Řešení potíží s výpočetními prostředky Kubernetes
V tomto článku se dozvíte, jak řešit běžné chyby úloh na výpočetních prostředcích Kubernetes. Mezi běžné chyby patří úlohy trénování a chyby koncových bodů.
Průvodce odvozováním
Běžné chyby koncových bodů Kubernetes ve výpočetních prostředcích Kubernetes jsou rozdělené do dvou oborů: rozsah výpočetních prostředků a rozsah clusteru. Chyby rozsahu výpočetních prostředků souvisejí s cílovým výpočetním objektem, jako je například cílový výpočetní objekt, nebyl nalezen nebo cílový výpočetní objekt není přístupný. Chyby rozsahu clusteru souvisejí se základním clusterem Kubernetes, jako je samotný cluster, není dostupný nebo se cluster nenajde.
Chyby výpočetních prostředků Kubernetes
Níže jsou uvedené běžné typy chyb v rozsahu výpočetních prostředků, se kterými se můžete setkat při použití výpočetních prostředků Kubernetes k vytváření online koncových bodů a online nasazení pro odvozování modelů v reálném čase. Můžete se střílet podle propojených částí pokynů:
- CHYBA: GenericComputeError
- CHYBA: ComputeNotFound
- CHYBA: ComputeNotAccessible
- CHYBA: InvalidComputeInformation
- CHYBA: InvalidComputeNoKubernetesConfiguration
CHYBA: GenericComputeError
Chybová zpráva je následující:
Failed to get compute information.
K této chybě by mělo dojít v případě, že se systému nepodařilo získat informace o výpočetních prostředcích z clusteru Kubernetes. Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
- Zkontrolujte stav clusteru Kubernetes. Pokud cluster není spuštěný, musíte nejprve spustit cluster.
- Zkontrolujte stav clusteru Kubernetes.
- Sestavu kontroly stavu clusteru můžete zobrazit pro všechny problémy, například pokud cluster není dostupný.
- Můžete přejít na portál pracovního prostoru a zkontrolovat stav výpočetních prostředků.
- Zkontrolujte, jestli jsou typy instancí správné. Podporované typy instancí můžete zkontrolovat v dokumentaci ke výpočetním prostředkům Kubernetes.
- Pokud je to možné, zkuste výpočetní prostředky odpojit a znovu připojit k pracovnímu prostoru.
Poznámka:
Pokud chcete střílet chyby opětovným připojením, ujistěte se, že chcete znovu připojit stejnou konfiguraci jako dříve odpojené výpočetní prostředky, jako je stejný název výpočetních prostředků a obor názvů, jinak může dojít k jiným chybám.
CHYBA: ComputeNotFound
Chybová zpráva je následující:
Cannot find Kubernetes compute.
K této chybě by mělo dojít v těchto případech:
- Systém nemůže najít výpočetní prostředky při vytváření nebo aktualizaci nového online koncového bodu nebo nasazení.
- Odebrali jsme výpočetní prostředky stávajících online koncových bodů a nasazení.
Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
- Zkuste znovu vytvořit koncový bod a nasazení.
- Zkuste výpočetní prostředky odpojit a znovu připojit k pracovnímu prostoru. Věnujte pozornost dalším poznámkám o opětovném připojení.
CHYBA: ComputeNotAccessible
Chybová zpráva je následující:
The Kubernetes compute is not accessible.
K této chybě by mělo dojít v případě, že MSI pracovního prostoru (spravovaná identita) nemá přístup ke clusteru AKS. Můžete zkontrolovat, jestli má MSI pracovního prostoru přístup k AKS, a pokud ne, můžete postupovat podle tohoto dokumentu a spravovat přístup a identitu.
CHYBA: InvalidComputeInformation
Chybová zpráva je následující:
The compute information is invalid.
Při nasazování modelů do clusteru Kubernetes existuje proces ověření cílového výpočetního objektu. K této chybě by mělo dojít, když jsou informace o výpočetních prostředcích neplatné. Například cílový výpočetní objekt se nenašel nebo se v clusteru Kubernetes aktualizovala konfigurace rozšíření Azure Machine Learning.
Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
- Zkontrolujte, jestli je použitý výpočetní cíl správný a existující ve vašem pracovním prostoru.
- Zkuste výpočetní prostředky odpojit a znovu připojit k pracovnímu prostoru. Věnujte pozornost dalším poznámkám o opětovném připojení.
CHYBA: InvalidComputeNoKubernetesConfiguration
Chybová zpráva je následující:
The compute kubeconfig is invalid.
K této chybě by mělo dojít v případě, že se systému nepodařilo najít žádnou konfiguraci pro připojení ke clusteru, například:
- V případě clusteru Arc-Kubernetes není k dispozici žádná konfigurace služby Azure Relay.
- V případě clusteru AKS není k dispozici žádná konfigurace AKS.
Pokud chcete v clusteru znovu sestavit konfiguraci výpočetního připojení, můžete se pokusit výpočetní prostředky odpojit a znovu připojit k pracovnímu prostoru. Věnujte pozornost dalším poznámkám o opětovném připojení.
Chyba clusteru Kubernetes
Níže je seznam typů chyb v oboru clusteru, se kterými se můžete setkat při použití výpočetních prostředků Kubernetes k vytváření online koncových bodů a online nasazení pro odvozování modelů v reálném čase, které můžete střílet podle pokynů:
- CHYBA: GenericClusterError
- CHYBA: ClusterNotReachable
- CHYBA: ClusterNotFound
- CHYBA: ClusterServiceNotFound
- CHYBA: ClusterUnauthorized
CHYBA: GenericClusterError
Chybová zpráva je následující:
Failed to connect to Kubernetes cluster: <message>
K této chybě by mělo dojít v případě, že se systém kvůli neznámému důvodu nepodařilo připojit ke clusteru Kubernetes. Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
Pro clustery AKS:
- Zkontrolujte, jestli je cluster AKS vypnutý.
- Pokud cluster není spuštěný, musíte nejprve spustit cluster.
- Zkontrolujte, jestli cluster AKS povolil vybranou síť pomocí autorizovaných rozsahů IP adres.
- Pokud cluster AKS povolil autorizované rozsahy IP adres, ujistěte se, že jsou pro cluster AKS povolené všechny rozsahy IP roviny řízení služby Azure Machine Learning. Další informace, které můžete zobrazit v tomto dokumentu
Pro cluster AKS nebo cluster Kubernetes s podporou Azure Arc:
- Spuštěním
kubectlpříkazu v clusteru zkontrolujte, jestli je server rozhraní API Kubernetes přístupný.
CHYBA: ClusterNotReachable
Chybová zpráva je následující:
The Kubernetes cluster is not reachable.
K této chybě by mělo dojít, když se systém nemůže připojit ke clusteru. Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
Pro clustery AKS:
- Zkontrolujte, jestli je cluster AKS vypnutý.
- Pokud cluster není spuštěný, musíte nejprve spustit cluster.
Pro cluster AKS nebo cluster Kubernetes s podporou Azure Arc:
- Spuštěním
kubectlpříkazu v clusteru zkontrolujte, jestli je server rozhraní API Kubernetes přístupný.
CHYBA: ClusterNotFound
Chybová zpráva je následující:
Cannot found Kubernetes cluster.
K této chybě by mělo dojít, když systém nemůže najít cluster AKS/Arc-Kubernetes.
Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
- Nejprve zkontrolujte ID prostředku clusteru na webu Azure Portal a ověřte, jestli prostředek clusteru Kubernetes stále existuje a běží normálně.
- Pokud cluster existuje a je spuštěný, můžete se pokusit odpojit a znovu připojit výpočetní prostředky k pracovnímu prostoru. Věnujte pozornost dalším poznámkám o opětovném připojení.
CHYBA: ClusterServiceNotFound
Chybová zpráva je následující:
AzureML extension service not found in cluster.
K této chybě by mělo dojít, když služba příchozího přenosu dat vlastněná rozšířením nemá dostatek back-endových podů.
Můžete provádět následující akce:
- Přejděte ke clusteru a zkontrolujte stav služby
azureml-ingress-nginx-controllera jeho back-endového poduazuremlv oboru názvů. - Pokud cluster nemá spuštěné back-endové pody, zkontrolujte důvod popisem podu. Pokud například pod nemá dostatek prostředků ke spuštění, můžete některé pody odstranit, abyste uvolnili dostatek prostředků pro pod příchozího přenosu dat.
CHYBA: ClusterUnauthorized
Chybová zpráva je následující:
Request to Kubernetes cluster unauthorized.
K této chybě by mělo dojít pouze v clusteru s podporou technického poradce, což znamená, že platnost přístupového tokenu vypršela během nasazení.
Můžete to zkusit znovu po několika minutách.
Tip
Další průvodce odstraňováním běžných chyb při vytváření nebo aktualizaci online koncových bodů a nasazení Kubernetes najdete v tématu Řešení potíží s online koncovými body.
Chyba identity
CHYBA: RefreshExtensionIdentityNotSet
K této chybě dochází při instalaci rozšíření, ale identita rozšíření není správně přiřazena. Můžete zkusit rozšíření přeinstalovat a opravit ho.
Všimněte si, že tato chyba se týká jenom spravovaných clusterů.
Jak zkontrolovat správnost sslCertPemFile a sslKeyPemFile?
Abyste umožnili zobrazení všech známých chyb, můžete pomocí příkazů spustit základní kontrolu certifikátu a klíče. Počítejte s tím, že druhý příkaz vrátí "klíč RSA ok" bez výzvy k zadání hesla.
openssl x509 -in cert.pem -noout -text
openssl rsa -in key.pem -noout -check
Spuštěním příkazů ověřte, jestli se shodují sslCertPemFile a sslKeyPemFile:
openssl x509 -in cert.pem -noout -modulus | md5sum
openssl rsa -in key.pem -noout -modulus | md5sum
Pro sslCertPemFile se jedná o veřejný certifikát. Měl by obsahovat řetěz certifikátů, který obsahuje následující certifikáty a měl by být v posloupnosti certifikátu serveru, certifikátu zprostředkující certifikační autority a kořenového certifikátu certifikační autority:
- Certifikát serveru: Server prezentuje klientovi během metody handshake protokolu TLS. Obsahuje veřejný klíč serveru, název domény a další informace. Certifikát serveru je podepsaný zprostředkující certifikační autoritou (CA), která vychovává identitu serveru.
- Certifikát zprostředkující certifikační autority: zprostředkující certifikační autorita prezentuje klientovi, aby prokázala svou autoritu k podepsání certifikátu serveru. Obsahuje veřejný klíč, název a další informace zprostředkující certifikační autority. Certifikát zprostředkující certifikační autority je podepsaný kořenovou certifikační autoritou, která vymýšlí identitu zprostředkující certifikační autority.
- Kořenový certifikát certifikační autority: Kořenová certifikační autorita prezentuje klientovi, aby prokázala svou autoritu k podepsání certifikátu zprostředkující certifikační autority. Obsahuje veřejný klíč, název a další informace kořenové certifikační autority. Kořenový certifikát certifikační autority je podepsaný svým držitelem a je důvěryhodný klientem.
Průvodce školením
Po spuštění trénovací úlohy můžete zkontrolovat stav úlohy na portálu pracovního prostoru. Když narazíte na nějaký neobvyklý stav úlohy, jako je opakovaný opakovaný postup úlohy nebo se úloha zasekla ve stavu inicializace, nebo dokonce úloha nakonec selhala, můžete postupovat podle pokynů k řešení problému.
Ladění opakování úlohy
Pokud byl pod trénovací úlohy spuštěný v clusteru ukončen z důvodu uzlu spuštěného do OOM uzlu (nedostatek paměti), úloha se automaticky opakuje na jiný dostupný uzel.
Pokud chcete dále ladit původní příčinu pokusu o úlohu, můžete přejít na portál pracovního prostoru a zkontrolovat protokol opakování úlohy.
- Každý protokol opakování se zaznamená do nové složky protokolu s formátem "retry-retry< number>" (například: retry-001).
Pak můžete získat informace o mapování uzlu úlohy opakování a zjistit, na kterém uzlu byla úloha opakování spuštěna.
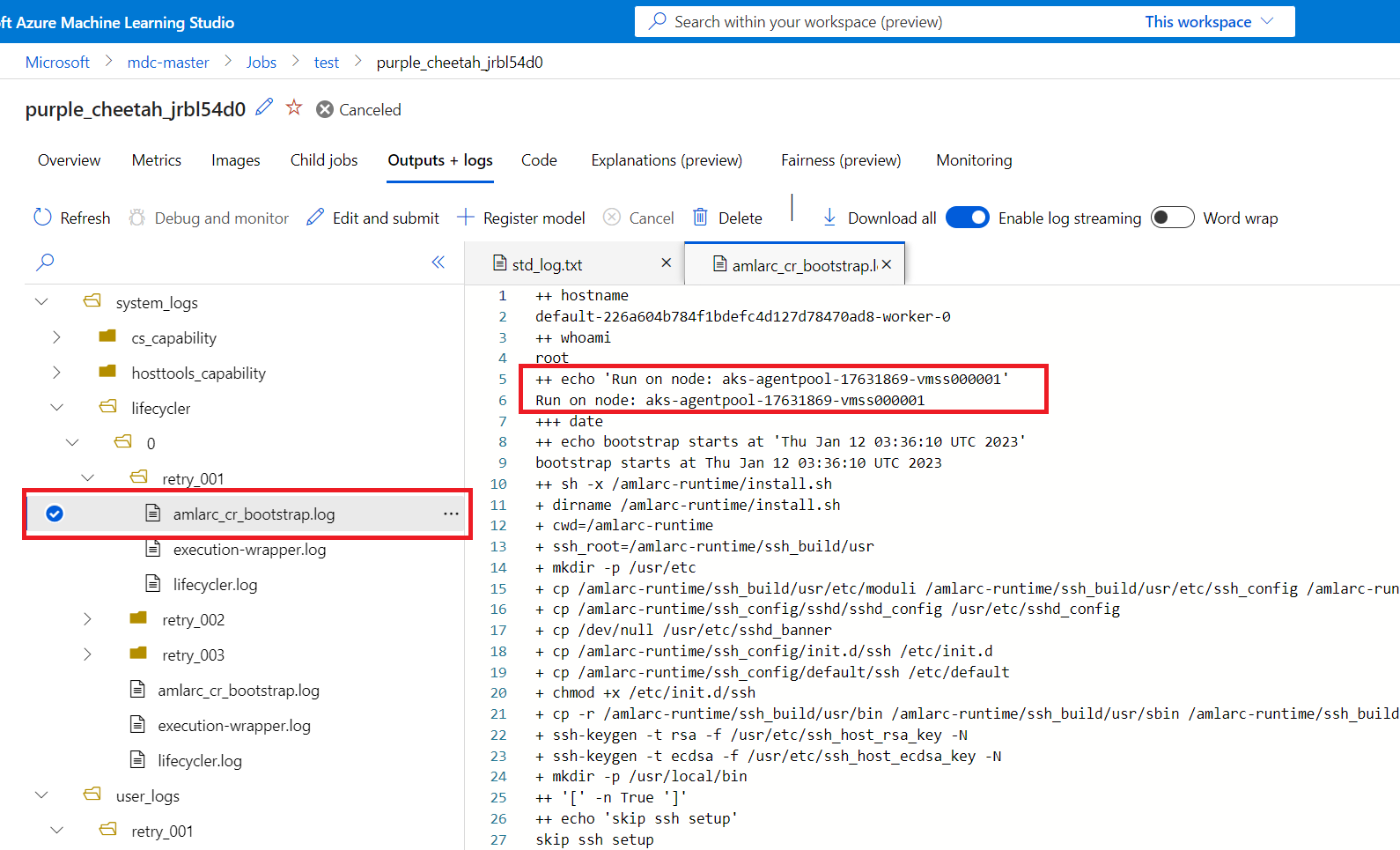
Informace o mapování uzlů úloh můžete získat z amlarc_cr_bootstrap.log ve složce system_logs.
Název hostitele uzlu, na kterém je pod úlohy spuštěný, je uvedený v tomto protokolu, například:
++ echo 'Run on node: ask-agentpool-17631869-vmss0000"
"ask-agentpool-17631869-vmss0000" představuje název hostitele uzlu, který spouští tuto úlohu v clusteru AKS. Pak můžete ke clusteru získat přístup a zkontrolovat stav uzlu pro další šetření.
Pod úlohy se zasekne ve stavu Init
Pokud úloha běží déle, než jste očekávali, a pokud zjistíte, že se pody úloh zablokují ve stavu Init s tímto upozorněním, může k tomuto problému Unable to attach or mount volumes: *** failed to get plugin from volumeSpec for volume ***-blobfuse-*** err=no volume plugin matcheddojít, protože rozšíření Azure Machine Learning nepodporuje režim stahování vstupních dat.
Pokud chcete tento problém vyřešit, změňte režim připojení pro vstupní data.
Běžné chyby selhání úloh
Níže je seznam běžných typů chyb, se kterými se můžete setkat při použití výpočetních prostředků Kubernetes k vytvoření a spuštění trénovací úlohy, které můžete střílet podle pokynů:
- Úloha selhala. 137
- Úloha selhala. E45004
- Úloha selhala. 400
- Poskytněte klíč účtu nebo token SAS
- Autorizace objektu blob Azure selhala
Úloha selhala. 137
Pokud je chybová zpráva:
Azure Machine Learning Kubernetes job failed. 137:PodPattern matched: {"containers":[{"name":"training-identity-sidecar","message":"Updating certificates in /etc/ssl/certs...\n1 added, 0 removed; done.\nRunning hooks in /etc/ca-certificates/update.d...\ndone.\n * Serving Flask app 'msi-endpoint-server' (lazy loading)\n * Environment: production\n WARNING: This is a development server. Do not use it in a production deployment.\n Use a production WSGI server instead.\n * Debug mode: off\n * Running on http://127.0.0.1:12342/ (Press CTRL+C to quit)\n","code":137}]}
Zkontrolujte nastavení proxy serveru a zkontrolujte, jestli bylo při použití az connectedk8s connect této konfigurace sítě přidáno 127.0.0.1 do rozsahu přeskočení proxy serveru.
Úloha selhala. E45004
Pokud je chybová zpráva:
Azure Machine Learning Kubernetes job failed. E45004:"Training feature is not enabled, please enable it when install the extension."
Zkontrolujte, jestli jste při enableTraining=True instalaci rozšíření Azure Machine Learning nastavili. Další podrobnosti najdete v tématu Nasazení rozšíření Azure Machine Learning v clusteru AKS nebo Arc Kubernetes.
Úloha selhala. 400
Pokud je chybová zpráva:
Azure Machine Learning Kubernetes job failed. 400:{"Msg":"Encountered an error when attempting to connect to the Azure Machine Learning token service","Code":400}
Pokud chcete zkontrolovat nastavení sítě, můžete postupovat podle části řešení potíží se službou Private Link.
Poskytněte klíč účtu nebo token SAS
Pokud potřebujete získat přístup ke službě Azure Container Registry (ACR) pro image Dockeru a získat přístup k účtu úložiště pro trénovací data, měl by k tomuto problému dojít v případě, že výpočetní prostředky nejsou zadané se spravovanou identitou.
Pokud chcete získat přístup ke službě Azure Container Registry (ACR) z výpočetního clusteru Kubernetes pro image Dockeru nebo získat přístup k účtu úložiště pro trénovací data, musíte výpočetní prostředky Kubernetes připojit s povolenou spravovanou identitou přiřazenou systémem nebo přiřazenou uživatelem.
Ve výše uvedeném scénáři trénování je tato výpočetní identita nezbytná pro použití výpočetních prostředků Kubernetes jako přihlašovací údaje ke komunikaci mezi prostředkem ARM vázaným na pracovní prostor a výpočetním clusterem Kubernetes. Bez této identity se tedy úloha trénování nezdaří a nahlásí chybějící klíč účtu nebo token SAS. Pokud například pro výpočetní prostředky Kubernetes nezadáte spravovanou identitu, úloha selže s následující chybovou zprávou:
Unable to mount data store workspaceblobstore. Give either an account key or SAS token
Příčinou je, že výchozí účet úložiště strojového učení bez přihlašovacích údajů není přístupný pro trénovací úlohy ve výpočetních prostředcích Kubernetes.
Pokud chcete tento problém zmírnit, můžete přiřadit spravovanou identitu výpočetním prostředkům v kroku připojení výpočetních prostředků nebo po připojení spravované identity k výpočetnímu objektu. Další podrobnosti najdete v části Přiřadit spravovanou identitu k cílovému výpočetnímu objektu.
Autorizace objektu blob Azure selhala
Pokud potřebujete získat přístup k AzureBlobu pro nahrání nebo stažení dat ve výpočetních úlohách Kubernetes, úloha selže s následující chybovou zprávou:
Unable to upload project files to working directory in AzureBlob because the authorization failed.
Příčinou je selhání autorizace, když se úloha pokusí nahrát soubory projektu do AzureBlobu. Pokud chcete tento problém vyřešit, můžete zkontrolovat následující položky:
- Ujistěte se, že účet úložiště povolil výjimky "Povolit službám Azure v seznamu důvěryhodných služeb přístup k tomuto účtu úložiště" a pracovní prostor je v seznamu instancí prostředků.
- Ujistěte se, že má pracovní prostor spravovanou identitu přiřazenou systémem.
Problém se službou Private Link
Metodu můžeme použít ke kontrole nastavení privátního propojení tak, že se v clusteru Kubernetes přihlásíme k jednomu podu a pak zkontrolujeme související nastavení sítě.
Vyhledejte ID pracovního prostoru na webu Azure Portal nebo získejte toto ID spuštěním
az ml workspace showna příkazovém řádku.Zobrazit všechny pody azureml-fe spuštěné uživatelem
kubectl get po -n azureml -l azuremlappname=azureml-fe.Přihlaste se k některému z nich
kubectl exec -it -n azureml {scorin_fe_pod_name} bash.Pokud cluster nepoužívá proxy server, spusťte
nslookup {workspace_id}.workspace.{region}.api.azureml.msho. Pokud nastavíte privátní propojení z virtuální sítě do pracovního prostoru správně, měla by být interní IP adresa ve virtuální síti zodpovězena nástrojem DNSLookup .Pokud cluster používá proxy server, můžete se pokusit o
curlpracovní prostor.
curl https://{workspace_id}.workspace.westcentralus.api.azureml.ms/metric/v2.0/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{workspace_name}/api/2.0/prometheus/post -X POST -x {proxy_address} -d {} -v -k
Pokud je proxy server a pracovní prostor správně nastavené pomocí privátního propojení, měli byste sledovat pokus o připojení k interní IP adrese. V tomto scénáři se očekává odpověď se stavovým kódem HTTP 401, pokud není zadaný token.
Další známé problémy
Aktualizace výpočetních prostředků Kubernetes se neprojeví
V současné době rozhraní příkazového řádku v2 a SDK verze 2 neumožňují aktualizaci žádné konfigurace stávajících výpočetních prostředků Kubernetes. Změna oboru názvů se například neprojeví.
Název pracovního prostoru nebo skupiny prostředků končí na -.
Běžnou příčinou chyby InternalServerError při vytváření úloh, jako jsou nasazení, koncové body nebo úlohy ve výpočetních prostředcích Kubernetes, jsou speciální znaky, jako je -, na konci pracovního prostoru nebo názvu skupiny prostředků.