filter: {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}}');Toto vyhledávání lze provést také vynucením explicitní aktualizace zahrnutých horizontálních oddílů indexu:
SELECT * FROM tweets WHERE expr(tweets_index, '{ filter: {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}, refresh: true }') limit 100;
Hledání dat
Pokud chcete prohledat 100 relevantních tweetů, ve kterých pole textu obsahuje frázi "Click my link" (Kliknout na můj odkaz) v určitém rozsahu kalendářních dat:
SELECT * FROM tweets WHERE expr(tweets_index, '{ filter: {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}, query: {type: "phrase", field: "body", value: "Click my link", slop: 1} }') LIMIT 100;Pokud chcete hledání upřesnit, abyste získali pouze tweety napsané uživateli, jejichž jména začínají na "q":
SELECT * FROM tweets WHERE expr(tweets_index, '{ filter: [ {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}, {type: "prefix", field: "user", value: "q"} ], query: {type: "phrase", field: "body", value: "Click my link", slop: 1} }') LIMIT 100;Pokud chcete získat 100 novějších filtrovaných výsledků, můžete použít možnost řazení:
SELECT * FROM tweets WHERE expr(tweets_index, '{ filter: [ {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}, {type: "prefix", field: "user", value: "q"} ], query: {type: "phrase", field: "body", value: "Click my link", slop: 1}, sort: {field: "time", reverse: true} }') limit 100;Předchozí vyhledávání lze omezit na tweety vytvořené blízko zeměpisné polohy:
SELECT * FROM tweets WHERE expr(tweets_index, '{ filter: [ {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}, {type: "prefix", field: "user", value: "q"}, {type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"} ], query: {type: "phrase", field: "body", value: "Click my link", slop: 1}, sort: {field: "time", reverse: true} }') limit 100;Výsledky je také možné seřadit podle vzdálenosti od zeměpisné polohy:
SELECT * FROM tweets WHERE expr(tweets_index, '{ filter: [ {type: "range", field: "time", lower: "2023/03/01", upper: "2023/05/01"}, {type: "prefix", field: "user", value: "q"}, {type: "geo_distance", field: "place", latitude: 40.3930, longitude: -3.7328, max_distance: "1km"} ], query: {type: "phrase", field: "body", value: "Click my link", slop: 1}, sort: [ {field: "time", reverse: true}, {field: "place", type: "geo_distance", latitude: 40.3930, longitude: -3.7328} ] }') limit 100;
Další kroky
V tomto rychlém startu jste zjistili, jak pomocí Lucene Search prohledat cluster Azure Managed Instance for Apache Cassandra. Teď můžete začít pracovat s clusterem: