Kurz: Trénování klasifikačního modelu bez kódu v studio Azure Machine Learning
V tomto kurzu se naučíte trénovat klasifikační model bez kódu automatizovaného strojového učení (AutoML) pomocí služby Azure Machine Learning v studio Azure Machine Learning. Tento klasifikační model předpovídá, jestli se klient přihlásí k odběru dlouhodobého vkladu u finanční instituce.
Pomocí automatizovaného strojového učení můžete automatizovat úlohy náročné na čas. Automatizované strojové učení rychle iteruje více kombinací algoritmů a hyperparametrů, které vám pomůžou najít nejlepší model založený na metrikě úspěchu podle vašeho výběru.
V tomto kurzu nenapíšete žádný kód. K trénování použijete rozhraní studia. Naučíte se provádět následující úlohy:
- Vytvoření pracovního prostoru Azure Machine Learning
- Spuštění experimentu automatizovaného strojového učení
- Prozkoumání podrobností modelu
- Nasazení doporučeného modelu
Požadavky
Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si bezplatný účet.
Stáhněte si datový soubor bankmarketing_train.csv. Sloupec y označuje, jestli se zákazník přihlásil k odběru dlouhodobého vkladu, který je později identifikován jako cílový sloupec pro předpovědi v tomto kurzu.
Poznámka:
Tato datová sada bankovního marketingu je dostupná v rámci licence Creative Commons (CCO: Public Domain). Veškerá práva v jednotlivých obsahech databáze jsou licencována v rámci licence Na obsah databáze a k dispozici v Kaggle. Tato datová sada byla původně k dispozici v databázi strojového učení UCI.
[Moro et al., 2014] S. Moro, P. Cortez a P. Rita. Přístup řízený daty k předpovídání úspěchu bankovního telemarketingu. Decision Support Systems, Elsevier, 62:22-31, červen 2014.
Vytvoření pracovního prostoru
Pracovní prostor Azure Machine Learning je základní prostředek v cloudu, který používáte k experimentování, trénování a nasazování modelů strojového učení. Prováže vaše předplatné Azure a skupinu prostředků s snadno využitým objektem ve službě.
Pomocí následujících kroků vytvořte pracovní prostor a pokračujte v kurzu.
Přihlaste se k studio Azure Machine Learning.
Vyberte Vytvořit pracovní prostor.
Zadejte následující informace pro konfiguraci nového pracovního prostoru:
Pole Popis Název pracovního prostoru Zadejte jedinečný název, který identifikuje váš pracovní prostor. Názvy musí být v rámci skupiny prostředků jedinečné. Použijte název, který je snadno odvolatelný a odlišit se od pracovních prostorů vytvořených jinými uživateli. Název pracovního prostoru nerozlišuje velká a malá písmena. Předplatné Vyberte předplatné Azure, které chcete použít. Skupina prostředků Použijte stávající skupinu prostředků, kterou máte v předplatném, nebo zadejte název a vytvořte novou skupinu prostředků. Skupina prostředků obsahuje související prostředky pro řešení Azure. K použití existující skupiny prostředků potřebujete roli přispěvatele nebo vlastníka . Další informace najdete v tématu Správa přístupu k pracovnímu prostoru Azure Machine Learning. Oblast Vyberte oblast Azure, která je nejblíže vašim uživatelům, a datové prostředky a vytvořte pracovní prostor. Výběrem možnosti Vytvořit vytvořte pracovní prostor.
Další informace o prostředcích Azure najdete v tématu Vytvoření pracovního prostoru.
Další způsoby, jak vytvořit pracovní prostor v Azure, spravovat pracovní prostory Azure Machine Learning na portálu nebo pomocí sady Python SDK (v2)
Vytvoření úlohy automatizovaného strojového učení
Pomocí studio Azure Machine Learning na https://ml.azure.comadrese . Machine Learning Studio je konsolidované webové rozhraní, které zahrnuje nástroje strojového učení pro provádění scénářů datových věd pro odborníky na datové vědy na všech úrovních dovedností. Studio není podporované v prohlížečích Internet Explorer.
Vyberte své předplatné a pracovní prostor, který jste vytvořili.
V navigačním podokně vyberte Vytváření automatizovaného strojového>učení.
Vzhledem k tomu, že tento kurz je vaším prvním experimentem automatizovaného strojového učení, zobrazí se prázdný seznam a odkazy na dokumentaci.
Vyberte novou úlohu automatizovaného strojového učení.
V metodě trénování vyberte Automaticky trénovat a pak vyberte Spustit konfiguraci úlohy.
V základním nastavení vyberte Vytvořit nový a pak jako název experimentu zadejte my-1st-automl-experiment.
Vyberte Další a načtěte datovou sadu.

Vytvoření a načtení datové sady jako datového assetu
Než experiment nakonfigurujete, nahrajte datový soubor do pracovního prostoru ve formě datového prostředku služby Azure Machine Learning. Pro účely tohoto kurzu si můžete datový asset představit jako datovou sadu pro úlohu automatizovaného strojového učení. To vám umožní zajistit, aby se data správně naformátovala pro váš experiment.
V seznamu Typ úkolu a data vyberte typ úkolu a zvolte Klasifikace.
V části Vybrat data zvolte Vytvořit.
Ve formuláři Datový typ zadejte název datového prostředku a zadejte volitelný popis.
Jako typ vyberte Tabulkový. Automatizované rozhraní ML v současné době podporuje pouze tabulkové datové sady.
Vyberte Další.
Ve formuláři Zdroj dat vyberte Z místních souborů. Vyberte Další.
V cílovém typu úložiště vyberte výchozí úložiště dat, které se automaticky nastavilo během vytváření pracovního prostoru: workspaceblobstore. Datový soubor nahrajete do tohoto umístění, aby byl dostupný pro váš pracovní prostor.
Vyberte Další.
Ve výběru souboru nebo složky vyberte Nahrát soubory nebo složky>Nahrát soubory.
Zvolte soubor bankmarketing_train.csv na místním počítači. Tento soubor jste stáhli jako předpoklad.
Vyberte Další.
Po dokončení nahrávání se oblast náhledu dat naplní na základě typu souboru.
Ve formuláři Nastavení zkontrolujte hodnoty dat. Pak vyberte Další.
Pole Popis Hodnota pro kurz File format Definuje rozložení a typ dat uložených v souboru. Oddělené Delimiter Jeden nebo více znaků pro určení hranice mezi samostatnými, nezávislými oblastmi v prostém textu nebo jinými datovými proudy. Comma Kódování Určuje, jaký bit tabulky schématu znaků se má použít ke čtení datové sady. UTF-8 Záhlaví sloupců Určuje, jak se zachází s hlavičkami datové sady( pokud existuje). Všechny soubory mají stejné hlavičky. Přeskočit řádky Určuje, kolik řádků se v datové sadě přeskočí( pokud existuje). Nic Formulář schématu umožňuje další konfiguraci dat pro tento experiment. V tomto příkladu vyberte přepínač pro day_of_week, aby ho nezahrnuli. Vyberte Další.
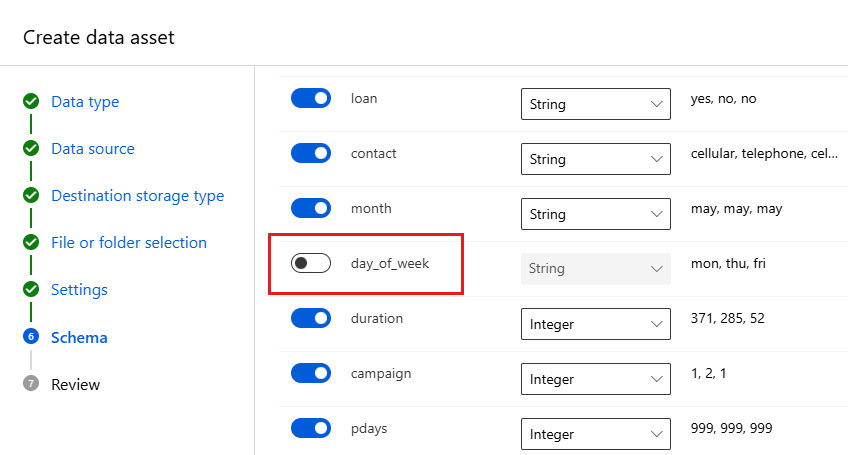
Ve formuláři Kontrola ověřte své informace a pak vyberte Vytvořit.
Ze seznamu vyberte datovou sadu.
Zkontrolujte data tak, že vyberete datový asset a podíváte se na kartu Náhled. Ujistěte se, že neobsahuje day_of_week, a vyberte Zavřít.
Chcete-li pokračovat v nastavení úkolu, vyberte Další .
Konfigurace úlohy
Po načtení a konfiguraci dat můžete experiment nastavit. Toto nastavení zahrnuje úlohy návrhu experimentů, například výběr velikosti výpočetního prostředí a určení sloupce, který chcete předpovědět.
Vyplňte formulář Nastavení úlohy následujícím způsobem:
Jako cílový sloupec vyberte y (String), což je to, co chcete předpovědět. Tento sloupec označuje, jestli se klient přihlásil k odběru vkladu termínů, nebo ne.
Vyberte Zobrazit další nastavení konfigurace a vyplňte pole následujícím způsobem. Tato nastavení slouží k lepšímu řízení trénovací úlohy. V opačném případě se výchozí hodnoty použijí na základě výběru experimentu a dat.
Další konfigurace Popis Hodnota pro kurz Primární metrika Metrika vyhodnocení použitá k měření algoritmu strojového učení AUCWeighted Vysvětlit nejlepší model Automaticky zobrazuje vysvětlitelnost nejlepšího modelu vytvořeného automatizovaným strojovém učení. Povolit Blokované modely Algoritmy, které chcete vyloučit z trénovací úlohy Nic Zvolte Uložit.
V části Ověření a testování:
- Jako typ ověření vyberte křížové ověření k-fold.
- V části Počet křížových ověření vyberte 2.
Vyberte Další.
Jako typ výpočetních prostředků vyberte výpočetní cluster .
Cílový výpočetní objekt je místní nebo cloudové prostředí prostředků, které slouží ke spuštění trénovacího skriptu nebo hostování nasazení služby. Pro účely tohoto experimentu můžete vyzkoušet cloudový bezserverový výpočetní výkon (Preview) nebo vytvořit vlastní cloudové výpočetní prostředky.
Poznámka:
Pokud chcete používat bezserverové výpočetní prostředky, povolte funkci Preview, vyberte Bezserverové prostředí a tento postup přeskočte.
Pokud chcete vytvořit vlastní cílový výpočetní objekt, v části Vyberte typ výpočetních prostředků vyberte Výpočetní cluster a nakonfigurujte cílový výpočetní objekt.
Vyplňte formulář virtuálního počítače a nastavte výpočetní prostředky. Vyberte Nový.
Pole Popis Hodnota pro kurz Umístění Oblast, ze které chcete počítač spustit Západní USA 2 Úroveň virtuálního počítače Vyberte, jakou prioritu má experiment mít. Vyhrazené Typ virtuálního počítače Vyberte typ virtuálního počítače pro výpočetní prostředky. CPU (jednotka centrálního zpracování) Velikost virtuálního počítače Vyberte velikost virtuálního počítače pro výpočetní prostředky. Seznam doporučených velikostí se poskytuje na základě vašich dat a typu experimentu. Standard_DS12_V2 Výběrem možnosti Další přejděte do formuláře Upřesnit nastavení .
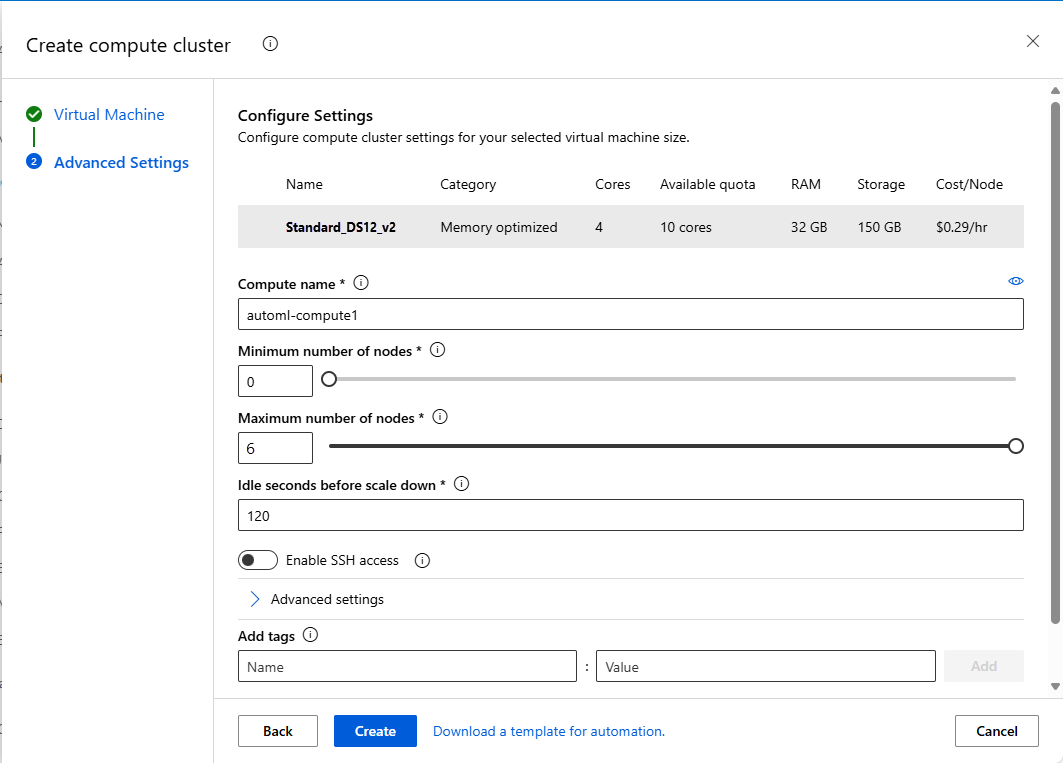
Pole Popis Hodnota pro kurz Název výpočetních prostředků Jedinečný název, který identifikuje výpočetní kontext. automl-compute Minimální a maximální počet uzlů Chcete-li profilovat data, musíte zadat 1 nebo více uzlů. Minimální počet uzlů: 1
Maximální počet uzlů: 6Nečinné sekundy před vertikálním snížením kapacity Doba nečinnosti před automatickým vertikálním snížením kapacity clusteru na minimální počet uzlů. 120 (výchozí) Rozšířené nastavení Nastavení pro konfiguraci a autorizaci virtuální sítě pro experiment Nic Vyberte Vytvořit.
Vytvoření výpočetních prostředků může trvat několik minut.
Po vytvoření vyberte nový cílový výpočetní objekt ze seznamu. Vyberte Další.
Vyberte Odeslat trénovací úlohu a spusťte experiment. Při zahájení přípravy experimentu se otevře obrazovka Přehled se stavem nahoře. Tento stav se aktualizuje při pokroku experimentu. Oznámení se také zobrazí v studiu, aby vás informovala o stavu experimentu.

Důležité
Příprava trvá 10 až 15 minut , než se experiment připraví. Po spuštění trvá pro každou iteraci dalších 2 až 3 minuty.
V produkčním prostředí byste asi trochu odešel. V tomto kurzu ale můžete začít zkoumat testované algoritmy na kartě Modely , zatímco ostatní budou dál spouštět.
Prozkoumání modelů
Přejděte na kartu Modely a podřízené úlohy a prohlédněte si testované algoritmy (modely). Ve výchozím nastavení úloha objednává modely podle skóre metrik při jejich dokončení. V tomto kurzu je v horní části seznamu model, který vyhodnocuje nejvyšší skóre na základě zvolené metriky AUCWeighted .
Během čekání na dokončení všech modelů experimentů vyberte název algoritmu dokončeného modelu a prozkoumejte jeho podrobnosti o výkonu. Vyberte kartu Přehled a Metriky , kde najdete informace o úloze.
Následující animace zobrazuje vlastnosti, metriky a výkonnostní grafy vybraného modelu.

Zobrazení vysvětlení modelu
Zatímco čekáte na dokončení modelů, můžete se také podívat na vysvětlení modelu a zjistit, které datové funkce (nezpracované nebo inženýrované) ovlivnily predikce konkrétního modelu.
Vysvětlení těchto modelů je možné generovat na vyžádání. Řídicí panel vysvětlení modelu, který je součástí karty Vysvětlení (Preview), shrnuje tato vysvětlení.
Generování vysvětlení modelu:
V navigačních odkazech v horní části stránky vyberte název úlohy, abyste se vrátili na obrazovku Modely .
Vyberte kartu Modely a podřízené úlohy.
Pro účely tohoto kurzu vyberte první model MaxAbsScaler, LightGBM .
Vyberte Vysvětlit model. Vpravo se zobrazí podokno Vysvětlit model.
Vyberte typ výpočetních prostředků a pak vyberte instanci nebo cluster: automl-compute , který jste vytvořili dříve. Tento výpočetní objekt spustí podřízenou úlohu, která vygeneruje vysvětlení modelu.
Vyberte Vytvořit. Zobrazí se zelená zpráva o úspěchu.
Poznámka:
Dokončení úlohy vysvětlení trvá přibližně 2 až 5 minut.
Vyberte vysvětlení (Preview). Tato karta se naplní po dokončení spuštění vysvětlitelnosti.
Vlevo rozbalte podokno. V části Funkce vyberte řádek s nezpracovanou položkou.
Vyberte kartu Důležitost agregace funkcí. Tento graf ukazuje, které datové funkce ovlivnily předpovědi vybraného modelu.
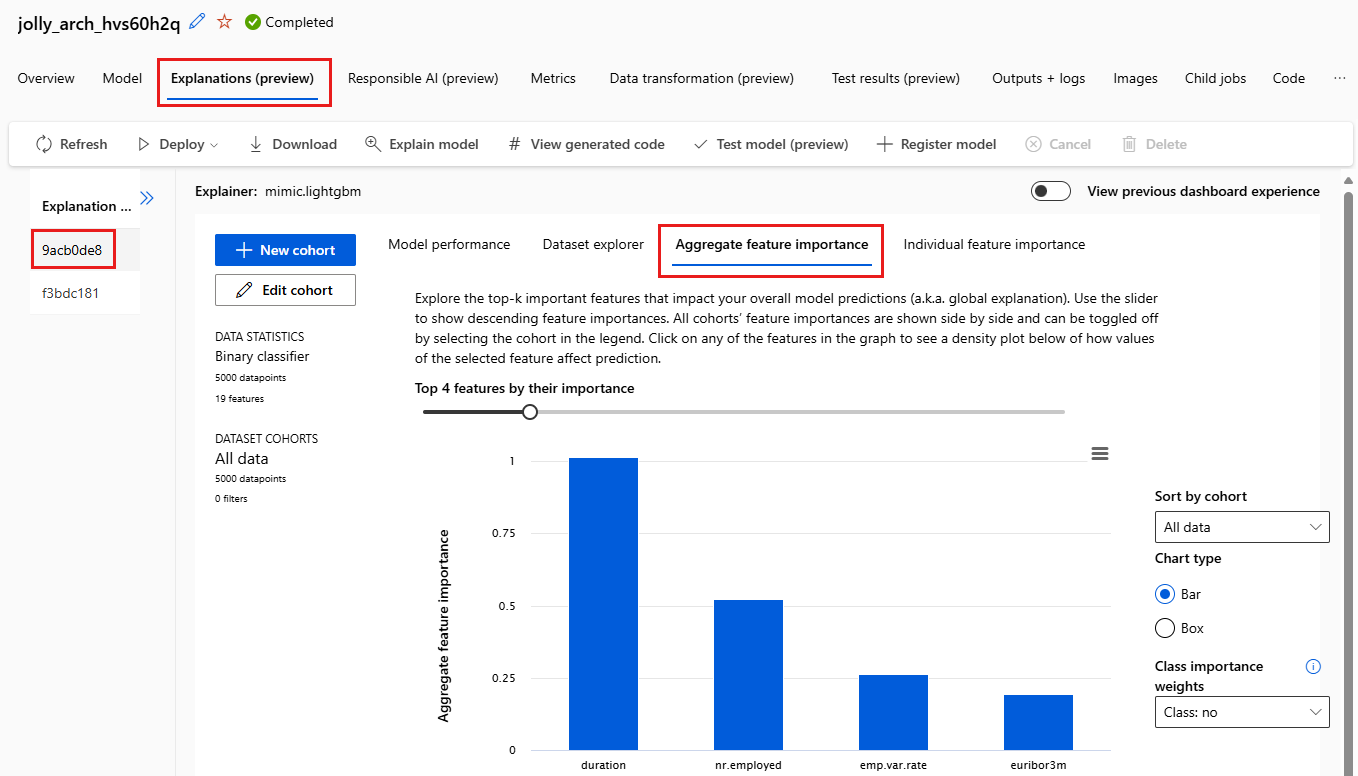
V tomto příkladu se zdá, že doba trvání má největší vliv na předpovědi tohoto modelu.

Nasazení nejlepšího modelu
Automatizované rozhraní strojového učení umožňuje nasadit nejlepší model jako webovou službu. Nasazení je integrace modelu, takže dokáže předpovědět nová data a identifikovat potenciální oblasti příležitostí. Pro účely tohoto experimentu nasazení do webové služby znamená, že finanční instituce teď má iterativní a škálovatelné webové řešení pro identifikaci potenciálních zákazníků s pevným vkladem.
Zkontrolujte, jestli je spuštění experimentu dokončené. Uděláte to tak, že přejdete zpět na stránku nadřazené úlohy tak, že vyberete název úlohy v horní části obrazovky. Stav Dokončeno se zobrazí v levém horním rohu obrazovky.
Po dokončení experimentu se stránka Podrobnosti naplní oddílem Nejlepší souhrn modelu. V tomto kontextu experimentu se VotingEnsemble považuje za nejlepší model založený na metrice AUCWeighted .
Nasaďte tento model. Dokončení nasazení trvá přibližně 20 minut. Proces nasazení zahrnuje několik kroků, včetně registrace modelu, generování prostředků a jejich konfigurace pro webovou službu.
Výběrem možnosti VotingEnsemble otevřete stránku specifickou pro model.
Vyberte Nasadit>webovou službu.
Naplňte podokno Nasazení modelu následujícím způsobem:
Pole Hodnota Name my-automl-deploy Popis Moje první nasazení experimentu automatizovaného strojového učení Typ výpočetních prostředků Výběr instance kontejneru Azure Povolit ověřování Zakázat. Použití vlastních prostředků nasazení Zakázat. Umožňuje automaticky vygenerovat výchozí soubor ovladače (bodovací skript) a soubor prostředí. V tomto příkladu použijte výchozí hodnoty uvedené v nabídce Upřesnit .
Vyberte Nasadit.
V horní části obrazovky Úlohy se zobrazí zelená zpráva o úspěchu. V podokně Souhrn modelu se v části Stav nasazení zobrazí stavová zpráva. Pravidelně vyberte Aktualizovat a zkontrolujte stav nasazení.
Máte provozní webovou službu pro generování předpovědí.
Přejděte k souvisejícímu obsahu , kde se dozvíte více o tom, jak využívat novou webovou službu, a otestujte predikce pomocí power BI integrované podpory služby Azure Machine Learning.
Vyčištění prostředků
Soubory nasazení jsou větší než data a soubory experimentů, takže jejich ukládání je nákladnější. Pokud chcete zachovat pracovní prostor a soubory experimentů, odstraňte pouze soubory nasazení, abyste minimalizovali náklady na váš účet. Pokud nemáte v úmyslu používat žádné soubory, odstraňte celou skupinu prostředků.
Odstranění instance nasazení
Odstranění pouze instance nasazení ze služby Azure Machine Learning na adrese https://ml.azure.com/.
Přejděte do služby Azure Machine Learning. Přejděte do svého pracovního prostoru a v podokně Prostředky vyberte Koncové body.
Vyberte nasazení, které chcete odstranit, a vyberte Odstranit.
Vyberte Pokračovat.
Odstranění skupiny prostředků
Důležité
Prostředky, které jste vytvořili, se dají použít jako předpoklady pro další kurzy a články s postupy pro Azure Machine Learning.
Pokud nemáte v úmyslu používat žádné prostředky, které jste vytvořili, odstraňte je, abyste za ně neúčtovaly žádné poplatky:
Na webu Azure Portal do vyhledávacího pole zadejte skupiny prostředků a vyberte je z výsledků.
V seznamu vyberte skupinu prostředků, kterou jste vytvořili.
Na stránce Přehled vyberte Odstranit skupinu prostředků.
Zadejte název skupiny prostředků. Poté vyberte Odstranit.
Související obsah
V tomto kurzu automatizovaného strojového učení jste k vytvoření a nasazení klasifikačního modelu použili automatizované rozhraní strojového učení služby Azure Machine Learning. Další informace a další kroky najdete v těchto zdrojích informací:
- Přečtěte si další informace o automatizovaném strojovém učení.
- Další informace o metrikách klasifikace a grafech: Vyhodnocení výsledků experimentů automatizovaného strojového učení
- Přečtěte si další informace o tom, jak nastavit AutoML pro NLP.
Vyzkoušejte také automatizované strojové učení pro tyto další typy modelů:
- Příklad prognózování bez kódu najdete v tématu Kurz: Prognóza poptávky bez kódu automatizovaného strojového učení v studio Azure Machine Learning.
- První příklad kódu modelu rozpoznávání objektů najdete v kurzu: Trénování modelu rozpoznávání objektů pomocí AutoML a Pythonu.