Monitorování výkonu modelů nasazených do produkčního prostředí
PLATÍ PRO: Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Rozšíření Azure CLI ml v2 (aktuální)Python SDK azure-ai-ml v2 (aktuální)
Naučte se používat monitorování modelů služby Azure Machine Learning k nepřetržitému sledování výkonu modelů strojového učení v produkčním prostředí. Monitorování modelů poskytuje široký přehled o monitorovacích signálech a upozorněních na potenciální problémy. Když monitorujete signály a metriky výkonu modelů v produkčním prostředí, můžete kriticky vyhodnotit související rizika a identifikovat slepá místa, která by mohla nepříznivě ovlivnit vaši firmu.
V tomto článku se naučíte provádět následující úlohy:
- Nastavení připraveného a pokročilého monitorování pro modely nasazené do online koncových bodů služby Azure Machine Learning
- Monitorování metrik výkonu pro modely v produkčním prostředí
- Monitorování modelů nasazených mimo Azure Machine Learning nebo nasazených do dávkových koncových bodů služby Azure Machine Learning
- Nastavení monitorování modelů s využitím vlastních signálů a metrik
- Interpretace výsledků monitorování
- Integrace monitorování modelu Azure Machine Learning s Azure Event Gridem
Požadavky
Než budete postupovat podle kroků v tomto článku, ujistěte se, že máte následující požadavky:
Azure CLI a
mlrozšíření azure CLI. Další informace najdete v tématu Instalace, nastavení a použití rozhraní příkazového řádku (v2).Důležité
Příklady rozhraní příkazového řádku v tomto článku předpokládají, že používáte prostředí Bash (nebo kompatibilní). Například ze systému Linux nebo Subsystém Windows pro Linux.
Pracovní prostor služby Azure Machine Learning. Pokud ho nemáte, vytvořte ho pomocí kroků v části Instalace, nastavení a použití rozhraní příkazového řádku (v2).
Řízení přístupu na základě role v Azure (Azure RBAC) slouží k udělení přístupu k operacím ve službě Azure Machine Learning. Pokud chcete provést kroky v tomto článku, musí mít váš uživatelský účet přiřazenou roli vlastníka nebo přispěvatele pro pracovní prostor Služby Azure Machine Learning nebo vlastní roli, která povoluje
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Další informace najdete v tématu Správa přístupu k pracovnímu prostoru Azure Machine Learning.Pokud chcete monitorovat model nasazený do online koncového bodu služby Azure Machine Learning (spravovaný online koncový bod nebo online koncový bod Kubernetes), nezapomeňte:
Už máte model nasazený do online koncového bodu služby Azure Machine Learning. Podporují se spravované online koncové body i online koncový bod Kubernetes. Pokud nemáte model nasazený do online koncového bodu služby Azure Machine Learning, přečtěte si téma Nasazení a hodnocení modelu strojového učení pomocí online koncového bodu.
Povolte shromažďování dat pro nasazení modelu. Shromažďování dat můžete povolit během kroku nasazení pro online koncové body služby Azure Machine Learning. Další informace najdete v tématu Shromažďování produkčních dat z modelů nasazených do koncového bodu v reálném čase.
Pokud chcete monitorovat model, který je nasazený do dávkového koncového bodu služby Azure Machine Learning nebo nasazený mimo Azure Machine Learning, nezapomeňte:
- Mít prostředky ke shromažďování produkčních dat a jejich registraci jako datového prostředku služby Azure Machine Learning.
- Průběžně aktualizujte zaregistrovaný datový asset pro monitorování modelu.
- (Doporučeno) Zaregistrujte model v pracovním prostoru Azure Machine Learning pro sledování rodokmenu.
Důležité
Úlohy monitorování modelů jsou naplánované tak, aby běžely na bezserverových výpočetních fondech Sparku s podporou následujících typů instancí virtuálních počítačů: Standard_E4s_v3, , Standard_E8s_v3Standard_E16s_v3, Standard_E32s_v3a Standard_E64s_v3. Typ instance virtuálního počítače můžete vybrat s create_monitor.compute.instance_type vlastností v konfiguraci YAML nebo v rozevíracím seznamu v studio Azure Machine Learning.
Nastavení připraveného monitorování modelů
Předpokládejme, že model nasadíte do produkčního prostředí v online koncovém bodu služby Azure Machine Learning a povolíte shromažďování dat v době nasazení. V tomto scénáři azure Machine Learning shromažďuje produkční data odvozování a automaticky je ukládá do Služby Microsoft Azure Blob Storage. Pak můžete pomocí monitorování modelu Azure Machine Learning průběžně monitorovat tato produkční data odvozování.
K předběžnému nastavení monitorování modelů můžete použít Azure CLI, Sadu Python SDK nebo studio. Předefinovaná konfigurace monitorování modelu poskytuje následující možnosti monitorování:
- Azure Machine Learning automaticky rozpozná produkční datovou sadu odvozování přidruženou k online nasazení služby Azure Machine Learning a použije datovou sadu pro monitorování modelu.
- Referenční datová sada porovnání je nastavená jako nedávná datová sada pro odvozovací sadu v minulém produkčním prostředí.
- Nastavení monitorování automaticky zahrnuje a sleduje integrované monitorovací signály: posun dat, posun předpovědi a kvalitu dat. Pro každý signál monitorování azure Machine Learning používá:
- poslední datová sada pro odvození v minulém produkčním prostředí jako referenční datová sada porovnání
- inteligentní výchozí hodnoty pro metriky a prahové hodnoty
- Úloha monitorování se plánuje spouštět každý den v 3:15 (v tomto příkladu), aby získala monitorovací signály a vyhodnotila každý výsledek metriky s odpovídající prahovou hodnotou. Když dojde k překročení jakékoli prahové hodnoty, Azure Machine Learning ve výchozím nastavení pošle uživateli, který monitor nastavil, e-mail s upozorněním.
Monitorování modelů Azure Machine Learning používá az ml schedule k naplánování úlohy monitorování. Předsefinované monitorování modelu můžete vytvořit pomocí následujícího příkazu rozhraní příkazového řádku a definice YAML:
az ml schedule create -f ./out-of-box-monitoring.yaml
Následující YAML obsahuje definici pro předběžné monitorování modelu.
# out-of-box-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: credit_default_model_monitoring
display_name: Credit default model monitoring
description: Credit default model monitoring setup with minimal configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute: # specify a spark compute for monitoring job
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification # model task type: [classification, regression, question_answering]
endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id
alert_notification: # emails to get alerts
emails:
- abc@example.com
- def@example.com


Nastavení rozšířeného monitorování modelů
Azure Machine Learning poskytuje mnoho funkcí pro průběžné monitorování modelů. Úplný seznam těchto funkcí najdete v tématu Možnosti monitorování modelů. V mnoha případech je potřeba nastavit monitorování modelů s pokročilými možnostmi monitorování. V následujících částech nastavíte monitorování modelů s těmito funkcemi:
- Použití více monitorovacích signálů pro široké zobrazení.
- Použití historických trénovacích dat modelu nebo ověřovacích dat jako referenční datová sada porovnání.
- Monitorování nejdůležitějších N nejdůležitějších funkcí a jednotlivých funkcí
Konfigurace důležitosti funkcí
Důležitost funkce představuje relativní důležitost jednotlivých vstupních funkcí pro výstup modelu. Například temperature může být důležitější pro predikci modelu v porovnání s elevation. Když povolíte důležitost funkcí, získáte přehled o funkcích, které nechcete, aby se v produkčním prostředí zobrazovaly problémy s kvalitou dat.
Pokud chcete povolit důležitost funkce u jakéhokoli signálu (například posunu dat nebo kvality dat), musíte poskytnout:
- Trénovací datová sada jako
reference_datadatová sada - Vlastnost
reference_data.data_column_names.target_column, což je název výstupního nebo prediktivního sloupce modelu.
Po povolení důležitosti funkcí uvidíte důležitost funkcí pro každou funkci, kterou monitorujete, v uživatelském rozhraní monitorovacího studia modelu Azure Machine Learning.
Upozornění pro každý signál můžete povolit nebo zakázat nastavením alert_enabled vlastnosti při používání sady SDK nebo rozhraní příkazového řádku.
K pokročilému nastavení monitorování modelů můžete použít Azure CLI, sadu Python SDK nebo studio.
Pomocí následujícího příkazu rozhraní příkazového řádku a definice YAML vytvořte pokročilé nastavení monitorování modelů:
az ml schedule create -f ./advanced-model-monitoring.yaml
Následující YAML obsahuje definici pro pokročilé monitorování modelů.
# advanced-model-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with advanced configurations
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:credit-default:main
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1 # use training data as comparison reference dataset
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
features:
top_n_feature_importance: 10 # monitor drift for top 10 features
alert_enabled: true
metric_thresholds:
numerical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_data_quality:
type: data_quality
# reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
features: # monitor data quality for 3 individual features only
- SEX
- EDUCATION
alert_enabled: true
metric_thresholds:
numerical:
null_value_rate: 0.05
categorical:
out_of_bounds_rate: 0.03
feature_attribution_drift_signal:
type: feature_attribution_drift
# production_data: is not required input here
# Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data
# Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation
reference_data:
input_data:
path: azureml:credit-reference:1
type: mltable
data_context: training
data_column_names:
target_column: DEFAULT_NEXT_MONTH
alert_enabled: true
metric_thresholds:
normalized_discounted_cumulative_gain: 0.9
alert_notification:
emails:
- abc@example.com
- def@example.com






Nastavení monitorování výkonu modelu
Monitorování modelů Azure Machine Learning umožňuje sledovat výkon modelů v produkčním prostředí pomocí výpočtu jejich metrik výkonu. Aktuálně se podporují následující metriky výkonu modelu:
Klasifikační modely:
- Počet deset. míst
- Přesnost
- Odvolat
Pro regresní modely:
- Střední absolutní chyba (MAE)
- Střední kvadratická chyba (MSE)
- Odmocněná střední kvadratická chyba (RMSE)
Další předpoklady pro monitorování výkonu modelu
Abyste mohli nakonfigurovat signál výkonu modelu, musíte splnit následující požadavky:
Mít výstupní data pro produkční model (předpovědi modelu) s jedinečným ID pro každý řádek. Pokud shromáždíte produkční data s kolektorem dat Azure Machine Learning,
correlation_idposkytne se pro každou žádost o odvozování za vás. S kolektorem dat máte také možnost protokolovat vlastní jedinečné ID z vaší aplikace.Mít základní pravdivá data (skutečné hodnoty) s jedinečným ID pro každý řádek. Jedinečné ID pro daný řádek by se mělo shodovat s jedinečným ID pro výstupy modelu pro konkrétní požadavek odvození. Toto jedinečné ID slouží k propojení základní datové sady s výstupy modelu.
Aniž byste měli základní pravdivá data, nemůžete provádět monitorování výkonu modelu. Vzhledem k tomu, že se na úrovni aplikace narazí základní pravdivá data, je vaší zodpovědností je shromáždit, jakmile budou k dispozici. Měli byste také udržovat datový prostředek ve službě Azure Machine Learning, který obsahuje tato základní pravdivá data.
(Volitelné) Máte předem připojenou tabulkovou datovou sadu s výstupy modelu a podkladovými pravdivými daty, která jsou už propojená.
Monitorování požadavků na výkon modelu při použití kolektoru dat
Pokud použijete kolektor dat Azure Machine Learning ke shromažďování produkčních dat odvozování bez zadání vlastního jedinečného ID pro každý řádek jako samostatný sloupec, correlationid automaticky se vygeneruje a zahrne do zaprotokolovaného objektu JSON. Kolektor dat ale bude dávkovat řádky , které se odesílají v krátkých časových intervalech. Dávkové řádky spadají do stejného objektu JSON a budou tedy mít stejné correlationid.
Aby bylo možné rozlišovat řádky ve stejném objektu JSON, monitorování výkonu modelu Azure Machine Learning používá indexování k určení pořadí řádků v objektu JSON. Pokud jsou například tři řádky dávkové a correlationid řádek 1 bude mít ID , řádek dva bude mít ID test_0test_1a řádek tři bude mít ID test_2.test Aby se zajistilo, že datová sada základní pravdy obsahuje jedinečná ID, která odpovídají výstupům shromážděného produkčního modelu odvozování, ujistěte se, že každý z nich correlationid indexujete odpovídajícím způsobem. Pokud má váš zaprotokolovaný objekt JSON pouze jeden řádek, pak by to correlationid bylo correlationid_0.
Abyste se vyhnuli použití tohoto indexování, doporučujeme protokolovat jedinečné ID do vlastního sloupce v datovém rámci pandas, který protokolujete pomocí kolektoru dat služby Azure Machine Learning. Potom v konfiguraci monitorování modelu zadáte název tohoto sloupce, který spojí výstupní data modelu s vašimi základními pravdivými daty. Pokud jsou ID pro každý řádek v obou datových sadách stejná, může monitorování modelu Azure Machine Learning provádět monitorování výkonu modelu.
Příklad pracovního postupu monitorování výkonu modelu
Abyste pochopili koncepty spojené s monitorováním výkonu modelu, zvažte tento ukázkový pracovní postup. Předpokládejme, že nasazujete model, který předpovídá, jestli jsou transakce platební karty podvodné nebo ne, můžete pomocí těchto kroků monitorovat výkon modelu:
- Nakonfigurujte nasazení tak, aby používalo kolektor dat ke shromažďování produkčních dat odvozování modelu (vstupní a výstupní data). Řekněme, že výstupní data jsou uložená ve sloupci
is_fraud. - Pro každý řádek shromážděných dat odvozování zapište jedinečné ID. Jedinečné ID může pocházet z vaší aplikace nebo můžete pro každý protokolovaný objekt JSON použít
correlationidjedinečné vygenerování služby Azure Machine Learning. - Později, když budou k dispozici základní pravdivá (nebo skutečná)
is_frauddata, zaprotokolují a mapují se také na stejné jedinečné ID, které se protokolovalo s výstupy modelu. - Tato základní pravdivá
is_frauddata se také shromažďují, spravují a registruje ve službě Azure Machine Learning jako datový prostředek. - Vytvořte signál monitorování výkonu modelu, který spojuje produkční odvozování modelu a podkladové datové prostředky pravdivých informací pomocí jedinečných sloupců ID.
- Nakonec vypočítá metriky výkonu modelu.
Jakmile splníte požadavky na monitorování výkonu modelu, můžete nastavit monitorování modelů pomocí následujícího příkazu rozhraní příkazového řádku a definice YAML:
az ml schedule create -f ./model-performance-monitoring.yaml
Následující YAML obsahuje definici pro monitorování modelů s daty odvozování produkčního prostředí, která jste shromáždili.
$schema: http://azureml/sdk-2-0/Schedule.json
name: model_performance_monitoring
display_name: Credit card fraud model performance
description: Credit card fraud model performance
trigger:
type: recurrence
frequency: day
interval: 7
schedule:
hours: 10
minutes: 15
create_monitor:
compute:
instance_type: standard_e8s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment
monitoring_signals:
fraud_detection_model_performance:
type: model_performance
production_data:
data_column_names:
prediction: is_fraud
correlation_id: correlation_id
reference_data:
input_data:
path: azureml:my_model_ground_truth_data:1
type: mltable
data_column_names:
actual: is_fraud
correlation_id: correlation_id
data_context: actuals
alert_enabled: true
metric_thresholds:
tabular_classification:
accuracy: 0.95
precision: 0.8
alert_notification:
emails:
- abc@example.com





Nastavení monitorování modelů přenesením produkčních dat do služby Azure Machine Learning
Můžete také nastavit monitorování modelů pro modely nasazené do dávkových koncových bodů služby Azure Machine Learning nebo nasazených mimo Azure Machine Learning. Pokud nemáte nasazení, ale máte produkční data, můžete je použít k provádění průběžného monitorování modelu. Abyste mohli monitorovat tyto modely, musíte být schopni:
- Shromážděte produkční data odvozování z modelů nasazených v produkčním prostředí.
- Zaregistrujte produkční data odvozování jako datový prostředek služby Azure Machine Learning a zajistěte průběžné aktualizace dat.
- Zadejte vlastní komponentu předběžného zpracování dat a zaregistrujte ji jako komponentu Azure Machine Learning.
Pokud se data neshromažďují s kolektorem dat, musíte zadat vlastní komponentu předběžného zpracování dat. Bez této vlastní komponenty předběžného zpracování dat systém monitorování modelů Azure Machine Learning neví, jak zpracovávat data do tabulkového formuláře s podporou časových intervalů.
Vaše vlastní komponenta předběžného zpracování musí obsahovat tyto vstupní a výstupní podpisy:
| Vstup a výstup | Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|---|
| input | data_window_start |
literál, řetězec | data window start-time in ISO8601 format. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
literál, řetězec | data window end-time in ISO8601 format. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Shromážděná produkční data odvozování, která jsou zaregistrovaná jako datový prostředek služby Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Tabulková datová sada, která odpovídá podmnožině schématu referenčních dat. |
Příklad vlastní komponenty předběžného zpracování dat najdete v custom_preprocessing v úložišti Azuremml-examples Na GitHubu.
Jakmile splníte předchozí požadavky, můžete nastavit monitorování modelů pomocí následujícího příkazu rozhraní příkazového řádku a definice YAML:
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Následující YAML obsahuje definici pro monitorování modelů s daty odvozování produkčního prostředí, která jste shromáždili.
# model-monitoring-with-collected-data.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: fraud_detection_model_monitoring
display_name: Fraud detection model monitoring
description: Fraud detection model monitoring with your own production data
trigger:
# perform model monitoring activity daily at 3:15am
type: recurrence
frequency: day #can be minute, hour, day, week, month
interval: 1 # #every day
schedule:
hours: 3 # at 3am
minutes: 15 # at 15 mins after 3am
create_monitor:
compute:
instance_type: standard_e4s_v3
runtime_version: "3.3"
monitoring_target:
ml_task: classification
endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment
monitoring_signals:
advanced_data_drift: # monitoring signal name, any user defined name works
type: data_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_inputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_training_data:1 # use training data as comparison baseline
type: mltable
data_context: training
data_column_names:
target_column: is_fraud
features:
top_n_feature_importance: 20 # monitor drift for top 20 features
alert_enabled: true
metric_thresholds:
numberical:
jensen_shannon_distance: 0.01
categorical:
pearsons_chi_squared_test: 0.02
advanced_prediction_drift: # monitoring signal name, any user defined name works
type: prediction_drift
# define production dataset with your collected data
production_data:
input_data:
path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset
type: uri_folder
data_context: model_outputs
pre_processing_component: azureml:production_data_preprocessing:1
reference_data:
input_data:
path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset
type: mltable
data_context: validation
alert_enabled: true
metric_thresholds:
categorical:
pearsons_chi_squared_test: 0.02
alert_notification:
emails:
- abc@example.com
- def@example.com
Nastavení monitorování modelů s využitím vlastních signálů a metrik
Pomocí monitorování modelů Azure Machine Learning můžete definovat vlastní signál a implementovat libovolnou metriku podle vašeho výběru pro monitorování modelu. Tento vlastní signál můžete zaregistrovat jako součást služby Azure Machine Learning. Když se úloha monitorování modelu Azure Machine Learning spustí v zadaném plánu, vypočítá metriky, které jste definovali ve vlastním signálu, stejně jako u předem připravených signálů (posun dat, posun predikce a kvalita dat).
Pokud chcete nastavit vlastní signál pro monitorování modelů, musíte nejprve definovat vlastní signál a zaregistrovat ho jako komponentu Azure Machine Learning. Komponenta Azure Machine Learning musí mít tyto vstupní a výstupní podpisy:
Podpis vstupu komponenty
Vstupní datový rámec komponenty by měl obsahovat následující položky:
- S
mltablezpracovanými daty ze komponenty předběžného zpracování - Libovolný počet literálů, z nichž každý představuje implementovanou metriku jako součást vlastní komponenty signálu. Pokud jste například implementovali metriku,
std_deviationbudete potřebovat vstup prostd_deviation_threshold. Obecně platí, že pro každou metriku by měl být jeden vstup s názvem<metric_name>_threshold.
| Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|
| production_data | mltable | Tabulková datová sada, která odpovídá podmnožině schématu referenčních dat. | |
| std_deviation_threshold | literál, řetězec | Odpovídající prahová hodnota implementované metriky. | 2 |
Podpis výstupu komponenty
Výstupní port komponenty by měl mít následující podpis.
| Název podpisu | Typ | Popis |
|---|---|---|
| signal_metrics | mltable | Tabulka mltable, která obsahuje vypočítané metriky. Schéma je definováno v další části signal_metrics schématu. |
schéma signal_metrics
Výstupní datový rámec komponenty by měl obsahovat čtyři sloupce: group, metric_name, metric_valuea threshold_value.
| Název podpisu | Typ | Popis | Příklad hodnoty |
|---|---|---|---|
| skupina | literál, řetězec | Logické seskupení nejvyšší úrovně, které se má použít na tuto vlastní metriku. | TRANSACTIONAMOUNT |
| metric_name | literál, řetězec | Název vlastní metriky | std_deviation |
| metric_value | číselný | Hodnota vlastní metriky. | 44,896.082 |
| threshold_value | číselný | Prahová hodnota vlastní metriky. | 2 |
Následující tabulka ukazuje příklad výstupu z vlastní komponenty signálu, která vypočítá metriku std_deviation :
| skupina | metric_value | metric_name | threshold_value |
|---|---|---|---|
| TRANSACTIONAMOUNT | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| TRANSACTIONAMOUNTUSD | 54,004.902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
Pokud chcete zobrazit příklad definice vlastní komponenty signálu a výpočetní kód metriky, podívejte se na custom_signal v úložišti azureml-examples.
Jakmile splníte požadavky na používání vlastních signálů a metrik, můžete nastavit monitorování modelu pomocí následujícího příkazu rozhraní příkazového řádku a definice YAML:
az ml schedule create -f ./custom-monitoring.yaml
Následující YAML obsahuje definici monitorování modelu s vlastním signálem. Něco, co si o kódu můžete všimnout:
- Předpokládá se, že jste už vytvořili a zaregistrovali komponentu s vlastní definicí signálu ve službě Azure Machine Learning.
- Registrovaná
component_idvlastní komponenta signálu jeazureml:my_custom_signal:1.0.0. - Pokud jste data s kolekcí dat shromáždili, můžete vlastnost vynechat
pre_processing_component. Pokud chcete použít součást předběžného zpracování k předběžnému zpracování produkčních dat, která kolektor dat neshromažďuje, můžete ji zadat.
# custom-monitoring.yaml
$schema: http://azureml/sdk-2-0/Schedule.json
name: my-custom-signal
trigger:
type: recurrence
frequency: day # can be minute, hour, day, week, month
interval: 7 # #every day
create_monitor:
compute:
instance_type: "standard_e4s_v3"
runtime_version: "3.3"
monitoring_signals:
customSignal:
type: custom
component_id: azureml:my_custom_signal:1.0.0
input_data:
production_data:
input_data:
type: uri_folder
path: azureml:my_production_data:1
data_context: test
data_window:
lookback_window_size: P30D
lookback_window_offset: P7D
pre_processing_component: azureml:custom_preprocessor:1.0.0
metric_thresholds:
- metric_name: std_deviation
threshold: 2
alert_notification:
emails:
- abc@example.com
Interpretace výsledků monitorování
Po nakonfigurování monitorování modelu a dokončení prvního spuštění můžete přejít zpět na kartu Monitorování v studio Azure Machine Learning a zobrazit výsledky.
V hlavním zobrazení Monitorování vyberte název monitorování modelu a zobrazte stránku Přehled monitorování. Tato stránka zobrazuje odpovídající model, koncový bod a nasazení spolu s podrobnostmi o signálech, které jste nakonfigurovali. Následující obrázek ukazuje řídicí panel monitorování, který zahrnuje signály pro posun dat a kvalitu dat. V závislosti na signálech monitorování, které jste nakonfigurovali, může řídicí panel vypadat jinak.
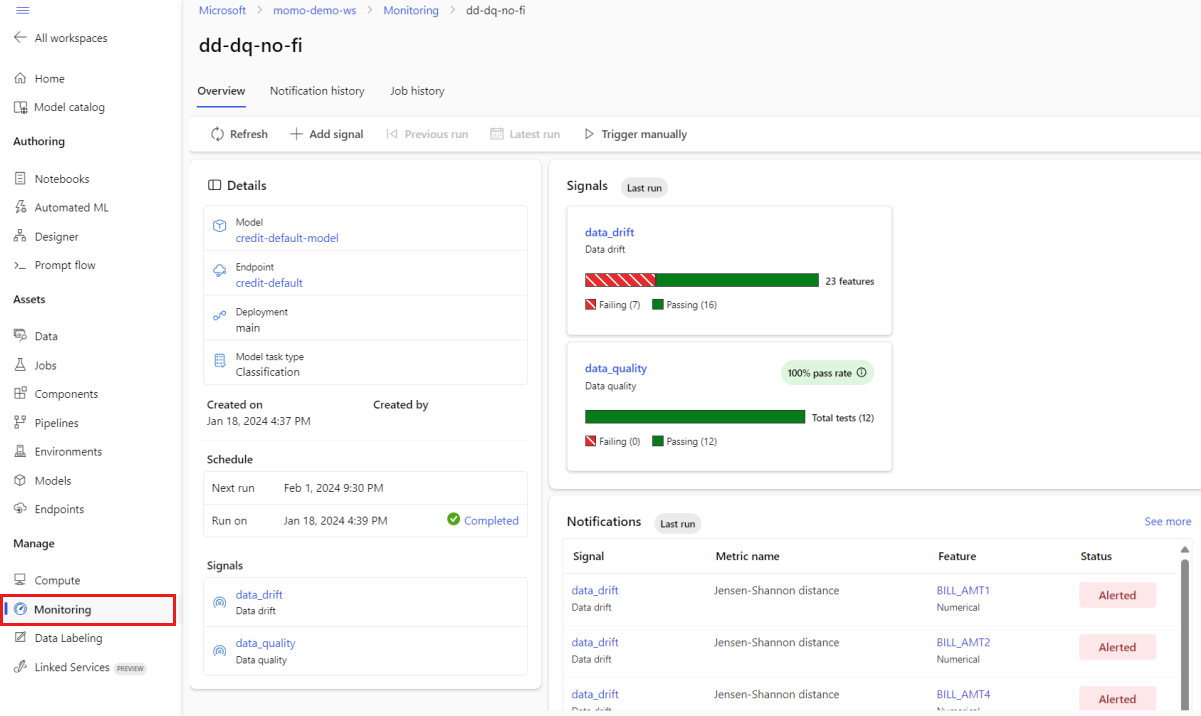
V části Oznámení na řídicím panelu si prohlédněte jednotlivé signály, které funkce překročily nakonfigurovanou prahovou hodnotu pro příslušné metriky:
Výběrem data_drift přejděte na stránku s podrobnostmi o posunu dat. Na stránce podrobností můžete zobrazit hodnotu metrik posunu dat pro každou číselnou a kategorickou funkci, kterou jste zahrnuli do konfigurace monitorování. Když má monitor více než jedno spuštění, zobrazí se spojnice trendu pro každou funkci.
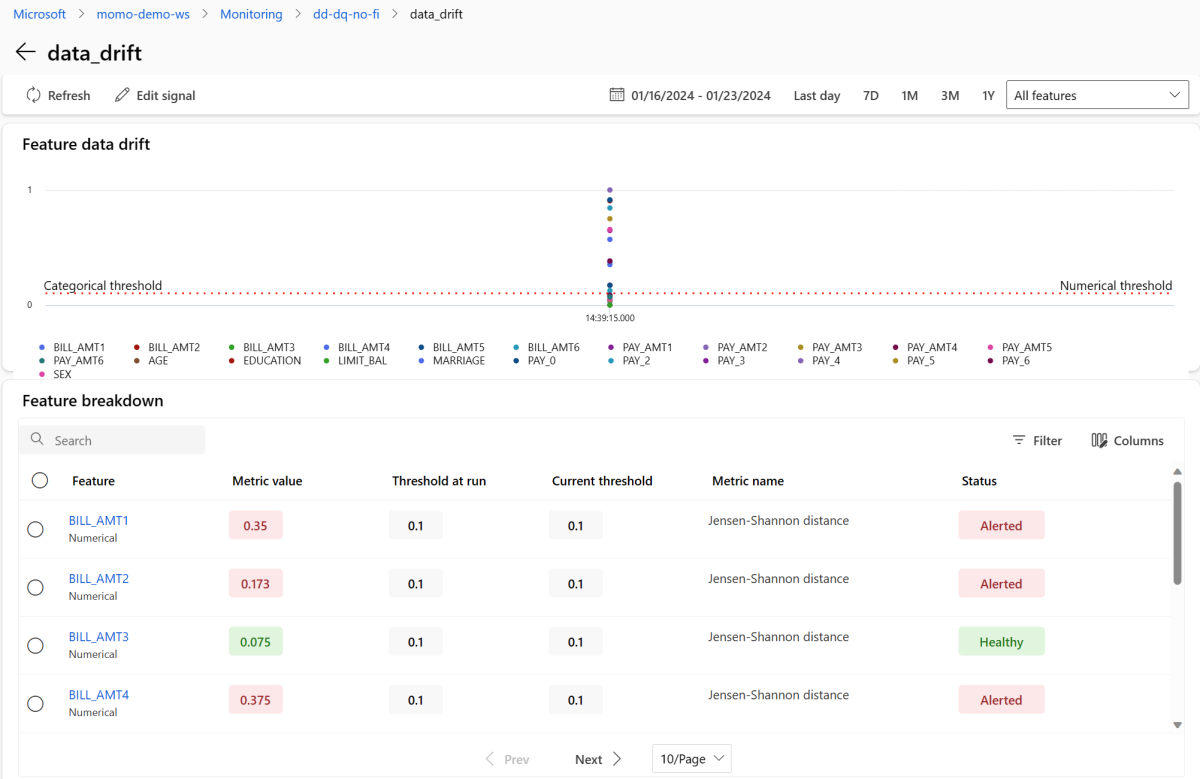
Pokud chcete zobrazit jednotlivé funkce podrobně, vyberte název funkce, abyste zobrazili produkční distribuci v porovnání s referenční distribucí. Toto zobrazení také umožňuje sledovat posun v průběhu času pro danou konkrétní funkci.

Vraťte se na řídicí panel monitorování a výběrem data_quality zobrazte stránku signálu kvality dat. Na této stránce můžete zobrazit míry hodnot null, míry chyb mimo hranice a chybovost datových typů pro každou funkci, kterou monitorujete.





Monitorování modelů je průběžný proces. Pomocí monitorování modelů Azure Machine Learning můžete nakonfigurovat několik monitorovacích signálů, abyste získali široký přehled o výkonu modelů v produkčním prostředí.
Integrace monitorování modelu Azure Machine Learning s Azure Event Gridem
Události vygenerované monitorováním modelu Služby Azure Machine Learning můžete použít k nastavení aplikací, procesů nebo pracovních postupů CI/CD řízených událostmi pomocí služby Azure Event Grid. Události můžete využívat prostřednictvím různých obslužných rutin událostí, jako jsou Azure Event Hubs, Funkce Azure a aplikace logiky. Na základě posunu zjištěného monitory můžete provádět akce prostřednictvím kódu programu, například nastavením kanálu strojového učení, který model znovu vytrénuje a znovu ho nasadí.
Začínáme s integrací monitorování modelu Azure Machine Learning se službou Event Grid:
Postupujte podle pokynů v tématu Nastavení na webu Azure Portal. Zadejte název odběru události, například MonitoringEvent, a v části Typy událostí vyberte pouze pole Stav spuštění změněno.
Upozorňující
Nezapomeňte u typu události vybrat Stav spuštění změněný . Nevybírejte zjištěný posun datové sady, protože se týká posunu dat verze 1 místo monitorování modelu Azure Machine Learning.
Postupujte podle kroků v části Filtrování a přihlášení k odběru událostí a nastavte filtrování událostí pro váš scénář. Přejděte na kartu Filtry a v části Rozšířené filtry přidejte následující klíč, operátor a hodnotu:
-
Klíč:
data.RunTags.azureml_modelmonitor_threshold_breached - Hodnota: Selhalo kvůli jedné nebo více funkcím, které porušují prahové hodnoty metriky.
- Operátor: Řetězec obsahuje
S tímto filtrem se události generují, když se stav spuštění změní (z dokončeného na neúspěšné nebo neúspěšné dokončení) pro jakékoli monitorování v pracovním prostoru Služby Azure Machine Learning.
-
Klíč:
Pokud chcete filtrovat na úrovni monitorování, použijte následující klíč, operátor a hodnotu v části Rozšířené filtry:
-
Klíč:
data.RunTags.azureml_modelmonitor_threshold_breached -
Hodnota:
your_monitor_name_signal_name - Operátor: Řetězec obsahuje
Ujistěte se, že
your_monitor_name_signal_nameje název signálu v konkrétním monitoru, pro který chcete filtrovat události. Napříkladcredit_card_fraud_monitor_data_drift. Aby tento filtr fungoval, musí tento řetězec odpovídat názvu monitorovacího signálu. Signál byste měli pojmenovat jak názvem monitoru, tak názvem signálu pro tento případ.-
Klíč:
Po dokončení konfigurace odběru událostí vyberte požadovaný koncový bod, který bude sloužit jako obslužná rutina události, například Azure Event Hubs.
Po zachycení událostí je můžete zobrazit na stránce koncového bodu:


Události můžete zobrazit také na kartě Metriky služby Azure Monitor:
