Použití paralelních úloh v kanálech
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Tento článek vysvětluje, jak pomocí rozhraní příkazového řádku v2 a sady Python SDK v2 spouštět paralelní úlohy v kanálech Služby Azure Machine Learning. Paralelní úlohy urychlují spouštění úloh distribucí opakovaných úloh na výkonných výpočetních clusterech s více uzly.
Technici strojového učení mají vždy požadavky na škálování na trénování nebo odvozování úkolů. Pokud například datový vědec poskytuje jeden skript pro trénování modelu predikce prodeje, musí technici strojového učení tuto trénovací úlohu použít pro každé jednotlivé úložiště dat. Výzvy tohoto procesu horizontálního navýšení kapacity zahrnují dlouhou dobu provádění, která způsobují zpoždění, a neočekávané problémy, které vyžadují ruční zásah, aby úloha zůstala spuštěná.
Základní úlohou paralelizace služby Azure Machine Learning je rozdělit jeden sériový úkol do minidávek a odeslat tyto minidávkové dávky do několika výpočetních prostředků, aby bylo provedeno paralelně. Paralelní úlohy výrazně zkracují dobu provádění na konci a také automaticky zpracovávají chyby. Zvažte použití paralelní úlohy Azure Machine Learning k trénování mnoha modelů nad dělenými daty nebo zrychlení úloh odvozování velkých dávek.
Například ve scénáři, ve kterém spouštíte model detekce objektů ve velké sadě imagí, umožňují paralelní úlohy Azure Machine Learning snadno distribuovat image tak, aby spouštěly vlastní kód paralelně na konkrétním výpočetním clusteru. Paralelizace může výrazně snížit časové náklady. Paralelní úlohy Azure Machine Learning můžou také zjednodušit a automatizovat proces, aby byl efektivnější.
Požadavky
- Máte účet a pracovní prostor služby Azure Machine Learning.
- Seznamte se s kanály Azure Machine Learning.
- Nainstalujte Azure CLI a
mlrozšíření. Další informace najdete v tématu Instalace, nastavení a použití rozhraní příkazového řádku (v2). Rozšířenímlautomaticky nainstaluje při prvním spuštěníaz mlpříkazu. - Zjistěte, jak vytvářet a spouštět kanály a komponenty služby Azure Machine Learning pomocí rozhraní příkazového řádku v2.
Vytvoření a spuštění kanálu s krokem paralelní úlohy
Paralelní úlohu Služby Azure Machine Learning je možné použít pouze jako krok v úloze kanálu.
Následující příklady pocházejí z spuštění úlohy kanálu pomocí paralelní úlohy v kanálu v úložišti příkladů služby Azure Machine Learning.
Příprava na paralelizaci
Tento paralelní krok úlohy vyžaduje přípravu. Potřebujete vstupní skript, který implementuje předdefinované funkce. V definici paralelní úlohy musíte také nastavit atributy, které:
- Definujte a svázejte vstupní data.
- Nastavte metodu dělení dat.
- Nakonfigurujte výpočetní prostředky.
- Zavolejte vstupní skript.
Následující části popisují, jak připravit paralelní úlohu.
Deklarujte nastavení vstupů a dělení dat.
Paralelní úloha vyžaduje rozdělení a zpracování jednoho hlavního vstupu paralelně. Hlavním vstupním formátem dat může být tabulková data nebo seznam souborů.
Různé formáty dat mají různé vstupní typy, režimy vstupu a metody dělení dat. Následující tabulka popisuje možnosti:
| Formát dat | Input type | Režim vstupu | Metoda dělení dat |
|---|---|---|---|
| Seznam souborů | mltable nebo uri_folder |
ro_mount nebo download |
Podle velikosti (počtu souborů) nebo podle oddílu |
| Tabulková data | mltable |
direct |
Podle velikosti (odhadovaná fyzická velikost) nebo podle oddílu |
Poznámka:
Pokud jako hlavní vstupní data používáte tabulkovou mltable tabulku, musíte:
- Nainstalujte knihovnu
mltabledo svého prostředí, jak je uvedeno v řádku 9 tohoto souboru conda. - V zadané cestě zadejte soubor specifikace MLTable s
transformations: - read_delimited:vyplněným oddílem. Příklady najdete v tématu Vytváření a správa datových prostředků.
Hlavní vstupní data můžete deklarovat pomocí atributu input_data v jazyce YAML paralelní úlohy nebo Pythonu a svázat data s definovanou input paralelní úlohou pomocí ${{inputs.<input name>}}. Potom definujete atribut dělení dat pro hlavní vstup v závislosti na metodě dělení dat.
| Metoda dělení dat | Attribute name | Typ atributu | Příklad úlohy |
|---|---|---|---|
| Podle velikosti | mini_batch_size |
string | Dávkové předpovědi Iris |
| Podle oddílu | partition_keys |
seznam řetězců | Předpověď prodeje pomerančové šťávy |
Konfigurace výpočetních prostředků pro paralelizaci
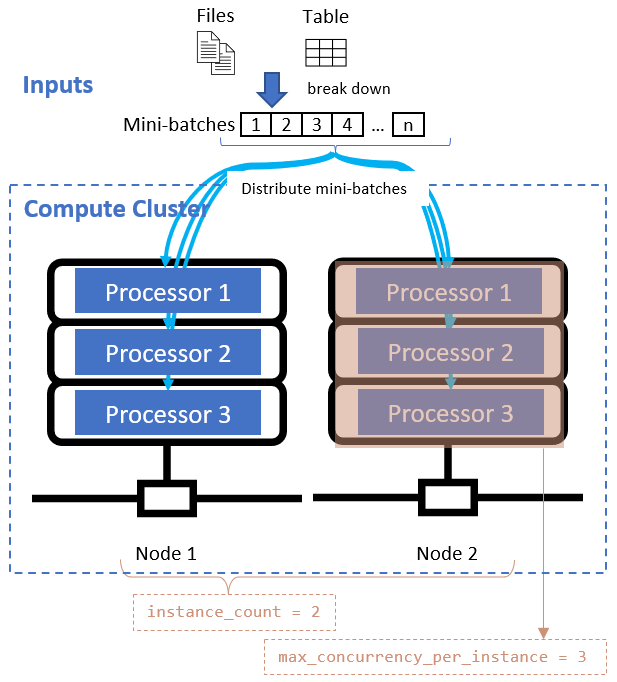
Po definování atributu dělení dat nakonfigurujte výpočetní prostředky pro paralelizaci nastavením instance_count atributů a max_concurrency_per_instance atributů.
| Attribute name | Type | Popis | Default value |
|---|---|---|---|
instance_count |
integer | Počet uzlů, které se mají pro úlohu použít. | 0 |
max_concurrency_per_instance |
integer | Počet procesorů na každém uzlu. | Pro výpočetní výkon GPU: 1. Pro výpočetní výkon procesoru: počet jader. |
Tyto atributy spolupracují se zadaným výpočetním clusterem, jak je znázorněno v následujícím diagramu:
Volání vstupního skriptu
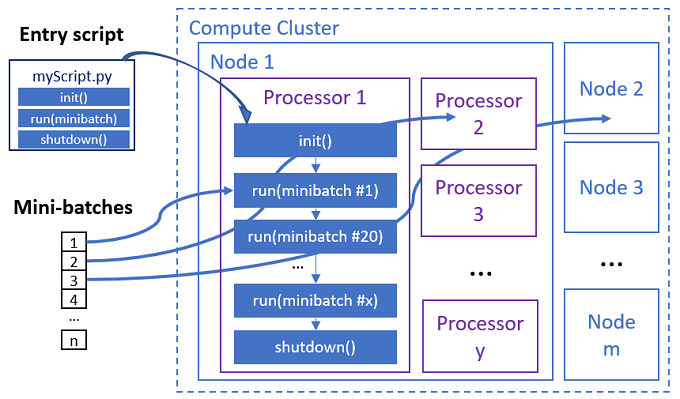
Vstupní skript je jeden soubor Pythonu, který implementuje následující tři předdefinované funkce s vlastním kódem.
| Název funkce | Požadováno | Description | Vstup | Zpět |
|---|---|---|---|---|
Init() |
Y | Běžná příprava před zahájením spouštění minidávek. Pomocí této funkce můžete například načíst model do globálního objektu. | -- | -- |
Run(mini_batch) |
Y | Implementuje logiku hlavního spouštění pro mini-dávky. | mini_batch je datový rámec pandas, pokud vstupní data jsou tabulková data, nebo seznam cest k souboru, pokud vstupní data jsou adresář. |
Datový rámec, seznam nebo řazená kolekce členů |
Shutdown() |
N | Volitelná funkce, která před vrácením výpočetních prostředků do fondu provede vlastní čištění. | -- | -- |
Důležité
Chcete-li zabránit výjimkám při analýze argumentů nebo Init() Run(mini_batch) funkcí, použijte parse_known_args místo parse_args. Podívejte se na iris_score příklad vstupního skriptu s analyzátorem argumentů.
Důležité
Funkce Run(mini_batch) vyžaduje vrácení datového rámce, seznamu nebo položky řazené kolekce členů. Paralelní úloha používá počet, který se vrátí k měření položek úspěchu v rámci této minidávkové dávky. Minimální počet dávek by měl být roven počtu vrácených seznamů, pokud byly zpracovány všechny položky.
Paralelní úloha spouští funkce v každém procesoru, jak je znázorněno v následujícím diagramu.
Projděte si následující příklady vstupních skriptů:
Chcete-li volat vstupní skript, nastavte následující dva atributy v definici paralelní úlohy:
| Attribute name | Type | Description |
|---|---|---|
code |
string | Místní cesta k adresáři zdrojového kódu pro nahrání a použití pro úlohu. |
entry_script |
string | Soubor Pythonu, který obsahuje implementaci předdefinovaných paralelních funkcí. |
Příklad kroku paralelní úlohy
Následující paralelní krok úlohy deklaruje typ vstupu, režim a metodu dělení dat, vytvoří vazbu vstupu, nakonfiguruje výpočetní prostředky a zavolá vstupní skript.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Zvažte nastavení automatizace.
Paralelní úloha Azure Machine Learning zveřejňuje mnoho volitelných nastavení, která můžou automaticky řídit úlohu bez ručního zásahu. Tato nastavení jsou popsána v následující tabulce.
| Klíč | Typ | Popis | Povolené hodnoty | Default value | Nastavit v argumentu atribut nebo programu |
|---|---|---|---|---|---|
mini_batch_error_threshold |
integer | Počet neúspěšných minidávek, které se mají v této paralelní úloze ignorovat. Pokud je počet neúspěšných minidávek vyšší než tato prahová hodnota, znamená to, že paralelní úloha se označí jako neúspěšná. Minidávka se označí jako neúspěšná, pokud: - Počet vrácených hodnot run() je menší než minimální počet vstupů dávky.– Výjimky jsou zachyceny ve vlastním run() kódu. |
[-1, int.max] |
-1, což znamená ignorovat všechny neúspěšné minidály |
Atribut mini_batch_error_threshold |
mini_batch_max_retries |
integer | Počet opakování v případě selhání nebo vypršení časového limitu minidávkové dávky Pokud všechny opakování selžou, je minidávka označená jako neúspěšná podle mini_batch_error_threshold výpočtu. |
[0, int.max] |
2 |
Atribut retry_settings.max_retries |
mini_batch_timeout |
integer | Časový limit v sekundách pro spuštění vlastní run() funkce Pokud je doba provádění vyšší než tato prahová hodnota, přeruší se minidávka a označí se jako neúspěšná aktivace opakování. |
(0, 259200] |
60 |
Atribut retry_settings.timeout |
item_error_threshold |
