Integrace toku výzvy s DevOps pro aplikace založené na LLM
Tok výzvy služby Azure Machine Learning je vývoj a iterace toků pro vývoj a iterace pro vývoj aplikací založených na velkých jazykových modelech (LLM) přívětivá a snadno použitelná metoda kódu. Tok výzvy poskytuje sadu SDK a rozhraní příkazového řádku, rozšíření editoru Visual Studio Code a uživatelské rozhraní pro vytváření toků. Tyto nástroje usnadňují vývoj místních toků, spouštění místních toků a spouštění vyhodnocení a přechod toků mezi prostředími místního a cloudového pracovního prostoru.
Možnosti toku výzvy a kódu můžete kombinovat s vývojářskými operacemi (DevOps) a vylepšit pracovní postupy vývoje aplikací založených na LLM. Tento článek se zaměřuje na integraci toku výzvy a DevOps pro aplikace založené na azure Machine Learning LLM.
Následující diagram znázorňuje interakci místního a cloudového vývoje toku výzvy s DevOps.

Požadavky
Pracovní prostor služby Azure Machine Learning. Pokud ho chcete vytvořit, přečtěte si článek Vytvoření prostředků, abyste mohli začít.
Místní prostředí Pythonu s nainstalovanou sadou Azure Machine Learning Python SDK v2 vytvořenou podle pokynů v části Začínáme.
Poznámka:
Toto prostředí je oddělené od prostředí, které výpočetní relace používá ke spuštění toku, který definujete jako součást toku. Další informace najdete v tématu Správa výpočetní relace toku výzvy v studio Azure Machine Learning.
Visual Studio Code s nainstalovanými rozšířeními toku Pythonu a výzvy

Použití prostředí prvního kódu v toku výzvy
Vývoj aplikací založených na LLM se obvykle řídí standardizovaným procesem přípravy aplikací, který zahrnuje úložiště zdrojového kódu a kanály kontinuální integrace/průběžného nasazování (CI/CD). Tento proces podporuje zjednodušený vývoj, správu verzí a spolupráci mezi členy týmu.
Integrace DevOps s prostředím kódu toku výzvy nabízí vývojářům kódu efektivnější proces iterace GenAIOps nebo LLMOps s následujícími klíčovými funkcemi a výhodami:
Správa verzí toku v úložišti kódu Soubory toku můžete definovat ve formátu YAML a zůstanou v souladu s odkazovanými zdrojovými soubory ve stejné struktuře složek.
Integrace spuštění toku s kanály CI/CD Pomocí rozhraní příkazového řádku nebo sady SDK můžete bezproblémově integrovat tok výzvy do kanálů CI/CD a procesu doručování a automaticky aktivovat spuštění toku.
Hladký přechod mezi místním prostředím a cloudem Složku toku můžete snadno exportovat do místního nebo upstreamového úložiště kódu pro správu verzí, místní vývoj a sdílení. Složku toku můžete také snadno importovat zpět do služby Azure Machine Learning pro další vytváření, testování a nasazení pomocí cloudových prostředků.
Přístup k kódu toku výzvy
Každý tok výzvy má strukturu složek toku obsahující základní soubory kódu, které definují tok. Struktura složek uspořádá tok a usnadňuje plynulejší přechody mezi místním prostředím a cloudem.
Azure Machine Learning poskytuje sdílený systém souborů pro všechny uživatele pracovního prostoru. Po vytvoření toku se automaticky vygeneruje a uloží odpovídající složka toku v adresáři Users/<username>/promptflow .

Práce se soubory kódu toku
Po vytvoření toku v studio Azure Machine Learning můžete zobrazit, upravit a spravovat soubory toku v části Soubory na stránce vytváření toku. Všechny změny, které provedete v souborech, se projeví přímo v úložišti sdílených složek.

Složka toku pro tok založený na LLM obsahuje následující klíčové soubory.
flow.dag.yaml je primární definiční soubor toku ve formátu YAML. Tento soubor je nedílnou součástí vytváření a definování toku výzvy. Soubor obsahuje informace o vstupech, výstupech, uzlech, nástrojích a variantách, které tok používá.
Soubory zdrojového kódu spravované uživatelem ve formátu Pythonu (.py) nebo Jinja 2 (.jinja2) konfigurují nástroje a uzly v toku. Nástroj Python používá soubory Pythonu k definování vlastní logiky Pythonu. Nástroj výzvy a nástroj LLM používají k definování kontextu výzvy soubory Jinja 2.
Soubory bez zdroje, jako jsou utility a datové soubory, mohou být zahrnuty do složky toku spolu se zdrojovými soubory.
Pokud chcete zobrazit a upravit nezpracovaný kód souboru flow.dag.yaml a zdrojových souborů v editoru souborů, zapněte režim nezpracovaných souborů.

Případně můžete na stránce poznámkových bloků studio Azure Machine Learning poznámkových bloků přistupovat ke všem složkám a souborům toku a upravovat je.

Stažení a vrácení kódu toku výzvy
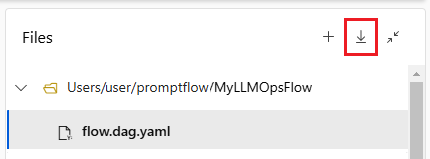
Pokud chcete zkontrolovat tok do úložiště kódu, exportujte složku toku z studio Azure Machine Learning do místního počítače. Výběrem ikony pro stažení v části Soubory na stránce vytváření toku stáhněte balíček ZIP obsahující všechny soubory toku. Pak můžete tento soubor zkontrolovat do úložiště kódu nebo ho rozbalit, abyste mohli pracovat se soubory místně.
Další informace o integraci DevOps se službou Azure Machine Learning najdete v tématu Integrace Gitu pro Azure Machine Learning.
Místní vývoj a testování
Při upřesňování a doladění toku nebo zobrazování výzev během iterativního vývoje můžete provádět několik iterací místně v úložišti kódu. Komunitní verze VS Code, rozšíření toku VS Code Prompt a místní sada SDK a rozhraní příkazového řádku toku usnadňují čistý místní vývoj a testování bez vazby Azure.
Práce místně umožňuje rychle provádět a testovat změny, aniž byste museli pokaždé aktualizovat hlavní úložiště kódu. Další podrobnosti a pokyny k používání místních verzí najdete v komunitě GitHubu s výzvou k toku.
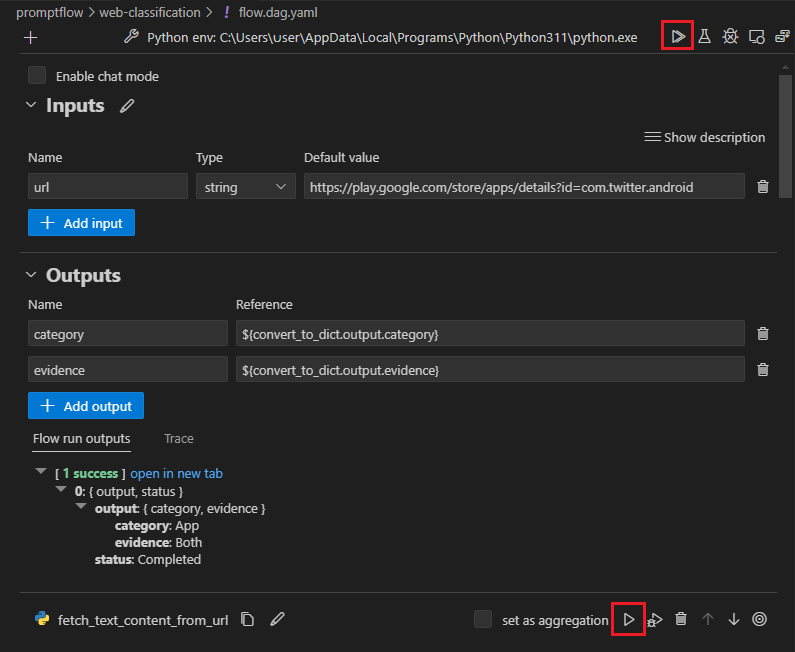
Použití rozšíření toku výzvy VS Code
Pomocí rozšíření VS Code toku výzvy můžete tok snadno vytvořit místně v editoru VS Code s podobným uživatelským rozhraním jako v cloudu.
Místní úpravy souborů ve VS Code pomocí rozšíření Tok výzvy:
Ve VS Code s povoleným rozšířením toku výzvy otevřete složku toku výzvy.
Otevřete soubor flow.dag.yaml a vyberte odkaz editoru vizuálů v horní části souboru.
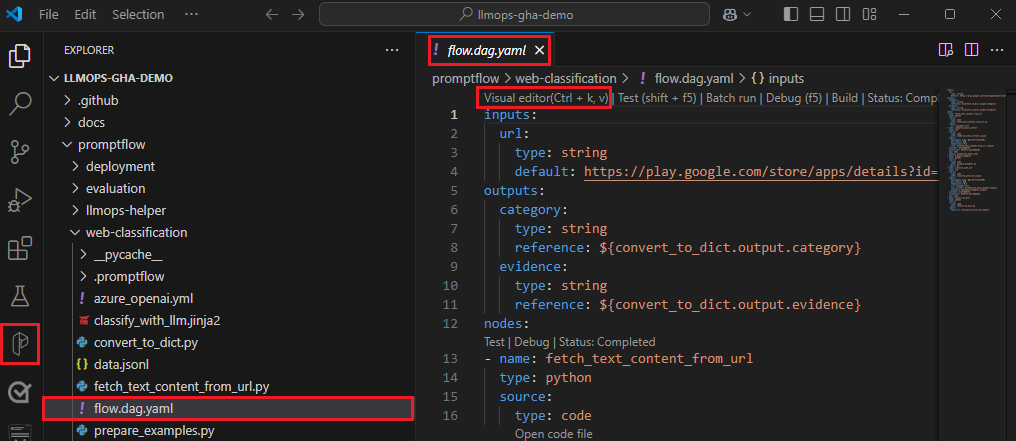
Pomocí vizuálního editoru toku výzvy proveďte změny toku, například ladění výzev ve variantách nebo přidání dalších uzlů.
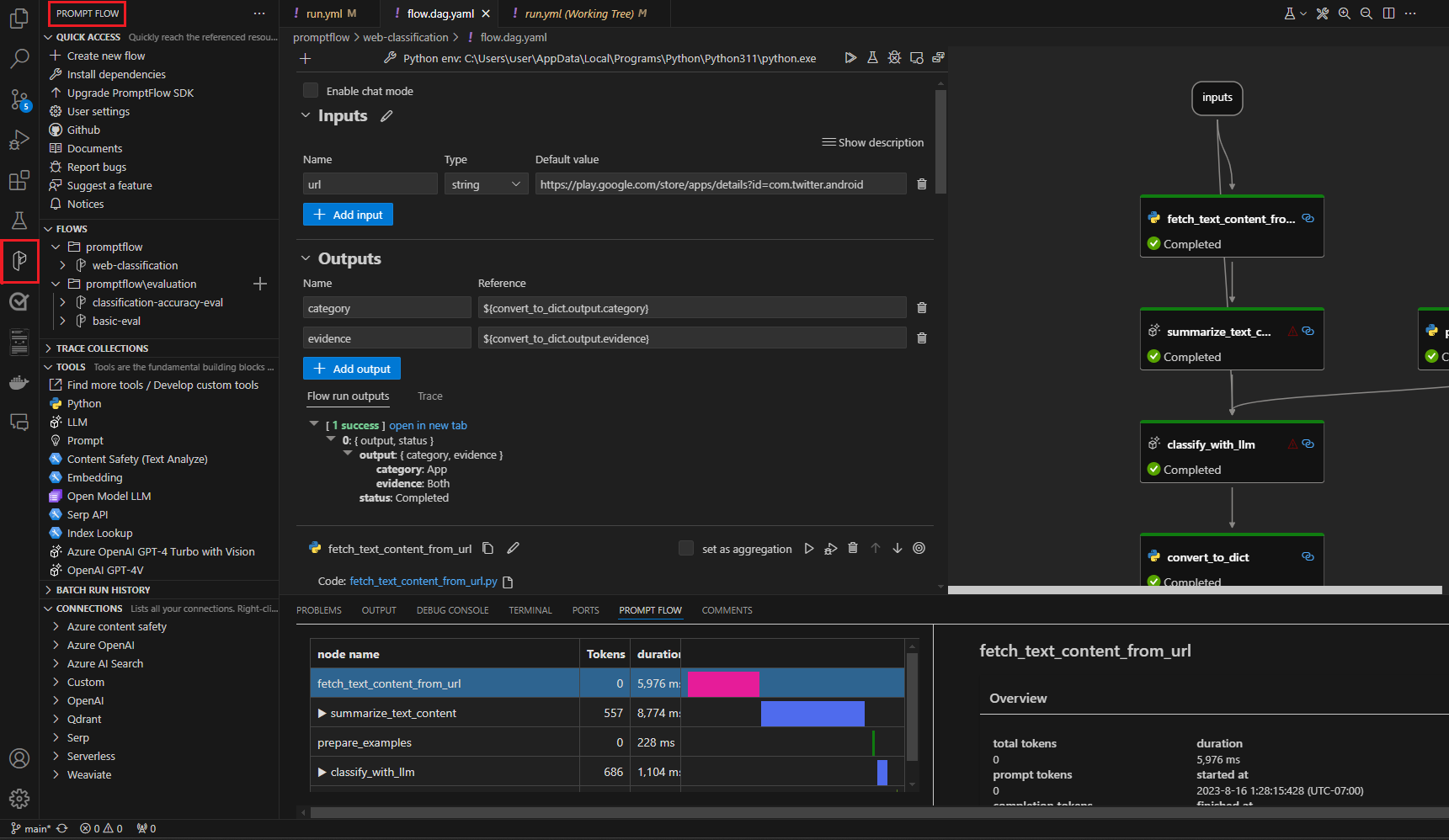
Pokud chcete tok otestovat, vyberte ikonu Spustit v horní části editoru vizuálů nebo otestujte libovolný uzel, vyberte ikonu Spustit v horní části uzlu.



Použití sady SDK toku výzvy a rozhraní příkazového řádku
Pokud raději pracujete přímo v kódu nebo používáte Jupyter, PyCharm, Visual Studio nebo jiné integrované vývojové prostředí (IDE), můžete kód YAML přímo upravit v souboru flow.dag.yaml .

Pak můžete spustit jeden tok pro testování pomocí příkazového rozhraní příkazového řádku nebo sady SDK v terminálu následujícím způsobem.
Pokud chcete spustit spuštění z pracovního adresáře, spusťte následující kód:
pf flow test --flow <directory-name>
Návratové hodnoty jsou testovací protokoly a výstupy.

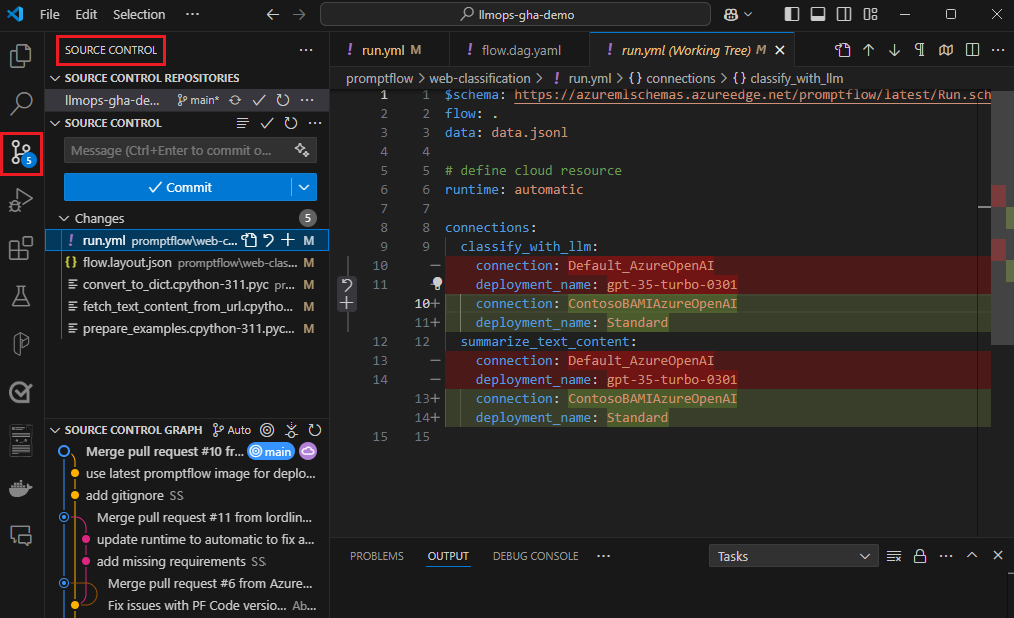
Odeslání spuštění do cloudu z místního úložiště
Jakmile budete s výsledky místního testování spokojeni, můžete pomocí příkazového řádku nebo sady SDK odeslat spuštění do cloudu z místního úložiště. Následující postup a kód jsou založené na ukázkovém projektu Klasifikace webu na GitHubu. Úložiště projektu můžete naklonovat nebo stáhnout kód toku výzvy do místního počítače.
Instalace sady SDK toku výzvy
Nainstalujte sadu SDK nebo rozhraní příkazového řádku Azure prompt tím, že spustíte pip install promptflow[azure] promptflow-tools.
Pokud používáte ukázkový projekt, získejte sadu SDK a další potřebné balíčky instalací requirements.txt s využitímpip install -r <path>/requirements.txt.
Připojení k pracovnímu prostoru Azure Machine Learning
az login
Nahrání toku a vytvoření spuštění
Připravte soubor run.yml k definování konfigurace pro tento tok spuštěný v cloudu.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
column_mapping:
url: ${data.url}
# Define cloud compute resource
resources:
instance_type: <compute-type>
# If using compute instance compute type, also specify instance name
# compute: <compute-instance-name>
# Specify connections
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Pro každý nástroj v toku, který vyžaduje připojení, můžete zadat název připojení a nasazení. Pokud nezadáte název připojení a nasazení, nástroj použije připojení a nasazení v souboru flow.dag.yaml . K formátování připojení použijte následující kód:
...
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
...
Vytvořte spuštění.
pfazure run create --file run.yml
Vytvoření spuštění toku vyhodnocení
Připravte soubor run_evaluation.yml k definování konfigurace pro tento tok vyhodnocení spuštěný v cloudu.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path-to-flow>
data: <path-to-flow>/<data-file>.jsonl
run: <id-of-base-flow-run>
column_mapping:
<input-name>: ${data.<column-from-test-dataset>}
<input-name>: ${run.outputs.<column-from-run-output>}
resources:
instance_type: <compute-type>
compute: <compute_instance_name>
connections:
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
<node-name>:
connection: <connection-name>
deployment_name: <deployment-name>
Vytvořte zkušební spuštění.
pfazure run create --file run_evaluation.yml
Zobrazení výsledků spuštění
Odeslání spuštění toku do cloudu vrátí adresu URL cloudu spuštění. Adresu URL můžete otevřít a zobrazit výsledky spuštění v studio Azure Machine Learning. Můžete také spustit následující příkazy rozhraní příkazového řádku nebo sady SDK a zobrazit výsledky spuštění.
Streamování protokolů
pfazure run stream --name <run-name>
Zobrazení výstupů spuštění
pfazure run show-details --name <run-name>
Zobrazení metrik spuštění vyhodnocení
pfazure run show-metrics --name <evaluation-run-name>
Integrace s DevOps
Kombinace místního vývojového prostředí a systému správy verzí, jako je Git, je obvykle nejúčinnější pro iterativní vývoj. Kód můžete upravit a otestovat místně a pak změny potvrdit do Gitu. Tento proces vytvoří průběžný záznam o vašich změnách a v případě potřeby nabízí možnost vrátit se k dřívějším verzím.
Když potřebujete sdílet toky napříč různými prostředími, můžete je odeslat do cloudového úložiště kódu, jako je GitHub nebo Azure Repos. Tato strategie umožňuje přístup k nejnovější verzi kódu z libovolného umístění a poskytuje nástroje pro spolupráci a správu kódu.
Díky těmto postupům můžou týmy vytvořit bezproblémové, efektivní a produktivní prostředí pro spolupráci pro vývoj toků.
Například kompletní kanály LLMOps, které spouštějí toky klasifikace webu, najdete v tématu Nastavení kompletního GenAIOps s výzvou Flow a GitHubu a ukázkovým projektem Klasifikace webu GitHubu.
Spuštění toku triggeru v kanálech CI
Po úspěšném vývoji a otestování toku a jeho vrácení se změnami jako počáteční verze jste připraveni na ladění a testování iterací. V této fázi můžete aktivovat spuštění toku, včetně dávkových testování a zkušebních spuštění, pomocí rozhraní příkazového řádku toku k automatizaci kroků v kanálu CI.
V průběhu životního cyklu iterací toku můžete pomocí rozhraní příkazového řádku automatizovat následující operace:
- Spuštění toku výzvy po žádosti o přijetí změn
- Spuštění vyhodnocení toku výzvy k zajištění vysoké kvality výsledků
- Registrace modelů toků výzvy
- Nasazení modelů toků výzvy
Použití uživatelského rozhraní studia pro průběžný vývoj
V každém okamžiku vývoje toku se můžete vrátit do studio Azure Machine Learning uživatelského rozhraní a použít cloudové prostředky a prostředí k provádění změn toku.
Pokud chcete pokračovat v vývoji a práci s nejaktuálnějšími verzemi souborů toku, můžete získat přístup k terminálu na stránce Poznámkový blok a stáhnout nejnovější soubory toku z úložiště. Nebo můžete přímo importovat místní složku toku jako nový tok konceptu, abyste mohli bezproblémově přecházet mezi místním a cloudovým vývojem.

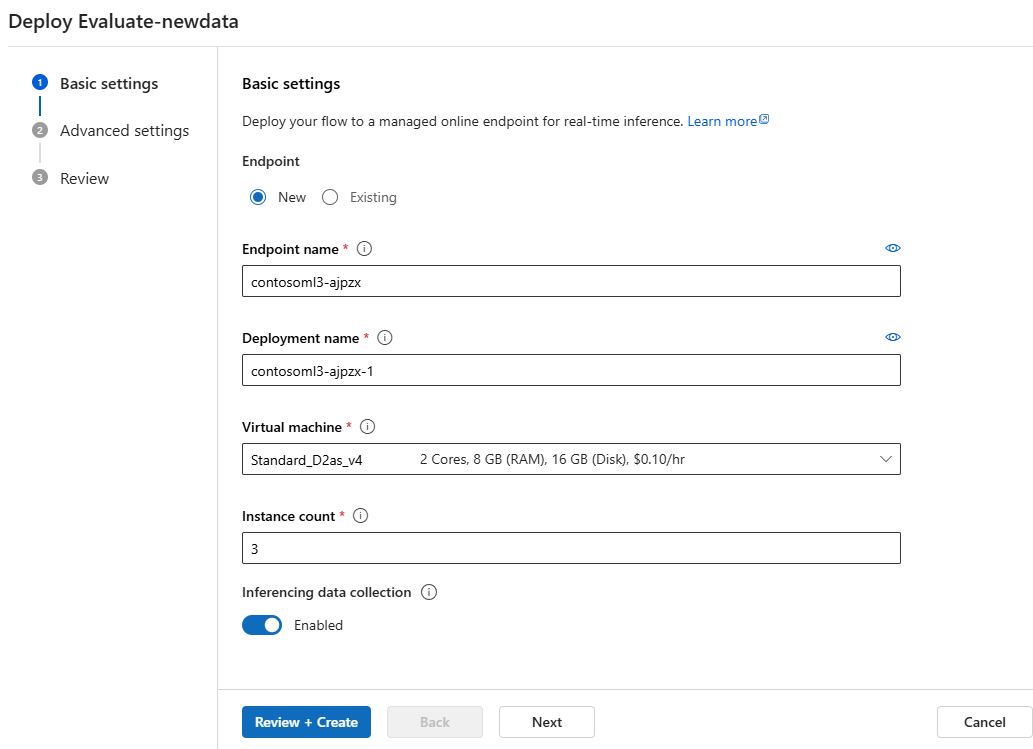
Nasazení toku jako online koncového bodu
Posledním krokem v produkčním prostředí je nasazení toku jako online koncového bodu ve službě Azure Machine Learning. Tento proces umožňuje integrovat tok do aplikace a zpřístupnit ho k použití. Další informace o nasazení toku najdete v tématu Nasazení toků do online koncového bodu spravovaného službou Azure Machine Learning pro odvozování v reálném čase.
Spolupráce na vývoji toků
Spolupráce mezi členy týmu může být důležitá při vývoji aplikace založené na LLM s tokem výzvy. Členové týmu můžou vytvářet a testovat stejný tok, pracovat na různých omezujících vlastností toku nebo provádět iterativní změny a vylepšení současně. Tato spolupráce vyžaduje efektivní a zjednodušený přístup ke sdílení kódu, sledování úprav, správě verzí a integraci změn do konečného projektu.
Rozšíření toku příkazového řádku nebo sady SDK a příkazového řádku VS Code usnadňují snadnou spolupráci na vývoji toku založeného na kódu v úložišti zdrojového kódu. Ke sledování změn, správě verzí a integraci těchto úprav do konečného projektu můžete použít cloudový systém správy zdrojového kódu, jako je GitHub nebo Azure Repos.
Dodržování osvědčených postupů pro spolupráci při vývoji
Nastavte centralizované úložiště kódu.
Prvním krokem procesu spolupráce je nastavení úložiště kódu jako základ pro kód projektu, včetně kódu toku výzvy. Toto centralizované úložiště umožňuje efektivní organizaci, sledování změn a spolupráci mezi členy týmu.
Vytvořte a otestujte tok místně ve VS Code pomocí rozšíření Tok výzvy.
Po nastavení úložiště můžou členové týmu použít VS Code s rozšířením Tok výzvy pro místní vytváření a testování jednoho vstupu toku. Standardizované integrované vývojové prostředí podporuje spolupráci mezi více členy pracujícími na různých aspektech toku.
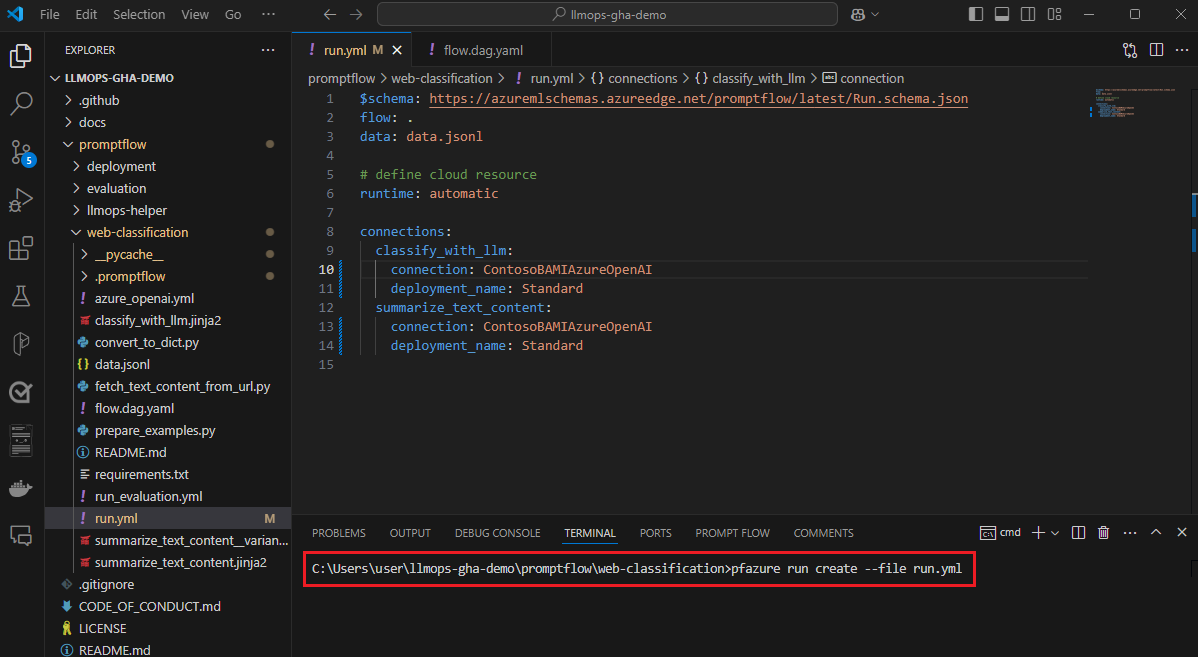
K odeslání dávkových spuštění a vyhodnocení z místních toků do cloudu použijte rozhraní příkazového
pfazureřádku nebo sadu SDK.Po místním vývoji a testování můžou členové týmu pomocí příkazového řádku nebo sady SDK toku odesílat a vyhodnocovat dávkové a vyhodnocovací spuštění do cloudu. Tento proces umožňuje využití cloudových výpočetních prostředků, trvalé úložiště výsledků, vytváření koncových bodů pro nasazení a efektivní správu v uživatelském rozhraní studia.
Výsledky spuštění můžete zobrazit a spravovat v uživatelském rozhraní pracovního prostoru studio Azure Machine Learning.
Po odeslání do cloudu můžou členové týmu získat přístup k uživatelskému rozhraní studia a efektivně zobrazit výsledky a spravovat experimenty. Cloudový pracovní prostor poskytuje centralizované umístění pro shromažďování a správu historie spuštění, protokolů, snímků, komplexních výsledků a vstupů a výstupů na úrovni instance.
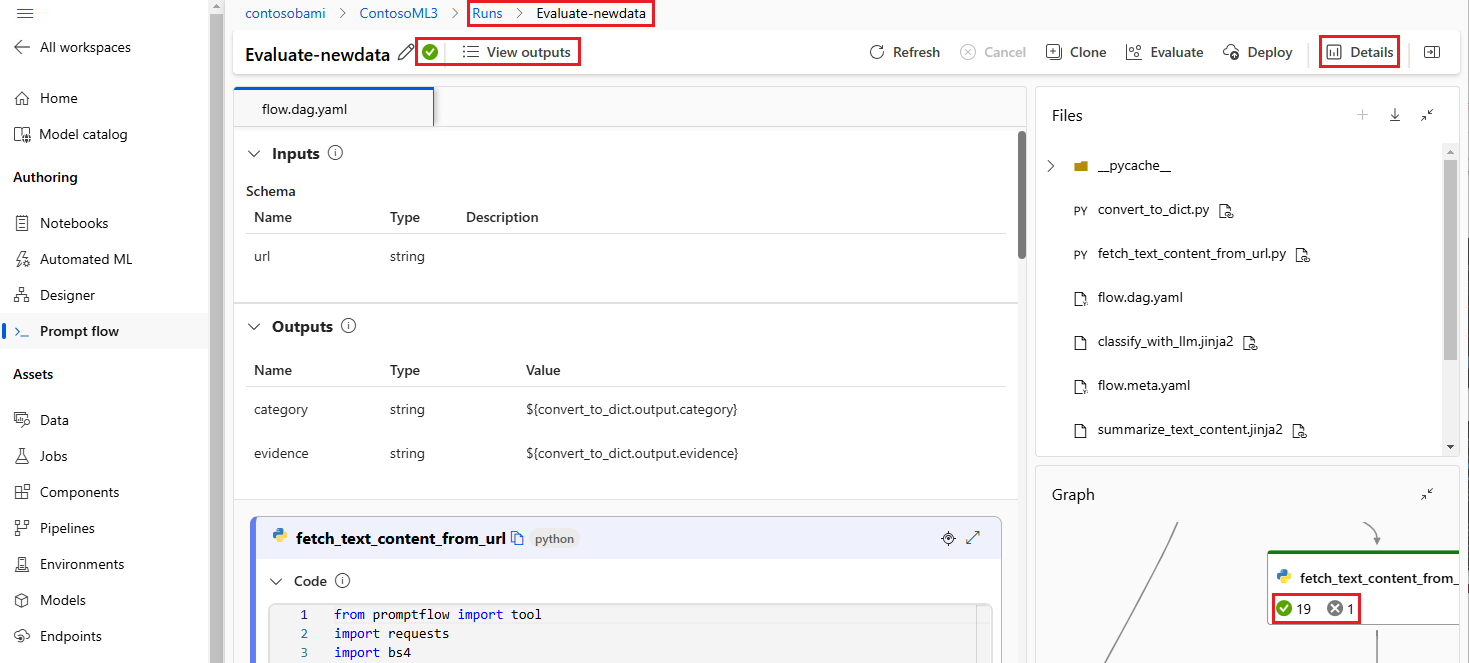
Pomocí seznamu Spuštění, který zaznamenává všechny historie spuštění, můžete snadno porovnat výsledky různých spuštění, které pomáhají při analýze kvality a nezbytných úpravách.
Pokračujte v používání místního iterativního vývoje.
Po analýze výsledků experimentů se členové týmu můžou vrátit do místního prostředí a úložiště kódu pro další vývoj a vyladění a iterativním odesláním následných spuštění do cloudu. Tento iterativní přístup zajišťuje konzistentní vylepšení, dokud tým nebude spokojen s kvalitou pro produkční prostředí.
Použijte jednokroové nasazení do produkčního prostředí v sadě Studio.
Jakmile je tým plně přesvědčený o kvalitě toku, může ho bez problémů nasadit jako online koncový bod v robustním cloudovém prostředí. Nasazení jako online koncový bod může být založené na snímku spuštění, což umožňuje stabilní a zabezpečené obsluhy, další přidělování prostředků a sledování využití a monitorování protokolů v cloudu.
Průvodce nasazením studio Azure Machine Learning vám pomůže snadno nakonfigurovat nasazení.