integer | Prahová hodnota neúspěšných položek Neúspěšné položky se počítají podle počtu mezer mezi vstupy a výnosy z každé minidávkové dávky. Pokud je součet neúspěšných položek vyšší než tato prahová hodnota, je paralelní úloha označena jako neúspěšná. | [-1, int.max] |
-1, což znamená ignorovat všechna selhání během paralelní úlohy |
Argument programu--error_threshold |
allowed_failed_percent |
integer | mini_batch_error_thresholdPodobně jako v případě , ale používá procento neúspěšných minidávek místo počtu. |
[0, 100] |
100 |
Argument programu--allowed_failed_percent |
overhead_timeout |
integer | Časový limit v sekundách pro inicializaci každé minidávkové dávky Například načtěte minidávová data a předejte je funkci run() . |
(0, 259200] |
600 |
Argument programu--task_overhead_timeout |
progress_update_timeout |
integer | Časový limit v sekundách pro monitorování průběhu minidávkového spouštění Pokud v tomto nastavení časového limitu nejsou přijaty žádné aktualizace průběhu, je paralelní úloha označena jako neúspěšná. | (0, 259200] |
Dynamicky vypočítané jinými nastaveními | Argument programu--progress_update_timeout |
first_task_creation_timeout |
integer | Časový limit v sekundách pro monitorování času mezi spuštěním úlohy a spuštěním první minidávkové dávky | (0, 259200] |
600 |
Argument programu--first_task_creation_timeout |
logging_level |
string | Úroveň protokolů, které se mají vypíše do souborů protokolů uživatelů. | INFO, WARNING nebo DEBUG |
INFO |
Atribut logging_level |
append_row_to |
string | Agregujte všechny výnosy z každého spuštění minidávkové dávky a vypíšete je do tohoto souboru. Může odkazovat na jeden z výstupů paralelní úlohy pomocí výrazu. ${{outputs.<output_name>}} |
Atribut task.append_row_to |
||
copy_logs_to_parent |
string | Logická možnost, jestli chcete zkopírovat průběh úlohy, přehled a protokoly do nadřazené úlohy kanálu. | True nebo False |
False |
Argument programu--copy_logs_to_parent |
resource_monitor_interval |
integer | Časový interval v sekundách pro výpis využití prostředků uzlu (například procesor nebo paměť) pro protokolování složky v cestě logs/sys/perf . Poznámka: Časté protokoly prostředků výpisu paměti mírně pomalé spouštění. Nastavte tuto hodnotu tak, aby 0 se zastavilo dumpingové využití prostředků. |
[0, int.max] |
600 |
Argument programu--resource_monitor_interval |
Následující ukázkový kód aktualizuje tato nastavení:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Vytvoření kanálu s krokem paralelní úlohy
Následující příklad ukazuje úplnou úlohu kanálu s vloženým krokem paralelní úlohy:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Odeslání úlohy kanálu
Pomocí příkazu CLI odešlete úlohu kanálu s paralelním az ml job create krokem:
az ml job create --file pipeline.yml
Kontrola paralelního kroku v uživatelském rozhraní studia
Po odeslání úlohy kanálu vám widget SDK nebo rozhraní příkazového řádku poskytne odkaz na webovou adresu URL grafu kanálu v uživatelském rozhraní studio Azure Machine Learning.
Pokud chcete zobrazit výsledky paralelní úlohy, poklikejte na paralelní krok v grafu kanálu, na panelu podrobností vyberte kartu Nastavení, rozbalte nastavení spuštění a rozbalte oddíl Paralelní.

Pokud chcete ladit selhání paralelní úlohy, vyberte kartu Výstupy a protokoly , rozbalte složku protokolů a zkontrolujte job_result.txt , abyste pochopili, proč paralelní úloha selhala. Informace o struktuře protokolování paralelních úloh najdete v tématu readme.txt ve stejné složce.
